
המסמך הזה, שמיועד להטמעה בפרויקט הקוד הפתוח של Android (AOSP), מסביר את הרציונל מאחורי התכונה 'התאמה אישית במכשיר' (ODP), את עקרונות העיצוב שמנחים את הפיתוח שלה, את הפרטיות שלה באמצעות מודל סודיות ואיך היא עוזרת להבטיח חוויה פרטית שניתנת לאימות.
אנחנו מתכננים לעשות את זה על ידי פישוט מודל הגישה לנתונים, ולוודא שכל נתוני המשתמשים שיוצאים מגבולות האבטחה הם פרטיים דיפרנציאלית ברמה של (משתמש, מאמץ, מופע_מודל) (לפעמים מקוצר לרמת המשתמש במסמך הזה).
כל הקוד שקשור ליציאה פוטנציאלית של נתוני משתמשי קצה מהמכשירים של משתמשי הקצה יהיה קוד פתוח וניתן לאימות על ידי גורמים חיצוניים. בשלבים הראשונים של ההצעה שלנו, אנחנו רוצים לעורר עניין ולאסוף משוב לגבי פלטפורמה שתאפשר הזדמנויות להתאמה אישית במכשיר. אנחנו מזמינים בעלי עניין כמו מומחי פרטיות, מנתחי נתונים ומומחי אבטחה ליצור איתנו קשר.
Vision
התאמה אישית במכשיר נועדה להגן על המידע של משתמשי הקצה מפני עסקים שהם לא יצרו איתם אינטראקציה. עסקים יכולים להמשיך להתאים אישית את המוצרים והשירותים שלהם למשתמשי הקצה (לדוגמה, באמצעות מודלים של למידת מכונה שעברו אנונימיזציה מתאימה ודיפרנציאלית), אבל הם לא יוכלו לראות את ההתאמות האישיות המדויקות שבוצעו למשתמש קצה (שלא תלויות רק בכלל ההתאמה האישית שנוצר על ידי בעל העסק, אלא גם בהעדפות האישיות של משתמש הקצה), אלא אם יש אינטראקציות ישירות בין העסק לבין משתמש הקצה. אם עסק יוצר מודלים של למידת מכונה או ניתוחים סטטיסטיים, ODP יפעל כדי לוודא שהם עוברים אנונימיזציה נכונה באמצעות המנגנונים המתאימים של פרטיות דיפרנציאלית.
התוכנית הנוכחית שלנו היא לבחון את ODP בכמה אבני דרך, ולכלול את התכונות והפונקציות הבאות. אנחנו גם מזמינים גורמים מעוניינים להציע באופן בונה תכונות או תהליכי עבודה נוספים כדי לקדם את המחקר הזה:
- סביבת ארגז חול שבה כל הלוגיקה העסקית נכללת ומופעלת, ומאפשרת למספר רב של אותות ממשתמשי קצה להיכנס לארגז החול תוך הגבלת התפוקות.
מאגרי נתונים מוצפנים מקצה לקצה עבור:
- אמצעי בקרה למשתמשים ונתונים אחרים שקשורים למשתמשים. הנתונים האלה יכולים להיות נתונים שהמשתמשים סיפקו או נתונים שנאספו על ידי העסקים והוסקו מהם, יחד עם אמצעי בקרה על זמן החיים (TTL), מדיניות מחיקה, מדיניות פרטיות ועוד.
- הגדרות עסקיות. ODP מספק אלגוריתמים לדחיסה או להסוואה של הנתונים האלה.
- תוצאות העיבוד של העסק. התוצאות האלה יכולות להיות:
- הם משמשים כקלטים בסבבים מאוחרים יותר של עיבוד,
- הנתונים עוברים רעש בהתאם למנגנוני פרטיות דיפרנציאלית מתאימים ומועלים לנקודות קצה שעומדות בדרישות.
- העלאה באמצעות תהליך העלאה מהימן לסביבות מחשוב אמינות (TEE) שמריצות עומסי עבודה בקוד פתוח עם מנגנוני פרטיות דיפרנציאלית מרכזיים מתאימים
- מוצג למשתמשי קצה.
ממשקי API שנועדו:
- עדכון 2(א), עדכון אצווה או עדכון מצטבר.
- עדכון 2(ב) באופן תקופתי, בשיטת אצווה או באופן מצטבר.
