
Данный технический обзор, предназначенный для реализации в проекте Android Open Source Project (AOSP) , рассматривает мотивацию, лежащую в основе персонализации на устройстве (ODP), принципы проектирования, которыми руководствуется ее разработка, модель обеспечения конфиденциальности и то, как она помогает гарантировать проверяемую приватность.
Мы планируем достичь этого путем упрощения модели доступа к данным и обеспечения того, чтобы все пользовательские данные, покидающие зону безопасности, были дифференцированно приватными на уровне каждого (пользователя, пользователя, экземпляра модели) уровня (иногда сокращенно называемого уровнем пользователя в этом документе).
Весь код, связанный с потенциальным исходящим трафиком данных конечных пользователей с их устройств, будет иметь открытый исходный код и будет доступен для проверки внешними организациями. На ранних этапах разработки нашего предложения мы стремимся вызвать интерес и собрать отзывы о платформе, которая способствует персонализации на устройстве. Мы приглашаем к сотрудничеству заинтересованных лиц, таких как эксперты по вопросам конфиденциальности, аналитики данных и специалисты по безопасности.
Зрение
Персонализация на устройстве (ODP) предназначена для защиты информации конечных пользователей от компаний, с которыми они не взаимодействовали. Компании могут продолжать персонализировать свои продукты и услуги для конечных пользователей (например, используя модели машинного обучения с соответствующей анонимизацией и дифференциальной конфиденциальностью), но они не смогут увидеть точные настройки, сделанные для конечного пользователя (это зависит не только от правила персонализации, созданного владельцем компании, но и от индивидуальных предпочтений конечного пользователя), если нет прямого взаимодействия между компанией и конечным пользователем. Если компания создает какие-либо модели машинного обучения или проводит статистический анализ, ODP будет стремиться обеспечить их надлежащую анонимизацию с использованием соответствующих механизмов дифференциальной конфиденциальности.
В настоящее время мы планируем поэтапно изучать ODP, охватывая следующие функции и возможности. Мы также приглашаем заинтересованные стороны конструктивно предлагать любые дополнительные функции или рабочие процессы для дальнейшего изучения:
- Изолированная среда, в которой содержится и выполняется вся бизнес-логика, позволяющая множеству сигналов от конечных пользователей поступать в эту среду, но ограничивающая выходные данные.
Хранилища данных с сквозным шифрованием для:
- Пользовательские настройки и другие данные, связанные с пользователем. Эти данные могут быть предоставлены конечным пользователем или собраны и получены компаниями путем анализа, наряду с настройками времени жизни (TTL), политиками удаления, политиками конфиденциальности и многим другим.
- Конфигурации бизнес-процессов. ODP предоставляет алгоритмы для сжатия или обфускации этих данных.
- Результаты обработки бизнес-процессов. Эти результаты могут быть следующими:
- Используется в качестве входных данных на последующих этапах обработки.
- Шум, создаваемый с помощью соответствующих механизмов дифференциальной конфиденциальности, загружается на соответствующие конечные точки.
- Загрузка осуществляется с использованием доверенного процесса загрузки в доверенные среды выполнения (TEE), работающие с рабочими нагрузками с открытым исходным кодом и соответствующими централизованными механизмами дифференциальной конфиденциальности.
- Демонстрируется конечным пользователям.
API, предназначенные для:
- Обновление 2(а), пакетное или поэтапное.
- Периодически обновляйте пункт 2(b), пакетно или поэтапно.
- Загрузите 2(c) с соответствующими механизмами шумоподавления в надежных средах агрегации. Такие результаты могут стать 2(b) для следующих раундов обработки.
Хронология
Это текущий план тестирования ODP в бета-версии. Сроки могут быть изменены.
| Особенность | H1 2025 | 3 квартал 2025 г. |
|---|---|---|
| Обучение и вывод результатов непосредственно на устройстве | Обратитесь к команде Privacy Sandbox, чтобы обсудить возможные варианты пилотного внедрения в течение этого периода времени. | Начинается развертывание на соответствующих устройствах Android T+. |
Принципы проектирования
ODP стремится сбалансировать три основных принципа: конфиденциальность, справедливость и полезность.
