
این توضیحدهنده فنی که قرار است در پروژه متنباز اندروید (AOSP) پیادهسازی شود، انگیزه پشت شخصیسازی روی دستگاه (ODP)، اصول طراحی که توسعه آن را هدایت میکنند، حریم خصوصی آن از طریق مدل محرمانگی و چگونگی کمک آن به تضمین یک تجربه خصوصی قابل اثبات را مورد بحث قرار میدهد.
ما قصد داریم با سادهسازی مدل دسترسی به دادهها و اطمینان از اینکه تمام دادههای کاربر که از مرز امنیتی خارج میشوند، به صورت جداگانه در سطح (کاربر، پذیرنده، نمونه مدل) (که گاهی در این سند به صورت خلاصه به سطح کاربر گفته میشود) خصوصی هستند، به این هدف دست یابیم.
تمام کدهای مربوط به خروج دادههای کاربر نهایی از دستگاههای کاربران نهایی، متنباز و قابل تأیید توسط نهادهای خارجی خواهد بود. در مراحل اولیه پیشنهاد ما، ما به دنبال ایجاد علاقه و جمعآوری بازخورد برای پلتفرمی هستیم که فرصتهای شخصیسازی روی دستگاه را تسهیل میکند. ما از ذینفعان مانند کارشناسان حریم خصوصی، تحلیلگران داده و متخصصان امنیتی دعوت میکنیم تا با ما همکاری کنند.
چشم انداز
شخصیسازی روی دستگاه به گونهای طراحی شده است که اطلاعات کاربران نهایی را از کسبوکارهایی که با آنها تعامل نداشتهاند، محافظت کند. کسبوکارها ممکن است به سفارشیسازی محصولات و خدمات خود برای کاربران نهایی ادامه دهند (برای مثال با استفاده از مدلهای یادگیری ماشینی که به طور مناسب ناشناس و به صورت تفاضلی خصوصی هستند)، اما آنها قادر به مشاهده دقیق سفارشیسازیهای انجام شده برای کاربر نهایی نخواهند بود (که این امر نه تنها به قانون سفارشیسازی ایجاد شده توسط صاحب کسبوکار، بلکه به ترجیحات شخصی کاربر نهایی نیز بستگی دارد) مگر اینکه تعاملات مستقیمی بین کسبوکار و کاربر نهایی وجود داشته باشد. اگر کسبوکاری هرگونه مدل یادگیری ماشینی یا تحلیلهای آماری تولید کند، ODP با استفاده از مکانیسمهای مناسب حریم خصوصی تفاضلی، سعی خواهد کرد تا از ناشناسسازی صحیح آنها اطمینان حاصل کند.
برنامه فعلی ما بررسی ODP در چندین مرحله است که ویژگیها و قابلیتهای زیر را پوشش میدهد. همچنین از علاقهمندان دعوت میکنیم تا هرگونه ویژگی یا گردش کار اضافی را برای پیشبرد این بررسی، به طور سازنده پیشنهاد دهند:
- یک محیط سندباکسشده که در آن تمام منطق کسبوکار گنجانده و اجرا میشود و به انبوهی از سیگنالهای کاربر نهایی اجازه ورود به سندباکس را میدهد و در عین حال خروجیها را محدود میکند.
ذخیرهسازی دادههای رمزگذاریشده سرتاسری برای:
- کنترلهای کاربر و سایر دادههای مرتبط با کاربر. این دادهها میتوانند توسط کاربر نهایی ارائه شوند یا توسط کسبوکارها جمعآوری و استنباط شوند، همراه با کنترلهای زمان حیات (TTL)، سیاستهای حذف، سیاستهای حفظ حریم خصوصی و موارد دیگر.
- پیکربندیهای تجاری. ODP الگوریتمهایی را برای فشردهسازی یا مبهمسازی این دادهها ارائه میدهد.
- نتایج پردازش کسب و کار. این نتایج میتوانند عبارتند از:
- به عنوان ورودی در دورهای بعدی پردازش مصرف میشوند،
- طبق مکانیسمهای مناسب حریم خصوصی تفاضلی نویزگذاری شده و در نقاط انتهایی واجد شرایط آپلود میشود.
- با استفاده از جریان آپلود قابل اعتماد در محیطهای اجرایی قابل اعتماد (TEE) که بارهای کاری متنباز را با مکانیسمهای مرکزی مناسبِ حفظ حریم خصوصیِ تفاضلی اجرا میکنند، آپلود شده است.
- به کاربران نهایی نشان داده میشود.
APIهایی که برای موارد زیر طراحی شدهاند:
- بهروزرسانی ۲(الف)، بهصورت دستهای یا تدریجی.
