
Diese technische Erläuterung, die für die Implementierung im Android Open Source Project (AOSP) vorgesehen ist, befasst sich mit den Motiven hinter der On-Device-Personalisierung (ODP), den Designprinzipien, die ihre Entwicklung leiten, dem Datenschutz durch das Vertraulichkeitsmodell und wie sie zu einer nachweislich privaten Nutzung beiträgt.
Wir möchten dies erreichen, indem wir das Datenzugriffsmodell vereinfachen und dafür sorgen, dass alle Nutzerdaten, die die Sicherheitsgrenze überschreiten, auf Nutzer-, Nutzer-Adopter- und Modellinstanzebene (in diesem Dokument manchmal zu Nutzerebene verkürzt) differenzenziell geschützt sind.
Der gesamte Code, der sich auf den potenziellen Datenabfluss von Endnutzerdaten von den Geräten der Endnutzer bezieht, ist Open Source und kann von externen Stellen überprüft werden. In der Anfangsphase unseres Vorschlags möchten wir Interesse wecken und Feedback zu einer Plattform einholen, die Möglichkeiten zur On-Device-Personalisierung bietet. Wir laden Stakeholder wie Datenschutzexperten, Datenanalysten und Sicherheitsexperten ein, sich mit uns auszutauschen.
Vision
Die On-Device-Personalisierung soll die Daten von Endnutzern vor Unternehmen schützen, mit denen sie nicht interagiert haben. Unternehmen können ihre Produkte und Dienstleistungen weiterhin für Endnutzer anpassen (z. B. mithilfe von ordnungsgemäß anonymisierten und differentialdatenschutzkonformen Modellen für maschinelles Lernen). Die genauen Anpassungen für einen Endnutzer sind jedoch nicht sichtbar, es sei denn, es gibt direkte Interaktionen zwischen dem Unternehmen und dem Endnutzer. Das hängt nicht nur von der vom Geschäftsinhaber generierten Anpassungsregel ab, sondern auch von den individuellen Einstellungen des Endnutzers. Wenn ein Unternehmen Modelle für maschinelles Lernen oder statistische Analysen erstellt, sorgt ODP dafür, dass sie mithilfe der entsprechenden Mechanismen für Differential Privacy ordnungsgemäß anonymisiert werden.
Derzeit planen wir, ODP in mehreren Meilensteinen zu untersuchen und dabei die folgenden Funktionen zu berücksichtigen: Wir laden interessierte Nutzer auch ein, konstruktiv Vorschläge für zusätzliche Funktionen oder Workflows zu machen, um diese explorative Datenanalyse voranzutreiben:
- Eine Sandbox-Umgebung, in der die gesamte Geschäftslogik enthalten und ausgeführt wird, sodass eine Vielzahl von Endnutzersignalen in die Sandbox gelangen kann, während die Ausgabe begrenzt wird.
Datenspeicher mit Ende-zu-Ende-Verschlüsselung für:
- Nutzereinstellungen und andere nutzerbezogene Daten Dazu gehören von Endnutzern bereitgestellte oder von Unternehmen erhobene und abgeleitete Daten sowie TTL-Einstellungen (Time to Live), Löschrichtlinien, Datenschutzrichtlinien und mehr.
- Unternehmenskonfigurationen ODP bietet Algorithmen zum Komprimieren oder Verschleieren dieser Daten.
- Ergebnisse der Geschäftsverarbeitung. Das können folgende Ergebnisse sein:
- Sie werden in späteren Verarbeitungsrunden als Eingaben verwendet.
- Die Daten werden gemäß den entsprechenden Differential Privacy-Mechanismen mit Rauschen versehen und auf berechtigte Endpunkte hochgeladen.
- Sie werden mit dem vertrauenswürdigen Uploadvorgang in vertrauenswürdige Ausführungsumgebungen (Trusted Execution Environments, TEE) hochgeladen, in denen Open-Source-Arbeitslasten mit geeigneten zentralen Mechanismen zur differenziellen Privatsphäre ausgeführt werden.
- Wird Endnutzern angezeigt.
APIs für folgende Zwecke:
- Aktualisieren Sie 2(a) per Batch oder inkrementell.
- Aktualisieren Sie 2(b) regelmäßig, entweder im Batch-Verfahren oder inkrementell.