Многоуровневая модель данных для повышения уровня защиты конфиденциальности
ODP следует принципу «защита конфиденциальности на этапе проектирования» и разработан с учетом защиты конфиденциальности конечного пользователя по умолчанию.
ODP рассматривает возможность переноса обработки персонализированных данных на устройство конечного пользователя. Такой подход обеспечивает баланс между конфиденциальностью и полезностью, сохраняя данные на устройстве как можно больше и обрабатывая их вне устройства только при необходимости. ODP фокусируется на:
- Контроль над данными конечного пользователя устройством, даже когда они покидают устройство. Для обеспечения безопасности получателей данных необходимо использовать подтвержденные доверенные среды выполнения (Trusted Execution Environments), предоставляемые публичными облачными провайдерами, работающими с кодом, разработанным в рамках ODP.
- Проверка подлинности данных конечного пользователя после их передачи за пределы устройства. ODP предоставляет рабочие нагрузки с открытым исходным кодом и федеративными вычислениями для координации машинного обучения и статистического анализа на разных устройствах для своих пользователей. Устройство конечного пользователя подтвердит, что такие рабочие нагрузки выполняются в доверенных средах выполнения без изменений.
- Гарантированная техническая конфиденциальность (например, агрегирование, шум, дифференциальная конфиденциальность) выходных данных, выходящих за пределы контролируемой/проверяемой устройством границы.
Следовательно, персонализация будет зависеть от конкретного устройства.
Кроме того, предприятиям также необходимы меры по обеспечению конфиденциальности, которые платформа должна учитывать. Это подразумевает хранение исходных бизнес-данных на собственных серверах. Для достижения этой цели ODP использует следующую модель данных:
- Каждый исходный источник данных будет храниться либо на устройстве, либо на сервере, что позволит проводить локальное обучение и делать выводы.
- Мы предоставим алгоритмы для облегчения принятия решений на основе множества источников данных, например, для фильтрации между двумя различными источниками данных или для обучения или вывода результатов из различных источников.
В этом контексте может существовать бизнес-подразделение и подразделение конечных пользователей:
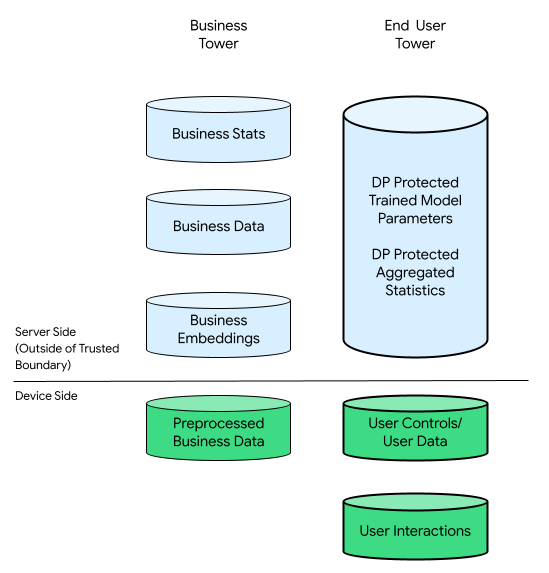
Пользовательский интерфейс включает в себя данные, предоставленные конечным пользователем (например, информацию об учетной записи и элементы управления), собранные данные, связанные с взаимодействием конечного пользователя с его устройством, и производные данные (например, интересы и предпочтения), полученные компанией на основе анализа. Полученные данные не заменяют прямые заявления пользователя.
Для сравнения, в облачно-ориентированной инфраструктуре все необработанные данные с сервера конечного пользователя передаются на серверы компании. В свою очередь, в инфраструктуре, ориентированной на устройства, все необработанные данные с сервера конечного пользователя остаются на исходном сервере, а данные компании хранятся на серверах.
Персонализация на устройстве сочетает в себе лучшие стороны обоих подходов, позволяя обрабатывать данные, имеющие потенциальную связь с конечными пользователями в рамках TEE, только проверенному коду с открытым исходным кодом, используя более приватные каналы вывода.
Инклюзивное вовлечение общественности для поиска справедливых решений.
Цель ODP — обеспечить сбалансированную среду для всех участников в рамках разнообразной экосистемы. Мы признаем сложность этой экосистемы, состоящей из различных игроков, предлагающих уникальные услуги и продукты.
