
Ten dokument zawiera podsumowanie podejścia do ochrony prywatności w przypadku personalizacji na urządzeniu (ODP), w szczególności w kontekście prywatności różnicowej. Inne kwestie związane z prywatnością i decyzje projektowe, takie jak minimalizacja danych, zostały celowo pominięte, aby zachować spójność tego dokumentu.
Prywatność różnicowa
Prywatność różnicowa1 to powszechnie stosowany standard ochrony prywatności w analizie danych statystycznych i uczeniu maszynowym2 3. Nieformalnie oznacza to, że przeciwnik dowiaduje się o użytkowniku prawie tego samego z wyników algorytmu spełniającego wymogi prywatności różnicowej, niezależnie od tego, czy jego rekord znajduje się w bazowym zbiorze danych. Oznacza to silną ochronę osób fizycznych: wszelkie wnioski wyciągane na temat danej osoby mogą wynikać tylko z właściwości zbiorczych zbioru danych, które byłyby prawdziwe z zapisem danych tej osoby lub bez niego.
W kontekście uczenia maszynowego dane wyjściowe algorytmu należy traktować jako wytrenowane parametry modelu. Wyrażenie prawie to samo jest matematycznie kwantyfikowane przez 2 parametry (ε, δ), gdzie ε jest zwykle małą stałą, a δ≪1/(liczba użytkowników).
Semantyka prywatności
Celem ODP jest zapewnienie, że każdy przebieg trenowania jest (ε,δ)-różnicowo prywatny na poziomie użytkownika. Poniżej przedstawiamy nasze podejście do osiągnięcia tego celu.
Model zagrożeń
Określamy różne strony i podajemy założenia dotyczące każdej z nich:
- Użytkownik: użytkownik, który jest właścicielem urządzenia i korzysta z produktów lub usług dostarczanych przez dewelopera. Ich prywatne informacje są w pełni dostępne dla nich samych.
- Zaufane środowisko wykonawcze (TEE): dane i zaufane obliczenia, które odbywają się w TEE, są chronione przed atakami za pomocą różnych technologii. Dlatego obliczenia i dane nie wymagają dodatkowej ochrony. Obecne środowiska TEE mogą umożliwiać administratorom projektu dostęp do informacji w nich zawartych. Proponujemy niestandardowe funkcje, które uniemożliwiają administratorowi dostęp i sprawdzają, czy jest on niedostępny.
- Osoba atakująca: może mieć dodatkowe informacje o użytkowniku i pełny dostęp do wszystkich informacji opuszczających TEE (np. opublikowanych parametrów modelu).
- Deweloper: osoba, która definiuje i trenuje model. jest uznawany za niezaufany (i ma pełne możliwości atakującego);
Chcemy, aby ODP miało następującą semantykę prywatności różnicowej:
- Granica zaufania: z perspektywy użytkownika granica zaufania obejmuje jego urządzenie oraz środowisko TEE. Wszelkie informacje, które opuszczają tę granicę zaufania, powinny być chronione przez prywatność różnicową.
- Osoba atakująca: pełna ochrona prywatności różnicowej w odniesieniu do osoby atakującej. Każdy podmiot spoza granicy zaufania może być atakującym (dotyczy to dewelopera i innych użytkowników, którzy mogą działać w porozumieniu). Atakujący, który ma dostęp do wszystkich informacji spoza granicy zaufania (np. opublikowanego modelu), wszelkich informacji dodatkowych o użytkowniku i nieograniczonych zasobów, nie jest w stanie wywnioskować dodatkowych prywatnych danych o użytkowniku (poza tymi, które już znajdują się w informacjach dodatkowych) z prawdopodobieństwem określonym przez budżet prywatności. Oznacza to w szczególności pełną ochronę prywatności różnicowej w odniesieniu do dewelopera. Wszelkie informacje udostępniane deweloperowi (np. parametry wytrenowanego modelu lub zbiorcze wnioski) są chronione za pomocą prywatności różnicowej.
Parametry modelu lokalnego
Poprzednia semantyka prywatności uwzględniała przypadek, w którym niektóre parametry modelu są lokalne na urządzeniu (np. model zawierający osadzanie użytkownika specyficzne dla każdego użytkownika i nieudostępniane innym użytkownikom). W przypadku takich modeli te lokalne parametry pozostają w granicach zaufania (nie są publikowane) i nie wymagają ochrony, natomiast udostępnione parametry modelu są publikowane (i są chronione przez prywatność różnicową). Czasami nazywa się to modelem prywatności billboardu4.
Funkcje publiczne
W niektórych aplikacjach niektóre funkcje są publiczne. Na przykład w przypadku rekomendacji filmów cechy filmu (reżyser, gatunek czy rok premiery) są informacjami publicznymi i nie wymagają ochrony, natomiast cechy związane z użytkownikiem (np. dane demograficzne czy obejrzane przez niego filmy) są danymi prywatnymi i wymagają ochrony.
