
این سند، رویکرد حریم خصوصی برای شخصیسازی روی دستگاه (ODP) را بهطور خاص در زمینه حریم خصوصی تفاضلی خلاصه میکند. سایر پیامدهای حریم خصوصی و تصمیمات طراحی مانند کمینهسازی دادهها عمداً حذف شدهاند تا این سند متمرکز باقی بماند.
حریم خصوصی دیفرانسیلی
حریم خصوصی تفاضلی ۱ یک استاندارد گسترده برای حفاظت از حریم خصوصی در تحلیل دادههای آماری و یادگیری ماشینی ۲ ۳ است. به طور غیررسمی، این استاندارد میگوید که یک دشمن تقریباً همان چیز را در مورد یک کاربر از خروجی یک الگوریتم تفاضلی خصوصی میآموزد، چه رکورد او در مجموعه دادههای اصلی ظاهر شود و چه نشود. این به معنای محافظت قوی برای افراد است: هرگونه استنتاجی که در مورد یک شخص انجام میشود، فقط میتواند به دلیل ویژگیهای کلی مجموعه دادهها باشد که با یا بدون رکورد آن شخص برقرار است.
در زمینه یادگیری ماشین، خروجی الگوریتم باید به عنوان پارامترهای مدل آموزش دیده در نظر گرفته شود. عبارت تقریباً یکسانی از نظر ریاضی با دو پارامتر (ε، δ) کمیتبندی میشود، که در آن ε معمولاً به عنوان یک ثابت کوچک انتخاب میشود و δ≪1/(تعداد کاربران).
معناشناسی حریم خصوصی
طراحی ODP به دنبال اطمینان از این است که هر اجرای آموزشی (ε,δ)-سطح کاربر به صورت تفاضلی خصوصی باشد. در ادامه، رویکرد ما برای رسیدن به این معنا تشریح شده است.
مدل تهدید
ما احزاب مختلف را تعریف میکنیم و فرضیات مربوط به هر یک را بیان میکنیم:
- کاربر: کاربری که مالک دستگاه است و مصرفکننده محصولات یا خدمات ارائه شده توسط توسعهدهنده میباشد. اطلاعات خصوصی آنها کاملاً در دسترس خودشان است.
- محیط اجرای مطمئن (TEE): دادهها و محاسبات مطمئنی که درون TEEها رخ میدهند، با استفاده از فناوریهای متنوع از مهاجمان محافظت میشوند. بنابراین، محاسبات و دادهها نیازی به حفاظت اضافی ندارند. TEEهای موجود ممکن است به مدیران پروژه خود اجازه دسترسی به اطلاعات داخل را بدهند. ما قابلیتهای سفارشی را برای عدم اجازه و تأیید عدم دسترسی مدیر پیشنهاد میکنیم.
- مهاجم: ممکن است اطلاعات جانبی در مورد کاربر داشته باشد و به هرگونه اطلاعاتی که از TEE خارج میشود (مانند پارامترهای مدل منتشر شده) دسترسی کامل دارد.
- توسعهدهنده: کسی که مدل را تعریف و آموزش میدهد. غیرقابل اعتماد در نظر گرفته میشود (و تمام تواناییهای یک مهاجم را دارد).
ما به دنبال طراحی ODP با معانی زیر از حریم خصوصی تفاضلی هستیم:
- مرز اعتماد: از دیدگاه یک کاربر، مرز اعتماد شامل دستگاه خود کاربر به همراه TEE است. هر اطلاعاتی که از این مرز اعتماد خارج میشود، باید توسط حریم خصوصی تفاضلی محافظت شود.
- مهاجم: محافظت کامل از حریم خصوصی تفاضلی در رابطه با مهاجم. هر موجودیتی خارج از مرز اعتماد میتواند یک مهاجم باشد (این شامل توسعهدهنده و سایر کاربران میشود که همگی به طور بالقوه در حال تبانی هستند). مهاجم، با توجه به تمام اطلاعات خارج از مرز اعتماد (به عنوان مثال، مدل منتشر شده)، هرگونه اطلاعات جانبی در مورد کاربر و منابع نامحدود، قادر به استنباط دادههای خصوصی اضافی در مورد کاربر (فراتر از اطلاعات موجود در اطلاعات جانبی) تا حد احتمالات داده شده توسط بودجه حریم خصوصی نیست. به طور خاص، این به معنای محافظت کامل از حریم خصوصی تفاضلی در رابطه با توسعهدهنده است. هرگونه اطلاعاتی که به توسعهدهنده منتشر میشود (مانند پارامترهای مدل آموزش دیده یا استنتاجهای کلی) محافظت شده از حریم خصوصی تفاضلی هستند.