- بهروزرسانی ۲(ب) به صورت دورهای، چه به صورت دستهای و چه به صورت افزایشی.
- بارگذاری ۲(ج)، با مکانیسمهای نویز مناسب در محیطهای تجمیع مورد اعتماد. چنین نتایجی ممکن است برای دورهای پردازش بعدی به ۲(ب) تبدیل شوند.
گاهشمار
این طرح فعلی برای آزمایش ODP در نسخه بتا است. جدول زمانی ممکن است تغییر کند.
| ویژگی | نیمه اول ۲۰۲۵ | سهماهه سوم ۲۰۲۵ |
|---|---|---|
| آموزش روی دستگاه + استنتاج | برای گفتگو در مورد گزینههای بالقوه برای اجرای آزمایشی در این بازه زمانی، با تیم Privacy Sandbox تماس بگیرید. | شروع به انتشار برای دستگاههای واجد شرایط Android T+ کنید. |
اصول طراحی
سه رکن وجود دارد که ODP به دنبال ایجاد تعادل بین آنها است: حریم خصوصی، انصاف و سودمندی.
مدل دادهی Tower شده برای حفاظت از حریم خصوصی پیشرفته
ODP از حریم خصوصی بر اساس طراحی پیروی میکند و با حفاظت از حریم خصوصی کاربر نهایی به عنوان پیشفرض طراحی شده است.
ODP انتقال پردازش شخصیسازی به دستگاه کاربر نهایی را بررسی میکند. این رویکرد با نگهداشتن دادهها تا حد امکان روی دستگاه و پردازش آنها فقط در صورت لزوم در خارج از دستگاه، بین حریم خصوصی و سودمندی تعادل برقرار میکند. ODP بر موارد زیر تمرکز دارد:
- کنترل دستگاه بر دادههای کاربر نهایی، حتی زمانی که از دستگاه خارج میشوند. مقاصد باید دارای گواهی باشند. محیطهای اجرای قابل اعتماد ارائه شده توسط ارائه دهندگان ابر عمومی که کد نوشته شده ODP را اجرا میکنند.
- قابلیت تأیید دستگاه از آنچه که برای دادههای کاربر نهایی در صورت خروج از دستگاه اتفاق میافتد. ODP بارهای کاری متنباز و Federated Compute را برای هماهنگی یادگیری ماشینی و تحلیل آماری بین دستگاهی برای پذیرندگان خود فراهم میکند. دستگاه کاربر نهایی تأیید میکند که چنین بارهای کاری در محیطهای اجرایی قابل اعتماد (Trusted Execution Environments) بدون تغییر اجرا میشوند.
- تضمین حریم خصوصی فنی (برای مثال، تجمیع، نویز، حریم خصوصی تفاضلی) خروجیهایی که از مرز کنترلشده/قابل تأیید دستگاه خارج میشوند.
در نتیجه، شخصیسازی مختص هر دستگاه خواهد بود.
علاوه بر این، کسبوکارها به اقدامات حفظ حریم خصوصی نیز نیاز دارند که پلتفرم باید به آنها توجه کند. این امر مستلزم نگهداری دادههای خام کسبوکار در سرورهای مربوطه است. برای دستیابی به این هدف، ODP مدل داده زیر را اتخاذ میکند:
- هر منبع داده خام یا روی دستگاه یا سمت سرور ذخیره میشود و امکان یادگیری و استنتاج محلی را فراهم میکند.
- ما الگوریتمهایی را برای تسهیل تصمیمگیری در میان منابع داده متعدد، مانند فیلتر کردن بین دو مکان داده متفاوت یا آموزش یا استنتاج در میان منابع مختلف، ارائه خواهیم داد.
در این زمینه، میتواند یک برج تجاری و یک برج کاربر نهایی وجود داشته باشد:
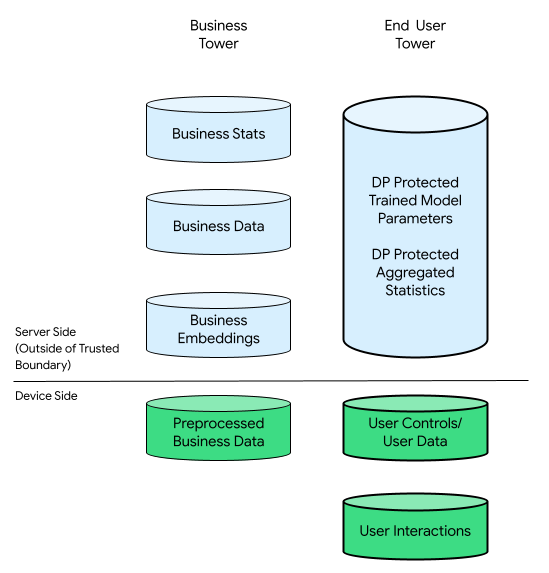
برج کاربر نهایی شامل دادههای ارائه شده توسط کاربر نهایی (به عنوان مثال، اطلاعات حساب و کنترلها)، دادههای جمعآوریشده مربوط به تعاملات کاربر نهایی با دستگاه خود و دادههای مشتقشده (به عنوان مثال، علایق و ترجیحات) استنباطشده توسط کسبوکار است. دادههای استنباطشده، اظهارات مستقیم هیچ کاربری را بازنویسی نمیکنند.