- Laden Sie 2(c) mit geeigneten Rauschmechanismen in vertrauenswürdigen Aggregationsumgebungen hoch. Solche Ergebnisse können in den nächsten Verarbeitungsrunden zu 2(b) werden.
Zeitachse
Dies ist der aktuelle Plan für den Betatest von ODP. Der Zeitplan kann sich ändern.
| Feature | 1. Halbjahr 2025 | 3. Quartal 2025 |
|---|---|---|
| On-Device-Training und ‑Inferenz | Wenden Sie sich an das Privacy Sandbox-Team, um mögliche Optionen für die Pilotphase zu besprechen. | Einführung auf geeigneten Android-Geräten mit T oder höher |
Designprinzipien
Das ODP basiert auf drei Säulen: Datenschutz, Fairness und Nützlichkeit.
Turmdatenmodell für mehr Datenschutz
ODP folgt dem Prinzip Privacy by Design und wurde so konzipiert, dass der Schutz der Privatsphäre der Endnutzer standardmäßig gewährleistet ist.
Bei ODP wird die Verarbeitung der Personalisierung auf das Gerät eines Endnutzers verlagert. Bei diesem Ansatz werden Datenschutz und Nutzen in Einklang gebracht, indem Daten so weit wie möglich auf dem Gerät verbleiben und nur bei Bedarf außerhalb des Geräts verarbeitet werden. ODP konzentriert sich auf:
- Gerätesteuerung der Endnutzerdaten, auch wenn sie das Gerät verlassen. Ziele müssen attestierte Trusted Execution Environments von Anbietern öffentlicher Clouds sein, die von ODP erstellten Code ausführen.
- Geräteüberprüfbarkeit, was mit den Endnutzerdaten passiert, wenn sie das Gerät verlassen. ODP stellt Open-Source-Arbeitslasten für föderiertes Computing bereit, um geräteübergreifendes maschinelles Lernen und statistische Analysen für seine Nutzer zu koordinieren. Das Gerät eines Endnutzers bestätigt, dass solche Arbeitslasten unverändert in vertrauenswürdigen Ausführungsumgebungen ausgeführt werden.
- Garantiert technischer Datenschutz (z. B. Aggregation, Rauschen, Differential Privacy) für Ausgaben, die die gerätekontrollierte/prüfbare Grenze überschreiten.
Die Personalisierung ist daher gerätespezifisch.
Darüber hinaus benötigen Unternehmen Datenschutzmaßnahmen, die von der Plattform berücksichtigt werden sollten. Dazu müssen Rohdaten auf den jeweiligen Servern gespeichert werden. Dazu verwendet ODP das folgende Datenmodell:
- Jede Rohdatenquelle wird entweder auf dem Gerät oder serverseitig gespeichert, was lokales Lernen und Inferenzen ermöglicht.
- Wir stellen Algorithmen bereit, die die Entscheidungsfindung über mehrere Datenquellen hinweg erleichtern, z. B. das Filtern zwischen zwei unterschiedlichen Datenspeicherorten oder das Training oder die Inferenz über verschiedene Quellen hinweg.
In diesem Zusammenhang könnte es einen Turm für Unternehmen und einen für Endnutzer geben:

Der Endnutzer-Tower besteht aus Daten, die vom Endnutzer bereitgestellt werden (z. B. Kontoinformationen und Steuerelemente), erfassten Daten zu den Interaktionen eines Endnutzers mit seinem Gerät und abgeleiteten Daten (z. B. Interessen und Präferenzen), die vom Unternehmen abgeleitet werden. Abgeleitete Daten überschreiben keine direkten Erklärungen von Nutzern.
Zum Vergleich: In einer cloudbasierten Infrastruktur werden alle Rohdaten aus dem Endnutzer-Tower auf die Server des Unternehmens übertragen. Im Gegensatz dazu bleiben bei einer geräteorientierten Infrastruktur alle Rohdaten aus dem Endnutzer-Tower an ihrem Ursprung, während die Daten des Unternehmens weiterhin auf Servern gespeichert werden.
Die On-Device-Personalisierung kombiniert das Beste aus beiden Welten, indem nur bestätigter Open-Source-Code zur Verarbeitung von Daten verwendet wird, die sich auf Endnutzer beziehen könnten, in TEEs mithilfe privaterer Ausgabekanäle.
