
Tài liệu này tóm tắt phương pháp bảo vệ quyền riêng tư cho hoạt động Cá nhân hoá trên thiết bị (ODP), đặc biệt là trong bối cảnh quyền riêng tư vi phân. Các tác động khác đến quyền riêng tư và quyết định thiết kế (chẳng hạn như giảm thiểu dữ liệu) được cố ý bỏ qua để giữ cho tài liệu này tập trung vào một chủ đề.
Sự riêng tư biệt lập
Quyền riêng tư vi phân 1 là một tiêu chuẩn được áp dụng rộng rãi để bảo vệ quyền riêng tư trong phân tích dữ liệu thống kê và học máy 2 3. Một cách không chính thức, sự riêng tư biệt lập cho biết rằng đối phương sẽ biết gần như cùng một thông tin về người dùng từ đầu ra của một thuật toán riêng tư biệt lập, cho dù bản ghi của người dùng có xuất hiện trong tập dữ liệu cơ bản hay không. Điều này ngụ ý rằng các cá nhân sẽ được bảo vệ mạnh mẽ: mọi suy luận về một người chỉ có thể là do các thuộc tính tổng hợp của tập dữ liệu, bất kể có bản ghi của người đó hay không.
Trong bối cảnh học máy, đầu ra của thuật toán nên được coi là các thông số mô hình đã huấn luyện. Cụm từ gần như giống nhau được định lượng bằng hai tham số (ε, δ), trong đó ε thường được chọn là một hằng số nhỏ và δ≪1/(số người dùng).
Ngữ nghĩa về quyền riêng tư
Thiết kế ODP nhằm đảm bảo mỗi lần chạy huấn luyện đều có quyền riêng tư khác biệt ở cấp độ người dùng (ε,δ). Sau đây là cách tiếp cận của chúng tôi để đạt được ngữ nghĩa này.
Mô hình mối đe doạ
Chúng ta xác định các bên liên quan và nêu ra các giả định về từng bên:
- Người dùng: Người dùng sở hữu thiết bị và là người tiêu dùng các sản phẩm hoặc dịch vụ do nhà phát triển cung cấp. Họ có thể xem toàn bộ thông tin riêng tư của mình.
- Môi trường thực thi đáng tin cậy (TEE): Dữ liệu và các phép tính đáng tin cậy diễn ra trong TEE được bảo vệ khỏi những kẻ tấn công bằng nhiều công nghệ. Do đó, việc tính toán và dữ liệu không cần được bảo vệ thêm. Các TEE hiện có có thể cho phép quản trị viên dự án truy cập vào thông tin bên trong. Chúng tôi đề xuất các chức năng tuỳ chỉnh để ngăn chặn và xác thực rằng quản trị viên không có quyền truy cập.
- Kẻ tấn công: Có thể có thông tin bên lề về người dùng và có toàn quyền truy cập vào mọi thông tin rời khỏi TEE (chẳng hạn như các tham số mô hình đã xuất bản).
- Nhà phát triển: Người xác định và huấn luyện mô hình. Được coi là không đáng tin cậy (và có toàn bộ khả năng của kẻ tấn công).
Chúng tôi cố gắng thiết kế ODP với các ngữ nghĩa sau về sự riêng tư biệt lập:
- Ranh giới tin cậy: Theo quan điểm của một người dùng, ranh giới tin cậy bao gồm thiết bị của chính người dùng đó cùng với TEE. Mọi thông tin nằm ngoài ranh giới tin cậy này đều phải được bảo vệ bằng sự riêng tư biệt lập.
- Kẻ tấn công: Bảo vệ quyền riêng tư biệt lập hoàn toàn đối với kẻ tấn công. Mọi thực thể bên ngoài ranh giới tin cậy đều có thể là kẻ tấn công (bao gồm cả nhà phát triển và những người dùng khác, tất cả đều có khả năng thông đồng). Kẻ tấn công, khi có tất cả thông tin bên ngoài ranh giới tin cậy (ví dụ: mô hình đã xuất bản), mọi thông tin phụ về người dùng và vô số tài nguyên, sẽ không thể suy luận thêm dữ liệu riêng tư về người dùng (ngoài những dữ liệu đã có trong thông tin phụ), cho đến khi đạt được tỷ lệ do ngân sách quyền riêng tư cung cấp. Cụ thể, điều này ngụ ý rằng nhà phát triển sẽ được bảo vệ hoàn toàn về quyền riêng tư biệt lập. Mọi thông tin được phát hành cho nhà phát triển (chẳng hạn như các thông số mô hình đã huấn luyện hoặc suy luận tổng hợp) đều được bảo vệ bằng quyền riêng tư vi phân.
