
このドキュメントでは、差分プライバシーのコンテキストにおけるオンデバイス パーソナライズ(ODP)のプライバシー アプローチについて説明します。このドキュメントの焦点を絞るため、データの最小化などのプライバシーに関するその他の影響と設計上の決定は意図的に除外しています。
差分プライバシー
差分プライバシー 1 は、統計データ分析と機械学習 2 3 において広く採用されているプライバシー保護の標準です。非公式には、差分プライバシー アルゴリズムの出力から、基盤となるデータセットにユーザーのレコードが含まれているかどうかにかかわらず、敵対者がユーザーについてほぼ同じことを学習すると言えます。これは、個人に対する強力な保護を意味します。個人に関する推論は、その個人のレコードの有無にかかわらず保持されるデータセットの集計プロパティのみに基づくことができます。
ML のコンテキストでは、アルゴリズムの出力はトレーニング済みモデル パラメータと考える必要があります。「ほぼ同じ」というフレーズは、2 つのパラメータ(ε、δ)によって数学的に定量化されます。通常、ε は小さな定数として選択され、δ≪1 /(ユーザー数)となります。
プライバシー セマンティクス
ODP の設計では、各トレーニング実行が(ε,δ)ユーザーレベルの差分プライベートになるようにします。以下に、このセマンティクスを実現するためのアプローチの概要を示します。
脅威モデル
さまざまな当事者を定義し、それぞれの当事者に関する仮定を述べます。
- ユーザー: デバイスを所有し、デベロッパーが提供するプロダクトやサービスの消費者であるユーザー。個人情報はユーザー自身が完全に利用できます。
- 高信頼実行環境(TEE): TEE 内で発生するデータと信頼できる計算は、さまざまなテクノロジーを使用して攻撃者から保護されます。したがって、計算とデータに追加の保護は必要ありません。既存の TEE では、プロジェクト管理者が内部の情報にアクセスできる場合があります。管理者がアクセスできないことを禁止して検証するカスタム機能を提案します。
- 攻撃者: ユーザーに関するサイド情報を持ち、TEE から送信される情報(公開されたモデル パラメータなど)に完全にアクセスできる可能性があります。
- デベロッパー: モデルを定義してトレーニングするユーザー。信頼できないと見なされる(攻撃者の能力を最大限に発揮できる)。
Google は、差分プライバシーの次のセマンティクスを使用して ODP を設計しようとしています。
- 信頼境界: 1 人のユーザーの視点から見ると、信頼境界はユーザー自身のデバイスと TEE で構成されます。この信頼境界外に出る情報は、差分プライバシーによって保護する必要があります。
- 攻撃者: 攻撃者に対する完全な差分プライバシー保護。信頼境界外のエンティティはすべて攻撃者になる可能性があります(デベロッパーや他のユーザーも含まれ、すべてが共謀する可能性があります)。攻撃者は、信頼境界外のすべての情報(公開されたモデルなど)、ユーザーに関するあらゆるサイド情報、無限のリソースを与えられたとしても、プライバシー予算で指定されたオッズを超えて、ユーザーに関する追加のプライベート データ(サイド情報にすでに含まれているものを除く)を推測することはできません。特に、これはデベロッパーに対する完全な差分プライバシー保護を意味します。デベロッパーにリリースされる情報(トレーニング済みモデルのパラメータや集計された推論など)は、差分プライバシーによって保護されます。
ローカルモデル パラメータ
以前のプライバシー セマンティクスは、モデル パラメータの一部がデバイスにローカルである場合(たとえば、各ユーザーに固有のユーザー エンベディングを含み、ユーザー間で共有されないモデル)に対応しています。このようなモデルでは、ローカル パラメータは信頼境界内に留まり(公開されず)、保護を必要としませんが、共有モデル パラメータは公開されます(差分プライバシーによって保護されます)。これは、ビルボード プライバシー モデル4 と呼ばれることもあります。