برای مقایسه، در یک زیرساخت ابر-محور، تمام دادههای خام از دکل کاربر نهایی به سرورهای کسبوکار منتقل میشود. برعکس، در یک زیرساخت دستگاه-محور، تمام دادههای خام از دکل کاربر نهایی در مبدا خود باقی میمانند، در حالی که دادههای کسبوکار در سرورها ذخیره میشوند.
شخصیسازی روی دستگاه، با فعال کردن کدهای متنباز و معتبر برای پردازش دادههایی که پتانسیل ارتباط با کاربران نهایی در TEEها را با استفاده از کانالهای خروجی خصوصیتر دارند، بهترینهای هر دو جهان را با هم ترکیب میکند.
مشارکت عمومی فراگیر برای راهحلهای عادلانه
هدف ODP تضمین محیطی متعادل برای همه شرکتکنندگان در یک اکوسیستم متنوع است. ما پیچیدگی این اکوسیستم را که از بازیگران مختلفی تشکیل شده است که خدمات و محصولات متمایزی را ارائه میدهند، درک میکنیم.
برای الهام بخشیدن به نوآوری، ODP رابطهای برنامهنویسی کاربردی (API) ارائه میدهد که میتوانند توسط توسعهدهندگان و کسبوکارهایی که آنها نمایندگی میکنند، پیادهسازی شوند. شخصیسازی روی دستگاه، ادغام یکپارچه این پیادهسازیها را در حین مدیریت انتشارها، نظارت، ابزارهای توسعهدهندگان و ابزارهای بازخورد تسهیل میکند. شخصیسازی روی دستگاه هیچ منطق تجاری مشخصی ایجاد نمیکند ؛ بلکه به عنوان کاتالیزوری برای خلاقیت عمل میکند.
ODP میتواند به مرور زمان الگوریتمهای بیشتری ارائه دهد. همکاری با اکوسیستم برای تعیین سطح مناسب ویژگیها و احتمالاً ایجاد یک سقف معقول برای منابع دستگاه برای هر کسبوکار مشارکتکننده ضروری است. ما منتظر بازخورد از اکوسیستم هستیم تا به ما در تشخیص و اولویتبندی موارد استفاده جدید کمک کند.
ابزار توسعهدهنده برای بهبود تجربه کاربری
با ODP هیچ گونه از دست رفتن اطلاعات رویداد یا تأخیر در مشاهده وجود ندارد، زیرا همه رویدادها به صورت محلی در سطح دستگاه ثبت میشوند. هیچ خطایی در اتصال وجود ندارد و همه رویدادها با یک دستگاه خاص مرتبط هستند. در نتیجه، همه رویدادهای مشاهده شده به طور طبیعی یک توالی زمانی را تشکیل میدهند که منعکس کننده تعاملات کاربر است.
این فرآیند سادهشده، نیاز به اتصال یا تنظیم مجدد دادهها را از بین میبرد و امکان دسترسی تقریباً بلادرنگ و بدون اتلاف به دادههای کاربر را فراهم میکند. در عوض، این امر میتواند سودمندی را که کاربران نهایی هنگام تعامل با محصولات و خدمات مبتنی بر داده درک میکنند، افزایش دهد و به طور بالقوه منجر به سطوح رضایت بالاتر و تجربیات معنادارتر شود. با ODP، کسبوکارها میتوانند به طور مؤثر با نیازهای کاربران خود سازگار شوند.
مدل حریم خصوصی: حریم خصوصی از طریق محرمانگی
بخشهای بعدی مدل مصرفکننده-تولیدکننده را به عنوان مبنای این تحلیل حریم خصوصی و حریم خصوصی محیط محاسبات در مقابل دقت خروجی مورد بحث قرار میدهند.