Informacje publiczne są sformalizowane w postaci publicznej macierzy cech (w poprzednim przykładzie macierz ta zawierałaby jeden wiersz na film i jedną kolumnę na cechę filmu), która jest dostępna dla wszystkich stron. Algorytm trenowania z prywatnością różnicową może korzystać z tej macierzy bez konieczności jej ochrony (np. 5). Platforma ODP planuje wdrożyć takie algorytmy.
Podejście do ochrony prywatności podczas prognozowania lub wnioskowania
Wnioski są wyciągane na podstawie parametrów modelu i funkcji wejściowych. Parametry modelu są trenowane z użyciem semantyki prywatności różnicowej. W tej sekcji omówimy rolę cech wejściowych.
W niektórych przypadkach, gdy deweloper ma już pełny dostęp do funkcji używanych w procesie wnioskowania, nie ma obaw o prywatność, a wynik wnioskowania może być widoczny dla dewelopera.
W innych przypadkach (gdy funkcje używane w procesie wnioskowania są prywatne i niedostępne dla dewelopera) wynik wnioskowania może być ukryty przed deweloperem, np. przez uruchomienie wnioskowania (i wszelkich procesów podrzędnych, które używają wyniku wnioskowania) na urządzeniu, w procesie i obszarze wyświetlania należącym do systemu operacyjnego, z ograniczoną komunikacją poza tym procesem.
Procedura trenowania
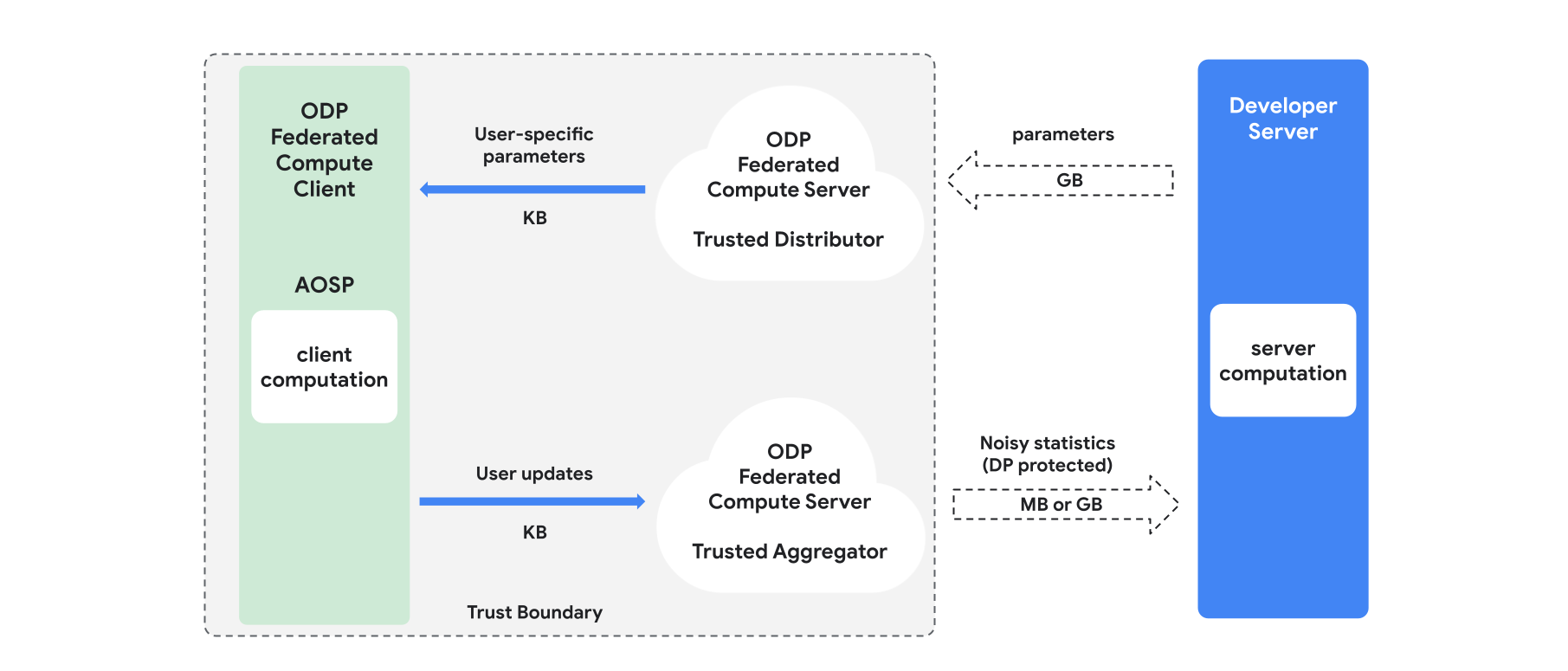
Przegląd
W tej sekcji znajdziesz omówienie architektury i przebiegu trenowania (patrz rysunek 1). Platforma ODP zawiera te komponenty:
Zaufany dystrybutor, np. federacyjne wybieranie, zaufane pobieranie lub prywatne pobieranie informacji, który odgrywa rolę w rozpowszechnianiu parametrów modelu. Zakłada się, że zaufany dystrybutor może wysyłać do każdego klienta podzbiór parametrów, nie ujawniając, które parametry zostały pobrane przez którego klienta. Takie „częściowe przesyłanie” pozwala systemowi zminimalizować obciążenie urządzenia użytkownika: zamiast wysyłać pełną kopię modelu, do każdego użytkownika przesyłana jest tylko część parametrów modelu.