Tham số mô hình cục bộ
Ngữ nghĩa về quyền riêng tư trước đây phù hợp với trường hợp một số tham số mô hình là cục bộ đối với thiết bị (ví dụ: một mô hình chứa thông tin nhúng người dùng dành riêng cho từng người dùng và không được chia sẻ giữa những người dùng). Đối với những mô hình như vậy, các thông số cục bộ này vẫn nằm trong ranh giới tin cậy (chúng không được xuất bản) và không cần được bảo vệ, trong khi các thông số mô hình được chia sẻ sẽ được xuất bản (và được bảo vệ bằng quyền riêng tư vi sai). Đây đôi khi được gọi là mô hình quyền riêng tư trên bảng quảng cáo 4.
Tính năng công khai
Trong một số ứng dụng, một số tính năng là công khai. Ví dụ: trong vấn đề đề xuất phim, các đặc điểm của một bộ phim (đạo diễn, thể loại hoặc năm phát hành của bộ phim) là thông tin công khai và không cần được bảo vệ, trong khi các đặc điểm liên quan đến người dùng (chẳng hạn như thông tin nhân khẩu học hoặc những bộ phim mà người dùng đã xem) là dữ liệu riêng tư và cần được bảo vệ.
Thông tin công khai được chính thức hoá dưới dạng một ma trận tính năng công khai (trong ví dụ trước, ma trận này sẽ chứa một hàng cho mỗi bộ phim và một cột cho mỗi tính năng của bộ phim), được cung cấp cho tất cả các bên. Thuật toán huấn luyện riêng tư vi phân có thể sử dụng ma trận này mà không cần bảo vệ, chẳng hạn như 5. Nền tảng ODP dự định triển khai các thuật toán như vậy.
Phương pháp tiếp cận quyền riêng tư trong quá trình dự đoán hoặc suy luận
Suy luận dựa trên các tham số mô hình và các đặc điểm đầu vào. Các tham số mô hình được huấn luyện bằng ngữ nghĩa về quyền riêng tư biệt lập. Trong đó, vai trò của các đặc điểm đầu vào sẽ được thảo luận.
Trong một số trường hợp sử dụng, khi nhà phát triển đã có toàn quyền truy cập vào các tính năng được dùng trong quá trình suy luận, thì không có vấn đề nào về quyền riêng tư từ quá trình suy luận và nhà phát triển có thể thấy kết quả suy luận.
Trong các trường hợp khác (khi các tính năng được dùng trong quá trình suy luận là riêng tư và nhà phát triển không truy cập được), kết quả suy luận có thể bị ẩn đối với nhà phát triển, chẳng hạn như bằng cách chạy quá trình suy luận (và mọi quy trình tiếp theo sử dụng kết quả suy luận) trên thiết bị, trong một quy trình và vùng hiển thị do hệ điều hành sở hữu, với hoạt động giao tiếp bị hạn chế bên ngoài quy trình đó.
