
Ce document résume l'approche de confidentialité pour la personnalisation sur l'appareil (ODP, On-Device Personalization), en particulier dans le contexte de la confidentialité différentielle. D'autres implications en termes de confidentialité et décisions de conception, telles que la minimisation des données, sont intentionnellement omises pour que ce document reste axé sur le sujet.
Confidentialité différentielle
La confidentialité différentielle 1 est une norme de protection de la confidentialité largement adoptée dans l'analyse statistique des données et le machine learning 2 3. En termes simples, cela signifie qu'un adversaire apprend presque la même chose sur un utilisateur à partir du résultat d'un algorithme différentiellement privé, que son enregistrement figure ou non dans l'ensemble de données sous-jacent. Cela implique une protection renforcée pour les personnes : toutes les inférences faites sur une personne ne peuvent être dues qu'aux propriétés agrégées de l'ensemble de données qui seraient valables avec ou sans l'enregistrement de cette personne.
Dans le contexte du machine learning, la sortie de l'algorithme doit être considérée comme les paramètres du modèle entraîné. L'expression presque la même chose est quantifiée mathématiquement par deux paramètres (ε, δ), où ε est généralement choisi pour être une petite constante, et δ≪1/(nombre d'utilisateurs).
Sémantique de confidentialité
La conception de l'ODP vise à garantir que chaque exécution d'entraînement est différentiellement privée au niveau de l'utilisateur (ε,δ). Vous trouverez ci-dessous notre approche pour atteindre cette sémantique.
Type de menace
Nous définissons les différentes parties et énonçons des hypothèses concernant chacune d'elles :
- Utilisateur : utilisateur propriétaire de l'appareil et consommateur des produits ou services fournis par le développeur. Ils ont accès à toutes leurs informations privées.
- Environnement d'exécution sécurisé (TEE) : les données et les calculs fiables qui ont lieu dans les TEE sont protégés contre les pirates informatiques à l'aide de diverses technologies. Par conséquent, le calcul et les données ne nécessitent aucune protection supplémentaire. Les TEE existants peuvent autoriser les administrateurs de projet à accéder aux informations qu'ils contiennent. Nous proposons des fonctionnalités personnalisées pour interdire l'accès à un administrateur et valider qu'il n'y a pas accès.
- Le pirate informatique : il peut disposer d'informations annexes sur l'utilisateur et avoir un accès complet à toutes les informations quittant l'environnement d'exécution sécurisé (TEE, Trusted Execution Environment), comme les paramètres du modèle publié.
- Développeur : personne qui définit et entraîne le modèle. Est considéré comme non fiable (et dispose de toutes les capacités d'un pirate informatique).
Nous cherchons à concevoir l'ODP avec la sémantique suivante de confidentialité différentielle :
- Limite de confiance : du point de vue d'un utilisateur, la limite de confiance se compose de son propre appareil et de l'environnement d'exécution sécurisé. Toute information qui quitte cette limite de confiance doit être protégée par la confidentialité différentielle.
- Attaquant : protection complète de la confidentialité différentielle par rapport à l'attaquant. Toute entité en dehors de la limite de confiance peut être un pirate informatique (y compris le développeur et d'autres utilisateurs, qui peuvent tous être de connivence). Étant donné toutes les informations en dehors de la limite de confiance (par exemple, le modèle publié), toutes les informations annexes sur l'utilisateur et des ressources infinies, le pirate informatique n'est pas en mesure d'inférer des données privées supplémentaires sur l'utilisateur (au-delà de celles déjà présentes dans les informations annexes), jusqu'aux chances données par le budget de confidentialité. Cela implique en particulier une protection complète de la confidentialité différentielle vis-à-vis du développeur. Toutes les informations communiquées au développeur (telles que les paramètres du modèle entraîné ou les inférences agrégées) sont protégées par la confidentialité différentielle.
Paramètres du modèle local
Les règles de confidentialité précédentes s'appliquent dans le cas où certains paramètres du modèle sont locaux à l'appareil (par exemple, un modèle qui contient un embedding utilisateur spécifique à chaque utilisateur et non partagé entre les utilisateurs). Pour ces modèles, ces paramètres locaux restent dans la limite de confiance (ils ne sont pas publiés) et ne nécessitent aucune protection, tandis que les paramètres de modèle partagés sont publiés (et sont protégés par la confidentialité différentielle). On parle parfois de modèle de confidentialité de type panneau publicitaire 4.
Fonctionnalités publiques
Dans certaines applications, certaines fonctionnalités sont publiques. Par exemple, dans un problème de recommandation de films, les caractéristiques d'un film (son réalisateur, son genre ou son année de sortie) sont des informations publiques qui ne nécessitent pas de protection, tandis que les caractéristiques liées à l'utilisateur (comme les informations démographiques ou les films qu'il a regardés) sont des données privées qui nécessitent une protection.