- העלאה 2(ג), עם מנגנוני רעש מתאימים בסביבות צבירה מהימנות. יכול להיות שהתוצאות האלה יהפכו ל-2(ב) בסבבי העיבוד הבאים.
ציר הזמן
זוהי התוכנית הנוכחית שרשומה לבדיקת ODP בגרסת בטא. ציר הזמן עשוי להשתנות.
| תכונה | המחצית הראשונה של 2025 | רבעון 3 2025 |
|---|---|---|
| אימון + הסקה במכשיר | אפשר לפנות לצוות של ארגז החול לפרטיות כדי לדון באפשרויות פוטנציאליות להפעלת פיילוט במהלך התקופה הזו. | מתחילים בהשקה למכשירים מתאימים עם Android T ומעלה. |
עקרונות עיצוב
יש שלושה עקרונות ש-ODP שואפת לאזן ביניהם: פרטיות, הוגנות ותועלת.
מודל נתונים מדורג להגנה משופרת על הפרטיות
ה-ODP פועל לפי עקרונות הפרטיות לפי עיצוב, והוא מתוכנן כך שההגנה על פרטיות משתמשי הקצה היא ברירת המחדל.
ב-ODP נבדקת האפשרות להעביר את העיבוד של ההתאמה האישית למכשיר של משתמש הקצה. הגישה הזו מאזנת בין פרטיות לבין שימושיות, כי הנתונים נשמרים במכשיר ככל האפשר והם מעובדים מחוץ למכשיר רק כשצריך. ה-ODP מתמקד ב:
- שליטה בנתוני משתמשי קצה במכשיר, גם כשהם יוצאים מהמכשיר. יעדים צריכים להיות סביבות ביצוע מהימנות שאושרו על ידי ספקי ענן ציבורי שמריצים קוד שנוצר על ידי ODP.
- אפשרות לבדיקה במכשיר של מה שקורה לנתוני משתמשי הקצה אם הם יוצאים מהמכשיר. ODP מספקת עומסי עבודה (workload) של מחשוב משותף בקוד פתוח, כדי לתאם למידת מכונה וניתוח סטטיסטי בין מכשירים שונים למשתמשים שלה. המכשיר של משתמש הקצה יאשר שעומסי העבודה האלה מבוצעים בסביבות מחשוב אמינות ללא שינויים.
- פרטיות טכנית מובטחת (לדוגמה, צבירת נתונים, הוספת נתונים מיותרים, פרטיות דיפרנציאלית) של פלט שיוצא מהגבול שניתן לאימות או שנשלט על ידי המכשיר.
לכן, ההתאמה האישית תהיה ספציפית למכשיר.
בנוסף, עסקים צריכים אמצעי הגנה על הפרטיות, והפלטפורמה צריכה לספק אותם. המשמעות היא שמירה של נתונים עסקיים גולמיים בשרתים המתאימים. כדי להשיג את זה, ODP משתמש במודל הנתונים הבא:
- כל מקור נתונים גולמי יאוחסן במכשיר או בצד השרת, וכך יתאפשר למידה והסקת מסקנות מקומיות.
- אנחנו נספק אלגוריתמים שיעזרו לכם לקבל החלטות על סמך כמה מקורות נתונים, למשל סינון בין שני מיקומים שונים של נתונים, או אימון או הסקת מסקנות על סמך מקורות שונים.
בהקשר הזה, יכול להיות מגדל עסקי ומגדל משתמשי קצה:
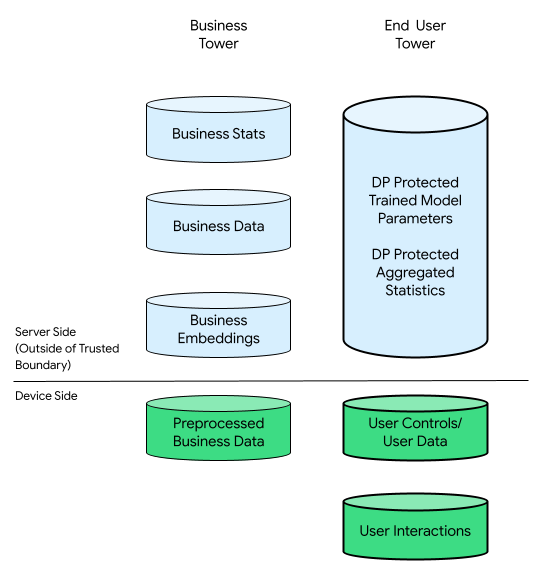
החלק של משתמשי הקצה מורכב מנתונים שסופקו על ידי משתמשי הקצה (לדוגמה, פרטי חשבון ואמצעי בקרה), נתונים שנאספו שקשורים לאינטראקציות של משתמשי הקצה עם המכשיר שלהם ונתונים נגזרים (לדוגמה, תחומי עניין והעדפות) שהעסק הסיק. נתונים משוערים לא מחליפים הצהרות ישירות של משתמשים.