一般公開版の機能
一部のアプリケーションでは、一部の機能が公開されています。たとえば、映画のレコメンデーションの問題では、映画の特徴(映画の監督、ジャンル、公開年)は公開情報であり、保護は必要ありません。一方、ユーザーに関連する特徴(ユーザーの属性情報やユーザーが視聴した映画など)は非公開データであり、保護が必要です。
公開情報は、すべての関係者が利用できる公開機能マトリックスとして形式化されます(前の例では、このマトリックスには映画ごとに 1 行、映画の機能ごとに 1 列が含まれます)。差分プライベート トレーニング アルゴリズムは、この行列を保護する必要なく使用できます。たとえば、5 をご覧ください。ODP プラットフォームは、このようなアルゴリズムの実装を計画しています。
予測または推論時のプライバシー保護のアプローチ
推論は、モデル パラメータと入力特徴に基づいています。モデル パラメータは差分プライバシー セマンティクスでトレーニングされます。ここでは、入力特徴の役割について説明します。
推論で使用される機能にデベロッパーがすでにフルアクセス権を持っている場合、推論によるプライバシー上の懸念はなく、推論結果がデベロッパーに表示されることがあります。
その他のケース(推論で使用される機能がプライベートで、デベロッパーがアクセスできない場合)では、推論結果がデベロッパーに表示されないことがあります。たとえば、推論(および推論結果を使用するダウンストリーム プロセス)をデバイス上の OS 所有のプロセスと表示領域で実行し、そのプロセス外の通信を制限することで、推論結果がデベロッパーに表示されないようにします。
トレーニング手順
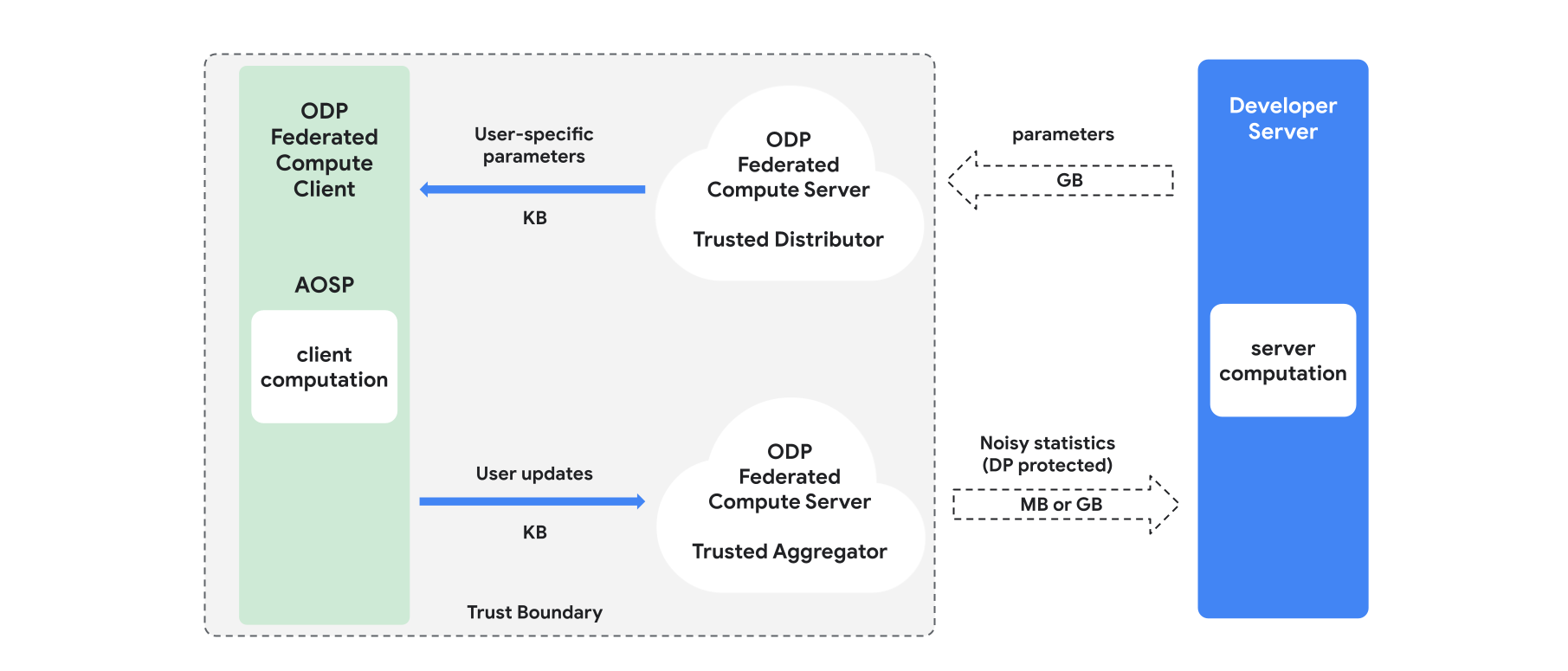
概要
このセクションでは、アーキテクチャの概要とトレーニングの進め方について説明します(図 1 を参照)。ODP は次のコンポーネントを実装します。
フェデレーション選択、信頼できるダウンロード、プライベート情報取得などの信頼できる配信者。モデル パラメータのブロードキャストの役割を果たします。信頼できる販売業者は、どのクライアントがどのパラメータをダウンロードしたかを明らかにすることなく、パラメータのサブセットを各クライアントに送信できると想定されています。この「部分ブロードキャスト」により、システムはエンドユーザーのデバイス上のフットプリントを最小限に抑えることができます。モデルの完全なコピーを送信する代わりに、モデル パラメータの一部のみが特定のユーザーに送信されます。
信頼できるアグリゲータ。複数のクライアントからの情報(グラデーションやその他の統計情報など)を集約し、ノイズを追加して、結果をサーバーに送信します。クライアントとアグリゲータの間、およびクライアントとディストリビュータの間には信頼できるチャネルがあることを前提としています。
このインフラストラクチャで実行される DP トレーニング アルゴリズム。各トレーニング アルゴリズムは、異なるコンポーネント(サーバー、クライアント、アグリゲータ、ディストリビュータ)で実行されるさまざまな計算で構成されています。
一般的なトレーニング ラウンドは、次の手順で構成されます。
- サーバーは、モデル パラメータを信頼できる販売者にブロードキャストします。
- クライアント コンピューティング
- 各クライアント デバイスは、ブロードキャスト モデル(またはユーザーに関連するパラメータのサブセット)を受け取ります。
- 各クライアントは、なんらかの計算(勾配やその他の十分な統計情報の計算など)を実行します。