Inklusive öffentliche Beteiligung für gleichberechtigte Lösungen
ODP zielt darauf ab, eine ausgewogene Umgebung für alle Teilnehmer in einem vielfältigen Ökosystem zu schaffen. Uns ist bewusst, dass dieses Ökosystem komplex ist und verschiedene Akteure umfasst, die unterschiedliche Dienstleistungen und Produkte anbieten.
Um Innovationen zu fördern, bietet ODP APIs, die von Entwicklern und den von ihnen vertretenen Unternehmen implementiert werden können. Die On-Device-Personalisierung ermöglicht eine nahtlose Integration dieser Implementierungen bei der Verwaltung von Releases, Monitoring, Entwicklertools und Feedbacktools. Die On-Device-Personalisierung erzeugt keine konkrete Geschäftslogik, sondern dient als Katalysator für Kreativität.
ODP könnte im Laufe der Zeit mehr Algorithmen anbieten. Die Zusammenarbeit mit dem gesamten System ist entscheidend, um das richtige Maß an Funktionen zu bestimmen und gegebenenfalls eine angemessene Obergrenze für die Geräteressourcen für jedes teilnehmende Unternehmen festzulegen. Wir freuen uns auf Feedback aus der Branche, damit wir neue Anwendungsfälle erkennen und priorisieren können.
Entwickler-Dienstprogramm für eine verbesserte Nutzerfreundlichkeit
Bei der ODP-Methode gehen keine Ereignisdaten verloren und es gibt keine Verzögerungen bei der Beobachtung, da alle Ereignisse lokal auf Geräteebene erfasst werden. Es treten keine Fehler beim Beitritt auf und alle Ereignisse sind einem bestimmten Gerät zugeordnet. So bilden alle beobachteten Ereignisse eine chronologische Abfolge, die die Interaktionen der Nutzer widerspiegelt.
Durch diesen vereinfachten Prozess müssen keine Daten mehr zusammengeführt oder neu angeordnet werden. So können Nutzerdaten nahezu in Echtzeit und ohne Verluste abgerufen werden. Dies kann wiederum die Nützlichkeit erhöhen, die Endnutzer bei der Interaktion mit datengetriebenen Produkten und Diensten wahrnehmen, was zu einer höheren Zufriedenheit und einer sinnvolleren Nutzung führen kann. Mit ODP können Unternehmen sich effektiv an die Anforderungen ihrer Nutzer anpassen.
Das Datenschutzmodell: Datenschutz durch Vertraulichkeit
In den folgenden Abschnitten wird das Verbraucher-Produzenten-Modell als Grundlage dieser Datenschutzanalyse und der Datenschutz in der Rechenumgebung im Vergleich zur Ausgabegenauigkeit erläutert.
Das Verbraucher-Produzenten-Modell als Grundlage dieser Datenschutzanalyse
Wir verwenden das Modell „Verbraucher-Produzent“, um die Datenschutzgarantien für den Datenschutz durch Vertraulichkeit zu untersuchen. Berechnungen in diesem Modell werden als Knoten in einem gerichteten azyklischen Graphen (Directed Acyclic Graph, DAG) dargestellt, der aus Knoten und Untergraphen besteht. Jeder Rechenknoten hat drei Komponenten: Verbrauchte Eingaben, erzeugte Ausgaben und die Berechnung, die Eingaben den Ausgaben zuordnet.

In diesem Modell gilt der Datenschutz für alle drei Komponenten:
- Datenschutz bei Eingaben Knoten können zwei Arten von Eingaben haben. Wenn eine Eingabe von einem Vorgängerknoten generiert wird, gelten für sie bereits die Datenschutzgarantien für die Ausgabe dieses Vorgängers. Andernfalls müssen Eingaben die Richtlinien für den Dateneintrag mithilfe der Richtlinien-Engine klären.
- Datenschutz bei der Ausgabe Die Ausgabe muss möglicherweise anonymisiert werden, z. B. durch Differential Privacy (DP).
