
Questo documento riassume l'approccio alla privacy per la personalizzazione on-device (ODP) nello specifico nel contesto della privacy differenziale. Altre implicazioni per la privacy e decisioni di progettazione, come la riduzione al minimo dei dati, sono intenzionalmente escluse per mantenere questo documento focalizzato.
Privacy differenziale
La privacy differenziale 1 è uno standard di protezione della privacy ampiamente adottato nell'analisi statistica dei dati e nel machine learning 2 3. In termini informali, afferma che un avversario apprende quasi la stessa cosa su un utente dall'output di un algoritmo con privacy differenziale, indipendentemente dal fatto che il suo record venga visualizzato o meno nel set di dati sottostante. Ciò implica una forte protezione per le persone: qualsiasi inferenza fatta su una persona può essere dovuta solo a proprietà aggregate del set di dati che sarebbero valide con o senza il record di quella persona.
Nel contesto del machine learning, l'output dell'algoritmo deve essere considerato come i parametri del modello addestrato. L'espressione quasi la stessa cosa viene quantificata matematicamente da due parametri (ε, δ), dove ε viene in genere scelto come una piccola costante e δ≪1/(numero di utenti).
Semantica della privacy
La progettazione ODP mira a garantire che ogni esecuzione dell'addestramento sia differenzialmente privata a livello di utente (ε,δ). Di seguito è descritto il nostro approccio per raggiungere questa semantica.
Modello di minaccia
Definiamo le diverse parti e indichiamo le ipotesi relative a ciascuna:
- Utente:l'utente proprietario del dispositivo e consumatore di prodotti o servizi forniti dallo sviluppatore. Le loro informazioni private sono completamente disponibili.
- Trusted Execution Environment (TEE): i dati e i calcoli attendibili che si verificano all'interno dei TEE sono protetti dagli autori di attacchi utilizzando una serie di tecnologie. Pertanto, il calcolo e i dati non richiedono alcuna protezione aggiuntiva. I TEE esistenti potrebbero consentire agli amministratori di progetto di accedere alle informazioni al loro interno. Proponiamo funzionalità personalizzate per impedire e verificare che l'accesso non sia disponibile per un amministratore.
- L'autore dell'attacco:potrebbe avere informazioni collaterali sull'utente e ha accesso completo a tutte le informazioni che escono dal TEE (ad esempio i parametri del modello pubblicato).
- Sviluppatore:chi definisce e addestra il modello. È considerato non attendibile (e ha la piena capacità di un malintenzionato).
Cerchiamo di progettare ODP con la seguente semantica della privacy differenziale:
- Confine di attendibilità:dal punto di vista di un utente, il confine di attendibilità è costituito dal dispositivo dell'utente e dal TEE. Qualsiasi informazione che esce da questo limite di attendibilità deve essere protetta dalla privacy differenziale.
- Attaccante:protezione completa della privacy differenziale rispetto all'attaccante. Qualsiasi entità al di fuori del limite di attendibilità può essere un malintenzionato (inclusi lo sviluppatore e altri utenti, tutti potenzialmente in combutta). L'attaccante, date tutte le informazioni al di fuori del limite di attendibilità (ad esempio, il modello pubblicato), qualsiasi informazione collaterale sull'utente e risorse infinite, non è in grado di dedurre ulteriori dati privati sull'utente (oltre a quelli già presenti nelle informazioni collaterali), fino alle probabilità indicate dal budget per la privacy. In particolare, ciò implica una protezione completa della privacy differenziale rispetto allo sviluppatore. Tutte le informazioni rilasciate allo sviluppatore (ad esempio i parametri del modello addestrato o le inferenze aggregate) sono protette dalla privacy differenziale.
Parametri del modello locale
La semantica della privacy precedente tiene conto del caso in cui alcuni parametri del modello sono locali al dispositivo (ad esempio un modello che contiene un embedding specifico per ogni utente e non condiviso tra gli utenti). Per questi modelli, i parametri locali rimangono all'interno del perimetro di attendibilità (non vengono pubblicati) e non richiedono protezione, mentre i parametri del modello condiviso vengono pubblicati (e sono protetti dalla privacy differenziale). A volte questo modello viene chiamato modello di privacy del cartellone pubblicitario 4.
Funzionalità pubbliche
In alcune applicazioni, alcune funzionalità sono pubbliche. Ad esempio, in un problema di raccomandazione di film, le caratteristiche di un film (il regista, il genere o l'anno di uscita) sono informazioni pubbliche e non richiedono protezione, mentre le caratteristiche relative all'utente (come i dati demografici o i film che ha guardato) sono dati privati e richiedono protezione.
