
Ten dokument techniczny, który ma być wdrożony w ramach Projektu Android Open Source (AOSP), omawia motywację, która stoi za personalizacją na urządzeniu (ODP), zasady projektowania, które kierują jej rozwojem, model ochrony prywatności oparty na poufności oraz sposób, w jaki pomaga ona zapewnić weryfikowalną prywatność.
Planujemy to osiągnąć przez uproszczenie modelu dostępu do danych i zapewnienie, że wszystkie dane użytkowników, które opuszczają granicę bezpieczeństwa, są różnicowo prywatne na poziomie (użytkownik, osoba korzystająca z usługi, instancja modelu) (w tym dokumencie czasami skracane do poziomu użytkownika).
Cały kod związany z potencjalnym wyciekiem danych użytkowników z ich urządzeń będzie dostępny na licencji open source i możliwy do zweryfikowania przez podmioty zewnętrzne. Na wczesnym etapie naszej propozycji chcemy wzbudzić zainteresowanie i zebrać opinie na temat platformy, która ułatwia personalizację na urządzeniu. Zapraszamy do współpracy zainteresowane strony, takie jak eksperci ds. prywatności, analitycy danych i specjaliści ds. bezpieczeństwa.
Vision
Personalizacja na urządzeniu została zaprojektowana tak, aby chronić informacje użytkowników przed firmami, z którymi nie weszli w interakcję. Firmy mogą nadal dostosowywać swoje produkty i usługi do potrzeb użytkowników (np. za pomocą odpowiednio zanonimizowanych i różnicowo prywatnych modeli uczenia maszynowego), ale nie będą mogły zobaczyć dokładnych dostosowań wprowadzonych dla użytkownika (zależy to nie tylko od reguły dostosowywania wygenerowanej przez właściciela firmy, ale także od indywidualnych preferencji użytkownika), chyba że dojdzie do bezpośrednich interakcji między firmą a użytkownikiem. Jeśli firma tworzy modele uczenia maszynowego lub analizy statystyczne, ODP będzie dbać o to, aby były one odpowiednio anonimizowane za pomocą odpowiednich mechanizmów prywatności różnicowej.
Obecnie planujemy wprowadzać ODP w kilku etapach, obejmujących te funkcje: Zachęcamy też zainteresowane strony do konstruktywnego sugerowania dodatkowych funkcji lub procesów, które mogłyby ułatwić dalsze badanie tego zagadnienia:
- Środowisko piaskownicy, w którym znajduje się i jest wykonywana cała logika biznesowa, co umożliwia wprowadzanie do piaskownicy wielu sygnałów użytkowników, a jednocześnie ogranicza dane wyjściowe.
w pełni szyfrowane magazyny danych:
- ustawienia użytkownika i inne dane z nim związane; Mogą to być dane dostarczone przez użytkownika lub zebrane i wywnioskowane przez firmy, a także ustawienia czasu życia danych (TTL), zasady czyszczenia danych, zasady ochrony prywatności i inne.
- konfiguracje biznesowe, ODP udostępnia algorytmy do kompresowania lub zaciemniania tych danych.
- wyniki przetwarzania biznesowego, Mogą to być:
- są wykorzystywane jako dane wejściowe w późniejszych etapach przetwarzania,
- z szumem dodanym za pomocą odpowiednich mechanizmów prywatności różnicowej i przesyłane do kwalifikujących się punktów końcowych.
- Przesłane za pomocą zaufanego procesu przesyłania do zaufanych środowisk wykonawczych (TEE) z otwartym kodem źródłowym z odpowiednimi centralnymi mechanizmami prywatności różnicowej.
- Wyświetlane użytkownikom.
Interfejsy API zaprojektowane w celu:
- Aktualizuj 2(a) partiami lub stopniowo.
- Okresowo aktualizuj punkt 2(b) w trybie wsadowym lub przyrostowym.
- Przesyłanie 2(c) z odpowiednimi mechanizmami szumu w zaufanych środowiskach agregacji. W kolejnych rundach przetwarzania takie wyniki mogą zostać oznaczone jako 2(b).