- Vertraulichkeit der Rechenumgebung Die Berechnung muss in einer sicher abgeschotteten Umgebung erfolgen, damit niemand Zugriff auf Zwischenzustände innerhalb eines Knotens hat. Zu den Technologien, die dies ermöglichen, gehören föderierte Berechnungen (FC), hardwarebasierte Trusted Execution Environments (TEE), sichere Multi-Party-Berechnungen (sMPC) und homomorphe Verschlüsselung (HPE). Beachten Sie, dass der Datenschutz durch Vertraulichkeitsmechanismen Zwischenzustände und alle Ausgaben, die die Vertraulichkeitsgrenze überschreiten, weiterhin durch Differential Privacy-Mechanismen geschützt werden müssen. Zwei erforderliche Ansprüche sind:
- Vertraulichkeit von Umgebungen, damit nur deklarierte Ausgaben die Umgebung verlassen, und
- Solidität, die genaue Ableitung von Datenschutzansprüchen für die Ausgabe aus Datenschutzansprüchen für die Eingabe ermöglicht. Durch die Korrektheit kann die Datenschutzeigenschaft in einem DAG weitergegeben werden.
Ein privates System schützt die Privatsphäre der Eingabe, die Vertraulichkeit der Rechenumgebung und die Privatsphäre der Ausgabe. Die Anzahl der Anwendungen von Mechanismen der Differential Privacy kann jedoch reduziert werden, indem mehr Verarbeitung in einer vertraulichen Rechenumgebung durchgeführt wird.
Dieses Modell bietet zwei Hauptvorteile. Erstens können die meisten Systeme, ob groß oder klein, als DAG dargestellt werden. Zweitens: Die Eigenschaften der Postverarbeitung [Abschnitt 2.1] und der Zusammensetzung ( Lemma 2.4 in „The Complexity of Differential Privacy“) von Differential Privacy bieten leistungsstarke Tools zur Analyse des (schlimmstenfalls) Datenschutz- und Genauigkeitstrade-offs für einen gesamten Graphen:
- Durch die Nachbearbeitung wird sichergestellt, dass eine Quantität, die einmal anonymisiert wurde, nicht mehr de-anonymisiert werden kann, wenn die ursprünglichen Daten nicht noch einmal verwendet werden. Solange alle Eingaben für einen Knoten privat sind, ist seine Ausgabe unabhängig von den Berechnungen privat.
- Die erweiterte Zusammensetzung garantiert, dass der gesamte Graph differenzierbar ist, wenn jeder Graphenteil differenzierbar ist. Die Werte ε und δ der endgültigen Ausgabe eines Graphen werden dann auf etwa ε√κ begrenzt, vorausgesetzt, ein Graph hat κ Einheiten und die Ausgabe jeder Einheit ist (ε, δ)-differenzierbar.
Diese beiden Eigenschaften führen zu zwei Designprinzipien für jeden Knoten:
- Eigenschaft 1 (Aus der Nachbearbeitung): Wenn die Eingaben eines Knotens vollständig datensensitiv sind, ist auch seine Ausgabe datensensitiv. Dies ermöglicht die Ausführung beliebiger Geschäftslogik im Knoten und unterstützt die „Geheimrezepte“ von Unternehmen.
- Eigenschaft 2 (aus der erweiterten Komposition): Wenn nicht alle Eingaben eines Knotens DP sind, muss sein Ausgabesignal DP-konform sein. Wenn ein Rechenknoten in einer vertrauenswürdigen Ausführungsumgebung ausgeführt wird und Open-Source-Arbeitslasten und ‑konfigurationen von On-Device-Personalisierungen ausführt, sind engere DP-Grenzwerte möglich. Andernfalls müssen für die On-Device-Personalisierung möglicherweise die Worst-Case-DP-Grenzwerte verwendet werden. Aufgrund von Ressourceneinschränkungen werden Trusted Execution Environments, die von einem Public-Cloud-Anbieter angeboten werden, zuerst priorisiert.
Datenschutz in der Rechenumgebung im Vergleich zur Ausgabegenauigkeit
Künftig liegt der Schwerpunkt der On-Device-Personalisierung auf der Verbesserung der Sicherheit vertraulicher Rechenumgebungen und darauf, dass Zwischenzustände nicht zugänglich sind. Dieser Sicherheitsvorgang, der als Versiegelung bezeichnet wird, wird auf Subgraphebene angewendet. So können mehrere Knoten gleichzeitig DP-konform gemacht werden. Das bedeutet, dass Property 1 und Property 2 auf subgraph-Ebene angewendet werden.