مدل مصرفکننده-تولیدکننده به عنوان اساس این تحلیل حریم خصوصی
ما از مدل مصرفکننده-تولیدکننده برای بررسی تضمینهای حریم خصوصی از طریق محرمانگی استفاده خواهیم کرد. محاسبات در این مدل به صورت گرههایی در یک گراف جهتدار غیرمدور (DAG) نمایش داده میشوند که از گرهها و زیرگرافها تشکیل شده است. هر گره محاسباتی دارای سه جزء است: ورودیهای مصرفشده، خروجیهای تولیدشده و نگاشت محاسباتی ورودیها به خروجیها.

در این مدل، حفاظت از حریم خصوصی در هر سه مؤلفه اعمال میشود:
- حریم خصوصی ورودی . گرهها میتوانند دو نوع ورودی داشته باشند. اگر ورودی توسط یک گره قبلی تولید شده باشد، از قبل تضمینهای حریم خصوصی خروجی آن گره قبلی را دارد. در غیر این صورت، ورودیها باید سیاستهای ورود دادهها را با استفاده از موتور سیاست پاک کنند.
- حریم خصوصی خروجی . ممکن است خروجی نیاز به خصوصیسازی داشته باشد، مانند آنچه که توسط حریم خصوصی تفاضلی (DP) ارائه میشود.
- محرمانگی محیط محاسبات . محاسبات باید در یک محیط امن و مهر و موم شده انجام شود و تضمین شود که هیچ کس به حالتهای واسطه در یک گره دسترسی ندارد. فناوریهایی که این امکان را فراهم میکنند عبارتند از محاسبات فدرال (FC)، محیطهای اجرای قابل اعتماد مبتنی بر سختافزار (TEE)، محاسبات چندجانبه امن (sMPC)، رمزگذاری همومورفیک (HPE) و موارد دیگر. شایان ذکر است که حریم خصوصی از طریق محرمانگی، حالتهای واسطه را محافظت میکند و تمام خروجیهایی که از مرز محرمانگی خارج میشوند، همچنان باید توسط مکانیسمهای حریم خصوصی تفاضلی محافظت شوند. دو ادعای مورد نیاز عبارتند از:
- محرمانگی محیط، تضمین اینکه فقط خروجیهای اعلامشده از محیط خارج میشوند و
- صحت، امکان استنتاج دقیق ادعاهای حریم خصوصی خروجی از ادعاهای حریم خصوصی ورودی را فراهم میکند. صحت، امکان انتشار ویژگی حریم خصوصی در سراسر یک DAG را فراهم میکند.
یک سیستم خصوصی، حریم خصوصی ورودی، محرمانگی محیط محاسباتی و حریم خصوصی خروجی را حفظ میکند. با این حال، تعداد کاربردهای مکانیسمهای حریم خصوصی تفاضلی را میتوان با محصور کردن پردازشهای بیشتر در یک محیط محاسباتی محرمانه کاهش داد.
این مدل دو مزیت اصلی ارائه میدهد. اول، اکثر سیستمها، بزرگ و کوچک، میتوانند به صورت یک DAG نمایش داده شوند. دوم، پسپردازش DP [بخش 2.1] و لم ترکیبی 2.4 در پیچیدگی ویژگیهای حریم خصوصی دیفرانسیلی ، ابزارهای قدرتمندی را برای تجزیه و تحلیل (بدترین حالت) بدهبستان حریم خصوصی و دقت برای کل گراف ارائه میدهند:
- پسپردازش تضمین میکند که وقتی یک کمیت خصوصیسازی میشود، اگر دادههای اصلی دوباره استفاده نشوند، نمیتوان آن را «از حالت خصوصی خارج کرد». تا زمانی که همه ورودیهای یک گره خصوصی باشند، خروجی آن نیز صرف نظر از محاسباتش، خصوصی خواهد بود.
- ترکیب پیشرفته تضمین میکند که اگر هر بخش گراف DP باشد، گراف کلی نیز DP است، که به طور مؤثر ε و δ خروجی نهایی گراف را به ترتیب تقریباً ε√κ محدود میکند، با فرض اینکه گراف دارای واحد κ است و خروجی هر واحد (ε, δ)-DP است.
این دو ویژگی به دو اصل طراحی برای هر گره تبدیل میشوند:
- ویژگی ۱ (از پسپردازش) اگر ورودیهای یک گره همگی DP باشند، خروجی آن DP است که با هر منطق تجاری دلخواه اجرا شده در گره سازگار است و از «مخفیکاریهای» کسبوکارها پشتیبانی میکند.