לשם השוואה, בתשתית שמתמקדת בענן, כל הנתונים הגולמיים מהמגדל של משתמש הקצה מועברים לשרתים של העסקים. לעומת זאת, בתשתית שממוקדת במכשיר, כל הנתונים הגולמיים ממגדל משתמשי הקצה נשארים במקור שלהם, בעוד שהנתונים של העסק נשארים מאוחסנים בשרתים.
התאמה אישית במכשיר משלבת את היתרונות של שני העולמות. היא מאפשרת רק לקוד מאומת ממקור פתוח לעבד נתונים שיש להם פוטנציאל להיות קשורים למשתמשי קצה בסביבות מחשוב אמינות (TEE) באמצעות ערוצי פלט פרטיים יותר.
השתתפות ציבורית כוללת לפתרונות הוגנים
המטרה של ODP היא ליצור סביבה מאוזנת לכל המשתתפים בסביבה עסקית מגוונת. אנחנו מבינים שמדובר במערכת אקולוגית מורכבת שכוללת מגוון שחקנים שמציעים שירותים ומוצרים שונים.
כדי לעודד חדשנות, ODP מציעה ממשקי API שאפשר להטמיע באמצעות מפתחים ועסקים שהם מייצגים. התאמה אישית במכשיר מאפשרת שילוב חלק של ההטמעות האלה תוך ניהול של גרסאות, מעקב, כלים למפתחים וכלים למשוב. התאמה אישית במכשיר לא יוצרת לוגיקה עסקית קונקרטית, אלא משמשת כזרז ליצירתיות.
יכול להיות שבהמשך יתווספו עוד אלגוריתמים ל-ODP. שיתוף פעולה עם המערכת האקולוגית הוא חיוני כדי לקבוע את רמת התכונות הנכונה, וכדי להגדיר מכסת משאבי מכשיר סבירה לכל עסק שמשתתף בתוכנית. אנחנו מצפים לקבל משוב מהסביבה העסקית כדי שנוכל לזהות ולתעדף תרחישי שימוש חדשים.
כלי למפתחים לשיפור חוויית המשתמש
עם ODP לא מאבדים נתוני אירועים ואין עיכובים בתצפיות, כי כל האירועים מתועדים באופן מקומי ברמת המכשיר. אין שגיאות בהצטרפות וכל האירועים משויכים למכשיר ספציפי. כתוצאה מכך, כל האירועים שנצפו יוצרים באופן טבעי רצף כרונולוגי שמשקף את האינטראקציות של המשתמש.
התהליך הפשוט הזה מבטל את הצורך בצירוף או בסידור מחדש של נתונים, ומאפשר גישה לנתוני משתמשים כמעט בזמן אמת וללא אובדן נתונים. בתמורה, יכול להיות שהשיפור הזה יגביר את התועלת שמשתמשי הקצה תופסים כשהם משתמשים במוצרים ובשירותים מבוססי-נתונים, ויכול להיות שהוא יוביל לרמות גבוהות יותר של שביעות רצון ולחוויות משמעותיות יותר. בעזרת ODP, עסקים יכולים להתאים את עצמם ביעילות לצרכים של המשתמשים שלהם.
מודל הפרטיות: פרטיות באמצעות סודיות
בקטעים הבאים נסביר על מודל הצרכן-יצרן כבסיס לניתוח הפרטיות הזה, ועל פרטיות בסביבת מחשוב לעומת דיוק הפלט.
מודל צרכן-יצרן כבסיס לניתוח הפרטיות הזה
נשתמש במודל צרכן-יצרן כדי לבחון את הבטחות הפרטיות של פרטיות באמצעות סודיות. החישובים במודל הזה מיוצגים כצמתים בגרף אציקלי מכוון (DAG) שמורכב מצמתים ומגרפים משניים. לכל צומת חישוב יש שלושה רכיבים: קלט שנצרך, פלט שנוצר ומיפוי חישוב של קלט לפלט.