Die endgültige Grafikausgabe, Ausgabe 7, wird natürlich gemäß der Zusammensetzung mit DP versehen. Das bedeutet, dass es für dieses Diagramm insgesamt zwei DP gibt, verglichen mit drei (lokalen) DP, wenn keine Abdichtung verwendet wurde.
Durch die Sicherung der Rechenumgebung und die Beseitigung von Möglichkeiten für Angreifer, auf die Eingaben und Zwischenzustände eines Graphen oder Subgraphs zuzugreifen, wird die Implementierung von zentraler Differential Privacy ermöglicht (d. h. die Ausgabe einer versiegelten Umgebung ist DP-konform). Dies kann die Genauigkeit im Vergleich zu lokaler Differential Privacy verbessern (d. h. die einzelnen Eingaben sind DP-konform). Dieses Prinzip liegt der Einstufung von FC, TEEs, sMPCs und HPEs als Datenschutztechnologien zugrunde. Siehe Kapitel 10 in The Complexity of Differential Privacy.
Ein gutes praktisches Beispiel sind Modelltraining und Inferenz. In den folgenden Erläuterungen wird davon ausgegangen, dass (1) die Trainingspopulation und die Inferenzpopulation sich überschneiden und (2) sowohl Merkmale als auch Labels personenbezogene Nutzerdaten darstellen. Wir können DP auf alle Eingaben anwenden:

Bei der On-Device-Personalisierung kann lokale datenschutzfreundliche Datenverarbeitung auf Nutzerlabels und -funktionen angewendet werden, bevor sie an Server gesendet werden. Dieser Ansatz stellt keine Anforderungen an die Ausführungsumgebung oder die Geschäftslogik des Servers.



Das ist das aktuelle Design für die On-Device-Personalisierung.
Nachweislich vertraulich
Die On-Device-Personalisierung soll nachweislich vertraulich sein. Der Schwerpunkt liegt darauf, zu prüfen, was außerhalb der Geräte der Nutzer passiert. ODP erstellt den Code, der die Daten verarbeitet, die die Geräte der Endnutzer verlassen, und verwendet die RFC 9334 Remote ATtestation procedureS (RATS) Architecture des NIST, um zu bestätigen, dass dieser Code unverändert auf einem Confidential Computing Consortium-kompatiblen, deprivilegierten Server ausgeführt wird, der dem Instanzadministrator gehört. Diese Codes sind Open Source und können für eine transparente Überprüfung zugänglich gemacht werden, um Vertrauen zu schaffen. Solche Maßnahmen können Nutzern die Gewissheit geben, dass ihre Daten geschützt sind, und Unternehmen können sich auf der Grundlage einer soliden Datenschutzgarantie einen guten Ruf aufbauen.
Die Reduzierung der Menge an privaten Daten, die erhoben und gespeichert werden, ist ein weiterer wichtiger Aspekt der On-Device-Personalisierung. Dieses Prinzip wird durch die Verwendung von Technologien wie Federated Computing und Differential Privacy eingehalten. So können wertvolle Datenmuster offengelegt werden, ohne dass sensible individuelle Details oder personenidentifizierbare Informationen offengelegt werden.
Ein weiterer wichtiger Aspekt des nachweisbaren Datenschutzes ist die Aufzeichnung von Aktivitäten im Zusammenhang mit der Datenverarbeitung und ‑weitergabe in einem Audit-Trail. So können Prüfberichte erstellt und Sicherheitslücken erkannt werden, was unser Engagement für den Datenschutz unterstreicht.
Wir möchten mit Datenschutzexperten, Behörden, Branchen und Einzelpersonen konstruktiv zusammenarbeiten, um das Design und die Implementierung kontinuierlich zu verbessern.
Die folgende Grafik zeigt den Codepfad für die geräteübergreifende Aggregation und die Einfügung von Rauschen gemäß Differential Privacy.
