
इस दस्तावेज़ में, डिवाइस पर उपयोगकर्ता के हिसाब से अनुभव को बेहतर बनाने (ओडीपी) के लिए, निजता से जुड़े तरीके के बारे में खास जानकारी दी गई है. यह जानकारी, खास तौर पर डिफ़रेंशियल प्राइवसी के संदर्भ में दी गई है. इस दस्तावेज़ को फ़ोकस में रखने के लिए, निजता से जुड़े अन्य पहलुओं और डिज़ाइन से जुड़े फ़ैसलों, जैसे कि डेटा को कम से कम इस्तेमाल करने के सिद्धांत को जान-बूझकर शामिल नहीं किया गया है.
डिफ़रेंशियल प्राइवसी
डिफ़रेंशियल प्राइवसी 1, निजता की सुरक्षा का एक ऐसा स्टैंडर्ड है जिसे सांख्यिकीय डेटा विश्लेषण और मशीन लर्निंग 2 3 में बड़े पैमाने पर अपनाया जाता है. आसान शब्दों में कहें, तो इसका मतलब है कि डिफ़रेंशियल प्राइवसी वाले एल्गोरिदम के आउटपुट से, किसी विरोधी को उपयोगकर्ता के बारे में लगभग वही जानकारी मिलती है. भले ही, उपयोगकर्ता का रिकॉर्ड डेटासेट में मौजूद हो या न हो. इसका मतलब है कि लोगों के लिए, निजता की सुरक्षा के कड़े इंतज़ाम किए गए हैं: किसी व्यक्ति के बारे में कोई भी अनुमान सिर्फ़ डेटासेट की एग्रीगेट प्रॉपर्टी की वजह से लगाया जा सकता है. यह अनुमान, उस व्यक्ति के रिकॉर्ड के साथ या उसके बिना भी लगाया जा सकता है.
मशीन लर्निंग के संदर्भ में, एल्गोरिदम के आउटपुट को ट्रेन किए गए मॉडल पैरामीटर के तौर पर देखा जाना चाहिए. लगभग एक जैसी चीज़ वाक्यांश को गणित के हिसाब से दो पैरामीटर (ε, δ) से तय किया जाता है. इसमें ε को आम तौर पर एक छोटा कॉन्स्टेंट चुना जाता है और δ≪1/(उपयोगकर्ताओं की संख्या) होती है.
निजता से जुड़े सिमेंटिक
ODP का डिज़ाइन यह पक्का करता है कि ट्रेनिंग का हर रन, (ε,δ)-उपयोगकर्ता लेवल पर अलग-अलग निजता वाला हो. इस सिमैंटिक तक पहुंचने के लिए, हम यहां दिए गए तरीके का इस्तेमाल करते हैं.
खतरे का मॉडल
हम अलग-अलग पक्षों के बारे में बताते हैं. साथ ही, हर पक्ष के बारे में अनुमानित जानकारी देते हैं:
- उपयोगकर्ता: वह व्यक्ति जिसके पास डिवाइस का मालिकाना हक है. साथ ही, वह डेवलपर के प्रॉडक्ट या सेवाओं का इस्तेमाल करता है. उनकी निजी जानकारी, सिर्फ़ उन्हें दिखती है.
- ट्रस्टेड एक्ज़ीक्यूशन एनवायरमेंट (टीईई): टीईई में मौजूद डेटा और भरोसेमंद कंप्यूटेशन को, कई तरह की टेक्नोलॉजी का इस्तेमाल करके हमलावरों से सुरक्षित रखा जाता है. इसलिए, डेटा और कंप्यूटेशन को किसी अतिरिक्त सुरक्षा की ज़रूरत नहीं होती. मौजूदा टीईई, अपने प्रोजेक्ट एडमिन को अंदर मौजूद जानकारी ऐक्सेस करने की अनुमति दे सकते हैं. हम कस्टम सुविधाएं उपलब्ध कराते हैं, ताकि यह पुष्टि की जा सके कि एडमिन के पास ऐक्सेस नहीं है.
- हमलावर: इसके पास उपयोगकर्ता के बारे में कुछ जानकारी हो सकती है और इसके पास टीईई से बाहर जाने वाली किसी भी जानकारी का पूरा ऐक्सेस होता है. जैसे, पब्लिश किए गए मॉडल पैरामीटर.