- ویژگی ۲ (از ترکیب پیشرفته) اگر ورودیهای یک گره همگی DP نباشند، خروجی آن باید با DP سازگار شود. اگر یک گره محاسباتی گرهای باشد که روی محیطهای اجرای مطمئن اجرا میشود و بارهای کاری و پیکربندیهای متنباز و شخصیسازیشده روی دستگاه را اجرا میکند، در این صورت میتوان از مرزهای DP دقیقتری استفاده کرد. در غیر این صورت، شخصیسازی روی دستگاه ممکن است نیاز به استفاده از مرزهای DP در بدترین حالت داشته باشد. به دلیل محدودیتهای منابع، محیطهای اجرای مطمئن ارائه شده توسط یک ارائهدهنده ابر عمومی در ابتدا در اولویت قرار میگیرند.
حریم خصوصی محیط محاسبات در مقابل دقت خروجی
از این پس، شخصیسازی روی دستگاه بر افزایش امنیت محیطهای محاسباتی محرمانه و اطمینان از غیرقابل دسترس ماندن حالتهای میانی تمرکز خواهد کرد. این فرآیند امنیتی که به عنوان مهر و موم کردن شناخته میشود، در سطح زیرگراف اعمال میشود و به چندین گره اجازه میدهد تا با هم با DP سازگار شوند. این بدان معناست که ویژگی ۱ و ویژگی ۲ که قبلاً ذکر شد، در سطح زیرگراف اعمال میشوند.

البته خروجی نهایی نمودار، خروجی ۷، به ازای هر ترکیب DP میشود. این بدان معناست که در مجموع ۲ DP برای این نمودار وجود خواهد داشت؛ در مقایسه با ۳ DP کلی (موضعی) اگر از هیچ آببندی استفاده نشود.
اساساً، با ایمنسازی محیط محاسباتی و حذف فرصتهای دسترسی دشمنان به ورودیها و حالتهای میانی یک گراف یا زیرگراف، این امر امکان پیادهسازی DP مرکزی (یعنی خروجی یک محیط مهر و موم شده مطابق با DP است) را فراهم میکند، که میتواند دقت را در مقایسه با DP محلی (یعنی ورودیهای منفرد مطابق با DP هستند) بهبود بخشد. این اصل، زیربنای در نظر گرفتن FC، TEEها، sMPCها و HPEها به عنوان فناوریهای حریم خصوصی است. به فصل 10 در پیچیدگی حریم خصوصی تفاضلی مراجعه کنید.
یک مثال خوب و کاربردی، آموزش مدل و استنتاج است. بحثهای زیر فرض میکنند که (1)، جمعیت آموزشی و جمعیت استنتاج با هم همپوشانی دارند، و (2)، هم ویژگیها و هم برچسبها، دادههای کاربر خصوصی را تشکیل میدهند. میتوانیم DP را برای همه ورودیها اعمال کنیم:

شخصیسازی روی دستگاه میتواند DP محلی را قبل از ارسال برچسبها و ویژگیهای کاربر به سرورها اعمال کند. این رویکرد هیچ الزامی بر محیط اجرای سرور یا منطق کسبوکار آن تحمیل نمیکند.



این طرح شخصیسازی روی دستگاه فعلی است.
قابل تأیید، خصوصی
شخصیسازی روی دستگاه (On-Device Personalization) با هدف حفظ حریم خصوصی قابل تأیید انجام میشود. این رویکرد بر تأیید اتفاقاتی که خارج از دستگاههای کاربر رخ میدهد، تمرکز دارد. ODP کدی را که دادههای خروجی از دستگاههای کاربر نهایی را پردازش میکند، مینویسد و از معماری رویههای تأیید از راه دور (RATS) RFC 9334 NIST برای تأیید اینکه چنین کدی بدون تغییر در یک سرور بدون دسترسی مدیر نمونه و مطابق با کنسرسیوم محاسبات محرمانه اجرا میشود، استفاده خواهد کرد. این کدها متنباز و برای تأیید شفاف جهت ایجاد اعتماد، در دسترس خواهند بود. چنین اقداماتی میتواند به افراد اطمینان دهد که دادههایشان محافظت میشود و کسبوکارها میتوانند بر اساس پایهای قوی از تضمین حریم خصوصی، شهرت ایجاد کنند.
کاهش میزان دادههای خصوصی جمعآوری و ذخیرهشده، یکی دیگر از جنبههای حیاتی شخصیسازی درون دستگاهی است. این روش با اتخاذ فناوریهایی مانند محاسبات فدرال و حریم خصوصی تفاضلی، به این اصل پایبند است و امکان آشکارسازی الگوهای ارزشمند دادهها را بدون افشای جزئیات حساس فردی یا اطلاعات قابل شناسایی فراهم میکند.
حفظ یک مسیر حسابرسی که فعالیتهای مربوط به پردازش و اشتراکگذاری دادهها را ثبت میکند، یکی دیگر از جنبههای کلیدی حریم خصوصی قابل تأیید است. این امر امکان ایجاد گزارشهای حسابرسی و شناسایی آسیبپذیریها را فراهم میکند و تعهد ما به حریم خصوصی را نشان میدهد.
