
Dokumen ini merangkum pendekatan privasi untuk Personalisasi di Perangkat (ODP) khususnya dalam konteks privasi diferensial. Implikasi privasi dan keputusan desain lainnya seperti minimisasi data sengaja tidak disertakan agar dokumen ini tetap fokus.
Privasi diferensial
Privasi diferensial 1 adalah standar perlindungan privasi yang banyak digunakan dalam analisis data statistik dan machine learning 2 3. Secara informal, privasi diferensial menyatakan bahwa penyerang mempelajari hampir hal yang sama tentang pengguna dari output algoritma privasi diferensial, terlepas dari apakah data pengguna tersebut muncul dalam set data pokok atau tidak. Hal ini menyiratkan perlindungan yang kuat bagi individu: inferensi apa pun yang dibuat tentang seseorang hanya dapat dilakukan karena properti gabungan set data yang akan berlaku dengan atau tanpa catatan orang tersebut.
Dalam konteks machine learning, output algoritma harus dianggap sebagai parameter model terlatih. Frasa hampir sama secara matematis dikuantifikasi oleh dua parameter (ε, δ), dengan ε biasanya dipilih sebagai konstanta kecil, dan δ≪1/(jumlah pengguna).
Semantik privasi
Desain ODP berupaya memastikan setiap proses pelatihan bersifat pribadi diferensial tingkat pengguna (ε,δ). Berikut adalah pendekatan kami untuk mencapai semantik ini.
Model ancaman
Kita mendefinisikan berbagai pihak, dan menyatakan asumsi tentang masing-masing pihak:
- Pengguna: Pengguna yang memiliki perangkat, dan merupakan konsumen produk atau layanan yang disediakan oleh developer. Informasi pribadi mereka sepenuhnya tersedia untuk mereka sendiri.
- Trusted execution environment (TEE): Data dan komputasi tepercaya yang terjadi dalam TEE dilindungi dari penyerang menggunakan berbagai teknologi. Oleh karena itu, komputasi dan data tidak memerlukan perlindungan tambahan. TEE yang ada dapat mengizinkan admin project-nya mengakses informasi di dalamnya. Kami mengusulkan kemampuan kustom untuk melarang dan memvalidasi bahwa akses tidak tersedia bagi administrator.
- Penyerang: Mungkin memiliki informasi sampingan tentang pengguna dan memiliki akses penuh ke informasi apa pun yang keluar dari TEE (seperti parameter model yang dipublikasikan).
- Developer: Orang yang menentukan dan melatih model. Dianggap tidak tepercaya (dan memiliki kemampuan penyerang sepenuhnya).
Kami berupaya mendesain ODP dengan semantik privasi diferensial berikut:
- Batas kepercayaan: Dari perspektif satu pengguna, batas kepercayaan terdiri dari perangkat pengguna itu sendiri beserta TEE. Setiap informasi yang keluar dari batas kepercayaan ini harus dilindungi oleh privasi diferensial.
- Penyerang: Perlindungan privasi diferensial penuh sehubungan dengan penyerang. Entitas apa pun di luar batas kepercayaan dapat menjadi penyerang (termasuk developer dan pengguna lain, yang berpotensi berkolusi). Penyerang, yang diberi semua informasi di luar batas kepercayaan (misalnya, model yang dipublikasikan), informasi sampingan apa pun tentang pengguna, dan resource tak terbatas, tidak dapat menyimpulkan data pribadi tambahan tentang pengguna (di luar yang sudah ada dalam informasi sampingan), hingga peluang yang diberikan oleh anggaran privasi. Secara khusus, hal ini menyiratkan perlindungan privasi diferensial penuh sehubungan dengan developer. Setiap informasi yang dirilis kepada developer (seperti parameter model terlatih atau inferensi gabungan) dilindungi privasi diferensial.
Parameter model lokal
Semantik privasi sebelumnya mengakomodasi kasus ketika beberapa parameter model bersifat lokal untuk perangkat (misalnya, model yang berisi penyematan pengguna khusus untuk setiap pengguna, dan tidak dibagikan di antara pengguna). Untuk model tersebut, parameter lokal ini tetap berada dalam batas kepercayaan (tidak dipublikasikan) dan tidak memerlukan perlindungan, sedangkan parameter model bersama dipublikasikan (dan dilindungi oleh privasi diferensial). Hal ini terkadang disebut sebagai model privasi papan iklan 4.
Fitur publik
Di aplikasi tertentu, beberapa fitur bersifat publik. Misalnya, dalam masalah rekomendasi film, fitur film (sutradara, genre, atau tahun rilis film) adalah informasi publik dan tidak memerlukan perlindungan, sedangkan fitur yang terkait dengan pengguna (seperti informasi demografis atau film yang ditonton pengguna) adalah data pribadi dan memerlukan perlindungan.
