
이 문서에서는 특히 차등 개인 정보 보호와 관련하여 온디바이스 맞춤설정 (ODP)의 개인 정보 보호 접근 방식을 요약합니다. 이 문서의 초점을 유지하기 위해 데이터 최소화와 같은 기타 개인 정보 보호 영향 및 설계 결정은 의도적으로 제외되었습니다.
개인 정보 차등 보호
차등 개인 정보 보호 1는 통계 데이터 분석 및 머신러닝 2 3에서 널리 채택되는 개인 정보 보호 표준입니다. 비공식적으로는 개인 정보 차등 보호 알고리즘의 출력에서 공격자가 기본 데이터 세트에 레코드가 표시되는지 여부에 관계없이 사용자에 관해 거의 동일한 정보를 학습한다고 말합니다. 이는 개인에 대한 추론이 해당 개인의 레코드가 있든 없든 유지되는 데이터 세트의 집계 속성으로만 이루어질 수 있음을 의미하므로 개인에 대한 강력한 보호를 의미합니다.
머신러닝의 맥락에서 알고리즘의 출력은 학습된 모델 매개변수로 생각해야 합니다. 거의 동일한 것이라는 문구는 두 매개변수 (ε, δ)로 수학적으로 정량화되며, 여기서 ε은 일반적으로 작은 상수로 선택되고 δ≪1/(사용자 수)입니다.
개인 정보 보호 시맨틱스
ODP 설계는 각 학습 실행이 (ε,δ)-사용자 수준 차등 프라이버시를 갖도록 하는 데 중점을 둡니다. 다음은 이 시맨틱에 도달하기 위한 접근 방식을 간략하게 설명합니다.
위협 모델
다양한 당사자를 정의하고 각 당사자에 관한 가정을 명시합니다.
- 사용자: 기기를 소유하고 개발자가 제공하는 제품 또는 서비스를 소비하는 사용자입니다. 개인 정보는 본인에게 완전히 공개됩니다.
- 신뢰할 수 있는 실행 환경 (TEE): TEE 내에서 발생하는 데이터와 신뢰할 수 있는 컴퓨팅은 다양한 기술을 사용하여 공격자로부터 보호됩니다. 따라서 계산과 데이터에 추가 보호가 필요하지 않습니다. 기존 TEE는 프로젝트 관리자가 내부 정보에 액세스하도록 허용할 수 있습니다. 관리자가 액세스할 수 없음을 허용하고 검증하는 맞춤 기능을 제안합니다.
- 공격자: 사용자에 관한 부가 정보를 보유할 수 있으며 TEE를 벗어나는 모든 정보 (예: 게시된 모델 매개변수)에 대한 전체 액세스 권한이 있습니다.
- 개발자: 모델을 정의하고 학습시키는 사람입니다. 신뢰할 수 없는 것으로 간주됩니다 (공격자의 모든 기능을 갖습니다).
Google은 다음과 같은 개인 정보 차등 보호 의미론을 사용하여 ODP를 설계하고자 합니다.
- 신뢰 경계: 한 사용자의 관점에서 신뢰 경계는 사용자의 자체 기기와 TEE로 구성됩니다. 이 신뢰 경계를 벗어나는 모든 정보는 개인 정보 차등 보호로 보호되어야 합니다.
- 공격자: 공격자에 대한 완전한 개인 정보 차등 보호 신뢰 경계 외부의 모든 항목은 공격자가 될 수 있습니다 (개발자와 다른 사용자를 포함하며 모두 공모할 수 있음). 공격자는 신뢰 경계 외부의 모든 정보 (예: 게시된 모델), 사용자에 관한 모든 부가 정보, 무한한 리소스를 보유하더라도 개인 정보 보호 예산에서 제공하는 확률까지 사용자에 관한 추가 비공개 데이터 (이미 부가 정보에 있는 데이터 제외)를 추론할 수 없습니다. 특히 이는 개발자와 관련하여 완전한 개인 정보 차등 보호를 의미합니다. 개발자에게 공개되는 모든 정보 (예: 학습된 모델 파라미터 또는 집계된 추론)는 개인 정보 차등 보호가 적용됩니다.
로컬 모델 매개변수
이전 개인 정보 보호 시맨틱은 모델 매개변수 중 일부가 기기에 로컬인 경우 (예: 각 사용자에게 고유하고 사용자 간에 공유되지 않는 사용자 삽입을 포함하는 모델)를 수용합니다. 이러한 모델의 경우 이러한 로컬 매개변수는 신뢰 경계 내에 유지되며 (게시되지 않음) 보호가 필요하지 않지만 공유 모델 매개변수는 게시됩니다 (차등 개인 정보 보호로 보호됨). 이를 전광판 개인 정보 보호 모델4이라고도 합니다.
공개 기능
일부 애플리케이션에서는 일부 기능이 공개됩니다. 예를 들어 영화 추천 문제에서 영화의 특징 (영화의 감독, 장르, 출시 연도)은 공개 정보이므로 보호가 필요하지 않지만 사용자와 관련된 특징 (예: 인구통계 정보 또는 사용자가 시청한 영화)은 비공개 데이터이므로 보호가 필요합니다.