במודל הזה, הגנה על הפרטיות חלה על כל שלושת הרכיבים:
- פרטיות הקלט. לצמתים יכולים להיות שני סוגים של קלטים. אם קלט נוצר על ידי צומת קודם, כבר יש לו את ערבויות הפרטיות של הפלט של הצומת הקודם. אחרת, הקלט צריך לעמוד בדרישות של מדיניות הכנסת הנתונים באמצעות מנוע המדיניות.
- פרטיות הפלט. יכול להיות שיהיה צורך להפוך את הפלט לפרטי, כמו הפלט שמתקבל מפרטיות דיפרנציאלית (DP).
- סודיות של סביבת החישוב. החישוב צריך להתבצע בסביבה מאובטחת, כדי להבטיח שלאף אחד לא תהיה גישה למצבי ביניים בתוך הצומת. הטכנולוגיות שמאפשרות את זה כוללות חישובים מאוחדים (FC), סביבות מחשוב אמינות (TEE) שמבוססות על חומרה, חישוב מאובטח רב-משתתפים (sMPC), הצפנה הומומורפית (HPE) ועוד. חשוב לציין שפרטיות באמצעות אמצעי הגנה על סודיות, מצבי ביניים וכל הפלט שיוצא מגבולות הסודיות עדיין צריכים להיות מוגנים על ידי מנגנוני פרטיות דיפרנציאלית. שני מאפייני החובה הם:
- סודיות של הסביבות, כדי להבטיח שרק פלטים מוצהרים ייצאו מהסביבה
- התקינות, שמאפשרת להסיק באופן מדויק טענות לגבי פרטיות של פלט מטענות לגבי פרטיות של קלט. התכונה Soundness מאפשרת להפיץ את מאפיין הפרטיות במורד ה-DAG.
מערכת פרטית שומרת על פרטיות הקלט, על סודיות סביבת המחשוב ועל פרטיות הפלט. עם זאת, אפשר להקטין את מספר היישומים של מנגנוני פרטיות דיפרנציאלית על ידי ביצוע יותר עיבוד בתוך סביבת מחשוב חסויה.
למודל הזה יש שני יתרונות עיקריים. קודם כל, אפשר לייצג את רוב המערכות, גדולות וקטנות, כגרף מכוון אציקלי (DAG). שנית, המאפיינים של Post-Processing [Section 2.1] ושל Lemma 2.4 ב- The Complexity of Differential Privacy מאפשרים לנתח את האיזון בין פרטיות לדיוק (במקרה הגרוע ביותר) עבור גרף שלם באמצעות כלים יעילים:
- העיבוד שלאחר מכן מבטיח שאחרי שהמערכת תהפוך כמות לפרטית, היא לא תוכל לבטל את ההפיכה הזו אם לא נעשה שימוש חוזר בנתונים המקוריים. כל עוד כל נתוני הקלט של צומת הם פרטיים, נתוני הפלט שלו הם פרטיים, ללא קשר לחישובים שלו.
- הכלל המתקדם של קומפוזיציה מבטיח שאם כל חלק בגרף הוא DP, גם הגרף הכולל הוא DP. הכלל הזה מגביל את ε ו-δ של הפלט הסופי של הגרף בערך ל-ε√κ, בהתאמה, בהנחה שלגרף יש κ יחידות וכל יחידה היא (ε, δ)-DP.
שני המאפיינים האלה מתורגמים לשני עקרונות עיצוב לכל צומת:
- Property 1 (From Post-Processing) if a node's inputs are all DP, its output is DP, accommodating any arbitrary business logic executed in the node, and supporting businesses' "secret sauces."
- מאפיין 2 (מתוך Advanced Composition) אם לא כל נתוני הקלט של צומת הם DP, הפלט שלו חייב להיות תואם ל-DP. אם צומת החישוב פועל בסביבות ביצוע מהימנות ומבצע עומסי עבודה והגדרות שסופקו על ידי התכונה 'התאמה אישית במכשיר' בקוד פתוח, אפשר להגדיר גבולות DP הדוקים יותר. אחרת, יכול להיות שהתאמה אישית במכשיר תצטרך להשתמש בגבולות של DP במקרה הגרוע. בגלל מגבלות משאבים, בשלב הראשון תינתן עדיפות לסביבות ביצוע מהימנות שמוצעות על ידי ספק ענן ציבורי.