Informasi publik diformalkan sebagai matriks fitur publik (dalam contoh sebelumnya, matriks ini akan berisi satu baris per film dan satu kolom per fitur film), yang tersedia untuk semua pihak. Algoritma pelatihan dengan privasi diferensial dapat menggunakan matriks ini tanpa perlu melindunginya, lihat misalnya 5. Platform ODP berencana menerapkan algoritma tersebut.
Pendekatan terhadap privasi selama prediksi atau inferensi
Inferensi didasarkan pada parameter model dan fitur input. Parameter model dilatih dengan semantik privasi diferensial. Di sini, peran fitur input dibahas.
Dalam beberapa kasus penggunaan, jika developer sudah memiliki akses penuh ke fitur yang digunakan dalam inferensi, tidak ada masalah privasi dari inferensi dan hasil inferensi mungkin terlihat oleh developer.
Dalam kasus lain (ketika fitur yang digunakan dalam inferensi bersifat pribadi dan tidak dapat diakses oleh developer), hasil inferensi dapat disembunyikan dari developer, misalnya, dengan menjalankan inferensi (dan proses hilir apa pun yang menggunakan hasil inferensi) di perangkat, dalam proses dan area tampilan milik OS, dengan komunikasi terbatas di luar proses tersebut.
Prosedur pelatihan
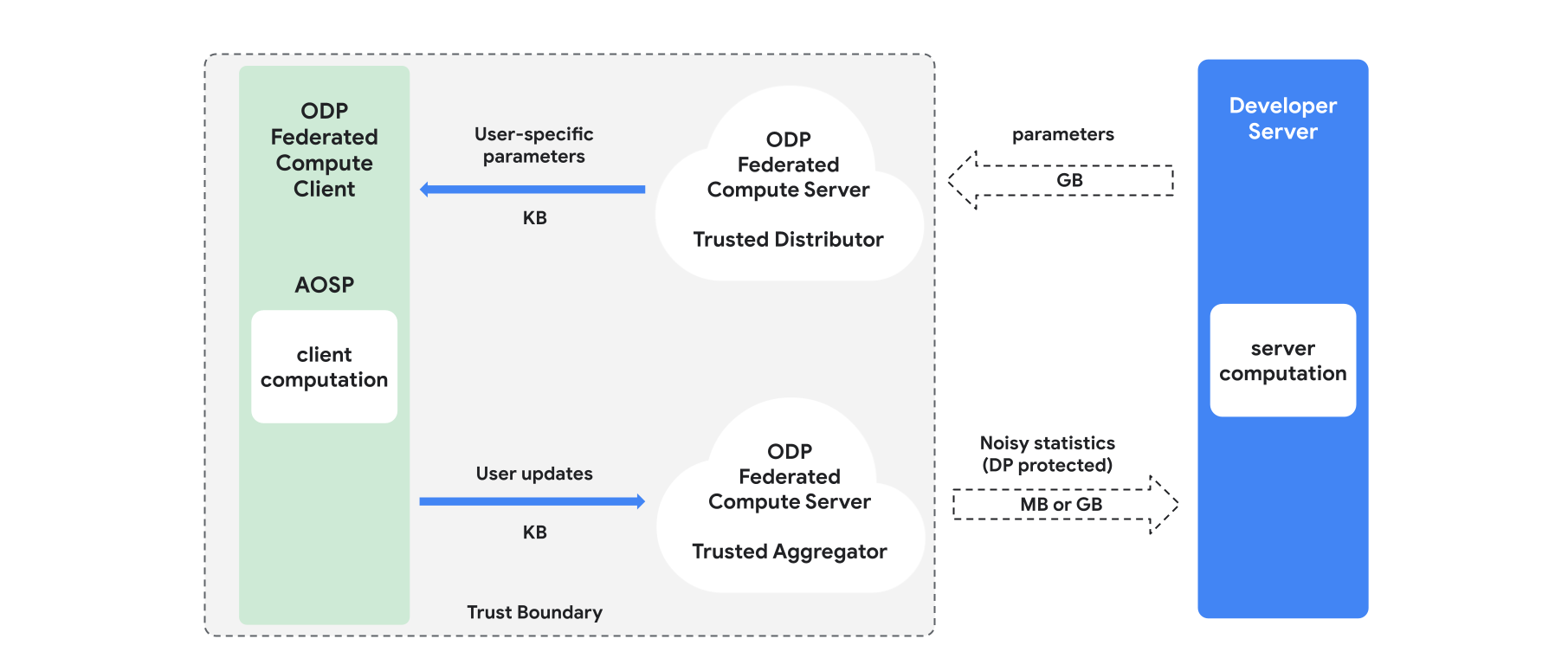
Ringkasan
Bagian ini memberikan ringkasan arsitektur dan cara pelatihan berlangsung, lihat Gambar 1. ODP mengimplementasikan komponen berikut:
Distributor tepercaya, seperti pemilihan gabungan, download tepercaya, atau pengambilan informasi pribadi, yang berperan sebagai menyiarkan parameter model. Diasumsikan bahwa distributor tepercaya dapat mengirimkan subset parameter ke setiap klien, tanpa mengungkapkan parameter apa yang didownload oleh klien mana. "Siaran parsial" ini memungkinkan sistem meminimalkan jejak di perangkat pengguna akhir: alih-alih mengirim salinan lengkap model, hanya sebagian kecil parameter model yang dikirim ke pengguna tertentu.