Le informazioni pubbliche vengono formalizzate come una matrice delle funzionalità pubbliche (nell'esempio precedente, questa matrice conterrebbe una riga per film e una colonna per funzionalità del film), disponibile per tutte le parti. L'algoritmo di addestramento con privacy differenziale può utilizzare questa matrice senza la necessità di proteggerla. Vedi ad esempio 5. La piattaforma ODP prevede di implementare questi algoritmi.
Un approccio alla privacy durante la previsione o l'inferenza
Le inferenze si basano sui parametri del modello e sulle funzionalità di input. I parametri del modello vengono addestrati con la semantica della privacy differenziale. Qui viene discusso il ruolo delle funzionalità di input.
In alcuni casi d'uso, quando lo sviluppatore ha già accesso completo alle funzionalità utilizzate nell'inferenza, non ci sono problemi di privacy derivanti dall'inferenza e il risultato dell'inferenza potrebbe essere visibile allo sviluppatore.
In altri casi (quando le funzionalità utilizzate nell'inferenza sono private e non accessibili allo sviluppatore), il risultato dell'inferenza potrebbe essere nascosto allo sviluppatore, ad esempio eseguendo l'inferenza (e qualsiasi processo a valle che utilizza il risultato dell'inferenza) sul dispositivo, in un processo e un'area di visualizzazione di proprietà del sistema operativo, con comunicazione limitata al di fuori di questo processo.
Procedura di addestramento
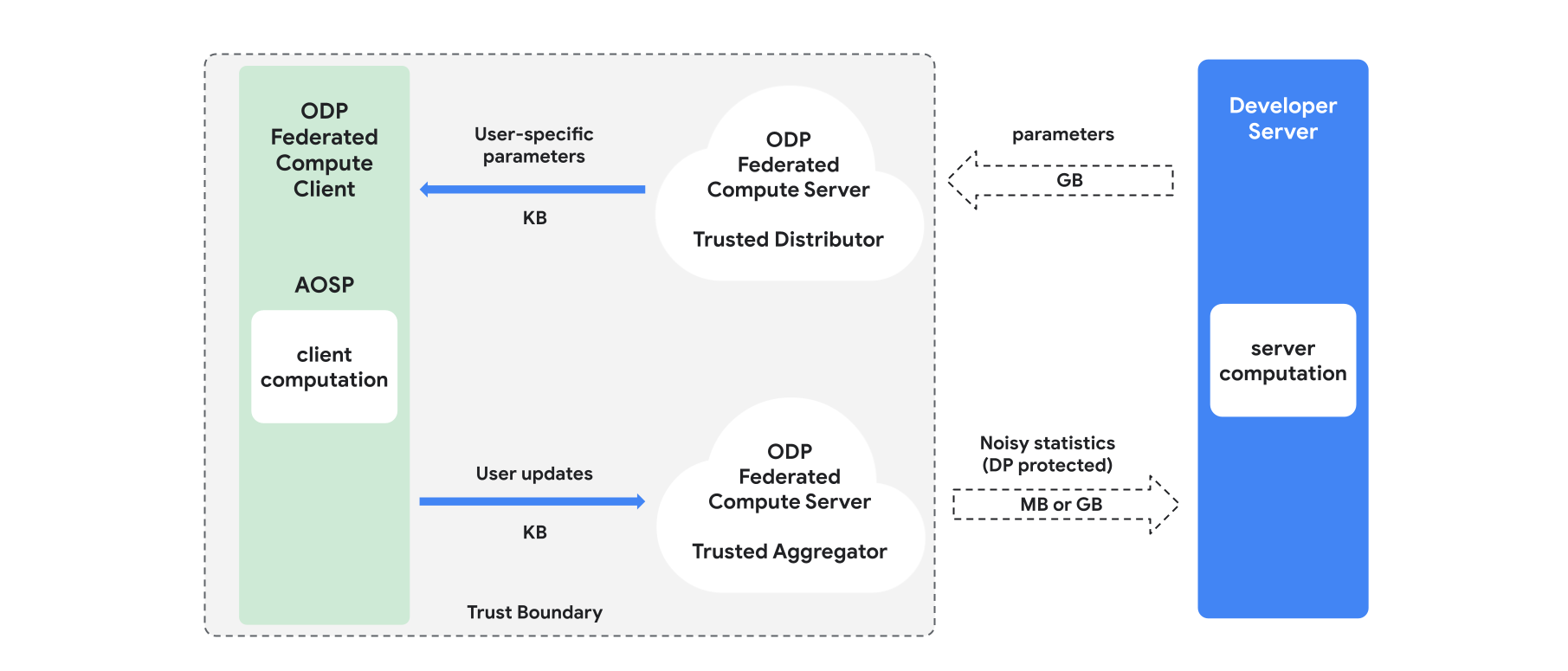
Panoramica
Questa sezione fornisce una panoramica dell'architettura e di come procede l'addestramento. Vedi la Figura 1. ODP implementa i seguenti componenti:
Un distributore attendibile, ad esempio federated select, trusted download o private information retrieval, che svolge il ruolo di trasmissione dei parametri del modello. Si presume che il distributore attendibile possa inviare un sottoinsieme di parametri a ogni client, senza rivelare quali parametri sono stati scaricati da quale client. Questa "trasmissione parziale" consente al sistema di ridurre al minimo l'impronta sul dispositivo dell'utente finale: anziché inviare una copia completa del modello, a ogni utente viene inviata solo una frazione dei parametri del modello.