פרטיות בסביבת מחשוב לעומת דיוק הפלט
מעכשיו, התכונה 'התאמה אישית במכשיר' תתמקד בשיפור האבטחה של סביבות מחשוב סודיות, ובהבטחה שמצבי ביניים יישארו בלתי נגישים. תהליך האבטחה הזה, שנקרא איטום, יחול ברמת הגרף המשני, ויאפשר ליצור כמה צמתים שתואמים ל-DP ביחד. המשמעות היא שהנכס property 1 וproperty 2 שצוינו קודם חלים ברמת הגרף המשני.

כמובן שצריך להחיל DP על הפלט הסופי של הגרף, פלט 7, לכל קומפוזיציה. כלומר, יהיו 2 נקודות נתונים בסך הכול לגרף הזה, לעומת 3 נקודות נתונים (מקומיות) אם לא נעשה שימוש באיטום.
בעצם, על ידי אבטחת סביבת החישוב וביטול ההזדמנויות של גורמים עוינים לגשת לכניסות של גרף או תת-גרף ולמצבי ביניים, אפשר ליישם DP מרכזי (כלומר, הפלט של סביבה אטומה תואם ל-DP), שיכול לשפר את הדיוק בהשוואה לDP מקומי (כלומר, הכניסות האישיות תואמות ל-DP). העיקרון הזה הוא הבסיס להכללה של FC, TEE, sMPC ו-HPE כטכנולוגיות לשמירה על פרטיות. אפשר לעיין בפרק 10 בספר The Complexity of Differential Privacy.
דוגמה טובה ופרקטית היא אימון מודלים והסקת מסקנות. הדיונים בהמשך מניחים ש-(1) יש חפיפה בין אוכלוסיית האימון לבין אוכלוסיית ההסקה, ו-(2) גם התכונות וגם התוויות מהווים נתונים פרטיים של משתמשים. אנחנו יכולים להחיל DP על כל כניסות הקלט:

התאמה אישית במכשיר יכולה להחיל DP מקומי על תוויות ותכונות של משתמשים לפני שליחתם לשרתים. הגישה הזו לא מטילה דרישות על סביבת ההפעלה של השרת או על הלוגיקה העסקית שלו.



זהו העיצוב הנוכחי של התאמה אישית במכשיר.
פרטיות מאומתת
התאמה אישית במכשיר נועדה להיות פרטית וניתנת לאימות. הוא מתמקד באימות של מה שקורה מחוץ למכשירי המשתמשים. ODP יכתוב את הקוד שמבצע עיבוד של הנתונים שיוצאים מהמכשירים של משתמשי הקצה, וישתמש ב-RFC 9334 Remote ATtestation procedureS (RATS) Architecture של NIST כדי לאשר שהקוד הזה פועל ללא שינוי בשרת שאינו דורש הרשאות אדמין, שתואם ל-Confidential Computing Consortium. הקודים האלה יהיו קוד פתוח ונגישים לאימות שקוף כדי לבנות אמון. אמצעים כאלה יכולים לתת לאנשים ביטחון שהנתונים שלהם מוגנים, ועסקים יכולים לבסס מוניטין על בסיס חזק של הבטחת פרטיות.
היבט חשוב נוסף של התאמה אישית במכשיר הוא צמצום כמות הנתונים הפרטיים שנאספים ונשמרים. העיקרון הזה מיושם באמצעות טכנולוגיות כמו Federated Compute ופרטיות דיפרנציאלית, שמאפשרות לחשוף דפוסי נתונים חשובים בלי לחשוף פרטים אישיים רגישים או מידע מזהה.
שמירה על נתיב ביקורת שמתעד פעילויות שקשורות לעיבוד נתונים ולשיתוף שלהם היא היבט חשוב נוסף של פרטיות שניתן לאמת. כך אפשר ליצור דוחות ביקורת ולזהות נקודות חולשה, וזה מדגים את המחויבות שלנו לפרטיות.
אנחנו מבקשים ממומחי פרטיות, רשויות, תעשיות ואנשים פרטיים לשתף איתנו פעולה באופן בונה כדי לעזור לנו לשפר כל הזמן את העיצוב וההטמעה של התכונות.