Oś czasu
Jest to obecny plan testowy na potrzeby testowania ODP w wersji beta. Harmonogram może ulec zmianie.
| Funkcja | I połowa 2025 roku | III kwartał 2025 r. |
|---|---|---|
| Szkolenie i wnioskowanie na urządzeniu | Skontaktuj się z zespołem Piaskownicy prywatności, aby omówić potencjalne opcje testowania w tym okresie. | Rozpoczynamy wdrażanie na kwalifikujących się urządzeniach z Androidem T+. |
Zasady projektowania
ODP opiera się na 3 filarach: prywatności, uczciwości i użyteczności.
Model danych z wieżami zapewniający lepszą ochronę prywatności
ODP jest zgodny z zasadą Privacy by Design i został zaprojektowany tak, aby domyślnie chronić prywatność użytkowników.
ODP rozważa przeniesienie przetwarzania personalizacji na urządzenie użytkownika. To podejście zapewnia równowagę między prywatnością a użytecznością, ponieważ dane są w jak największym stopniu przechowywane na urządzeniu i przetwarzane poza nim tylko wtedy, gdy jest to konieczne. ODP koncentruje się na:
- Kontrola nad danymi użytkownika na urządzeniu, nawet gdy opuszczają one urządzenie. Miejsca docelowe muszą być poświadczonymi zaufanymi środowiskami wykonawczymi oferowanymi przez dostawców chmury publicznej, w których działa kod napisany w ODP.
- Możliwość weryfikacji przez urządzenie, co się dzieje z danymi użytkownika, jeśli opuszczą urządzenie. ODP udostępnia obciążenia obliczeniowe typu open source i sfederowane, aby koordynować uczenie maszynowe i analizę statystyczną na różnych urządzeniach na potrzeby podmiotów korzystających z tej platformy. Urządzenie użytkownika końcowego potwierdzi, że takie zadania są wykonywane w zaufanych środowiskach wykonawczych bez modyfikacji.
- Gwarantowana techniczna ochrona prywatności (np. agregacja, szum, prywatność różnicowa) danych wyjściowych, które opuszczają kontrolowaną/weryfikowalną granicę urządzenia.
W związku z tym personalizacja będzie dotyczyć konkretnego urządzenia.
Firmy potrzebują też środków ochrony prywatności, które powinny być dostępne na platformie. Oznacza to przechowywanie nieprzetworzonych danych firmowych na odpowiednich serwerach. W tym celu ODP stosuje ten model danych:
- Każde źródło danych pierwotnych będzie przechowywane na urządzeniu lub po stronie serwera, co umożliwi lokalne uczenie i wnioskowanie.
- Udostępnimy algorytmy ułatwiające podejmowanie decyzji na podstawie wielu źródeł danych, np. filtrowanie między 2 różnymi lokalizacjami danych lub trenowanie albo wnioskowanie na podstawie różnych źródeł.
W tym kontekście może istnieć wieża biznesowa i wieża użytkownika:

Wieża użytkownika końcowego składa się z danych przekazywanych przez użytkownika końcowego (np. informacji o koncie i ustawień), zebranych danych związanych z interakcjami użytkownika końcowego z urządzeniem oraz danych pochodnych (np. zainteresowań i preferencji) wywnioskowanych przez firmę. Dane wywnioskowane nie zastępują bezpośrednich deklaracji użytkownika.
Dla porównania w infrastrukturze opartej na chmurze wszystkie nieprzetworzone dane z wieży użytkownika są przesyłane na serwery firm. Z kolei w infrastrukturze skoncentrowanej na urządzeniach wszystkie nieprzetworzone dane z wieży użytkownika końcowego pozostają w miejscu ich pochodzenia, a dane firmy są przechowywane na serwerach.
Personalizacja na urządzeniu łączy zalety obu tych rozwiązań, ponieważ umożliwia przetwarzanie danych, które mogą być powiązane z użytkownikami, w środowiskach TEE przy użyciu bardziej prywatnych kanałów wyjściowych. Do przetwarzania danych wykorzystywany jest tylko atestowany kod open source.