Для стимулирования инноваций ODP предлагает API, которые могут быть реализованы разработчиками и компаниями, которые они представляют. Персонализация на устройстве обеспечивает бесшовную интеграцию этих реализаций, одновременно управляя релизами, мониторингом, инструментами для разработчиков и инструментами обратной связи. Персонализация на устройстве не создает никакой конкретной бизнес-логики ; скорее, она служит катализатором творчества.
Со временем ODP может предложить больше алгоритмов. Сотрудничество с экосистемой имеет важное значение для определения оптимального уровня функциональности и, возможно, установления разумного ограничения на использование ресурсов устройства для каждого участвующего предприятия. Мы ожидаем обратной связи от экосистемы, которая поможет нам выявлять и расставлять приоритеты для новых вариантов использования.
Утилиты для разработчиков, улучшающие пользовательский опыт.
При использовании ODP отсутствует потеря данных о событиях и задержки наблюдения, поскольку все события записываются локально на уровне устройства. Отсутствуют ошибки объединения, и все события связаны с конкретным устройством. В результате все наблюдаемые события естественным образом образуют хронологическую последовательность, отражающую взаимодействие пользователя.
Этот упрощенный процесс исключает необходимость объединения или перегруппировки данных, обеспечивая доступ к пользовательским данным практически в режиме реального времени и без потери данных. В свою очередь, это может повысить удобство использования продуктов и услуг, основанных на данных, для конечных пользователей, что потенциально приведет к повышению уровня удовлетворенности и более значимому опыту. С помощью ODP предприятия могут эффективно адаптироваться к потребностям своих пользователей.
Модель конфиденциальности: конфиденциальность через секретность
В следующих разделах рассматривается модель «потребитель-производитель» как основа данного анализа конфиденциальности, а также взаимосвязь конфиденциальности в вычислительной среде и точности выходных данных.
Модель «потребитель-производитель» лежит в основе данного анализа конфиденциальности.
Мы будем использовать модель «потребитель-производитель» для изучения гарантий конфиденциальности посредством обеспечения защиты персональных данных. Вычисления в этой модели представлены в виде узлов в ориентированном ациклическом графе (DAG), состоящем из узлов и подграфов. Каждый вычислительный узел имеет три компонента: потребляемые входные данные, производимые выходные данные и отображение входных данных на выходные данные.

В данной модели защита конфиденциальности распространяется на все три компонента:
- Конфиденциальность входных данных . Узлы могут иметь два типа входных данных. Если входные данные генерируются предшествующим узлом, они уже обладают гарантиями конфиденциальности выходных данных этого предшествующего узла. В противном случае, входные данные должны очищать политики входящего трафика с помощью механизма политик .
- Конфиденциальность выходных данных . Возможно, потребуется обеспечить конфиденциальность выходных данных, например, с помощью механизма дифференциальной конфиденциальности (DP).
- Конфиденциальность вычислительной среды . Вычисления должны происходить в надежно защищенной среде, гарантирующей, что никто не имеет доступа к промежуточным состояниям внутри узла. Технологии, обеспечивающие это, включают федеративные вычисления (FC), аппаратные доверенные среды выполнения (TEE), безопасные многосторонние вычисления (sMPC), гомоморфное шифрование (HPE) и другие. Стоит отметить, что конфиденциальность обеспечивает защиту промежуточных состояний, и все выходные данные, выходящие за пределы зоны конфиденциальности, должны быть защищены механизмами дифференциальной конфиденциальности. Необходимы два утверждения:
- Конфиденциальность окружающей среды, гарантирующая, что из окружающей среды покидают только заявленные результаты.
- Обоснованность позволяет точно выводить утверждения о конфиденциальности на выходе из утверждений о конфиденциальности на входе. Обоснованность позволяет распространять свойства конфиденциальности вниз по направленному ациклическому графу (DAG).
Закрытая система обеспечивает конфиденциальность входных данных, конфиденциальность вычислительной среды и конфиденциальность выходных данных. Однако количество применений механизмов дифференциальной конфиденциальности может быть уменьшено за счет изоляции большей части обработки данных внутри конфиденциальной вычислительной среды.