- डेवलपर: मॉडल को तय करने और उसे ट्रेन करने वाला व्यक्ति. इसे भरोसेमंद नहीं माना जाता. साथ ही, इस पर हमलावर का पूरा कंट्रोल होता है.
हम डिफ़रेंशियल प्राइवसी के इन सिमैंटिक के साथ ओडीपी को डिज़ाइन करना चाहते हैं:
- भरोसेमंद सीमा: किसी उपयोगकर्ता के हिसाब से, भरोसेमंद सीमा में उपयोगकर्ता का डिवाइस और टीईई शामिल होता है. इस ट्रस्ट बाउंड्री से बाहर जाने वाली किसी भी जानकारी को डिफ़रेंशियल प्राइवसी से सुरक्षित रखा जाना चाहिए.
- हमलावर: हमलावर के हिसाब से, डिफ़रेंशियल प्राइवसी की पूरी सुरक्षा. भरोसेमंद सीमा से बाहर की कोई भी इकाई हमलावर हो सकती है. इसमें डेवलपर और अन्य उपयोगकर्ता शामिल हैं. ये सभी मिलकर हमला कर सकते हैं. हमलावर को भरोसेमंद सीमा के बाहर की सभी जानकारी (जैसे, पब्लिश किया गया मॉडल), उपयोगकर्ता के बारे में कोई भी अन्य जानकारी, और असीमित संसाधन दिए जाते हैं. इसके बावजूद, वह उपयोगकर्ता के बारे में अतिरिक्त निजी डेटा का अनुमान नहीं लगा पाता. यह डेटा, अन्य जानकारी में मौजूद डेटा के अलावा होता है. ऐसा निजता बजट के हिसाब से तय की गई संभावनाओं के आधार पर होता है. खास तौर पर, इसका मतलब है कि डेवलपर के लिए, डिफ़रेंशियल प्राइवसी की पूरी सुरक्षा उपलब्ध है. डेवलपर को रिलीज़ की गई किसी भी जानकारी (जैसे, ट्रेन किए गए मॉडल के पैरामीटर या एग्रीगेट अनुमान) को डिफ़रेंशियल प्राइवसी से सुरक्षित रखा जाता है.
लोकल मॉडल के पैरामीटर
निजता से जुड़े पिछले सिमैंटिक में, ऐसे मामले को शामिल किया गया है जहां मॉडल के कुछ पैरामीटर डिवाइस के हिसाब से अलग-अलग होते हैं. उदाहरण के लिए, ऐसा मॉडल जिसमें हर उपयोगकर्ता के लिए खास तौर पर तैयार की गई एम्बेडिंग होती है और जिसे उपयोगकर्ताओं के साथ शेयर नहीं किया जाता है. ऐसे मॉडल के लिए, ये लोकल पैरामीटर भरोसेमंद सीमा के अंदर ही रहते हैं. इन्हें पब्लिश नहीं किया जाता और इनकी सुरक्षा करने की ज़रूरत नहीं होती. वहीं, शेयर किए गए मॉडल पैरामीटर पब्लिश किए जाते हैं और इन्हें डिफ़रेंशियल प्राइवसी से सुरक्षित रखा जाता है. इसे कभी-कभी बिलबोर्ड प्राइवसी मॉडल 4 भी कहा जाता है.
सार्वजनिक सुविधाएं
कुछ ऐप्लिकेशन में, कुछ सुविधाएं सार्वजनिक होती हैं. उदाहरण के लिए, फ़िल्म का सुझाव देने की समस्या में, फ़िल्म की सुविधाओं (फ़िल्म के निर्देशक, शैली या रिलीज़ होने का साल) की जानकारी सार्वजनिक होती है और इसे सुरक्षित रखने की ज़रूरत नहीं होती. वहीं, उपयोगकर्ता से जुड़ी सुविधाओं (जैसे, डेमोग्राफ़िक जानकारी या उपयोगकर्ता ने कौनसी फ़िल्में देखीं) का डेटा निजी होता है और इसे सुरक्षित रखने की ज़रूरत होती है.