Włączanie społeczeństwa w proces tworzenia sprawiedliwych rozwiązań
Program ODP ma na celu zapewnienie zrównoważonego środowiska dla wszystkich uczestników w różnorodnym ekosystemie. Zdajemy sobie sprawę ze złożoności tego ekosystemu, który składa się z różnych podmiotów oferujących odmienne usługi i produkty.
Aby inspirować innowacje, ODP udostępnia interfejsy API, które mogą być wdrażane przez programistów i reprezentowane przez nich firmy. Personalizacja na urządzeniu ułatwia płynną integrację tych wdrożeń, a jednocześnie umożliwia zarządzanie wersjami, monitorowanie, narzędzia dla programistów i narzędzia do przesyłania opinii. Personalizacja na urządzeniu nie tworzy żadnej konkretnej logiki biznesowej, a raczej służy jako katalizator kreatywności.
Z czasem ODP może oferować więcej algorytmów. Współpraca z ekosystemem jest niezbędna do określenia odpowiedniego poziomu funkcji i ustalenia rozsądnego limitu zasobów urządzenia dla każdej uczestniczącej firmy. Oczekujemy opinii od uczestników ekosystemu, które pomogą nam rozpoznawać i ustalać priorytety nowych przypadków użycia.
Narzędzie dla deweloperów, które pozwala poprawić wrażenia użytkowników
W przypadku ODP nie dochodzi do utraty danych o zdarzeniach ani opóźnień w obserwacjach, ponieważ wszystkie zdarzenia są rejestrowane lokalnie na poziomie urządzenia. Nie ma błędów łączenia, a wszystkie zdarzenia są powiązane z konkretnym urządzeniem. Dzięki temu wszystkie zaobserwowane zdarzenia tworzą naturalną sekwencję chronologiczną odzwierciedlającą interakcje użytkownika.
Ten uproszczony proces eliminuje konieczność łączenia lub przestawiania danych, dzięki czemu dane użytkownika są dostępne niemal w czasie rzeczywistym i bez utraty informacji. Może to z kolei zwiększyć użyteczność, jaką użytkownicy końcowi dostrzegają podczas korzystania z usług i produktów opartych na danych, co może prowadzić do większej satysfakcji i lepszych wrażeń. Dzięki platformie ODP firmy mogą skutecznie dostosowywać się do potrzeb użytkowników.
Model prywatności: prywatność dzięki poufności
W kolejnych sekcjach omówimy model konsument–producent jako podstawę tej analizy prywatności oraz prywatność środowiska obliczeniowego w porównaniu z dokładnością danych wyjściowych.
Model konsument–producent jako podstawa analizy prywatności
Aby zbadać gwarancje prywatności w ramach ochrony poufności, zastosujemy model konsumenta i producenta. Obliczenia w tym modelu są reprezentowane jako węzły w skierowanym grafie acyklicznym (DAG), który składa się z węzłów i podgrafów. Każdy węzeł obliczeniowy ma 3 komponenty: dane wejściowe, dane wyjściowe i mapowanie obliczeń danych wejściowych na dane wyjściowe.

W tym modelu ochrona prywatności obejmuje wszystkie 3 komponenty:
- Prywatność danych wejściowych Węzły mogą mieć 2 rodzaje danych wejściowych. Jeśli dane wejściowe są generowane przez węzeł poprzedzający, mają już gwarancje prywatności danych wyjściowych tego węzła. W innych przypadkach dane wejściowe muszą być zgodne z zasadami dotyczącymi wprowadzania danych za pomocą silnika zasad.
- Prywatność danych wyjściowych Dane wyjściowe mogą wymagać ochrony prywatności, np. takiej, jaką zapewnia prywatność różnicowa.