- 各クライアントは、計算結果を信頼できるアグリゲータに送信します。
- 信頼できるアグリゲータは、適切な差分プライバシー メカニズムを使用してクライアントから統計情報を収集、集計、保護し、結果をサーバーに送信します。
- サーバー コンピューティング
- (信頼できない)サーバーは、差分プライバシーで保護された統計情報に対して計算を実行します(たとえば、差分プライバシーで保護された集約勾配を使用してモデル パラメータを更新します)。
因数分解モデルと差分プライベート交互最小化
ODP プラットフォームは、任意のモデル アーキテクチャ(DP-SGD 6 7 8 や DP-FTRL 9 10 など)に適用できる汎用の差分プライベート トレーニング アルゴリズムと、因数分解モデルに特化したアルゴリズムを提供する予定です。
ファクタライズド モデルは、サブモデル(エンコーダまたはタワーと呼ばれる)に分解できるモデルです。たとえば、f(u(θu, xu), v(θv, xv)) という形式のモデルを考えてみましょう。ここで、u() はユーザーの特徴 xu をエンコードし(パラメータ θu を持ちます)、v() はユーザー以外の特徴 xv をエンコードします(パラメータ θv を持ちます)。2 つのエンコードは f() を使用して結合され、最終的なモデル予測が生成されます。たとえば、映画のレコメンデーション モデルでは、xu はユーザーの特徴、xv は映画の特徴です。
このようなモデルは、前述の分散システム アーキテクチャに適しています(ユーザーと非ユーザーの機能を分離するため)。
因数分解モデルは、差分プライベート交互最小化(DPAM)を使用してトレーニングされます。DPAM は、パラメータ θu の最適化(θv は固定)と、その逆の最適化を交互に行います。DPAM アルゴリズムは、さまざまな設定でより優れたユーティリティを実現することが示されています4 11。特に、公開機能が存在する場合にその傾向が顕著です。
参照
- 1: Dwork 他、Calibrating Noise to Sensitivity in Private Data Analysis、TCC'06
- 2: 米国国勢調査局。Understanding Differential Privacy, 2020
- 3: Federated Learning with Formal Differential Privacy Guarantees, Google AI Blog Post, 2020
- 4: Jain 他、Differentially Private Model Personalization、NeurIPS'21
- 5: Krichene 他、Private Learning with Public Features、2023 年
- 6: Song 他、差分プライベート アップデートによる確率的勾配降下法、GlobalSIP'13
- 7: Differentially Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds, FOCS'14
- 8: Abadi 他、Deep Learning with Differential Privacy、CCS '16
- 9: Smith 他、Full-information 設定と Bandit 設定におけるプライベート オンライン学習のための(ほぼ)最適なアルゴリズム、NeurIPS'13
- 10: Kairouz ほか、Practical and Private (Deep) Learning without Sampling or Shuffling, ICML'21
- 11: Chien 他、Private Alternating Least Squares、ICML'21