Un aggregatore attendibile, che aggrega informazioni di più client (ad es. gradienti o altre statistiche), aggiunge rumore e invia il risultato al server. Si presume che esistano canali attendibili tra il client e l'aggregatore e tra il client e il distributore.
Algoritmi di addestramento DP eseguiti su questa infrastruttura. Ogni algoritmo di addestramento è costituito da calcoli diversi eseguiti sui diversi componenti (server, client, aggregatore, distributore).
Un tipico ciclo di addestramento è costituito dai seguenti passaggi:
- Il server trasmette i parametri del modello al distributore attendibile.
- Calcolo lato client
- Ogni dispositivo client riceve il modello di trasmissione (o il sottoinsieme di parametri pertinenti per l'utente).
- Ogni client esegue alcuni calcoli (ad esempio, calcola i gradienti o altre statistiche sufficienti).
- Ogni client invia il risultato del calcolo all'aggregatore attendibile.
- L'aggregatore attendibile raccoglie, aggrega e protegge le statistiche dei client utilizzando meccanismi di privacy differenziale adeguati, quindi invia il risultato al server.
- Calcolo del server
- Il server (non attendibile) esegue i calcoli sulle statistiche protette dalla privacy differenziale (ad esempio, utilizza gradienti aggregati di privacy differenziale per aggiornare i parametri del modello).
Modelli fattorizzati e minimizzazione alternata con privacy differenziale
La piattaforma ODP prevede di fornire algoritmi di addestramento differenzialmente privati di uso generale che possono essere applicati a qualsiasi architettura di modello (come DP-SGD 6 7 8 o DP-FTRL 9 10), nonché algoritmi specializzati per i modelli fattorizzati.
I modelli fattorizzati sono modelli che possono essere scomposti in sottomodelli (chiamati encoder o torri). Ad esempio, considera un modello della forma f(u(θu, xu), v(θv, xv)), dove u() codifica le funzionalità utente xu (e ha parametri θu) e v() codifica le funzionalità non utente xv (e ha parametri θv). Le due codifiche vengono combinate utilizzando f() per produrre la previsione finale del modello. Ad esempio, in un modello di consigli sui film, xu sono le funzionalità utente e xv sono le funzionalità dei film.
Questi modelli sono adatti all'architettura di sistema distribuito menzionata in precedenza (in quanto separano le funzionalità per gli utenti e non).
I modelli fattorizzati verranno addestrati utilizzando la minimizzazione alternata con privacy differenziale (DPAM), che alterna l'ottimizzazione dei parametri θu (mentre θv è fisso) e viceversa. È stato dimostrato che gli algoritmi DPAM ottengono una migliore utilità in una serie di impostazioni 4 11, in particolare in presenza di funzionalità pubbliche.
Riferimenti
- 1: Dwork et al. Calibrating Noise to Sensitivity in Private Data Analysis, TCC'06
- 2: US Census Bureau. Understanding Differential Privacy, 2020
- 3: Federated Learning with Formal Differential Privacy Guarantees, post del blog Google AI, 2020
- 4: Jain et al. Differentially Private Model Personalization, NeurIPS'21
- 5: Krichene et al. Private Learning with Public Features, 2023
- 6: Song et al. Stochastic gradient descent with differentially private updates, GlobalSIP'13
- 7: Differentially Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds, FOCS'14
- 8: Abadi et al. Deep Learning with Differential Privacy, CCS '16
- 9: Smith et al. (Nearly) Optimal Algorithms for Private Online Learning in Full-information and Bandit Settings, NeurIPS'13
- 10: Kairouz et al., Practical and Private (Deep) Learning without Sampling or Shuffling, ICML'21
- 11: Chien et al. Private Alternating Least Squares, ICML'21