Эта модель предлагает два основных преимущества. Во-первых, большинство систем, больших и малых, могут быть представлены в виде направленного ациклического графа (DAG). Во-вторых, постобработка DP [Раздел 2.1] и лемма 2.4 о композиции в работе «Сложность дифференциальной конфиденциальности » предоставляют мощные инструменты для анализа компромисса между конфиденциальностью и точностью (в наихудшем случае) для всего графа:
- Постобработка гарантирует, что после приватизации величины её нельзя будет «разблокировать», если исходные данные больше не используются. Пока все входные данные узла приватны, его выходные данные также приватны, независимо от выполняемых вычислений.
- Расширенная композиция гарантирует, что если каждая часть графа является DP, то и весь граф в целом также является DP, фактически ограничивая ε и δ конечного результата графа приблизительно ε√κ соответственно, при условии, что граф имеет κ единиц, а результат каждой единицы равен (ε, δ)-DP .
Эти два свойства приводят к двум принципам проектирования для каждого узла:
- Свойство 1 (из постобработки): если все входы узла являются динамическими представлениями (DP), то и его выход будет динамическим представлением (DP), что позволяет выполнять любую произвольную бизнес-логику в узле и поддерживает «секретные рецепты» бизнеса.
- Свойство 2 (из раздела «Расширенная композиция»): если не все входные данные узла соответствуют требованиям DP, его выходные данные должны соответствовать требованиям DP. Если вычислительный узел работает в доверенных средах выполнения и выполняет рабочие нагрузки и конфигурации с открытым исходным кодом, предоставляемые службой персонализации на устройстве, то возможны более жесткие ограничения DP. В противном случае службе персонализации на устройстве может потребоваться использовать ограничения DP наихудшего случая. Из-за ограниченности ресурсов первоначальный приоритет будет отдаваться доверенным средам выполнения, предоставляемым публичным облачным провайдером.
Конфиденциальность вычислительной среды против точности выходных данных
Отныне персонализация на устройстве будет сосредоточена на повышении безопасности конфиденциальных вычислительных сред и обеспечении недоступности промежуточных состояний. Этот процесс обеспечения безопасности, известный как «запечатывание», будет применяться на уровне подграфа, позволяя одновременно сделать совместимыми с DP несколько узлов. Это означает, что упомянутые ранее свойства 1 и 2 применяются на уровне подграфа.

Разумеется, итоговый график, вывод 7, обрабатывается методом динамического программирования (ДП) для каждого состава. Это означает, что для этого графика будет всего 2 ДП; по сравнению с 3 общими (локальными) ДП, если бы герметизация не использовалась.
По сути, обеспечивая безопасность вычислительной среды и исключая возможности доступа злоумышленников к входным данным и промежуточным состояниям графа или подграфа, это позволяет реализовать централизованную дифференциальную конфиденциальность (то есть, выходные данные в закрытой среде соответствуют требованиям дифференциальной конфиденциальности), что может повысить точность по сравнению с локальной дифференциальной конфиденциальностью (то есть, отдельные входные данные соответствуют требованиям дифференциальной конфиденциальности). Этот принцип лежит в основе рассмотрения FC, TEE, sMPC и HPE в качестве технологий обеспечения конфиденциальности. См. главу 10 в книге «Сложность дифференциальной конфиденциальности» .
Хороший практический пример — обучение модели и вывод результатов. В дальнейшем обсуждении предполагается, что (1) обучающая выборка и выборка для вывода результатов перекрываются, и (2) как признаки, так и метки представляют собой частные пользовательские данные. Мы можем применять DP ко всем входным данным:

Персонализация на устройстве позволяет применять локальные данные о местоположении к меткам и характеристикам пользователя перед отправкой их на серверы. Такой подход не накладывает никаких требований на среду выполнения сервера или его бизнес-логику.



Это текущий вариант персонализации на устройстве.