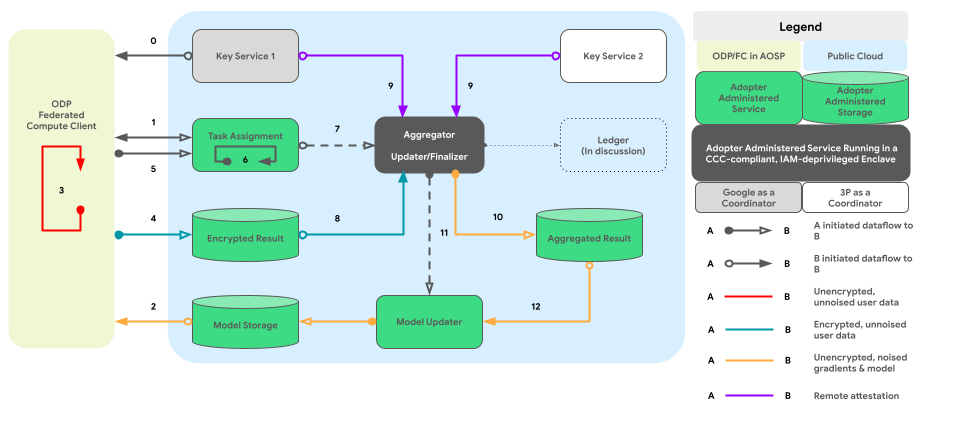
בתרשים הבא מוצג נתיב הקוד לצבירה ולרעש בין מכשירים לפי פרטיות דיפרנציאלית.
עיצוב ברמה גבוהה
איך אפשר להטמיע פרטיות באמצעות סודיות? ברמה גבוהה, מנוע מדיניות שנוצר על ידי ODP ופועל בסביבה אטומה משמש כרכיב הליבה שמפקח על כל צומת או תת-גרף, תוך מעקב אחר סטטוס ה-DP של הקלט והפלט שלהם:
- מנקודת המבט של מנוע המדיניות, המכשירים והשרתים מקבלים יחס זהה. מכשירים ושרתים שמריצים את אותו מנוע מדיניות נחשבים זהים מבחינה לוגית, אחרי שמנועי המדיניות שלהם עברו אימות הדדי.
- במכשירים, הבידוד מושג באמצעות תהליכים מבודדים של AOSP (או pKVM בטווח הארוך, אחרי שהזמינות תהיה גבוהה). בשרתים, הבידוד מתבסס על "צד מהימן", שהוא או TEE בתוספת פתרונות טכניים אחרים לאיטום (האפשרות המועדפת), או הסכם חוזי, או שניהם.
במילים אחרות, כל הסביבות הסגורות שמתקינות ומריצות את מנוע מדיניות הפלטפורמה נחשבות לחלק מבסיס המחשוב המהימן (TCB) שלנו. הנתונים יכולים להתפשט ללא רעשים נוספים באמצעות TCB. צריך להחיל DP כשנתונים יוצאים מ-TCB.
העיצוב הכללי של התאמה אישית במכשיר משלב ביעילות שני רכיבים חיוניים:
- ארכיטקטורה של תהליכים מוצמדים לביצוע לוגיקה עסקית
- מדיניות ומנוע מדיניות לניהול תעבורת נתונים נכנסת (ingress) ויוצאת (egress) ופעולות מותרות.
העיצוב המאוחד הזה מאפשר לעסקים להתחרות בתנאים שווים. הם יכולים להריץ את הקוד הקנייני שלהם בסביבת מחשוב אמינה (TEE) ולגשת לנתוני משתמשים שעברו בדיקות מדיניות מתאימות.
בקטעים הבאים נרחיב על שני ההיבטים העיקריים האלה.