ما از متخصصان حریم خصوصی، مقامات، صنایع و افراد درخواست همکاری سازنده داریم تا به ما در بهبود مستمر طراحی و پیادهسازی کمک کنند.
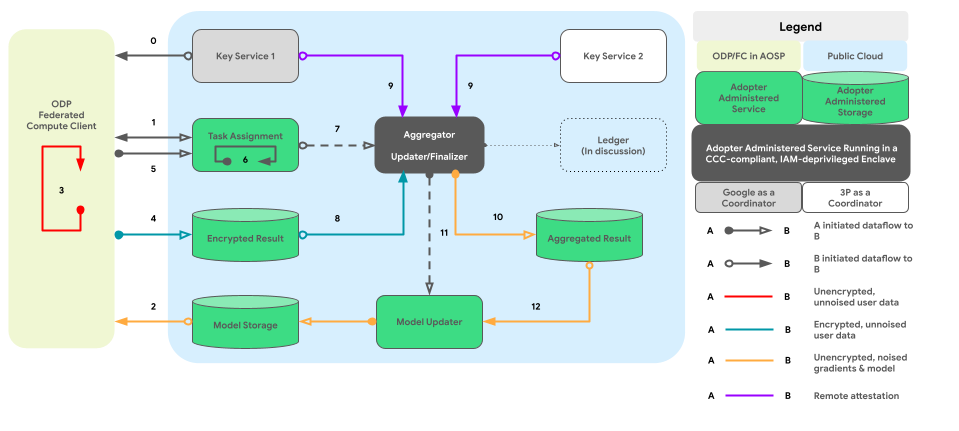
نمودار زیر مسیر کد برای تجمیع و نویزدهی بین دستگاهی را به ازای هر Differential Privacy نشان میدهد.
طراحی سطح بالا
چگونه میتوان حریم خصوصی را از طریق محرمانگی پیادهسازی کرد؟ در سطح بالا، یک موتور سیاستگذاری که توسط ODP نوشته شده و در یک محیط مهر و موم شده اجرا میشود، به عنوان مؤلفه اصلی بر هر گره/زیرگراف نظارت میکند و در عین حال وضعیت DP ورودیها و خروجیهای آنها را ردیابی میکند:
- از دیدگاه موتور سیاست، با دستگاهها و سرورها یکسان رفتار میشود. دستگاهها و سرورهایی که موتور سیاست یکسانی را اجرا میکنند، پس از اینکه موتورهای سیاست آنها به طور متقابل تأیید شدند، منطقاً یکسان در نظر گرفته میشوند.
- در دستگاهها، جداسازی از طریق فرآیندهای ایزوله AOSP (یا pKVM در درازمدت پس از افزایش دسترسیپذیری) حاصل میشود. در سرورها، جداسازی به یک «طرف قابل اعتماد» متکی است که یا یک TEE به علاوه سایر راهحلهای آببندی فنی ترجیحی، یک توافق قراردادی یا هر دو است.
به عبارت دیگر، تمام محیطهای مهر و موم شده که موتور سیاست پلتفرم را نصب و اجرا میکنند، بخشی از پایگاه محاسبات قابل اعتماد (TCB) ما محسوب میشوند. دادهها میتوانند بدون نویز اضافی با TCB منتشر شوند. DP باید هنگام خروج دادهها از TCB اعمال شود.
طراحی سطح بالای شخصیسازی روی دستگاه، دو عنصر اساسی را به طور مؤثر ادغام میکند:
- معماری فرآیند جفتشده برای اجرای منطق کسبوکار
- سیاستها و یک موتور سیاستگذاری برای مدیریت ورود، خروج و عملیات مجاز دادهها.
این طراحی منسجم، به کسبوکارها بستری برابر ارائه میدهد که در آن میتوانند کد اختصاصی خود را در یک محیط اجرایی قابل اعتماد اجرا کنند و به دادههای کاربری که بررسیهای مناسب سیاستها را پشت سر گذاشتهاند، دسترسی داشته باشند.
بخشهای بعدی به این دو جنبه کلیدی خواهند پرداخت.
