
Este documento resume a abordagem de privacidade para a personalização no dispositivo (ODP, na sigla em inglês), especificamente no contexto da privacidade diferencial. Outras implicações de privacidade e decisões de design, como a minimização de dados, foram intencionalmente omitidas para manter o foco deste documento.
Privacidade diferencial
A privacidade diferencial 1 é um padrão amplamente adotado de proteção da privacidade na análise de dados estatísticos e no aprendizado de máquina 2 3. De maneira informal, ela diz que um adversário aprende quase a mesma coisa sobre um usuário com a saída de um algoritmo diferencialmente privado, aparecendo ou não no conjunto de dados subjacente. Isso implica proteções fortes para os indivíduos: as inferências feitas sobre uma pessoa só podem ser devido a propriedades agregadas do conjunto de dados que seriam válidas com ou sem o registro dessa pessoa.
No contexto do machine learning, a saída do algoritmo deve ser considerada como os parâmetros do modelo treinado. A frase quase a mesma coisa é quantificada matematicamente por dois parâmetros (ε, δ), em que ε geralmente é escolhido como uma constante pequena e δ≪1/(número de usuários).
Semântica de privacidade
O design da ODP busca garantir que cada execução de treinamento seja (ε,δ)-privada diferencial no nível do usuário. A seguir, descrevemos nossa abordagem para alcançar essa semântica.
Modelo de ameaça
Definimos as diferentes partes e declaramos as proposições sobre cada uma delas:
- Usuário:o usuário proprietário do dispositivo e consumidor dos produtos ou serviços fornecidos pelo desenvolvedor. As informações particulares estão totalmente disponíveis para eles.
- Ambiente de execução confiável (TEE): os dados e as computações confiáveis que ocorrem nos TEEs são protegidos contra invasores usando várias tecnologias. Portanto, a computação e os dados não exigem proteção extra. Os TEEs atuais podem permitir que os administradores do projeto acessem as informações. Propomos recursos personalizados para impedir e validar que o acesso não esteja disponível para um administrador.
- O invasor:pode ter informações secundárias sobre o usuário e acesso total a qualquer informação que saia do TEE (como os parâmetros do modelo publicado).
- Desenvolvedor:pessoa que define e treina o modelo. É considerado não confiável (e tem toda a capacidade de um invasor).
Projetamos a ODP com a seguinte semântica de privacidade diferencial:
- Limite de confiança:da perspectiva de um usuário, o limite de confiança consiste no dispositivo do usuário e no TEE. Todas as informações que saem desse limite de confiança precisam ser protegidas pela privacidade diferencial.
- Atacante:proteção total de privacidade diferencial em relação ao atacante. Qualquer entidade fora do limite de confiança pode ser um invasor, incluindo o desenvolvedor e outros usuários, todos potencialmente em conluio. O invasor, com todas as informações fora do limite de confiança (por exemplo, o modelo publicado), qualquer informação secundária sobre o usuário e recursos infinitos, não consegue inferir dados particulares adicionais sobre o usuário (além daqueles já nas informações secundárias), até as chances fornecidas pelo orçamento de privacidade. Em particular, isso implica uma proteção completa de privacidade diferencial em relação ao desenvolvedor. Todas as informações divulgadas ao desenvolvedor (como parâmetros de modelo treinado ou inferências agregadas) são protegidas pela privacidade diferencial.
Parâmetros do modelo local
A semântica de privacidade anterior acomoda o caso em que alguns dos parâmetros do modelo são locais do dispositivo (por exemplo, um modelo que contém uma incorporação de usuário específica para cada usuário e não compartilhada entre eles). Para esses modelos, os parâmetros locais permanecem dentro do limite de confiança (não são publicados) e não exigem proteção, enquanto os parâmetros do modelo compartilhado são publicados (e protegidos pela privacidade diferencial). Isso às vezes é chamado de modelo de privacidade de outdoor 4.
Recursos públicos
Em alguns aplicativos, alguns dos recursos são públicos. Por exemplo, em um problema de recomendação de filmes, os recursos de um filme (diretor, gênero ou ano de lançamento) são informações públicas e não exigem proteção, enquanto os recursos relacionados ao usuário (como informações demográficas ou quais filmes ele assistiu) são dados particulares e exigem proteção.