공개 정보는 모든 당사자가 사용할 수 있는 공개 기능 매트릭스 (이전 예에서 이 매트릭스에는 영화당 하나의 행과 영화 기능당 하나의 열이 포함됨)로 공식화됩니다. 개인 정보 차등 보호 학습 알고리즘은 이 행렬을 보호할 필요 없이 사용할 수 있습니다(예: 5 참고). ODP 플랫폼은 이러한 알고리즘을 구현할 계획입니다.
예측 또는 추론 중 개인 정보 보호에 대한 접근 방식
추론은 모델 매개변수와 입력 기능을 기반으로 합니다. 모델 매개변수는 개인 정보 차등 보호 시맨틱으로 학습됩니다. 여기에서는 입력 기능의 역할에 대해 설명합니다.
일부 사용 사례에서는 개발자가 추론에 사용된 기능에 이미 모든 권한을 보유하고 있으므로 추론으로 인한 개인 정보 보호 문제가 없으며 추론 결과를 개발자가 볼 수 있습니다.
추론에 사용되는 기능이 비공개이고 개발자가 액세스할 수 없는 다른 경우 추론 결과가 개발자에게 숨겨질 수 있습니다. 예를 들어 추론(및 추론 결과를 사용하는 다운스트림 프로세스)이 OS 소유 프로세스 및 표시 영역에서 기기 내에서 실행되고 해당 프로세스 외부의 통신이 제한됩니다.
학습 절차
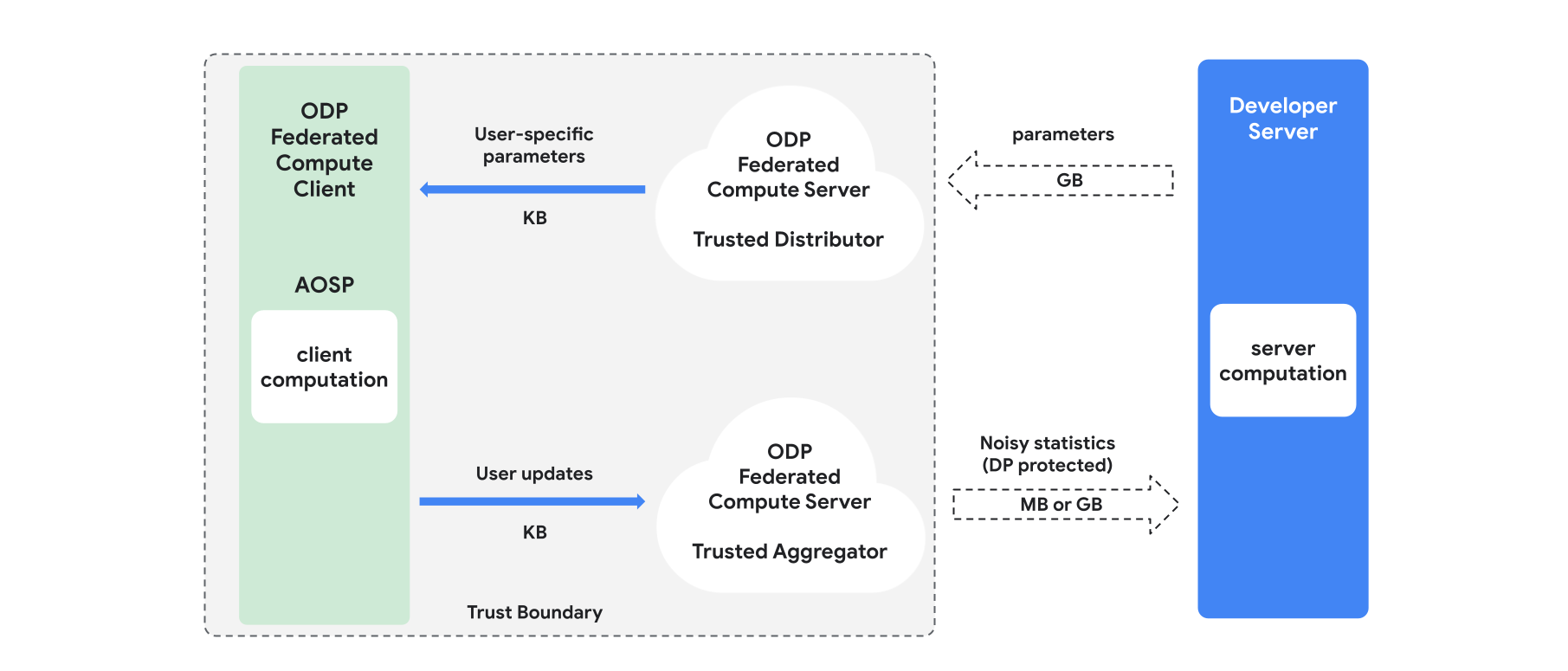
개요
이 섹션에서는 아키텍처와 학습 진행 방식을 간략하게 설명합니다(그림 1 참고). ODP는 다음 구성요소를 구현합니다.