Подтвержденная конфиденциальность
Персонализация на устройстве (ODP) направлена на обеспечение проверяемой конфиденциальности. Она фокусируется на проверке того, что происходит за пределами пользовательских устройств. ODP будет разрабатывать код, обрабатывающий данные, покидающие устройства конечных пользователей, и будет использовать архитектуру удаленной аттестации (RATS) RFC 9334 NIST для подтверждения того, что этот код выполняется без изменений на сервере с ограниченными правами администратора, соответствующем стандартам Консорциума конфиденциальных вычислений (Confidential Computing Consortium). Эти коды будут иметь открытый исходный код и будут доступны для прозрачной проверки, что позволит укрепить доверие. Такие меры могут дать людям уверенность в защите их данных, а предприятиям — создать репутацию, основанную на надежной гарантии конфиденциальности.
Сокращение объема собираемых и хранимых личных данных — еще один важный аспект персонализации на устройстве. Этот принцип реализуется с помощью таких технологий, как федеративные вычисления и дифференциальная конфиденциальность, что позволяет выявлять ценные закономерности в данных, не раскрывая конфиденциальную информацию об отдельных лицах или идентифицируемые сведения.
Ведение журнала аудита, регистрирующего действия, связанные с обработкой и обменом данными, является еще одним ключевым аспектом проверяемой конфиденциальности. Это позволяет создавать аудиторские отчеты и выявлять уязвимости, демонстрируя нашу приверженность принципам конфиденциальности.
Мы просим экспертов по вопросам конфиденциальности, представителей органов власти, отраслей промышленности и отдельных лиц о конструктивном сотрудничестве, чтобы помочь нам постоянно совершенствовать разработку и внедрение этих решений.
На следующем графике показан путь выполнения кода для агрегирования данных между устройствами и шумоподавления в соответствии с принципом дифференциальной конфиденциальности.
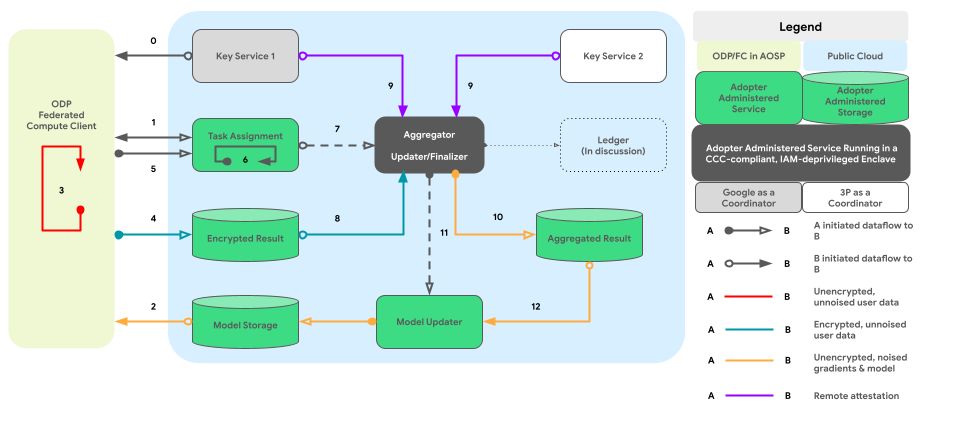
Проектирование высокого уровня
Как можно реализовать конфиденциальность посредством обеспечения секретности? В общих чертах, механизм политик, разработанный ODP и работающий в закрытой среде, служит основным компонентом, контролирующим каждый узел/подграф и отслеживающим статус DP их входных и выходных данных:
- С точки зрения механизма политик, устройства и серверы рассматриваются одинаково. Устройства и серверы, работающие с одним и тем же механизмом политик, считаются логически идентичными после взаимной проверки совместимости их механизмов политик.
- На устройствах изоляция достигается с помощью процессов изоляции AOSP (или pKVM в долгосрочной перспективе, когда доступность станет высокой). На серверах изоляция основана на «доверенной стороне», которой может быть либо TEE плюс другие предпочтительные технические решения для герметизации, либо договорное соглашение, либо и то, и другое.
Иными словами, все закрытые среды, в которых устанавливается и запускается механизм политик платформы, считаются частью нашей доверенной вычислительной базы (TCB). Данные могут распространяться без дополнительного шума внутри TCB. Политика защиты данных (DP) должна применяться, когда данные покидают TCB.
В основе высокоуровневой архитектуры персонализации на устройстве лежат два важных элемента:
- Парная архитектура процессов для выполнения бизнес-логики.
- Политики и механизм управления политиками для контроля входящего и исходящего трафика данных, а также разрешенных операций.