Les informations publiques sont formalisées sous la forme d'une matrice de caractéristiques publiques (dans l'exemple précédent, cette matrice contiendrait une ligne par film et une colonne par caractéristique de film), qui est disponible pour toutes les parties. L'algorithme d'entraînement avec confidentialité différentielle peut utiliser cette matrice sans avoir besoin de la protéger (voir, par exemple, 5). La plate-forme ODP prévoit d'implémenter de tels algorithmes.
Une approche de la confidentialité lors de la prédiction ou de l'inférence
Les inférences sont basées sur les paramètres du modèle et sur les caractéristiques d'entrée. Les paramètres du modèle sont entraînés avec la sémantique de confidentialité différentielle. Le rôle des caractéristiques d'entrée est abordé ici.
Dans certains cas d'utilisation, lorsque le développeur a déjà un accès complet aux fonctionnalités utilisées dans l'inférence, il n'y a pas de problème de confidentialité lié à l'inférence et le développeur peut voir le résultat de l'inférence.
Dans d'autres cas (lorsque les fonctionnalités utilisées dans l'inférence sont privées et non accessibles au développeur), le résultat de l'inférence peut être masqué au développeur, par exemple en exécutant l'inférence (et tout processus en aval qui utilise le résultat de l'inférence) sur l'appareil, dans un processus et une zone d'affichage appartenant à l'OS, avec une communication limitée en dehors de ce processus.
Procédure d'entraînement
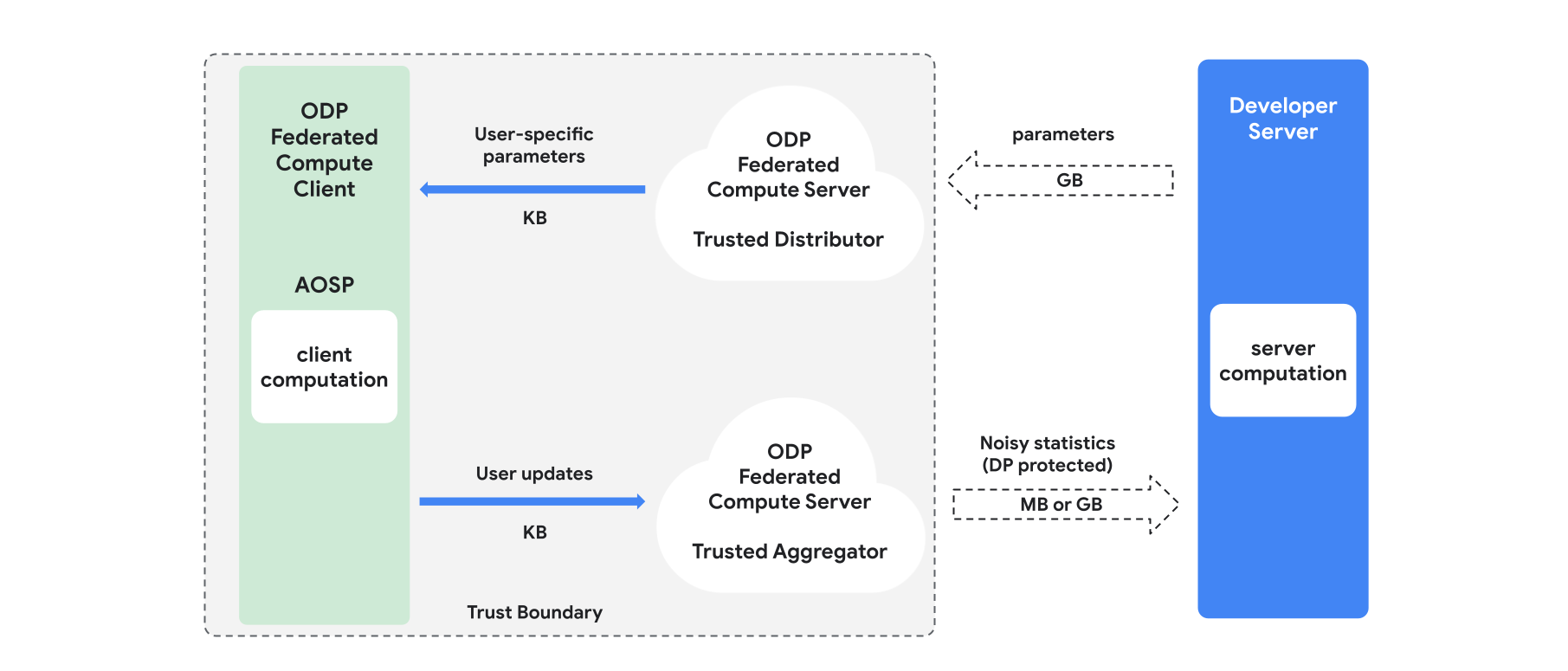
Présentation
Cette section présente l'architecture et le déroulement de l'entraînement (voir la figure 1). ODP implémente les composants suivants :
Distributeur de confiance, tel que la sélection fédérée, le téléchargement de confiance ou la récupération d'informations privées, qui joue le rôle de diffusion des paramètres du modèle. On suppose que le distributeur de confiance peut envoyer un sous-ensemble de paramètres à chaque client, sans révéler quels paramètres ont été téléchargés par quel client. Cette "diffusion partielle" permet au système de minimiser l'empreinte sur l'appareil de l'utilisateur final : au lieu d'envoyer une copie complète du modèle, seule une fraction des paramètres du modèle est envoyée à un utilisateur donné.