- Poufność środowiska obliczeniowego. Obliczenia muszą być przeprowadzane w bezpiecznym środowisku, które uniemożliwia dostęp do stanów pośrednich w węźle. Technologie, które to umożliwiają, to m.in. obliczenia federacyjne (FC), sprzętowe zaufane środowiska wykonawcze (TEE), bezpieczne obliczenia wielostronne (sMPC) i szyfrowanie homomorficzne (HPE). Warto zauważyć, że prywatność za pomocą zabezpieczeń poufności stanów pośrednich i wszystkich danych wyjściowych wychodzących poza granicę poufności nadal musi być chroniona przez mechanizmy prywatności różnicowej. Wymagane są 2 rodzaje roszczeń:
- poufność środowisk, dzięki której tylko zadeklarowane dane wyjściowe opuszczają środowisko;
- rzetelność, która umożliwia dokładne wyciąganie wniosków dotyczących ochrony prywatności danych wyjściowych na podstawie ochrony prywatności danych wejściowych; Prawidłowość umożliwia propagowanie właściwości prywatności w dół DAG.
System prywatny zapewnia prywatność danych wejściowych, poufność środowiska obliczeniowego i prywatność danych wyjściowych. Liczbę zastosowań mechanizmów ochrony prywatności przez zróżnicowanie można jednak zmniejszyć, zamykając więcej procesów w środowisku obliczeń poufnych.
Ten model ma 2 główne zalety. Po pierwsze, większość systemów, zarówno dużych, jak i małych, można przedstawić jako DAG. Po drugie, właściwości przetwarzania końcowego i kompozycji prywatności różnicowej (DP) (lemat 2.4 w artykule „The Complexity of Differential Privacy”) zapewniają skuteczne narzędzia do analizowania (w najgorszym przypadku) kompromisu między prywatnością a dokładnością w przypadku całego wykresu:
- Przetwarzanie końcowe gwarantuje, że po sprywatyzowaniu ilości nie można jej „odprywatyzować”, jeśli oryginalne dane nie zostaną ponownie użyte. Dopóki wszystkie dane wejściowe węzła są prywatne, jego dane wyjściowe są prywatne niezależnie od obliczeń.
- Zaawansowane komponowanie gwarantuje, że jeśli każda część wykresu jest DP, to cały wykres również jest DP, co skutecznie ogranicza wartości ε i δ końcowego wyniku wykresu o wartość około ε√κ, przy założeniu, że wykres ma κ jednostek, a wynik każdej jednostki jest (ε, δ)-DP.
Te 2 właściwości przekładają się na 2 zasady projektowania każdego węzła:
- Usługa 1 (z przetwarzania końcowego) jeśli dane wejściowe węzła są w całości DP, jego dane wyjściowe są DP, co umożliwia obsługę dowolnej logiki biznesowej wykonywanej w węźle i wspiera „tajne receptury” firm.
- Właściwość 2 (z kompozycji zaawansowanej): jeśli dane wejściowe węzła nie są w całości DP, jego dane wyjściowe muszą być zgodne z DP. Jeśli węzeł obliczeniowy działa w środowiskach Trusted Execution Environments i wykonuje zadania oraz konfiguracje dostarczone przez open source’ową personalizację na urządzeniu, można zastosować bardziej rygorystyczne ograniczenia DP. W przeciwnym razie personalizacja na urządzeniu może wymagać użycia najgorszych możliwych wartości DP. Ze względu na ograniczenia zasobów początkowo będą traktowane priorytetowo środowiska Trusted Execution Environment oferowane przez dostawcę chmury publicznej.
Prywatność środowiska obliczeniowego a dokładność danych wyjściowych
Od tej pory personalizacja na urządzeniu będzie koncentrować się na zwiększaniu bezpieczeństwa środowisk obliczeń poufnych i zapewnianiu, że stany pośrednie pozostaną niedostępne. Ten proces zabezpieczeń, zwany uszczelnianiem, będzie stosowany na poziomie podgrafu, co umożliwi jednoczesne zapewnienie zgodności z DP wielu węzłów. Oznacza to, że wspomniane wcześniej właściwość 1 i właściwość 2 mają zastosowanie na poziomie podgrafu.