Quy trình đào tạo
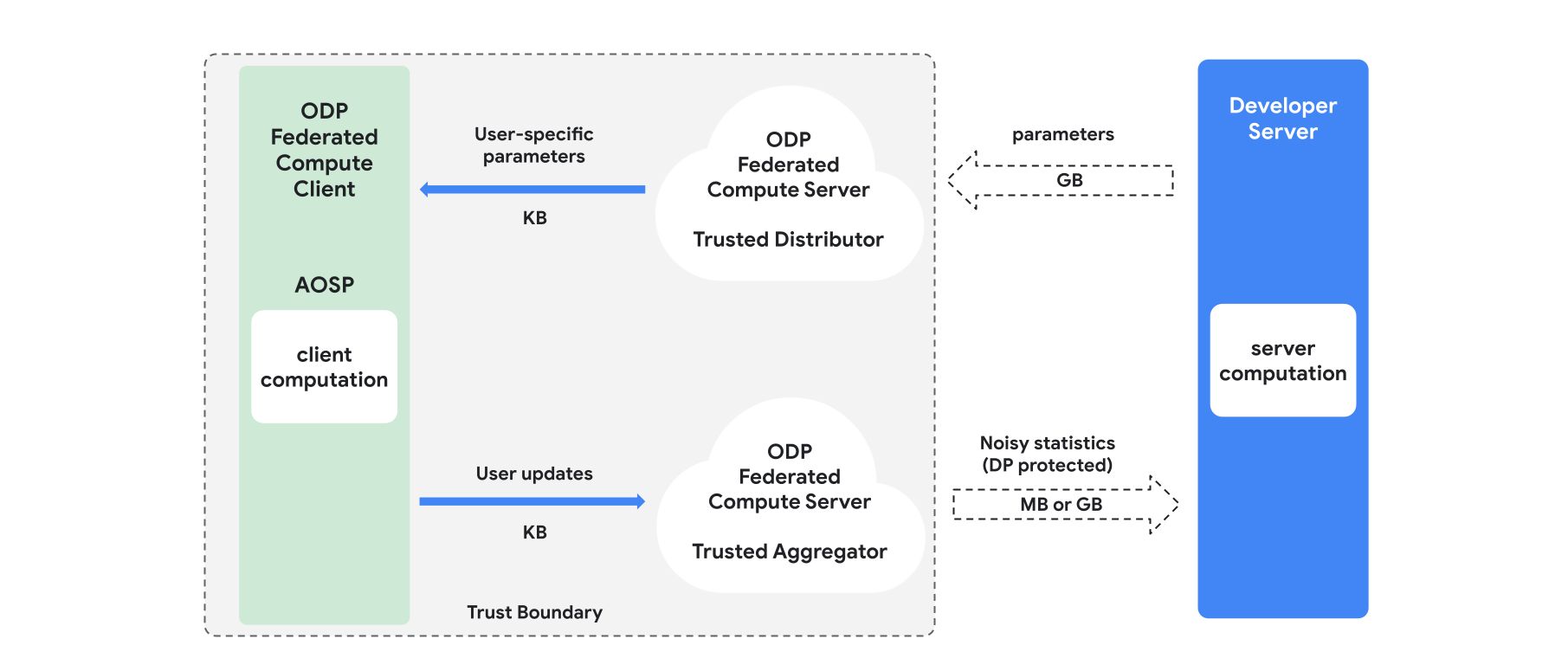
Tổng quan
Phần này cung cấp thông tin tổng quan về cấu trúc và cách tiến hành huấn luyện, hãy xem Hình 1. ODP triển khai các thành phần sau:
Một nhà phân phối đáng tin cậy, chẳng hạn như federated select, trusted download hoặc private information retrieval, đóng vai trò là phát các tham số mô hình. Giả sử rằng nhà phân phối đáng tin cậy có thể gửi một tập hợp con các thông số cho mỗi ứng dụng mà không tiết lộ ứng dụng nào đã tải thông số nào xuống. "Thông báo truyền tin một phần" này cho phép hệ thống giảm thiểu mức sử dụng bộ nhớ trên thiết bị của người dùng cuối: thay vì gửi toàn bộ bản sao của mô hình, hệ thống chỉ gửi một phần nhỏ các tham số mô hình cho bất kỳ người dùng nào.
Một đơn vị tổng hợp đáng tin cậy, tổng hợp thông tin từ nhiều máy khách (ví dụ: độ dốc hoặc các số liệu thống kê khác), thêm nhiễu và gửi kết quả đến máy chủ. Giả định là có các kênh đáng tin cậy giữa ứng dụng và đơn vị tổng hợp, cũng như giữa ứng dụng và nhà phân phối.
Các thuật toán huấn luyện DP chạy trên cơ sở hạ tầng này. Mỗi thuật toán huấn luyện bao gồm nhiều phép tính chạy trên các thành phần khác nhau (máy chủ, máy khách, bộ tổng hợp, bộ phân phối).
Một vòng huấn luyện điển hình bao gồm các bước sau:
- Máy chủ phát các thông số mô hình cho nhà phân phối đáng tin cậy.
- Tính toán phía máy khách
- Mỗi thiết bị của khách hàng sẽ nhận được mô hình truyền tin (hoặc một nhóm nhỏ các thông số liên quan đến người dùng).