معماری پردازش جفتی برای اجرای منطق کسبوکار
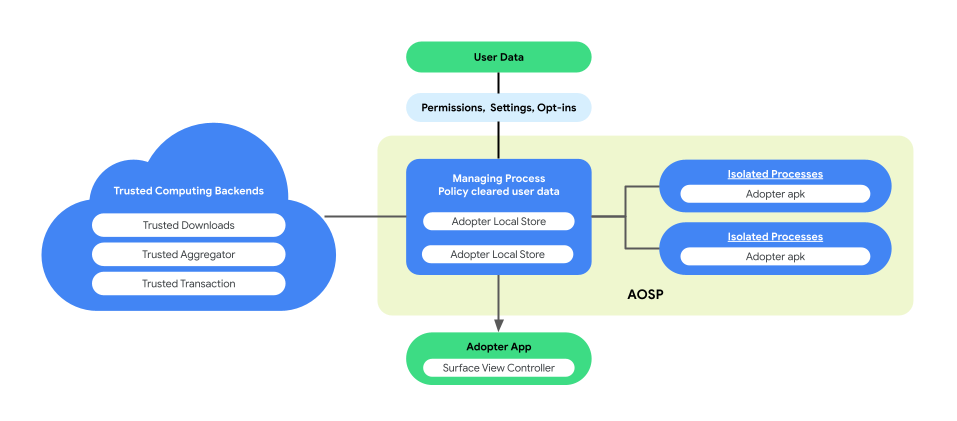
شخصیسازی روی دستگاه، معماری پردازش جفتشده را در AOSP معرفی میکند تا حریم خصوصی کاربر و امنیت دادهها را در حین اجرای منطق کسبوکار افزایش دهد. این معماری شامل موارد زیر است:
ManagingProcess. این فرآیند، IsolatedProcesses را ایجاد و مدیریت میکند و تضمین میکند که آنها در سطح فرآیند ایزوله باقی بمانند و دسترسی آنها محدود به APIهای مجاز و بدون مجوزهای شبکه یا دیسک باشد. ManagingProcess جمعآوری تمام دادههای تجاری، تمام دادههای کاربر نهایی و سیاستها را مدیریت میکند و آنها را برای کد تجاری پاک میکند و آنها را برای اجرا به IsolatedProcesses ارسال میکند. علاوه بر این، تعامل بین IsolatedProcesses و سایر فرآیندها، مانند system_server، را میانجیگری میکند.
IsolatedProcess. این فرآیند که به عنوان ایزوله (
isolatedprocess=trueدر مانیفست) تعیین شده است، دادههای تجاری، دادههای کاربر نهایی که از طریق سیاستها پاک شدهاند و کد تجاری را از ManagingProcess دریافت میکند. این فرآیندها به کد تجاری اجازه میدهند تا روی دادههای خود و دادههای کاربر نهایی که از طریق سیاستها پاک شدهاند، عمل کند. IsolatedProcess منحصراً برای ورود و خروج با ManagingProcess ارتباط برقرار میکند، بدون هیچ مجوز اضافی.
معماری فرآیند جفتشده، امکان تأیید مستقل سیاستهای حفظ حریم خصوصی دادههای کاربر نهایی را بدون نیاز به متنباز کردن منطق یا کد کسبوکار توسط کسبوکارها فراهم میکند. با حفظ استقلال IsolatedProcesses توسط ManagingProcess و اجرای کارآمد منطق کسبوکار توسط IsolatedProcesses، این معماری یک راهحل امنتر و کارآمدتر برای حفظ حریم خصوصی کاربر در طول شخصیسازی را تضمین میکند.
شکل زیر این معماری فرآیند جفتشده را نشان میدهد.
سیاستها و موتورهای سیاستگذاری برای عملیات داده
شخصیسازی روی دستگاه، یک لایه اجرای سیاست بین پلتفرم و منطق کسبوکار معرفی میکند. هدف، ارائه مجموعهای از ابزارها است که کنترلهای کاربر نهایی و کسبوکار را به تصمیمات سیاستی متمرکز و قابل اجرا تبدیل میکند. سپس این سیاستها به طور جامع و قابل اعتماد در جریانها و کسبوکارها اجرا میشوند.
در معماری فرآیند جفتشده، موتور سیاستگذاری درون ManagingProcess قرار دارد و بر ورود و خروج دادههای کاربر نهایی و کسبوکار نظارت میکند. همچنین عملیات مجاز را به IsolatedProcess ارائه میدهد. حوزههای پوشش نمونه شامل احترام به کنترل کاربر نهایی، محافظت از کودکان، جلوگیری از اشتراکگذاری بدون رضایت دادهها و حریم خصوصی کسبوکار است.