Zaufany agregator, który agreguje informacje od wielu klientów (np. gradienty lub inne statystyki), dodaje szum i wysyła wynik na serwer. Zakłada się, że między klientem a agregatorem oraz między klientem a dystrybutorem istnieją zaufane kanały.
algorytmy trenowania DP, które działają w tej infrastrukturze; Każdy algorytm trenowania składa się z różnych obliczeń wykonywanych na różnych komponentach (serwerze, kliencie, agregatorze, dystrybutorze).
Typowa runda trenowania obejmuje te etapy:
- Serwer rozsyła parametry modelu do zaufanego dystrybutora.
- Obliczenia po stronie klienta
- Każde urządzenie klienckie otrzymuje model transmisji (lub podzbiór parametrów istotnych dla użytkownika).
- Każdy klient wykonuje pewne obliczenia (np. oblicza gradienty lub inne statystyki wystarczające).
- Każdy klient wysyła wynik obliczeń do zaufanego agregatora.
- Zaufany agregator zbiera i agreguje statystyki od klientów oraz chroni je za pomocą odpowiednich mechanizmów prywatności różnicowej, a następnie przesyła wynik na serwer.
- Obliczenia na serwerze
- Serwer (niezaufany) przeprowadza obliczenia na statystykach chronionych za pomocą prywatności różnicowej (np. używa zagregowanych gradientów chronionych za pomocą prywatności różnicowej do aktualizowania parametrów modelu).
Modele faktoryzowane i prywatność różnicowa w minimalizacji naprzemiennej
Platforma ODP planuje udostępniać ogólne algorytmy trenowania z różnicową prywatnością, które można stosować w przypadku dowolnej architektury modelu (np. DP-SGD 6 7 8 lub DP-FTRL 9 10, a także algorytmy wyspecjalizowane w modelach sfaktoryzowanych).
Modele sfaktoryzowane to modele, które można rozłożyć na podmodele (zwane enkoderami lub wieżami). Rozważmy na przykład model w formie f(u(θu, xu), v(θv, xv)), gdzie u() koduje cechy użytkownika xu (i ma parametry θu), a v() koduje cechy niebędące cechami użytkownika xv (i ma parametry θv). Oba kodowania są łączone za pomocą funkcji f(), aby uzyskać ostateczną prognozę modelu. Na przykład w modelu rekomendacji filmów xu to cechy użytkownika, a xv to cechy filmu.
Takie modele dobrze pasują do wspomnianej architektury systemu rozproszonego (ponieważ rozdzielają funkcje użytkownika i funkcje niezwiązane z użytkownikiem).
Modele faktoryzowane będą trenowane przy użyciu algorytmu DPAM, który naprzemiennie optymalizuje parametry θu (przy stałej wartości θv) i odwrotnie. Algorytmy DPAM osiągają lepsze wyniki w różnych ustawieniach4 11, zwłaszcza w przypadku funkcji publicznych.
Odniesienia
- 1. Dwork i in. Calibrating Noise to Sensitivity in Private Data Analysis, TCC'06
- 2: US Census Bureau. Understanding Differential Privacy, 2020
- 3: Federated Learning with Formal Differential Privacy Guarantees, Google AI Blog Post, 2020
- 4. Jain i in. Differentially Private Model Personalization, NeurIPS'21
- 5. Krichene i in. Private Learning with Public Features, 2023
- 6. Song i in. Stochastic gradient descent with differentially private updates, GlobalSIP'13
- 7. Differentially Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds, FOCS'14
- 8. Abadi i in. Deep Learning with Differential Privacy, CCS '16
- 9. Smith i in. (Nearly) Optimal Algorithms for Private Online Learning in Full-information and Bandit Settings, NeurIPS'13
- 10: Kairouz i in., Practical and Private (Deep) Learning without Sampling or Shuffling, ICML'21
- 11. Chien i in. Private Alternating Least Squares, ICML'21