Эта целостная конструкция предоставляет компаниям равные условия, позволяя им запускать свой собственный код в доверенной среде выполнения и получать доступ к пользовательским данным, прошедшим соответствующие проверки на соответствие политике конфиденциальности.
В следующих разделах эти два ключевых аспекта будут рассмотрены более подробно.
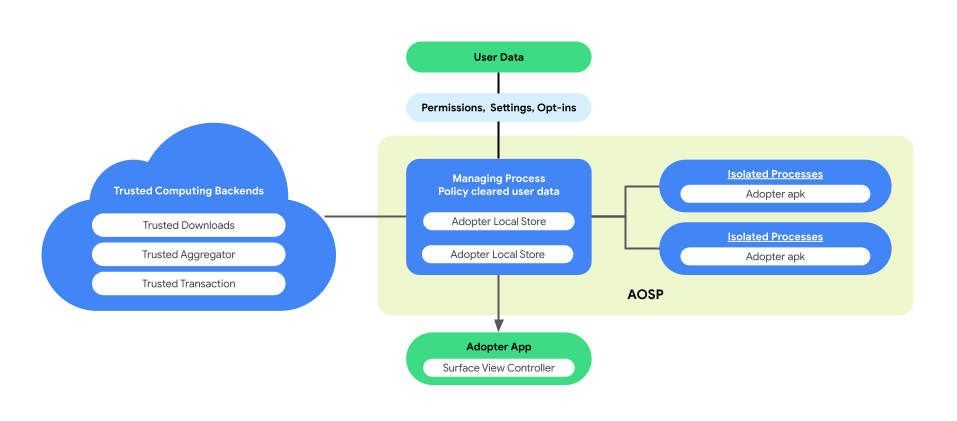
Парнопроцессная архитектура для выполнения бизнес-логики
В рамках концепции персонализации на устройстве (On-Device Personalization) в AOSP используется парнопроцессная архитектура для повышения конфиденциальности пользователей и безопасности данных во время выполнения бизнес-логики. Эта архитектура состоит из:
ManagingProcess. Этот процесс создает и управляет изолированными процессами (IsolatedProcesses), обеспечивая их изоляцию на уровне процессов с ограниченным доступом к разрешенным API и без сетевых или дисковых разрешений. ManagingProcess обрабатывает сбор всех бизнес-данных, всех данных конечных пользователей и разрешает их использование бизнес-кодом, передавая их в изолированные процессы для выполнения. Кроме того, он выступает посредником во взаимодействии между изолированными процессами и другими процессами, такими как system_server.
IsolatedProcess. Этот процесс, обозначенный как изолированный (
isolatedprocess=trueв манифесте), получает бизнес-данные, данные конечных пользователей, разрешенные политиками, и бизнес-код от управляющего процесса. Он позволяет бизнес-коду работать со своими данными и данными конечных пользователей, разрешенными политиками. IsolatedProcess взаимодействует исключительно с управляющим процессом как по входящему, так и по исходящему трафику, без дополнительных разрешений.
Архитектура парных процессов предоставляет возможность независимой проверки политик конфиденциальности данных конечных пользователей без необходимости для компаний открывать исходный код своей бизнес-логики или программного обеспечения. Благодаря тому, что управляющий процесс поддерживает независимость изолированных процессов, а изолированные процессы эффективно выполняют бизнес-логику, эта архитектура обеспечивает более безопасное и эффективное решение для сохранения конфиденциальности пользователей во время персонализации.
На следующем рисунке показана архитектура этого парного процесса.
Политики и механизмы управления политиками для операций с данными.
Персонализация на устройстве вводит уровень обеспечения соблюдения политик между платформой и бизнес-логикой. Цель состоит в предоставлении набора инструментов, которые преобразуют элементы управления конечного пользователя и бизнеса в централизованные и действенные решения по политикам. Затем эти политики всесторонне и надежно применяются во всех процессах и бизнес-логиках.
В архитектуре парных процессов механизм политик находится внутри управляющего процесса (ManagingProcess), контролируя входящий и исходящий трафик данных конечных пользователей и бизнеса. Он также предоставляет разрешенные операции изолированному процессу (IslacuteProcess). Примеры областей действия включают в себя соблюдение согласия конечных пользователей, защиту детей, предотвращение несанкционированного обмена данными и обеспечение конфиденциальности бизнеса.