Oczywiście ostateczne dane wyjściowe grafu, czyli dane wyjściowe 7, są chronione za pomocą DP zgodnie z kompozycją. Oznacza to, że na tym wykresie będą 2 wartości DP, w porównaniu z 3 wartościami DP (lokalnymi), gdyby nie zastosowano uszczelniania.
Zabezpieczenie środowiska obliczeniowego i wyeliminowanie możliwości uzyskania przez przeciwników dostępu do danych wejściowych i stanów pośrednich wykresu lub podgrafu umożliwia wdrożenie centralnego DP (czyli dane wyjściowe z zabezpieczonego środowiska są zgodne z DP), co może zwiększyć dokładność w porównaniu z lokalnym DP (czyli poszczególne dane wejściowe są zgodne z DP). Ta zasada jest podstawą uznawania FC, TEE, sMPC i HPE za technologie chroniące prywatność. Zapoznaj się z rozdziałem 10 w książce The Complexity of Differential Privacy.
Dobrym, praktycznym przykładem jest trenowanie modeli i wnioskowanie. Poniższe rozważania zakładają, że (1) populacja trenująca i populacja wnioskowania pokrywają się oraz (2) zarówno cechy, jak i etykiety stanowią prywatne dane użytkownika. Możemy zastosować DP do wszystkich danych wejściowych:

Personalizacja na urządzeniu może stosować lokalną ochronę prywatności przez zróżnicowanie przed wysłaniem etykiet i funkcji użytkownika na serwery. To podejście nie nakłada żadnych wymagań na środowisko wykonawcze serwera ani na jego logikę biznesową.



Tak wygląda obecnie personalizacja na urządzeniu.
Weryfikowalna prywatność
Personalizacja na urządzeniu ma być weryfikowalnie prywatna. Skupia się na weryfikacji tego, co dzieje się poza urządzeniami użytkowników. ODP utworzy kod, który przetwarza dane opuszczające urządzenia użytkowników, i użyje architektury procedur zdalnego potwierdzania (RATS) RFC 9334 NIST, aby potwierdzić, że ten kod działa bez modyfikacji na serwerze zgodnym z Confidential Computing Consortium, z ograniczonymi uprawnieniami administratora instancji. Kody te będą dostępne na zasadach open source i będzie można je przejrzyście weryfikować, aby budować zaufanie. Takie środki mogą dać osobom fizycznym pewność, że ich dane są chronione, a firmy mogą budować reputację na solidnych podstawach zapewniających ochronę prywatności.
Zmniejszenie ilości zbieranych i przechowywanych danych prywatnych to kolejny kluczowy aspekt personalizacji na urządzeniu. Jest to możliwe dzięki zastosowaniu technologii takich jak obliczenia sfederowane i prywatność różnicowa, które umożliwiają ujawnianie cennych wzorców danych bez ujawniania poufnych szczegółów dotyczących poszczególnych osób ani informacji umożliwiających ich identyfikację.
Prowadzenie ścieżki audytu, która rejestruje działania związane z przetwarzaniem i udostępnianiem danych, to kolejny kluczowy aspekt weryfikowalnej prywatności. Umożliwia to tworzenie raportów kontrolnych i identyfikowanie luk w zabezpieczeniach, co pokazuje nasze zaangażowanie w ochronę prywatności.
Prosimy ekspertów ds. prywatności, organy, branże i osoby fizyczne o konstruktywną współpracę, która pomoże nam stale ulepszać projekty i wdrażanie.
Poniższy wykres przedstawia ścieżkę kodu dla agregacji i dodawania szumu na różnych urządzeniach zgodnie z zasadami prywatności różnicowej.