ארכיטקטורה של תהליכים מוצמדים להרצת לוגיקה עסקית
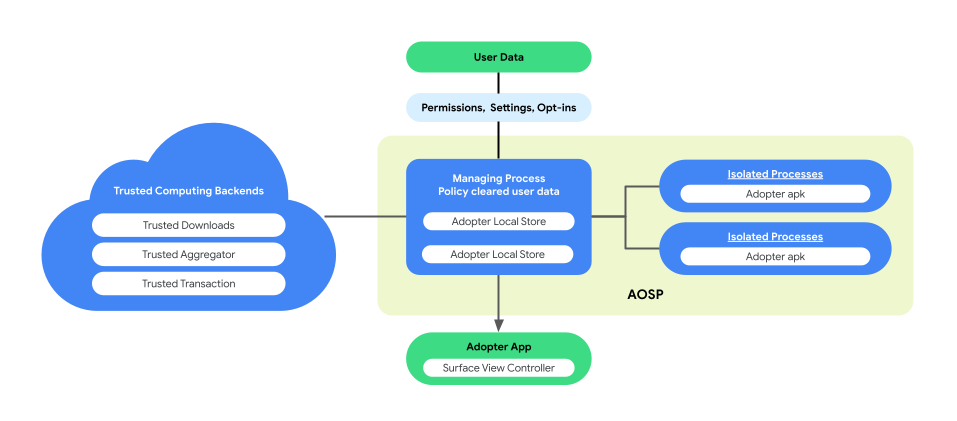
התכונה 'התאמה אישית במכשיר' מציגה ארכיטקטורה של תהליכים משולבים ב-AOSP כדי לשפר את פרטיות המשתמשים ואת אבטחת הנתונים במהלך הביצוע של הלוגיקה העסקית. הארכיטקטורה הזו כוללת:
ManagingProcess. התהליך הזה יוצר ומנהל IsolatedProcesses, ומוודא שהם יישארו מבודדים ברמת התהליך עם גישה מוגבלת לממשקי API שמופיעים ברשימת ההיתרים, וללא הרשאות גישה לרשת או לדיסק. התהליך ManagingProcess מטפל באיסוף של כל הנתונים העסקיים, כל נתוני משתמשי הקצה והמדיניות, מנקה אותם עבור הקוד העסקי ומעביר אותם אל IsolatedProcesses לביצוע. בנוסף, הוא מתווך בין IsolatedProcesses לבין תהליכים אחרים, כמו system_server.
IsolatedProcess. התהליך הזה, שמסומן כמבודד (
isolatedprocess=trueבמניפסט), מקבל נתונים עסקיים, נתוני משתמשי קצה שעברו אישור מדיניות וקוד עסקי מהתהליך ManagingProcess. הם מאפשרים לקוד העסקי לפעול על הנתונים שלו ועל נתוני משתמשי הקצה שעברו אישור מדיניות. ה-IsolatedProcess מתקשר באופן בלעדי עם ה-ManagingProcess גם לגבי תעבורת נכנסת וגם לגבי תעבורת יוצאת, ללא הרשאות נוספות.
ארכיטקטורת התהליכים המקבילים מאפשרת אימות עצמאי של מדיניות הפרטיות של נתוני משתמשי הקצה, בלי לדרוש מהעסקים להפוך את הלוגיקה העסקית או הקוד שלהם לקוד פתוח. הארכיטקטורה הזו מבטיחה פתרון מאובטח ויעיל יותר לשמירה על פרטיות המשתמשים במהלך התאמה אישית, כי התהליך ManagingProcess שומר על העצמאות של IsolatedProcesses, והתהליך IsolatedProcesses מבצע ביעילות את הלוגיקה העסקית.
באיור הבא מוצגת ארכיטקטורת התהליך המותאם.
מדיניות ומנועי מדיניות לפעולות על נתונים
התאמה אישית במכשיר מוסיפה שכבת אכיפת מדיניות בין הפלטפורמה לבין הלוגיקה העסקית. המטרה היא לספק קבוצה של כלים שממפים את אמצעי הבקרה של משתמשי הקצה והעסקים להחלטות מדיניות מרכזיות ופרקטיות. לאחר מכן, המדיניות הזו נאכפת באופן מקיף ואמין בכל התהליכים והעסקים.
בארכיטקטורה של תהליכים מוצמדים, מנוע המדיניות נמצא ב-ManagingProcess, ומפקח על הכניסה והיציאה של נתוני משתמשי הקצה והנתונים העסקיים. הוא גם יספק פעולות ברשימת ההיתרים ל-IsolatedProcess. דוגמאות לתחומים שבהם יש כיסוי: כיבוד אמצעי הבקרה של משתמשי קצה, הגנה על ילדים, מניעת שיתוף נתונים ללא הסכמה ופרטיות עסקית.