این معماری اجرای سیاست شامل سه نوع گردش کار است که میتوانند مورد استفاده قرار گیرند:
- گردشهای کاری آفلاین و محلی با ارتباطات محیط اجرایی قابل اعتماد (TEE):
- جریانهای دانلود دادهها: دانلودهای قابل اعتماد
- جریانهای آپلود دادهها: تراکنشهای مورد اعتماد
- گردشهای کاری آنلاین و محلی:
- جریانهای خدمترسانی بلادرنگ
- جریانهای استنتاج
- گردشهای کاری آفلاین و آغاز شده به صورت محلی:
- جریانهای بهینهسازی: آموزش مدل روی دستگاه که از طریق یادگیری فدرال (FL) پیادهسازی شده است
- جریانهای گزارشدهی: تجمیع بین دستگاهی از طریق Federated Analytics (FA) پیادهسازی شده است
شکل زیر معماری را از منظر سیاستها و موتورهای سیاست نشان میدهد.
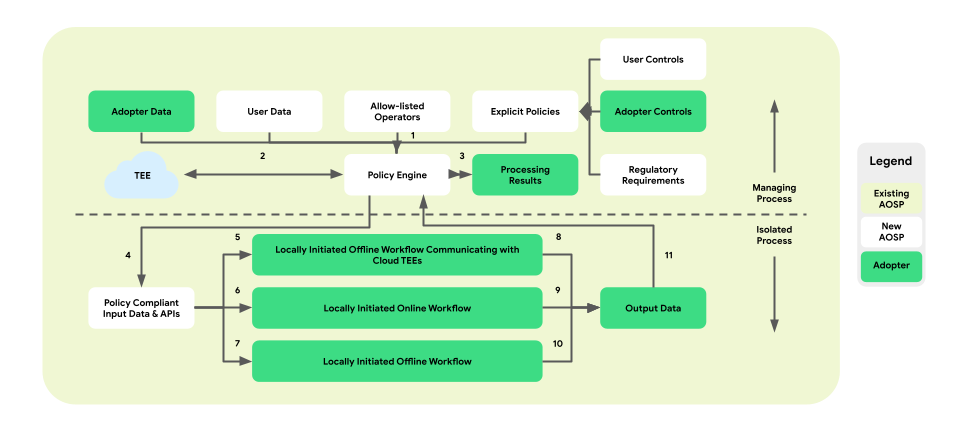
- دانلود: ۱ -> ۲ -> ۴ -> ۷ -> ۱۰ -> ۱۱ -> ۳
- تعداد سرو: ۱ + ۳ -> ۴ -> ۶ -> ۹ -> ۱۱ -> ۳
- بهینهسازی: ۲ (طرح آموزشی را ارائه میدهد) -> ۱ + ۳ -> ۴ -> ۵ -> ۸ -> ۱۱ -> ۲
- گزارشدهی: ۳ (طرح تجمیع را ارائه میدهد) -> ۱ + ۳ -> ۴ -> ۵ -> ۸ -> ۱۱ -> ۲
در مجموع، معرفی لایه اجرای سیاست و موتور سیاست در معماری پردازش جفتشدهی شخصیسازی روی دستگاه، محیطی ایزوله و حافظ حریم خصوصی را برای اجرای منطق کسبوکار تضمین میکند و در عین حال دسترسی کنترلشده به دادهها و عملیات لازم را فراهم میآورد.
سطوح API لایه بندی شده
شخصیسازی روی دستگاه، یک معماری API لایهای را برای کسبوکارهای علاقهمند فراهم میکند. لایه بالایی شامل برنامههایی است که برای موارد استفاده خاص ساخته شدهاند. کسبوکارهای بالقوه میتوانند دادههای خود را به این برنامهها که به عنوان APIهای لایه بالایی شناخته میشوند، متصل کنند. APIهای لایه بالایی بر روی APIهای لایه میانی ساخته شدهاند.
با گذشت زمان، انتظار داریم APIهای لایه بالایی بیشتری اضافه کنیم. وقتی API لایه بالایی برای یک مورد استفاده خاص در دسترس نباشد، یا وقتی APIهای لایه بالایی موجود به اندازه کافی انعطافپذیر نباشند، کسبوکارها میتوانند مستقیماً APIهای لایه میانی را پیادهسازی کنند که از طریق برنامهنویسی اولیه، قدرت و انعطافپذیری را فراهم میکنند.
نتیجهگیری
شخصیسازی روی دستگاه، یک طرح تحقیقاتی در مراحل اولیه برای جلب توجه و بازخورد در مورد یک راهحل بلندمدت است که با جدیدترین و بهترین فناوریهایی که انتظار میرود کاربرد بالایی داشته باشند، به نگرانیهای مربوط به حریم خصوصی کاربر نهایی میپردازد.
ما مایلیم با ذینفعان مانند متخصصان حریم خصوصی، تحلیلگران داده و کاربران نهایی بالقوه تعامل داشته باشیم تا اطمینان حاصل کنیم که ODP نیازها و نگرانیهای آنها را برآورده میکند.