Un agrégateur de confiance, qui agrège les informations de plusieurs clients (par exemple, les gradients ou d'autres statistiques), ajoute du bruit et envoie le résultat au serveur. L'hypothèse est qu'il existe des canaux fiables entre le client et l'agrégateur, et entre le client et le distributeur.
Algorithmes d'entraînement DP qui s'exécutent sur cette infrastructure. Chaque algorithme d'entraînement se compose de différents calculs exécutés sur les différents composants (serveur, client, agrégateur, distributeur).
Une série d'entraînement type comprend les étapes suivantes :
- Le serveur diffuse les paramètres du modèle au distributeur de confiance.
- Calcul côté client
- Chaque appareil client reçoit le modèle de diffusion (ou le sous-ensemble de paramètres pertinents pour l'utilisateur).
- Chaque client effectue des calculs (par exemple, le calcul des gradients ou d'autres statistiques suffisantes).
- Chaque client envoie le résultat du calcul à l'agrégateur de confiance.
- L'agrégateur de confiance collecte, agrège et protège les statistiques des clients à l'aide de mécanismes de confidentialité différentielle appropriés, puis envoie le résultat au serveur.
- Calcul du serveur
- Le serveur (non fiable) exécute des calculs sur les statistiques protégées par la confidentialité différentielle (par exemple, il utilise des gradients agrégés différentiellement privés pour mettre à jour les paramètres du modèle).
Modèles factorisés et minimisation en alternance à confidentialité différentielle
La plate-forme ODP prévoit de fournir des algorithmes d'entraînement à usage général avec confidentialité différentielle qui peuvent être appliqués à n'importe quelle architecture de modèle (tels que DP-SGD 6 7 8 ou DP-FTRL 9 10, ainsi que des algorithmes spécialisés pour les modèles factorisés).
Les modèles factorisés sont des modèles qui peuvent être décomposés en sous-modèles (appelés encodeurs ou tours). Par exemple, considérons un modèle de la forme f(u(θu, xu), v(θv, xv)), où u() encode les caractéristiques utilisateur xu (et comporte des paramètres θu), et v() encode les caractéristiques non utilisateur xv (et comporte des paramètres θv). Les deux encodages sont combinés à l'aide de f() pour produire la prédiction finale du modèle. Par exemple, dans un modèle de recommandation de films, xu correspond aux caractéristiques de l'utilisateur et xv à celles du film.
Ces modèles sont bien adaptés à l'architecture de système distribué mentionnée ci-dessus (car ils séparent les caractéristiques utilisateur et non utilisateur).
Les modèles factorisés seront entraînés à l'aide de la minimisation en alternance à confidentialité différentielle (DPAM), qui alterne entre l'optimisation des paramètres θu (tandis que θv est fixe) et inversement. Il a été démontré que les algorithmes DPAM permettent d'obtenir une meilleure utilité dans différents paramètres 4 11, en particulier en présence de fonctionnalités publiques.
Références
- 1 : Dwork et al. Calibrating Noise to Sensitivity in Private Data Analysis, TCC'06
- 2 : Bureau du recensement des États-Unis. Understanding Differential Privacy, 2020
- 3 : Federated Learning with Formal Differential Privacy Guarantees, article de blog Google AI, 2020
- 4 : Jain et al. Differentially Private Model Personalization, NeurIPS'21
- 5 : Krichene et al. Private Learning with Public Features, 2023
- 6 : Song et al. Stochastic gradient descent with differentially private updates, GlobalSIP'13
- 7 : Differentially Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds, FOCS'14
- 8 : Abadi et al. Deep Learning with Differential Privacy, CCS '16
- 9 : Smith et al. (Nearly) Optimal Algorithms for Private Online Learning in Full-information and Bandit Settings, NeurIPS'13
- 10 : Kairouz et al., Practical and Private (Deep) Learning without Sampling or Shuffling, ICML'21
- 11 : Chien et al. Private Alternating Least Squares, ICML'21