
本文档总结了设备端个性化 (ODP) 的隐私保护方法,尤其是在差分隐私的背景下。为了使本文档重点突出,我们有意省略了其他隐私影响和设计决策(例如数据最小化)。
差分隐私
差分隐私 1 是统计数据分析和机器学习领域广泛采用的隐私保护标准 2 3。简单来说,差分隐私性是指,无论用户的记录是否出现在底层数据集中,攻击者从差分隐私算法的输出中了解到的用户信息几乎相同。这意味着对个人用户提供强有力的保护:对某人做出的任何推理都只能基于数据集的汇总属性,无论是否包含该用户的记录,这些属性都成立。
在机器学习的背景下,算法的输出应被视为训练后的模型参数。几乎相同这一概念在数学上由两个形参 (ε, δ) 来量化,其中 ε 通常选择为较小的常数,而 δ≪1/(用户数量)。
隐私权语义
ODP 设计旨在确保每次训练运行都具有 (ε,δ) 用户级差分隐私。下文概述了我们实现此语义的方法。
威胁模型
我们定义了不同的当事方,并针对每个当事方陈述了假设:
- 用户:设备的所有者,也是开发者提供的产品或服务的消费者。他们可以完全访问自己的私密信息。
- 可信执行环境 (TEE):TEE 中发生的数据和可信计算会受到各种技术的保护,免遭攻击者的侵害。因此,计算和数据无需额外保护。现有 TEE 可能允许其项目管理员访问其中的信息。我们建议使用自定义功能来禁止并验证管理员是否无法访问。
- 攻击者:可能掌握有关用户的辅助信息,并且可以完全访问离开 TEE 的任何信息(例如已发布模型参数)。
- 开发者:定义和训练模型的人员。被视为不受信任(并且具有攻击者的全部能力)。
我们力求在设计 ODP 时实现以下差分隐私语义:
- 信任边界:从用户的角度来看,信任边界由用户自己的设备以及 TEE 组成。离开此信任边界的任何信息都应受到差分隐私保护。
- 攻击者:针对攻击者的完整差分隐私保护。信任边界之外的任何实体都可能是攻击者(包括开发者和其他用户,他们可能会串通一气)。在给定信任边界之外的所有信息(例如已发布模型)、有关用户的任何辅助信息以及无限资源的情况下,攻击者无法推断出有关用户的其他私密数据(超出辅助信息中已有的数据),但隐私预算给出的几率除外。 具体而言,这意味着针对开发者提供全面的差分隐私保护。向开发者发布的所有信息(例如训练后的模型参数或汇总推理结果)都受到差分隐私保护。
本地模型参数
之前的隐私语义可适应以下情况:部分模型参数在设备本地(例如,包含特定于每个用户且不跨用户共享的用户嵌入的模型)。对于此类模型,这些本地参数保留在信任边界内(无法发布),无需保护,而共享模型参数会发布(并受到差分隐私保护)。这有时称为广告牌隐私权模型 4。
公开功能
在某些应用中,部分功能是公开的。例如,在电影推荐问题中,电影的特征(导演、类型或发行年份)是公开信息,不需要保护,而与用户相关的特征(例如人口统计信息或用户观看的电影)是私密数据,需要保护。
公开信息会以公开特征矩阵的形式正式提供给所有各方(在前面的示例中,此矩阵将包含每部电影一行,每个电影特征一列)。差分隐私训练算法可以利用此矩阵,而无需对其进行保护,例如,请参阅5。ODP 平台计划实现此类算法。
预测或推理期间的隐私保护方法
推理基于模型参数和输入特征。模型参数是根据差分隐私语义进行训练的。本部分将讨论输入特征的作用。
在某些使用情形下,如果开发者已完全访问推理中使用的功能,则推理不会带来隐私问题,并且开发者可能会看到推理结果。
在其他情况下(当推理中使用的功能是私密的,开发者无法访问时),推理结果可能会对开发者隐藏,例如,通过在设备上、在操作系统拥有的进程和显示区域中运行推理(以及使用推理结果的任何下游进程),并限制该进程之外的通信。
训练程序
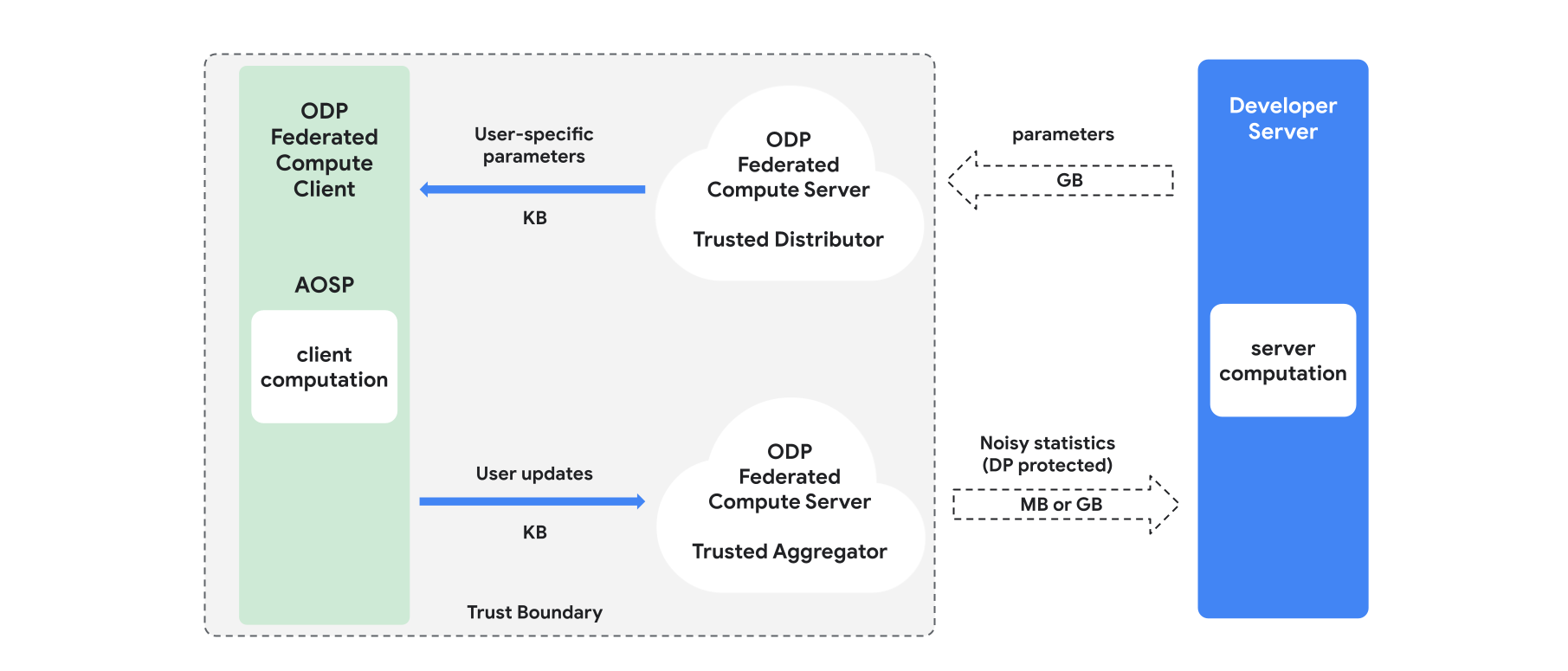
概览
本部分概述了架构以及训练的进行方式,如图 1 所示。 ODP 实现以下组件:
可信的分发者,例如联邦选择、可信下载或私密信息检索,用于广播模型参数。假设可信分发者可以向每个客户端发送一部分参数,而不会泄露哪些参数被哪些客户端下载。这种“部分广播”可让系统最大限度地减少对最终用户设备的占用空间:系统不会发送模型的完整副本,而是仅向任何给定用户发送一部分模型参数。
可信的聚合器,用于聚合来自多个客户端的信息(例如梯度或其他统计信息)、添加噪声,并将结果发送到服务器。假设客户端与汇总器之间以及客户端与分发器之间存在可信渠道。
在此基础设施上运行的 DP 训练算法。每种训练算法都包含在不同组件(服务器、客户端、聚合器、分发器)上运行的不同计算。
典型的训练轮次包括以下步骤:
- 服务器将模型参数广播给可信的分发者。
- 客户端计算
- 每个客户端设备都会接收广播模型(或与用户相关的参数子集)。
- 每个客户端都会执行一些计算(例如计算梯度或其他充分统计信息)。
- 每个客户端都会将计算结果发送给可信的汇总方。
- 可信的汇总器会收集、汇总并使用适当的差分隐私机制保护来自客户端的统计信息,然后将结果发送到服务器。
- 服务器计算
- (不受信任的)服务器对受差分隐私保护的统计信息运行计算(例如,使用差分隐私聚合梯度来更新模型参数)。
分解模型和差分隐私交替最小化
ODP 平台计划提供可应用于任何模型架构的通用差分隐私训练算法(例如 DP-SGD 6 7 8 或 DP-FTRL 9 10),以及专门用于分解模型的算法。
分解模型是指可以分解为子模型(称为编码器或塔)的模型。例如,考虑一个形如 f(u(θu, xu), v(θv, xv)) 的模型,其中 u() 对用户特征 xu 进行编码(并具有参数 θu),而 v() 对非用户特征 xv 进行编码(并具有参数 θv)。这两个编码使用 f() 进行组合,以生成最终的模型预测。例如,在电影推荐模型中,xu 是用户特征,xv 是电影特征。
此类模型非常适合上述分布式系统架构(因为它们会分离用户特征和非用户特征)。
分解模型将使用差分隐私交替最小化 (DPAM) 进行训练,该方法会在优化参数 θu(同时固定 θv)和优化参数 θv(同时固定 θu)之间交替进行。研究表明,DPAM 算法在各种设置下都能实现更好的效用 4 11,尤其是在存在公开特征的情况下。
参考
- 1:Dwork 等人,《Calibrating Noise to Sensitivity in Private Data Analysis》,TCC'06
- 2:美国人口普查局。了解差分隐私,2020 年
- 3:Federated Learning with Formal Differential Privacy Guarantees,Google AI 博文,2020 年
- 4:Jain 等人,Differentially Private Model Personalization,NeurIPS'21
- 5:Krichene 等人,Private Learning with Public Features,2023 年
- 6:Song 等人,Stochastic gradient descent with differentially private updates,GlobalSIP'13
- 7:Differentially Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds,FOCS'14
- 8:Abadi 等人,《Deep Learning with Differential Privacy》,CCS '16
- 9:Smith 等人,用于全信息和 Bandit 设置中私密在线学习的(近乎)最优算法,NeurIPS'13
- 10:Kairouz 等人,Practical and Private (Deep) Learning without Sampling or Shuffling, ICML'21
- 11:Chien 等人,Private Alternating Least Squares,ICML'21