Agregator tepercaya, yang menggabungkan informasi dari beberapa klien (misalnya, gradien, atau statistik lainnya), menambahkan derau, dan mengirimkan hasilnya ke server. Asumsinya adalah ada saluran tepercaya antara klien dan penggabung, serta antara klien dan distributor.
Algoritma pelatihan DP yang berjalan di infrastruktur ini. Setiap algoritma pelatihan terdiri dari komputasi berbeda yang berjalan di berbagai komponen (server, klien, penggabung, distributor).
Sesi pelatihan umum terdiri dari langkah-langkah berikut:
- Server menyiarkan parameter model ke distributor tepercaya.
- Komputasi klien
- Setiap perangkat klien menerima model siaran (atau subset parameter yang relevan dengan pengguna).
- Setiap klien melakukan beberapa komputasi (misalnya, menghitung gradien atau statistik lain yang memadai).
- Setiap klien mengirimkan hasil komputasi ke penggabung tepercaya.
- Agregator tepercaya mengumpulkan, menggabungkan, dan melindungi statistik dari klien menggunakan mekanisme privasi diferensial yang tepat, lalu mengirimkan hasilnya ke server.
- Komputasi server
- Server (yang tidak tepercaya) menjalankan komputasi pada statistik yang dilindungi privasi diferensial (misalnya, menggunakan gradien gabungan privasi diferensial untuk memperbarui parameter model).
Model Terfaktor dan Minimalisasi Alternatif Differentially Private
Platform ODP berencana menyediakan algoritma pelatihan dengan privasi diferensial tujuan umum yang dapat diterapkan ke arsitektur model apa pun (seperti DP-SGD 6 7 8 atau DP-FTRL 9 10, serta algoritma yang dikhususkan untuk model terfaktor.
Model terfaktor adalah model yang dapat diuraikan menjadi sub-model (disebut encoder, atau menara). Misalnya, pertimbangkan model formulir f(u(θu, xu), v(θv, xv)), dengan u() mengenkode fitur pengguna xu (dan memiliki parameter θu), dan v() mengenkode fitur non-pengguna xv (dan memiliki parameter θv). Kedua encoding digabungkan menggunakan f() untuk menghasilkan prediksi model akhir. Misalnya, dalam model rekomendasi film, xu adalah fitur pengguna dan xv adalah fitur film.
Model tersebut sangat cocok untuk arsitektur sistem terdistribusi yang disebutkan di atas (karena memisahkan fitur pengguna dan non-pengguna).
Model terfaktor akan dilatih menggunakan Minimalisasi Alternatif dengan Privasi Diferensial (DPAM), yang bergantian antara mengoptimalkan parameter θu (saat θv ditetapkan) dan sebaliknya. Algoritma DPAM telah terbukti mencapai utilitas yang lebih baik dalam berbagai setelan 4 11, khususnya jika ada fitur publik.
Referensi
- 1: Dwork et al. Calibrating Noise to Sensitivity in Private Data Analysis, TCC'06
- 2: US Census Bureau. Understanding Differential Privacy, 2020
- 3: Federated Learning with Formal Differential Privacy Guarantees, Google AI Blog Post, 2020
- 4: Jain et al. Differentially Private Model Personalization, NeurIPS'21
- 5: Krichene et al. Private Learning with Public Features, 2023
- 6: Song et al. Stochastic gradient descent with differentially private updates, GlobalSIP'13
- 7: Differentially Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds, FOCS'14
- 8: Abadi et al. Deep Learning with Differential Privacy, CCS '16
- 9: Smith et al. (Nearly) Optimal Algorithms for Private Online Learning in Full-information and Bandit Settings, NeurIPS'13
- 10: Kairouz dkk., Practical and Private (Deep) Learning without Sampling or Shuffling, ICML'21
- 11: Chien et al. Private Alternating Least Squares, ICML'21