सार्वजनिक जानकारी को सार्वजनिक फ़ीचर मैट्रिक्स के तौर पर फ़ॉर्मलाइज़ किया जाता है. ऊपर दिए गए उदाहरण में, इस मैट्रिक्स में हर फ़िल्म के लिए एक लाइन और हर फ़िल्म की सुविधा के लिए एक कॉलम होगा. यह मैट्रिक्स सभी पक्षों के लिए उपलब्ध होता है. डिफ़रेंशियल प्राइवसी वाले ट्रेनिंग एल्गोरिदम, इस मैट्रिक्स का इस्तेमाल कर सकते हैं. इसके लिए, उन्हें इसे सुरक्षित रखने की ज़रूरत नहीं होती. उदाहरण के लिए, 5 देखें. ओडीपी प्लैटफ़ॉर्म, इस तरह के एल्गोरिदम लागू करने का प्लान बना रहा है.
अनुमान या अनुमान लगाने के दौरान निजता बनाए रखने का तरीका
अनुमान, मॉडल के पैरामीटर और इनपुट सुविधाओं के आधार पर लगाए जाते हैं. मॉडल के पैरामीटर को डिफ़रेंशियल प्राइवसी सिमैंटिक के साथ ट्रेन किया जाता है. यहां इनपुट सुविधाओं की भूमिका के बारे में बताया गया है.
कुछ मामलों में, जब डेवलपर के पास अनुमान लगाने के लिए इस्तेमाल की गई सुविधाओं का पूरा ऐक्सेस होता है, तो अनुमान लगाने से जुड़ी निजता की कोई समस्या नहीं होती. साथ ही, अनुमान लगाने के नतीजे डेवलपर को दिख सकते हैं.
अन्य मामलों में, अनुमान लगाने के लिए इस्तेमाल की जाने वाली सुविधाएं निजी होती हैं और डेवलपर के लिए उपलब्ध नहीं होती हैं. ऐसे में, अनुमान के नतीजे को डेवलपर से छिपाया जा सकता है. उदाहरण के लिए, अनुमान लगाने की प्रोसेस और अनुमान के नतीजे का इस्तेमाल करने वाली किसी भी डाउनस्ट्रीम प्रोसेस को डिवाइस पर चलाया जा सकता है. साथ ही, इसे ओएस के मालिकाना हक वाली प्रोसेस और डिसप्ले एरिया में चलाया जा सकता है. इसके अलावा, इस प्रोसेस के बाहर कम्यूनिकेशन को सीमित किया जा सकता है.
ट्रेनिंग का तरीका
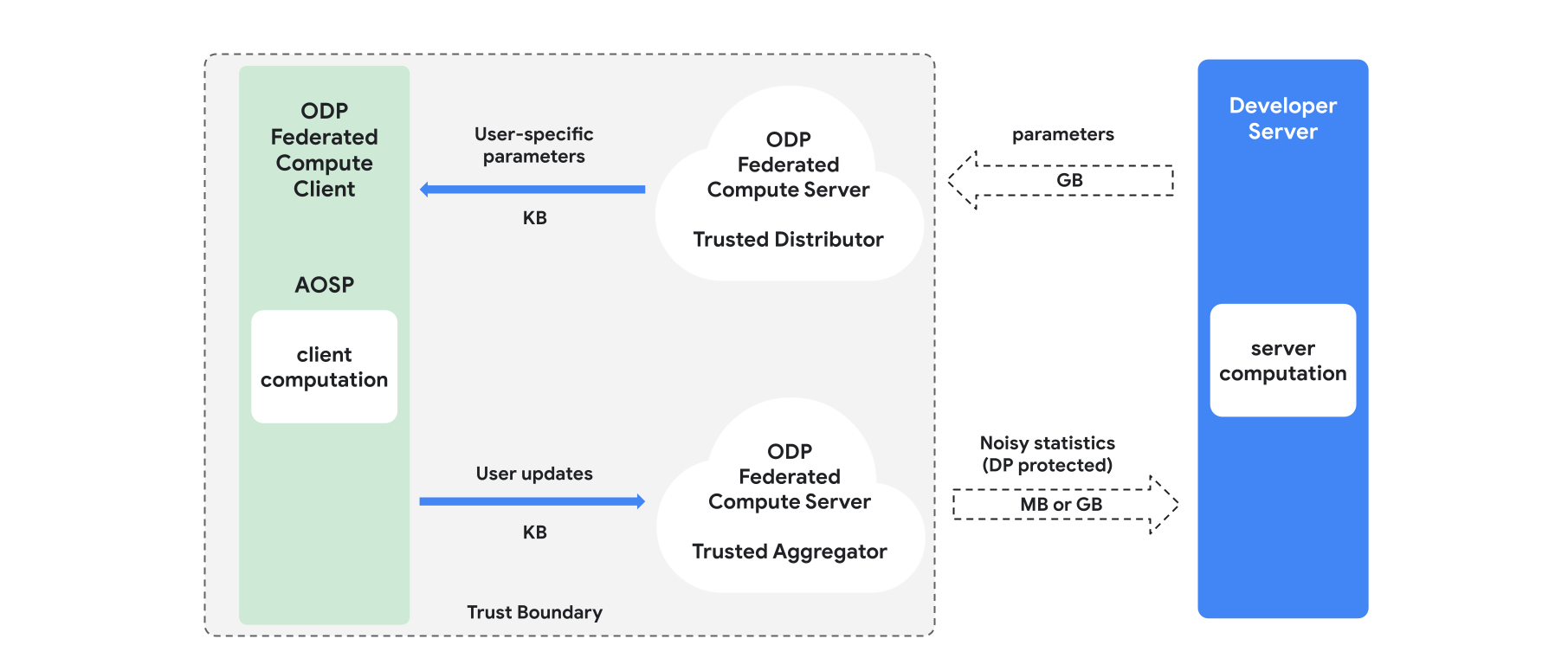
खास जानकारी