Данная архитектура обеспечения соблюдения политик включает в себя три типа рабочих процессов, которые можно использовать:
- Инициируемые локально, автономные рабочие процессы с использованием связи в рамках доверенной среды выполнения (TEE):
- Потоки загрузки данных: доверенные загрузки
- Потоки загрузки данных: доверенные транзакции
- Инициируемые на местном уровне онлайн-процессы:
- Потоки обслуживания в реальном времени
- Потоки вывода
- Рабочие процессы, инициируемые локально и работающие в автономном режиме:
- Потоки оптимизации: обучение модели на устройстве, реализованное с помощью федеративного обучения (FL).
- Процесс формирования отчетов: агрегация данных с разных устройств реализована с помощью федеративной аналитики (FA).
На следующем рисунке показана архитектура с точки зрения политик и механизмов управления политиками.
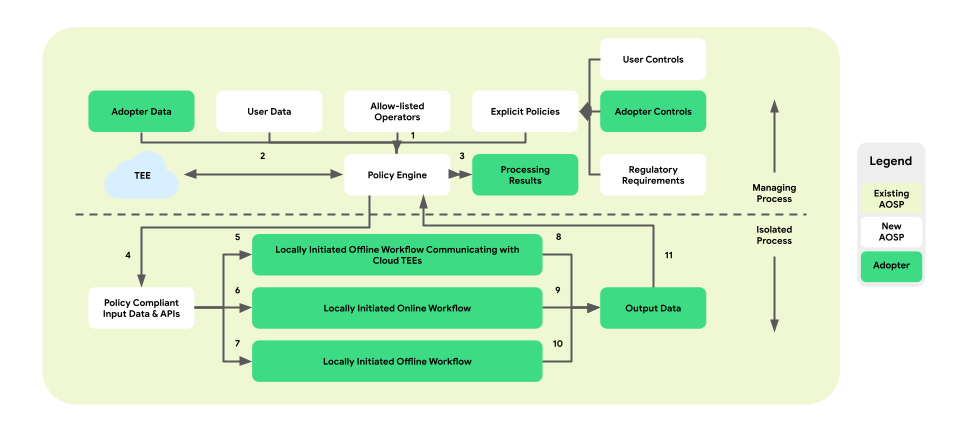
- Скачать: 1 -> 2 -> 4 -> 7 -> 10 -> 11 -> 3
- Порции: 1 + 3 -> 4 -> 6 -> 9 -> 11 -> 3
- Оптимизация: 2 (предоставляет план тренировок) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
- Отчетность: 3 (предоставляет план агрегирования) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
В целом, внедрение уровня обеспечения соблюдения политик и механизма управления политиками в архитектуру парных процессов On-Device Personalization обеспечивает изолированную и защищающую конфиденциальность среду для выполнения бизнес-логики, одновременно предоставляя контролируемый доступ к необходимым данным и операциям.
Многослойные поверхности API
Персонализация на устройстве предоставляет заинтересованным компаниям многоуровневую архитектуру API. Верхний уровень состоит из приложений, разработанных для конкретных сценариев использования. Потенциальные компании могут подключать свои данные к этим приложениям, известным как API верхнего уровня. API верхнего уровня строятся на основе API среднего уровня.
Со временем мы планируем добавить больше API верхнего уровня. Когда API верхнего уровня недоступен для конкретного варианта использования или когда существующие API верхнего уровня недостаточно гибки, предприятия могут напрямую использовать API среднего уровня, которые обеспечивают мощность и гибкость за счет программных примитивов.
Заключение
«Персонализация на устройстве» — это исследовательский проект на ранней стадии, призванный привлечь внимание и получить обратную связь по долгосрочному решению, которое решает проблемы конфиденциальности конечных пользователей с помощью новейших и лучших технологий, которые, как ожидается, обеспечат высокую эффективность.
Мы хотели бы взаимодействовать с заинтересованными сторонами, такими как эксперты по вопросам конфиденциальности, аналитики данных и потенциальные конечные пользователи, чтобы убедиться, что ODP отвечает их потребностям и учитывает их опасения.