ארכיטקטורת אכיפת המדיניות הזו כוללת שלושה סוגים של תהליכי עבודה שאפשר להשתמש בהם:
- תהליכי עבודה אופליין שהופעלו באופן מקומי עם תקשורת של סביבת מחשוב אמינה (TEE):
- תהליכי הורדה של נתונים: הורדות מהימנות
- תהליכי העלאת נתונים: עסקאות מהימנות
- תהליכי עבודה אונליין שמופעלים באופן מקומי:
- תהליכי הצגה בזמן אמת
- תהליכי עבודה של הסקת מסקנות
- תהליכי עבודה אופליין שמופעלים באופן מקומי:
- תהליכי אופטימיזציה: אימון מודלים במכשיר באמצעות למידה מאוחדת (FL)
- תהליכי דיווח: צבירה של נתונים ממכשירים שונים שמוטמעת באמצעות Federated Analytics (FA)
באיור הבא מוצגת הארכיטקטורה מנקודת המבט של מדיניות ומנועי מדיניות.
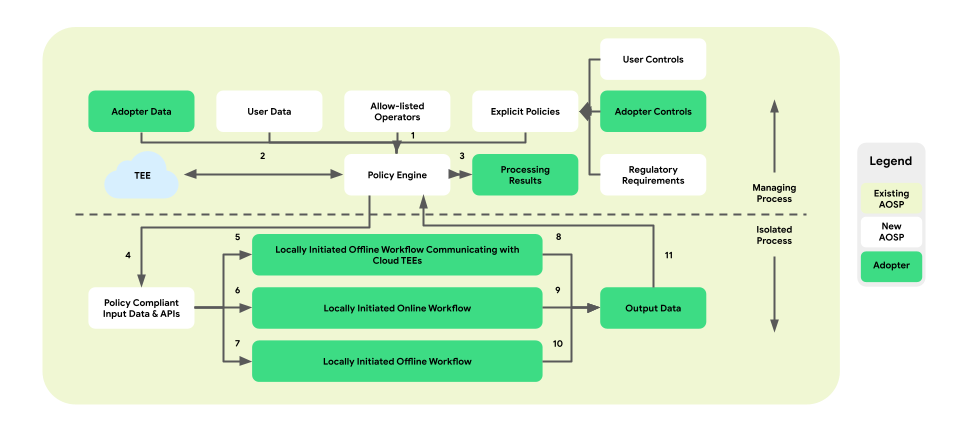
- הורדה: 1 -> 2 -> 4 -> 7 -> 10 -> 11 -> 3
- מנה: 1 + 3 -> 4 -> 6 -> 9 -> 11 -> 3
- אופטימיזציה: 2 (מספקת תוכנית אימונים) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
- דיווח: 3 (מספק תוכנית צבירה) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
בסך הכול, ההוספה של שכבת אכיפת המדיניות ומנוע המדיניות לארכיטקטורת התהליכים המזווגים של התכונה 'התאמה אישית במכשיר' מבטיחה סביבה מבודדת ששומרת על הפרטיות לביצוע לוגיקה עסקית, תוך מתן גישה מבוקרת לנתונים ולפעולות הנדרשים.
פלטפורמות API בשכבות
התכונה On-Device Personalization (התאמה אישית במכשיר) מספקת ארכיטקטורת API בשכבות לעסקים שמתעניינים בה. השכבה העליונה מורכבת מאפליקציות שנוצרו לתרחישי שימוש ספציפיים. עסקים פוטנציאליים יכולים לקשר את הנתונים שלהם לאפליקציות האלה, שנקראות ממשקי API ברמה העליונה. ממשקי API ברמה העליונה מבוססים על ממשקי API ברמה האמצעית.
עם הזמן, אנחנו צפויים להוסיף עוד ממשקי API ברמה העליונה. אם API ברמה העליונה לא זמין לתרחיש שימוש מסוים, או אם ממשקי API קיימים ברמה העליונה לא גמישים מספיק, עסקים יכולים להטמיע ישירות את ממשקי ה-API ברמה האמצעית, שמספקים עוצמה וגמישות באמצעות פרימיטיבים של תכנות.
סיכום
התאמה אישית במכשיר היא הצעה למחקר בשלב מוקדם, שמטרתו לקבל משוב על פתרון לטווח ארוך שנותן מענה לדאגות של משתמשי הקצה בנוגע לפרטיות, באמצעות הטכנולוגיות העדכניות והטובות ביותר, שאמורות לספק תועלת רבה.
אנחנו רוצים לשתף פעולה עם בעלי עניין כמו מומחי פרטיות, אנליסטים של נתונים ומשתמשי קצה פוטנציאליים כדי לוודא ש-ODP עונה על הצרכים שלהם ונותן מענה לחששות שלהם.