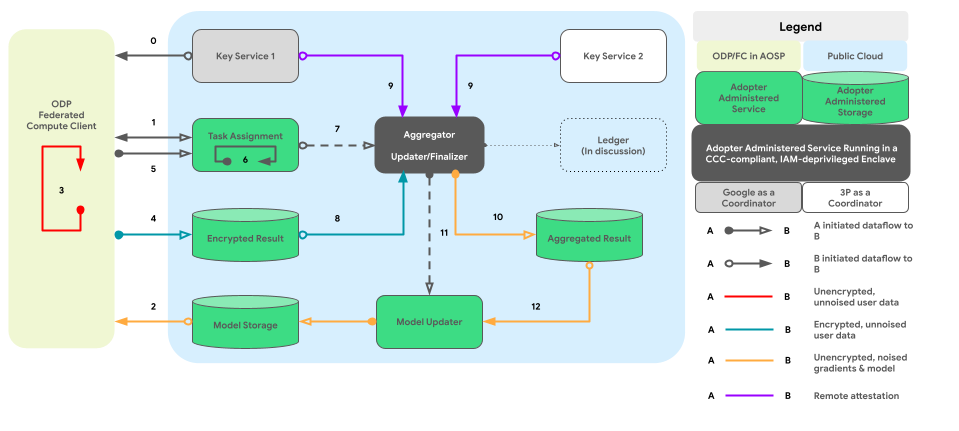
Grobkonzept
Wie kann der Datenschutz durch Vertraulichkeit umgesetzt werden? Im Großen und Ganzen dient eine von ODP erstellte Richtlinien-Engine, die in einer abgeschotteten Umgebung ausgeführt wird, als Kernkomponente, die jeden Knoten/Subgraphen überwacht und gleichzeitig den DP-Status seiner Eingaben und Ausgaben verfolgt:
- Aus Sicht der Richtlinien-Engine werden Geräte und Server gleich behandelt. Geräte und Server, auf denen dieselbe Richtlinien-Engine ausgeführt wird, gelten als logisch identisch, sobald ihre Richtlinien-Engines gegenseitig attestiert wurden.
- Auf Geräten wird die Isolation durch isolierte AOSP-Prozesse (oder langfristig durch pKVM, sobald die Verfügbarkeit hoch ist) erreicht. Auf Servern beruht die Isolation auf einer „vertrauenswürdigen Partei“, die entweder ein TEE mit anderen technischen Abdichtungslösungen (bevorzugt) oder eine vertragliche Vereinbarung oder beides ist.
Mit anderen Worten: Alle versiegelten Umgebungen, in denen die Plattformrichtlinien-Engine installiert und ausgeführt wird, gelten als Teil unserer Trusted Computing Base (TCB). Mit dem TCB können Daten ohne zusätzliches Rauschen übertragen werden. Die Datenträgersperre muss angewendet werden, wenn Daten den TCB verlassen.
Das allgemeine Design der On-Device-Personalisierung integriert zwei wichtige Elemente:
- Eine Architektur mit zwei Prozessen für die Ausführung der Geschäftslogik
- Richtlinien und eine Richtlinien-Engine zum Verwalten von Datenein- und ‑ausgang sowie zulässigen Vorgängen.
Dieses einheitliche Design bietet Unternehmen eine faire Ausgangslage, in der sie ihren proprietären Code in einer vertrauenswürdigen Ausführungsumgebung ausführen und auf Nutzerdaten zugreifen können, die die entsprechenden Richtlinienprüfungen bestanden haben.
In den folgenden Abschnitten werden diese beiden wichtigen Aspekte näher erläutert.