इस सेक्शन में, आर्किटेक्चर और ट्रेनिंग के तरीके के बारे में खास जानकारी दी गई है. इसके लिए, इमेज 1 देखें. ODP इन कॉम्पोनेंट को लागू करता है:
भरोसेमंद डिस्ट्रिब्यूटर, जैसे कि फ़ेडरेटेड सिलेक्ट, भरोसेमंद डाउनलोड या निजी जानकारी को वापस पाना. यह ब्रॉडकास्टिंग मॉडल पैरामीटर की भूमिका निभाता है. यह माना जाता है कि भरोसेमंद डिस्ट्रिब्यूटर, हर क्लाइंट को पैरामीटर का सबसेट भेज सकता है. हालांकि, वह यह ज़ाहिर नहीं करेगा कि किस क्लाइंट ने कौनसे पैरामीटर डाउनलोड किए हैं. "आंशिक ब्रॉडकास्ट" की मदद से, सिस्टम को एंड-यूज़र डिवाइस पर फ़ुटप्रिंट को कम करने की अनुमति मिलती है: मॉडल की पूरी कॉपी भेजने के बजाय, मॉडल के पैरामीटर का सिर्फ़ एक हिस्सा किसी भी उपयोगकर्ता को भेजा जाता है.
एक भरोसेमंद एग्रीगेटर, जो कई क्लाइंट से जानकारी इकट्ठा करता है.जैसे, ग्रेडिएंट या अन्य आंकड़े. इसके बाद, वह इसमें नॉइज़ जोड़ता है और नतीजे को सर्वर पर भेजता है. यह माना जाता है कि क्लाइंट और एग्रीगेटर के बीच, साथ ही क्लाइंट और डिस्ट्रिब्यूटर के बीच भरोसेमंद चैनल मौजूद हैं.
इस इंफ़्रास्ट्रक्चर पर काम करने वाले डीपी ट्रेनिंग एल्गोरिदम. हर ट्रेनिंग एल्गोरिदम में अलग-अलग तरह की कंप्यूटिंग होती है. ये अलग-अलग कॉम्पोनेंट (सर्वर, क्लाइंट, एग्रीगेटर, डिस्ट्रिब्यूटर) पर चलती हैं.
ट्रेनिंग के सामान्य राउंड में ये चरण शामिल होते हैं:
- सर्वर, मॉडल के पैरामीटर को भरोसेमंद डिस्ट्रिब्यूटर के साथ ब्रॉडकास्ट करता है.
- क्लाइंट कंप्यूटेशन
- हर क्लाइंट डिवाइस को ब्रॉडकास्ट मॉडल मिलता है. इसके अलावा, उपयोगकर्ता के लिए काम के पैरामीटर का सबसेट भी मिलता है.
- हर क्लाइंट कुछ हिसाब-किताब करता है. उदाहरण के लिए, ग्रेडिएंट या अन्य ज़रूरी आंकड़े का हिसाब लगाना.
- हर क्लाइंट, कंप्यूटेशन का नतीजा भरोसेमंद एग्रीगेटर को भेजता है.