- Mỗi máy khách thực hiện một số phép tính (ví dụ: tính toán độ dốc hoặc các số liệu thống kê đủ khác).
- Mỗi ứng dụng sẽ gửi kết quả tính toán đến trình tổng hợp đáng tin cậy.
- Trình tổng hợp đáng tin cậy thu thập, tổng hợp và bảo vệ số liệu thống kê từ các máy khách bằng các cơ chế thích hợp về sự riêng tư biệt lập, sau đó gửi kết quả đến máy chủ.
- Tính toán phía máy chủ
- Máy chủ (không đáng tin cậy) chạy các phép tính trên số liệu thống kê được bảo vệ quyền riêng tư một cách khác biệt (ví dụ: sử dụng các độ dốc tổng hợp riêng tư một cách khác biệt để cập nhật các tham số mô hình).
Mô hình phân tích và Giảm thiểu thay thế riêng tư khác biệt
Nền tảng ODP dự định cung cấp các thuật toán huấn luyện riêng tư vi phân cho mục đích chung có thể áp dụng cho mọi cấu trúc mô hình (chẳng hạn như DP-SGD 6 7 8 hoặc DP-FTRL 9 10, cũng như các thuật toán chuyên biệt cho các mô hình phân tích.
Mô hình được phân tích là những mô hình có thể được phân tách thành các mô hình phụ (gọi là bộ mã hoá hoặc tháp). Ví dụ: hãy xem xét một mô hình có dạng f(u(θu, xu), v(θv, xv)), trong đó u() mã hoá các đặc điểm của người dùng xu (và có các tham số θu), còn v() mã hoá các đặc điểm không phải của người dùng xv (và có các tham số θv). Hai phương thức mã hoá này được kết hợp bằng cách sử dụng f() để tạo ra dự đoán cuối cùng của mô hình. Ví dụ: trong mô hình đề xuất phim, xu là các đặc điểm của người dùng và xv là các đặc điểm của phim.
Những mô hình như vậy rất phù hợp với cấu trúc hệ thống phân tán nêu trên (vì chúng tách biệt các tính năng của người dùng và không phải người dùng).
Các mô hình được phân tích sẽ được huấn luyện bằng cách sử dụng phương pháp Giảm thiểu thay thế riêng tư khác biệt (DPAM), phương pháp này sẽ thay phiên nhau tối ưu hoá các tham số θu (trong khi θv được cố định) và ngược lại. Các thuật toán DPAM đã cho thấy khả năng đạt được tiện ích tốt hơn trong nhiều chế độ cài đặt 4 11, đặc biệt là khi có các tính năng công khai.
Tài liệu tham khảo
- 1: Dwork và cộng sự. Calibrating Noise to Sensitivity in Private Data Analysis, TCC'06
- 2: Cục Thống kê Dân số Hoa Kỳ. Tìm hiểu về Quyền riêng tư biệt lập, năm 2020
- 3: Học liên kết với các đảm bảo chính thức về quyền riêng tư vi sai, Bài đăng trên blog về AI của Google, 2020
- 4: Jain và cộng sự. Cá nhân hoá mô hình riêng tư vi phân, NeurIPS'21
- 5: Krichene và cộng sự. Private Learning with Public Features (Học tập riêng tư bằng các tính năng công khai), 2023
- 6: Song và cộng sự. Stochastic gradient descent with differentially private updates (Phương pháp hạ độ dốc ngẫu nhiên với các bản cập nhật riêng tư khác biệt), GlobalSIP'13
- 7: Giảm thiểu rủi ro thực nghiệm riêng biệt: Thuật toán hiệu quả và giới hạn lỗi chặt chẽ, FOCS'14
- 8: Abadi và cộng sự. Deep Learning with Differential Privacy, CCS '16
- 9: Smith và cộng sự. (Gần như) Thuật toán tối ưu để học tập riêng tư trên mạng trong các chế độ cài đặt đầy đủ thông tin và băng đảng, NeurIPS'13
- 10: Kairouz và cộng sự, Học sâu thực tế và riêng tư mà không cần lấy mẫu hoặc xáo trộn, ICML'21
- 11: Chien và cộng sự. Private Alternating Least Squares, ICML'21