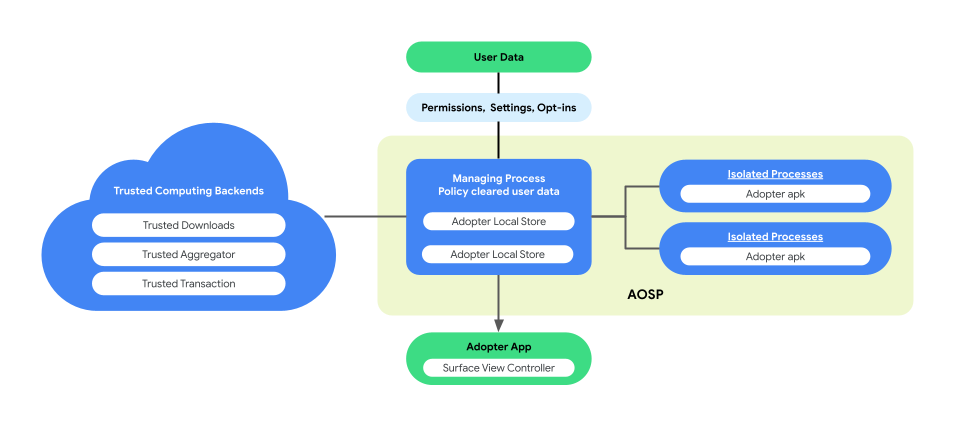
Paarprozessarchitektur für die Ausführung der Geschäftslogik
Bei der On-Device-Personalisierung wird in AOSP eine gekoppelte Prozessarchitektur eingeführt, um den Datenschutz und die Datensicherheit bei der Ausführung der Geschäftslogik zu verbessern. Diese Architektur besteht aus:
ManagingProcess. Dabei werden IsolatedProcesses erstellt und verwaltet, die auf Prozessebene isoliert bleiben und deren Zugriff auf APIs auf der Zulassungsliste beschränkt ist. Es gibt keine Netzwerk- oder Laufwerkberechtigungen. Der ManagingProcess kümmert sich um die Erhebung aller Geschäftsdaten und Endnutzerdaten und prüft, ob sie für den Geschäftscode zulässig sind. Anschließend werden sie zur Ausführung an die IsolatedProcesses übergeben. Außerdem vermittelt er die Interaktion zwischen IsolatedProcesses und anderen Prozessen wie system_server.
IsolatedProcess. Dieser Prozess ist als isoliert gekennzeichnet (
isolatedprocess=trueim Manifest) und empfängt Geschäftsdaten, richtlinienkonforme Endnutzerdaten und den Geschäftscode vom Prozess „ManagingProcess“. Sie ermöglichen es dem Geschäftscode, mit seinen Daten und den gemäß den Richtlinien freigegebenen Endnutzerdaten zu arbeiten. Der IsolatedProcess kommuniziert sowohl für den Eintritt als auch für den Austritt ausschließlich mit dem ManagingProcess, ohne zusätzliche Berechtigungen.
Die Architektur mit gekoppelten Prozessen bietet die Möglichkeit zur unabhängigen Überprüfung der Datenschutzrichtlinien für Endnutzerdaten, ohne dass Unternehmen ihre Geschäftslogik oder ihren Code als Open Source veröffentlichen müssen. Da der ManagingProcess die Unabhängigkeit der IsolatedProcesses beibehält und die IsolatedProcesses die Geschäftslogik effizient ausführen, bietet diese Architektur eine sicherere und effizientere Lösung zum Schutz der Privatsphäre der Nutzer bei der Personalisierung.
Die folgende Abbildung zeigt diese gekoppelte Prozessarchitektur.
Richtlinien und Richtlinien-Engines für Datenoperationen
Die On-Device-Personalisierung führt eine Richtliniendurchsetzungsebene zwischen der Plattform und der Geschäftslogik ein. Ziel ist es, eine Reihe von Tools bereitzustellen, mit denen Endnutzer- und Geschäftssteuerungen in zentralisierte und umsetzbare Richtlinienentscheidungen abgebildet werden. Diese Richtlinien werden dann umfassend und zuverlässig auf alle Abläufe und Unternehmen angewendet.
Bei der Architektur mit gekoppelten Prozessen befindet sich die Richtlinien-Engine im ManagingProcess, der den Datenfluss von Endnutzer- und Geschäftsdaten überwacht. Außerdem werden dem IsolatedProcess Vorgänge aus der Zulassungsliste zur Verfügung gestellt. Beispiele für abgedeckte Bereiche sind die Achtung der Kontrollen von Endnutzern, der Schutz von Kindern, die Verhinderung der Weitergabe von Daten ohne Einwilligung und der Datenschutz für Unternehmen.