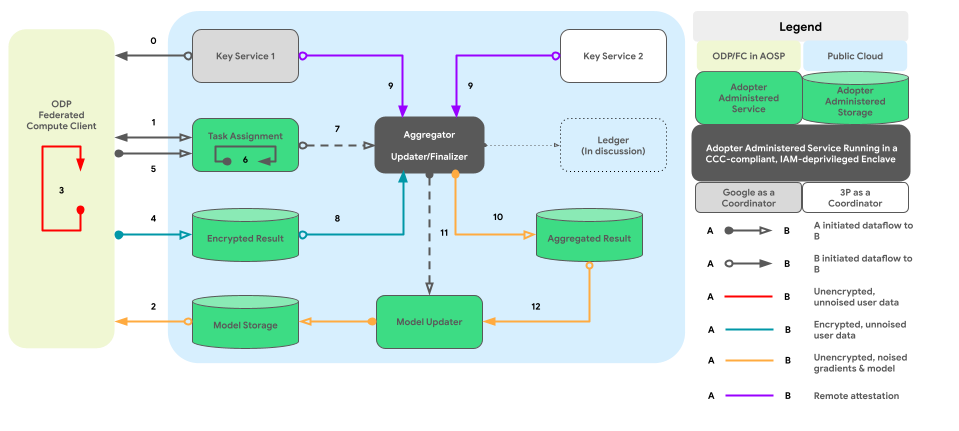
Projekt wysokiego poziomu
Jak można wdrożyć ochronę prywatności przez zachowanie poufności? Ogólnie rzecz biorąc, silnik zasad utworzony przez ODP, który działa w zamkniętym środowisku, jest podstawowym komponentem nadzorującym każdy węzeł lub podgraf i śledzącym stan ochrony danych jego danych wejściowych i wyjściowych:
- Z perspektywy silnika zasad urządzenia i serwery są traktowane tak samo. Urządzenia i serwery z identycznym silnikiem zasad są uważane za logicznie identyczne po wzajemnym potwierdzeniu ich silników zasad.
- Na urządzeniach izolacja jest osiągana za pomocą odseparowanych procesów AOSP (lub w przyszłości za pomocą pKVM, gdy ta funkcja będzie powszechnie dostępna). W przypadku serwerów izolacja opiera się na „zaufanej stronie”, którą może być preferowane środowisko TEE wraz z innymi technicznymi rozwiązaniami zabezpieczającymi, umowa lub oba te elementy.
Innymi słowy, wszystkie środowiska zamknięte, w których instalowany jest i działa silnik zasad platformy, są uważane za część naszej bazy zaufanych obliczeń (TCB). Dane mogą być propagowane bez dodatkowego szumu za pomocą TCB. DP musi być stosowane, gdy dane opuszczają TCB.
Ogólna koncepcja personalizacji na urządzeniu skutecznie integruje 2 niezbędne elementy:
- Architektura procesów sparowanych do wykonywania logiki biznesowej
- Zasady i silnik zasad do zarządzania danymi przychodzącymi, wychodzącymi i dozwolonymi operacjami.
Ta spójna konstrukcja zapewnia firmom równe szanse, ponieważ mogą one uruchamiać własny kod w zaufanym środowisku wykonawczym i uzyskiwać dostęp do danych użytkowników, które przeszły odpowiednie kontrole zgodności z zasadami.
W sekcjach poniżej znajdziesz więcej informacji o tych 2 kluczowych aspektach.