As informações públicas são formalizadas como uma matriz de recursos públicos (no exemplo anterior, essa matriz teria uma linha por filme e uma coluna por recurso de filme), que está disponível para todas as partes. O algoritmo de treinamento com privacidade diferencial pode usar essa matriz sem precisar protegê-la. Consulte, por exemplo, 5. A plataforma ODP planeja implementar esses algoritmos.
Uma abordagem de privacidade durante a previsão ou inferência
As inferências são baseadas nos parâmetros do modelo e nos recursos de entrada. Os parâmetros do modelo são treinados com semântica de privacidade diferencial. Aqui, discutimos a função dos atributos de entrada.
Em alguns casos de uso, quando o desenvolvedor já tem acesso total aos recursos usados na inferência, não há problema de privacidade com a inferência, e o resultado dela pode ficar visível para o desenvolvedor.
Em outros casos (quando os recursos usados na inferência são particulares e não acessíveis ao desenvolvedor), o resultado da inferência pode ser ocultado do desenvolvedor. Por exemplo, a inferência (e qualquer processo downstream que use o resultado da inferência) pode ser executada no dispositivo, em um processo e área de exibição pertencentes ao SO, com comunicação restrita fora desse processo.
Procedimento de treinamento
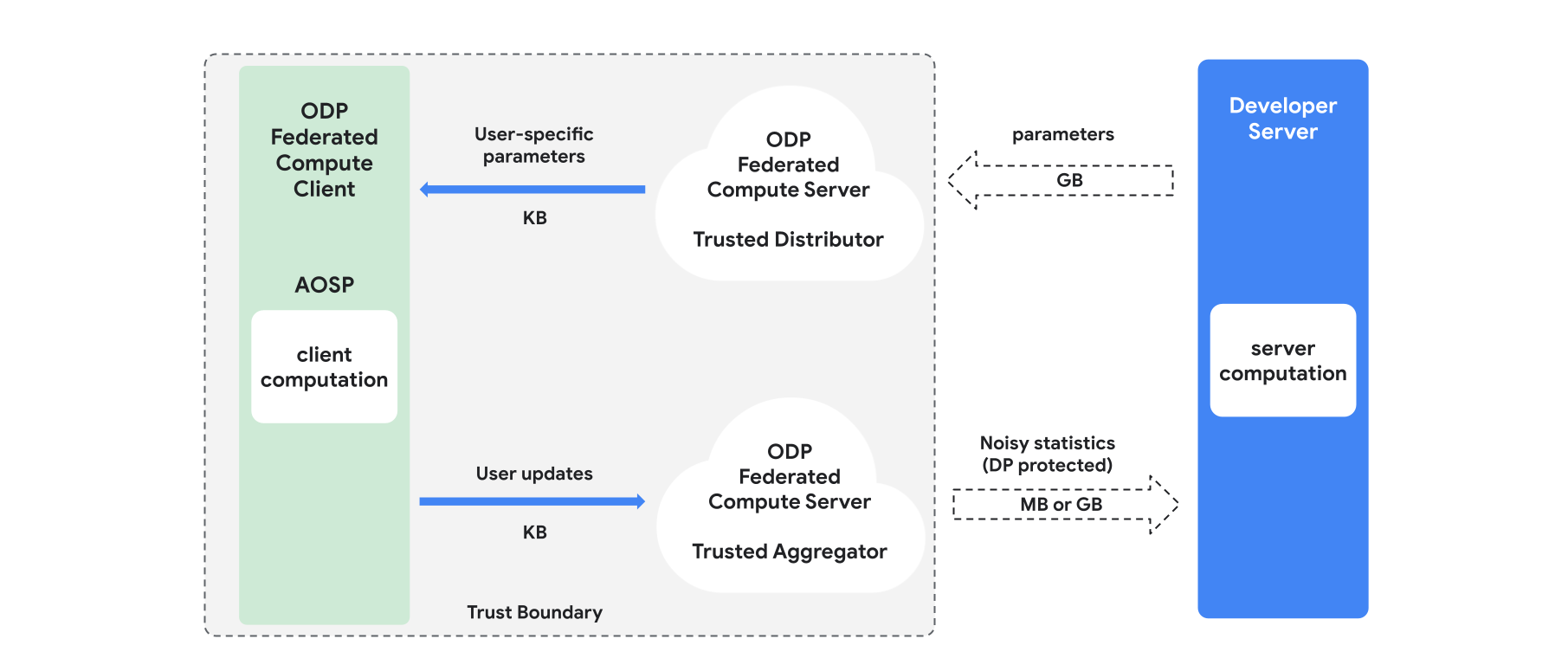
Visão geral
Esta seção apresenta uma visão geral da arquitetura e de como o treinamento é realizado. Consulte a Figura 1. O ODP implementa os seguintes componentes:
Um distribuidor confiável, como seleção federada, download confiável ou recuperação de informações particulares, que desempenha a função de transmitir parâmetros do modelo. Presume-se que o distribuidor confiável possa enviar um subconjunto de parâmetros a cada cliente sem revelar quais parâmetros foram baixados por qual cliente. Essa "transmissão parcial" permite que o sistema minimize a pegada no dispositivo do usuário final: em vez de enviar uma cópia completa do modelo, apenas uma fração dos parâmetros do modelo é enviada a um determinado usuário.