- भरोसेमंद एग्रीगेटर, क्लाइंट से मिले आंकड़ों को इकट्ठा करता है, उन्हें एग्रीगेट करता है, और डिफ़रेंशियल प्राइवसी के सही तरीकों का इस्तेमाल करके उनकी सुरक्षा करता है. इसके बाद, वह सर्वर को नतीजे भेजता है.
- सर्वर पर कंप्यूटेशन
- (अनट्रस्टेड) सर्वर, डिफ़रेंशियल प्राइवसी से सुरक्षित आंकड़ों पर कंप्यूटेशन करता है. उदाहरण के लिए, मॉडल के पैरामीटर को अपडेट करने के लिए, डिफ़रेंशियल प्राइवसी से सुरक्षित एग्रीगेटेड ग्रेडिएंट का इस्तेमाल करता है.
फ़ैक्टराइज़्ड मॉडल और डिफ़रेंशियली प्राइवेट अल्टरनेटिंग मिनिमाइज़ेशन
ODP प्लैटफ़ॉर्म, सामान्य मकसद के लिए अलग-अलग तरह के ट्रेनिंग एल्गोरिदम उपलब्ध कराने का प्लान बना रहा है. इन्हें किसी भी मॉडल आर्किटेक्चर पर लागू किया जा सकता है. जैसे, DP-SGD 6 7 8 या DP-FTRL 9 10. साथ ही, फ़ैक्टराइज़्ड मॉडल के लिए खास एल्गोरिदम भी उपलब्ध कराए जाएंगे.
फ़ैक्टराइज़्ड मॉडल ऐसे मॉडल होते हैं जिन्हें सब-मॉडल (जिन्हें एनकोडर या टावर कहा जाता है) में बांटा जा सकता है. उदाहरण के लिए, f(u(θu, xu), v(θv, xv)) फ़ॉर्मैट वाले मॉडल पर विचार करें. इसमें u(), उपयोगकर्ता की सुविधाओं xu को कोड में बदलता है और इसमें पैरामीटर θu होते हैं. वहीं, v(), उपयोगकर्ता से जुड़ी सुविधाओं xv को कोड में बदलता है और इसमें पैरामीटर θv होते हैं. दोनों एन्कोडिंग को f() का इस्तेमाल करके जोड़ा जाता है, ताकि मॉडल की फ़ाइनल भविष्यवाणी की जा सके. उदाहरण के लिए, फ़िल्म के सुझाव देने वाले मॉडल में, xu उपयोगकर्ता की विशेषताएं हैं और xv फ़िल्म की विशेषताएं हैं.
इस तरह के मॉडल, ऊपर बताए गए डिस्ट्रिब्यूटेड सिस्टम आर्किटेक्चर के लिए सबसे सही होते हैं. ऐसा इसलिए, क्योंकि ये मॉडल उपयोगकर्ता और गैर-उपयोगकर्ता की सुविधाओं को अलग-अलग करते हैं.
फ़ैक्टराइज़्ड मॉडल को, डिफ़रेंशियल प्राइवेट अल्टरनेटिंग मिनिमाइज़ेशन (डीपीएएम) का इस्तेमाल करके ट्रेन किया जाएगा. यह θu पैरामीटर को ऑप्टिमाइज़ करने के लिए (जबकि θv को फ़िक्स किया जाता है) और इसके उलट काम करता है. DPAM एल्गोरिदम, कई तरह की सेटिंग में बेहतर परफ़ॉर्म करते हैं 4 11. खास तौर पर, सार्वजनिक सुविधाओं के मामले में.
रेफ़रंस
- 1: Dwork et al. Calibrating Noise to Sensitivity in Private Data Analysis, TCC'06
- 2: US Census Bureau. Understanding Differential Privacy, 2020
- 3: Federated Learning with Formal Differential Privacy Guarantees, Google AI Blog Post, 2020
- 4: Jain et al. Differentially Private Model Personalization, NeurIPS'21
- 5: Krichene et al. Private Learning with Public Features, 2023
- 6: Song et al. Stochastic gradient descent with differentially private updates, GlobalSIP'13
- 7: Differentially Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds, FOCS'14
- 8: Abadi et al. Deep Learning with Differential Privacy, CCS '16
- 9: Smith et al. (Nearly) Optimal Algorithms for Private Online Learning in Full-information and Bandit Settings, NeurIPS'13
- 10: Kairouz et al., Practical and Private (Deep) Learning without Sampling or Shuffling, ICML'21
- 11: Chien et al. Private Alternating Least Squares, ICML'21