Architektura procesów sparowanych do wykonywania logiki biznesowej
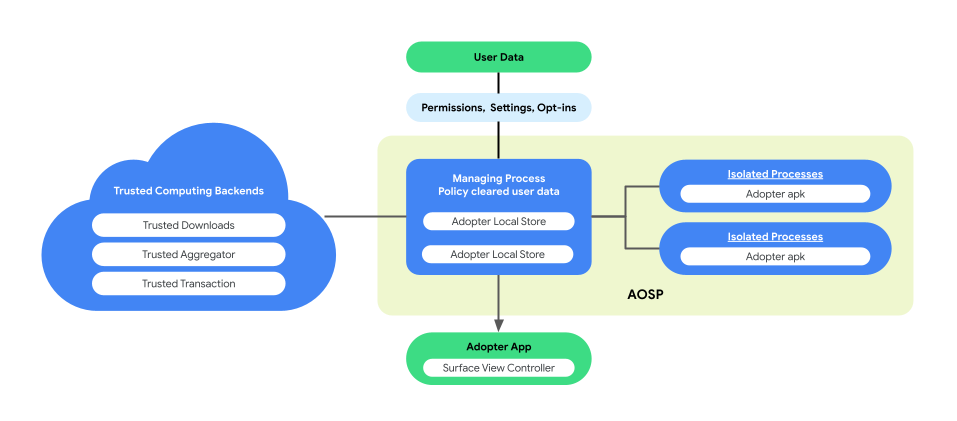
Personalizacja na urządzeniu wprowadza w AOSP architekturę z procesem sparowanym, aby zwiększyć prywatność użytkowników i bezpieczeństwo danych podczas wykonywania logiki biznesowej. Ta architektura składa się z:
ManagingProcess. Ten proces tworzy i zarządza elementami IsolatedProcess, zapewniając ich izolację na poziomie procesu z dostępem ograniczonym do interfejsów API z listy dozwolonych oraz bez uprawnień do sieci i dysku. Proces zarządzania (ManagingProcess) odpowiada za zbieranie wszystkich danych firmowych, wszystkich danych użytkowników i zasad, a także za ich czyszczenie na potrzeby kodu firmy i przesyłanie do procesów izolowanych (IsolatedProcesses) w celu wykonania. Poza tym pośredniczy w interakcjach między procesami odizolowanymi a innymi procesami, np. system_server.
IsolatedProcess. Oznaczony jako odizolowany (
isolatedprocess=truew pliku manifestu), ten proces otrzymuje dane biznesowe, dane użytkowników końcowych po sprawdzeniu zgodności z zasadami oraz kod biznesowy z procesu zarządzającego. Umożliwiają one kodowi firmy działanie na jej danych i danych użytkowników, które zostały sprawdzone pod kątem zgodności z zasadami. Proces odizolowany komunikuje się wyłącznie z procesem zarządzającym w przypadku ruchu przychodzącego i wychodzącego, bez dodatkowych uprawnień.
Architektura procesów w parach umożliwia niezależną weryfikację zasad ochrony prywatności danych użytkowników bez konieczności udostępniania przez firmy kodu źródłowego logiki biznesowej. Dzięki temu, że proces zarządzający zachowuje niezależność procesów izolowanych, a procesy izolowane skutecznie wykonują logikę biznesową, ta architektura zapewnia bezpieczniejsze i wydajniejsze rozwiązanie do ochrony prywatności użytkowników podczas personalizacji.
Na ilustracji poniżej przedstawiono architekturę tego procesu.
Zasady i mechanizmy zasad dotyczące operacji na danych
Personalizacja na urządzeniu wprowadza warstwę egzekwowania zasad między platformą a logiką biznesową. Celem jest udostępnienie zestawu narzędzi, które mapują ustawienia użytkowników i firm na scentralizowane i wykonalne decyzje dotyczące zasad. Te zasady są następnie kompleksowo i wiarygodnie egzekwowane w przypadku różnych procesów i firm.
W architekturze z procesami w parach silnik zasad znajduje się w procesie zarządzającym, który nadzoruje przepływ danych użytkowników i firm. Będzie też dostarczać do IsolatedProcess operacje z listy dozwolonych. Przykładowe obszary obejmujące te zasady to m.in. respektowanie kontroli użytkownika, ochrona dzieci, zapobieganie udostępnianiu danych bez zgody użytkownika oraz prywatność firm.
Ta architektura egzekwowania zasad obejmuje 3 rodzaje przepływów pracy, z których można korzystać:
- Lokalnie inicjowane przepływy pracy offline z komunikacją w zaufanym środowisku wykonawczym (TEE):
- Przepływy pobierania danych: zaufane pobierania
- Procesy przesyłania danych: zaufane transakcje
- Lokalnie inicjowane przepływy pracy online:
- Schematy wyświetlania w czasie rzeczywistym
- Przepływy wnioskowania
- Lokalnie inicjowane przepływy pracy offline:
- Procesy optymalizacji: trenowanie modeli na urządzeniu zaimplementowane za pomocą uczenia sfederowanego (FL)
- Procesy raportowania: agregacja danych z różnych urządzeń zaimplementowana za pomocą analizy federacyjnej
Na poniższym rysunku przedstawiono architekturę z perspektywy zasad i silników zasad.