Um agregador confiável, que agrega informações de vários clientes (por exemplo, gradientes ou outras estatísticas), adiciona ruído e envia o resultado ao servidor. A premissa é que há canais confiáveis entre o cliente e o agregador, e entre o cliente e o distribuidor.
Algoritmos de treinamento de DP que são executados nessa infraestrutura. Cada algoritmo de treinamento consiste em diferentes cálculos executados nos diferentes componentes (servidor, cliente, agregador, distribuidor).
Uma rodada típica de treinamento consiste nas seguintes etapas:
- O servidor transmite parâmetros do modelo para o distribuidor confiável.
- Computação do cliente
- Cada dispositivo cliente recebe o modelo de transmissão (ou o subconjunto de parâmetros relevantes para o usuário).
- Cada cliente realiza alguma computação (por exemplo, gradientes ou outras estatísticas suficientes).
- Cada cliente envia o resultado da computação ao agregador confiável.
- O agregador confiável coleta, agrega e protege usando mecanismos adequados de privacidade diferencial as estatísticas dos clientes e envia o resultado ao servidor.
- Computação do servidor
- O servidor (não confiável) executa cálculos nas estatísticas protegidas por privacidade diferencial (por exemplo, usa gradientes agregados diferencialmente particulares para atualizar os parâmetros do modelo).
Modelos fatorados e minimização alternada com privacidade diferencial
A plataforma ODP planeja fornecer algoritmos de treinamento de privacidade diferencial de uso geral que podem ser aplicados a qualquer arquitetura de modelo, como DP-SGD 6 7 8 ou DP-FTRL 9 10, além de algoritmos especializados em modelos fatorados.
Modelos fatorizados são aqueles que podem ser decompostos em submodelos (chamados de codificadores ou torres). Por exemplo, considere um modelo da forma f(u(θu, xu), v(θv, xv)), em que u() codifica recursos do usuário xu (e tem parâmetros θu), e v() codifica recursos não relacionados ao usuário xv (e tem parâmetros θv). As duas codificações são combinadas usando f() para produzir a previsão final do modelo. Por exemplo, em um modelo de recomendação de filmes, xu são os atributos do usuário e xv são os atributos do filme.
Esses modelos são adequados para a arquitetura de sistema distribuído mencionada acima, já que separam os recursos do usuário e não usuário.
Os modelos fatorados serão treinados usando a minimização alternada diferencialmente particular (DPAM, na sigla em inglês), que alterna entre a otimização dos parâmetros θu (enquanto θv é fixo) e vice-versa. Os algoritmos de DPAM demonstraram alcançar melhor utilidade em várias configurações 4 11, principalmente na presença de recursos públicos.
Referências
- 1: Dwork et al. Calibrating Noise to Sensitivity in Private Data Analysis, TCC'06
- 2: US Census Bureau. Understanding Differential Privacy, 2020
- 3: Aprendizado federado com garantias formais de privacidade diferencial, postagem do blog de IA do Google, 2020
- 4: Jain et al. Differentially Private Model Personalization, NeurIPS'21
- 5: Krichene et al. Private Learning with Public Features, 2023
- 6: Song et al. Stochastic gradient descent with differentially private updates, GlobalSIP'13
- 7: Differentially Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds, FOCS'14
- 8: Abadi et al. Deep Learning with Differential Privacy, CCS '16
- 9: Smith et al. (Nearly) Optimal Algorithms for Private Online Learning in Full-information and Bandit Settings, NeurIPS'13
- 10: Kairouz et al., Aprendizado profundo prático e privado sem amostragem ou embaralhamento, ICML'21
- 11: Chien et al. Private Alternating Least Squares, ICML'21