Diese Architektur zur Richtliniendurchsetzung umfasst drei Arten von Workflows, die genutzt werden können:
- Lokal initiierte, Offline-Workflows mit TEE-Kommunikation (Trusted Execution Environment):
- Datendownload-Abläufe: vertrauenswürdige Downloads
- Datenupload-Abläufe: vertrauenswürdige Transaktionen
- Lokal initiierte Online-Workflows:
- Bereitstellungsabläufe in Echtzeit
- Inferenzabläufe
- Lokal initiierte, offline ausgeführte Workflows:
- Optimierungsabläufe: On-Device-Modelltraining, das über Federated Learning (FL) implementiert wird
- Berichtsabläufe: Geräteübergreifende Aggregation über Federated Analytics (FA)
Die folgende Abbildung zeigt die Architektur aus der Perspektive von Richtlinien und Richtlinien-Engines.
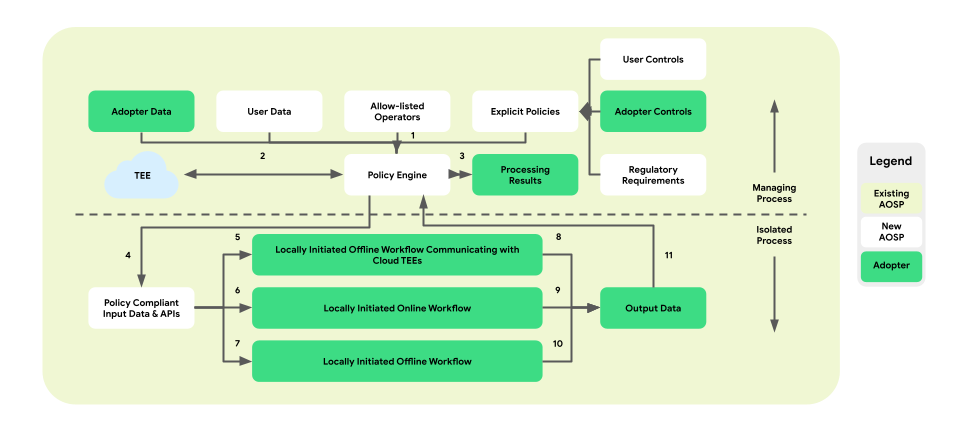
- Download: 1 -> 2 -> 4 -> 7 -> 10 -> 11 -> 3
- Auslieferung: 1 + 3 -> 4 -> 6 -> 9 -> 11 -> 3
- Optimierung: 2 (Trainingsplan bereitstellen) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
- Berichterstellung: 3 (Aggregationsplan bereitstellen) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
Insgesamt sorgt die Einführung der Richtliniendurchsetzungsebene und der Richtlinien-Engine in der gekoppelten Prozessarchitektur der On-Device-Personalisierung für eine isolierte und datenschutzfreundliche Umgebung zur Ausführung der Geschäftslogik und bietet gleichzeitig kontrollierten Zugriff auf erforderliche Daten und Vorgänge.
Mehrere API-Oberflächen
Die On-Device-Personalisierung bietet interessierten Unternehmen eine mehrschichtige API-Architektur. Die oberste Schicht besteht aus Anwendungen, die für bestimmte Anwendungsfälle entwickelt wurden. Potenzielle Unternehmen können ihre Daten mit diesen Anwendungen verbinden, die als Top-Layer-APIs bezeichnet werden. APIs der obersten Schicht basieren auf den APIs der mittleren Schicht.
Im Laufe der Zeit werden wir voraussichtlich weitere APIs der obersten Schicht hinzufügen. Wenn für einen bestimmten Anwendungsfall keine API der obersten Schicht verfügbar ist oder vorhandene APIs der obersten Schicht nicht flexibel genug sind, können Unternehmen die APIs der mittleren Schicht direkt implementieren. Diese bieten durch Programmierprimitiven Leistung und Flexibilität.
Fazit
Die On-Device-Personalisierung ist ein Forschungsvorschlag in der Anfangsphase, mit dem wir Interesse und Feedback zu einer langfristigen Lösung wecken möchten, die mit den neuesten und besten Technologien, die voraussichtlich einen hohen Nutzen bieten, Bedenken im Hinblick auf den Datenschutz von Endnutzern anspricht.
Wir möchten mit Stakeholdern wie Datenschutzexperten, Datenanalysten und potenziellen Endnutzern zusammenarbeiten, um sicherzustellen, dass ODP ihren Anforderungen entspricht und ihre Bedenken ausräumt.