모델 매개변수를 브로드캐스트하는 역할을 하는 제휴 선택, 신뢰할 수 있는 다운로드 또는 비공개 정보 검색과 같은 신뢰할 수 있는 유통업체 신뢰할 수 있는 유통업체는 어떤 클라이언트가 어떤 매개변수를 다운로드했는지 공개하지 않고 각 클라이언트에 매개변수의 하위 집합을 전송할 수 있다고 가정합니다. 이 '부분 브로드캐스트'를 통해 시스템은 최종 사용자 기기에서 차지하는 공간을 최소화할 수 있습니다. 모델의 전체 사본을 전송하는 대신 모델 매개변수의 일부만 특정 사용자에게 전송됩니다.
신뢰할 수 있는 애그리게이터는 여러 클라이언트의 정보 (예: 그라데이션 또는 기타 통계)를 집계하고 노이즈를 추가하며 결과를 서버로 전송합니다. 클라이언트와 애그리게이터 간, 클라이언트와 유통업체 간에 신뢰할 수 있는 채널이 있다고 가정합니다.
이 인프라에서 실행되는 DP 학습 알고리즘 각 학습 알고리즘은 서로 다른 구성요소 (서버, 클라이언트, 집계기, 분배기)에서 실행되는 서로 다른 계산으로 구성됩니다.
일반적인 학습 라운드는 다음 단계로 구성됩니다.
- 서버는 신뢰할 수 있는 유통업체에 모델 매개변수를 브로드캐스트합니다.
- 클라이언트 계산
- 각 클라이언트 기기는 브로드캐스트 모델 (또는 사용자와 관련된 매개변수의 하위 집합)을 수신합니다.
- 각 클라이언트는 일부 계산 (예: 경사 또는 기타 충분한 통계 계산)을 실행합니다.
- 각 클라이언트는 계산 결과를 신뢰할 수 있는 집계기에 전송합니다.
- 신뢰할 수 있는 집계기는 적절한 개인 정보 차등 보호 메커니즘을 사용하여 클라이언트의 통계를 수집, 집계, 보호한 다음 결과를 서버로 전송합니다.
- 서버 컴퓨팅
- (신뢰할 수 없는) 서버는 개인 정보 차등 보호 통계에 대한 계산을 실행합니다 (예: 개인 정보 차등 보호 집계된 그라데이션을 사용하여 모델 매개변수를 업데이트함).
팩터화된 모델 및 개인 정보 차등 보호 교대 최소화
ODP 플랫폼은 DP-SGD 6 7 8 또는 DP-FTRL 9 10과 같은 모든 모델 아키텍처에 적용할 수 있는 범용 개인 정보 차등 보호 학습 알고리즘과 factorized 모델에 특화된 알고리즘을 제공할 계획입니다.
팩터화된 모델은 하위 모델 (인코더 또는 타워라고 함)로 분해할 수 있는 모델입니다. 예를 들어 f(u(θu, xu), v(θv, xv)) 형태의 모델을 생각해 보세요. 여기서 u()는 사용자 기능 xu를 인코딩하고 (매개변수 θu 있음) v()는 비사용자 기능 xv를 인코딩합니다 (매개변수 θv 있음). 두 인코딩은 f()를 사용하여 결합되어 최종 모델 예측을 생성합니다. 예를 들어 영화 추천 모델에서 xu는 사용자 특성이고 xv는 영화 특성입니다.
이러한 모델은 사용자 및 비사용자 기능을 분리하므로 앞서 언급한 분산 시스템 아키텍처에 적합합니다.
팩터화된 모델은 개인 정보 차등 보호 교대 최소화(DPAM)를 사용하여 학습됩니다. DPAM은 θv이 고정된 상태에서 θu를 최적화하는 것과 그 반대를 번갈아 수행합니다. DPAM 알고리즘은 다양한 설정, 특히 공개 기능이 있는 경우 더 나은 유틸리티를 달성하는 것으로 나타났습니다. 4 11
참조
- 1: Dwork et al. Calibrating Noise to Sensitivity in Private Data Analysis, TCC'06
- 2: 미국 인구조사국. Understanding Differential Privacy, 2020
- 3: Federated Learning with Formal Differential Privacy Guarantees(공식 차등 프라이버시 보장을 통한 연합 학습), Google AI 블로그 게시물, 2020년
- 4: Jain et al. Differentially Private Model Personalization, NeurIPS'21
- 5: Krichene 외. Private Learning with Public Features, 2023
- 6: Song et al. Stochastic gradient descent with differentially private updates, GlobalSIP'13
- 7: Differentially Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds, FOCS'14
- 8: Abadi et al. Deep Learning with Differential Privacy, CCS '16
- 9: Smith 외, Nearly Optimal Algorithms for Private Online Learning in Full-information and Bandit Settings, NeurIPS'13
- 10: Kairouz et al., Practical and Private (Deep) Learning without Sampling or Shuffling, ICML'21
- 11: Chien 외. Private Alternating Least Squares, ICML'21