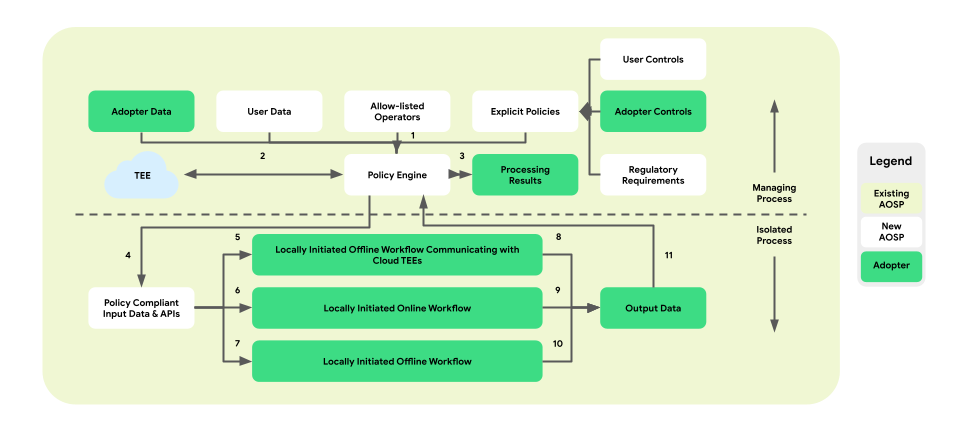
- Pobieranie: 1 –> 2 –> 4 –> 7 –> 10 –> 11 –> 3
- Obsługa: 1 + 3 → 4 → 6 → 9 → 11 → 3
- Optymalizacja: 2 (zapewnia plan treningowy) –> 1 + 3 –> 4 –> 5 –> 8 –> 11 –> 2
- Raportowanie: 3 (zapewnia plan agregacji) –> 1 + 3 –> 4 –> 5 –> 8 –> 11 –> 2
Ogólnie rzecz biorąc, wprowadzenie warstwy egzekwowania zasad i silnika zasad w architekturze sparowanych procesów personalizacji na urządzeniu zapewnia odizolowane i chroniące prywatność środowisko do wykonywania logiki biznesowej, a jednocześnie kontrolowany dostęp do niezbędnych danych i operacji.
Warstwowe interfejsy API
Interfejs On-Device Personalization udostępnia wielowarstwową architekturę interfejsu API dla zainteresowanych firm. Najwyższa warstwa to aplikacje stworzone z myślą o konkretnych zastosowaniach. Potencjalne firmy mogą łączyć swoje dane z tymi aplikacjami, które są znane jako interfejsy API najwyższego poziomu. Interfejsy API najwyższej warstwy są oparte na interfejsach API warstwy środkowej.
Z czasem planujemy dodać więcej interfejsów API najwyższego poziomu. Jeśli interfejs API najwyższej warstwy nie jest dostępny w określonym przypadku użycia lub jeśli istniejące interfejsy API najwyższej warstwy nie są wystarczająco elastyczne, firmy mogą bezpośrednio implementować interfejsy API warstwy środkowej, które zapewniają moc i elastyczność dzięki prymitywom programowania.
Podsumowanie
Personalizacja na urządzeniu to propozycja badawcza na wczesnym etapie, która ma na celu wzbudzenie zainteresowania i zebranie opinii na temat długoterminowego rozwiązania, które za pomocą najnowszych i najlepszych technologii ma zaspokajać obawy użytkowników dotyczące prywatności i zapewniać im dużą użyteczność.
Chcemy nawiązać współpracę z zainteresowanymi podmiotami, takimi jak eksperci ds. prywatności, analitycy danych i potencjalni użytkownicy, aby mieć pewność, że ODP spełnia ich potrzeby i odpowiada na ich obawy.