پارامترهای مدل محلی
معنای حریم خصوصی قبلی، حالتی را در بر میگیرد که برخی از پارامترهای مدل، محلی برای دستگاه هستند (برای مثال، مدلی که شامل یک جاسازی کاربر مختص به هر کاربر است و بین کاربران مشترک نیست). برای چنین مدلهایی، این پارامترهای محلی در مرز اعتماد باقی میمانند (منتشر نمیشوند) و نیازی به محافظت ندارند، در حالی که پارامترهای مدل مشترک منتشر میشوند (و توسط حریم خصوصی تفاضلی محافظت میشوند). این گاهی اوقات به عنوان مدل حریم خصوصی بیلبورد ۴ شناخته میشود.
ویژگیهای عمومی
در برخی از برنامهها، برخی از ویژگیها عمومی هستند. برای مثال، در یک مسئله پیشنهاد فیلم، ویژگیهای یک فیلم (کارگردان، ژانر یا سال انتشار فیلم) اطلاعات عمومی هستند و نیازی به حفاظت ندارند، در حالی که ویژگیهای مربوط به کاربر (مانند اطلاعات جمعیتشناختی یا فیلمهایی که کاربر تماشا کرده است) دادههای خصوصی هستند و نیاز به حفاظت دارند.
اطلاعات عمومی به صورت یک ماتریس ویژگی عمومی (در مثال قبلی، این ماتریس شامل یک ردیف برای هر فیلم و یک ستون برای هر ویژگی فیلم است) رسمیسازی میشود که برای همه طرفین در دسترس است. الگوریتم آموزش خصوصی تفاضلی میتواند بدون نیاز به محافظت از این ماتریس، از آن استفاده کند، برای مثال به 5 مراجعه کنید. پلتفرم ODP قصد دارد چنین الگوریتمهایی را پیادهسازی کند.
رویکردی به حریم خصوصی در طول پیشبینی یا استنتاج
استنتاجها بر اساس پارامترهای مدل و ویژگیهای ورودی انجام میشوند. پارامترهای مدل با معناشناسی حریم خصوصی تفاضلی آموزش داده میشوند. در اینجا، نقش ویژگیهای ورودی مورد بحث قرار میگیرد.
در برخی موارد استفاده، زمانی که توسعهدهنده از قبل به ویژگیهای مورد استفاده در استنتاج دسترسی کامل دارد، هیچ نگرانی در مورد حریم خصوصی از استنتاج وجود ندارد و نتیجه استنتاج ممکن است برای توسعهدهنده قابل مشاهده باشد.
در موارد دیگر (زمانی که ویژگیهای استفادهشده در استنتاج خصوصی هستند و برای توسعهدهنده قابل دسترسی نیستند)، نتیجه استنتاج ممکن است از توسعهدهنده پنهان بماند، برای مثال، با اجرای استنتاج (و هر فرآیند پاییندستی که از نتیجه استنتاج استفاده میکند) روی دستگاه، در یک فرآیند و ناحیه نمایش متعلق به سیستم عامل، با ارتباطات محدود در خارج از آن فرآیند.
رویه آموزش
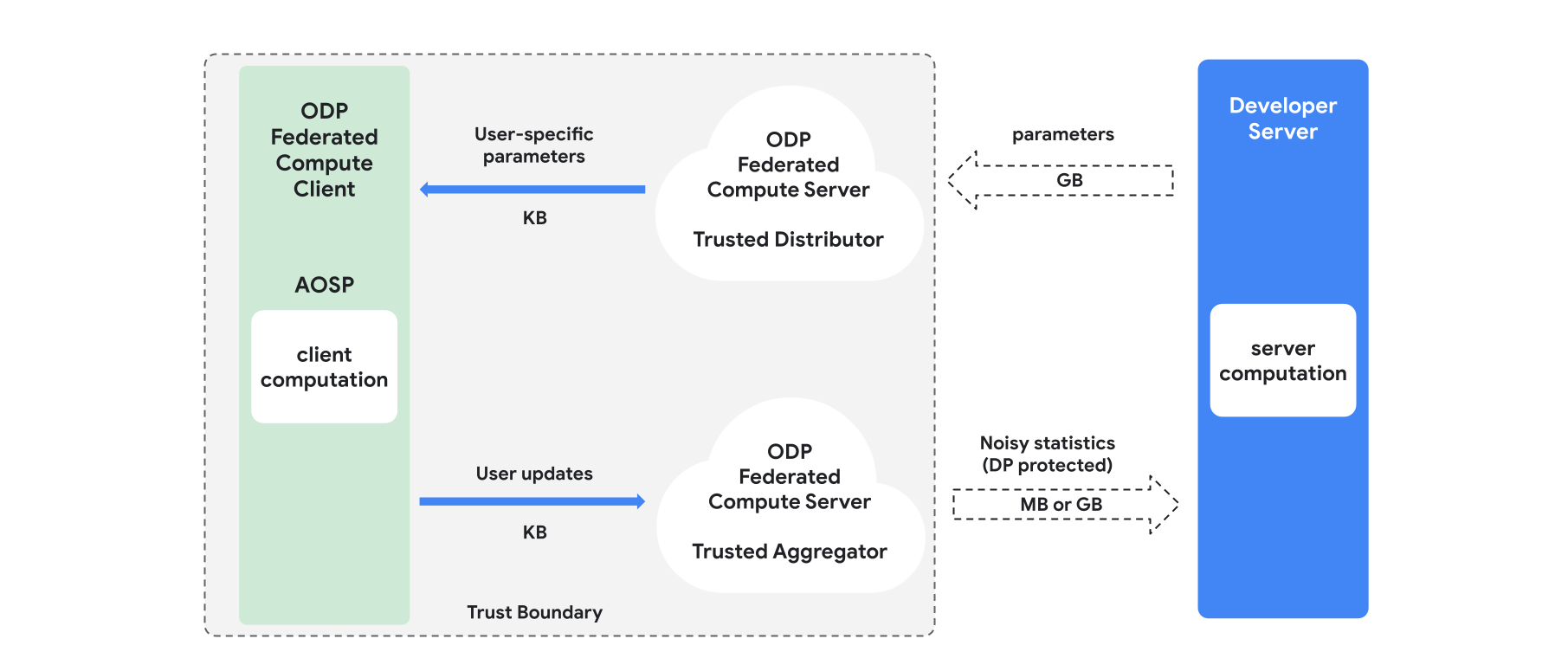
نمای کلی
این بخش، مروری بر معماری و نحوهی انجام آموزش ارائه میدهد، به شکل ۱ مراجعه کنید. ODP اجزای زیر را پیادهسازی میکند:
یک توزیعکنندهی قابل اعتماد، مانند انتخاب فدرال، دانلود قابل اعتماد یا بازیابی اطلاعات خصوصی، که نقش پخش پارامترهای مدل را ایفا میکند. فرض بر این است که توزیعکنندهی قابل اعتماد میتواند زیرمجموعهای از پارامترها را به هر کلاینت ارسال کند، بدون اینکه مشخص شود کدام پارامترها توسط کدام کلاینت دانلود شدهاند. این "پخش جزئی" به سیستم اجازه میدهد تا ردپای خود را در دستگاه کاربر نهایی به حداقل برساند: به جای ارسال یک کپی کامل از مدل، تنها کسری از پارامترهای مدل به هر کاربر مشخص ارسال میشود.
یک تجمیعکنندهی قابل اعتماد، که اطلاعات را از چندین کلاینت (مثلاً گرادیانها یا سایر آمارها) تجمیع میکند، نویز اضافه میکند و نتیجه را به سرور ارسال میکند. فرض بر این است که کانالهای قابل اعتمادی بین کلاینت و تجمیعکننده و بین کلاینت و توزیعکننده وجود دارد.
الگوریتمهای آموزش DP که روی این زیرساخت اجرا میشوند. هر الگوریتم آموزشی شامل محاسبات مختلفی است که روی اجزای مختلف (سرور، کلاینت، تجمیعکننده، توزیعکننده) اجرا میشوند.
یک دوره آموزشی معمولی شامل مراحل زیر است:
- سرور پارامترهای مدل را به توزیعکنندهی مورد اعتماد ارسال میکند.
- محاسبات کلاینت
- هر دستگاه کلاینت، مدل پخش (یا زیرمجموعهای از پارامترهای مربوط به کاربر) را دریافت میکند.
- هر کلاینت مقداری محاسبه انجام میدهد (برای مثال محاسبه گرادیان یا سایر آمارهای کافی).
- هر کلاینت نتیجه محاسبات را به تجمیعکننده مورد اعتماد ارسال میکند.
- تجمیعکنندهی مورد اعتماد، آمار را از کلاینتها جمعآوری، تجمیع و با استفاده از مکانیسمهای مناسب حریم خصوصی تفاضلی محافظت میکند، سپس نتیجه را به سرور ارسال میکند.
- محاسبات سرور
- سرور (غیرقابل اعتماد) محاسبات را روی آمارههای محافظتشده با حریم خصوصی تفاضلی اجرا میکند (برای مثال از گرادیانهای تجمیعشده با حریم خصوصی تفاضلی برای بهروزرسانی پارامترهای مدل استفاده میکند).
مدلهای فاکتورگیری شده و کمینهسازی متناوب خصوصی تفاضلی
پلتفرم ODP قصد دارد الگوریتمهای آموزش خصوصی تفاضلی همهمنظوره را ارائه دهد که میتوانند برای هر معماری مدلی (مانند DP-SGD 6 7 8 یا DP-FTRL 9 10 ) و همچنین الگوریتمهای مخصوص مدلهای فاکتورگیری شده اعمال شوند.
مدلهای فاکتورگیری شده، مدلهایی هستند که میتوانند به زیرمدلها (به نام رمزگذار یا برج) تجزیه شوند. به عنوان مثال، مدلی به شکل f(u(θu, xu), v(θv, xv)) را در نظر بگیرید، که در آن u() ویژگیهای کاربر xu را کدگذاری میکند (و پارامترهای θu را دارد)، و v() ویژگیهای غیرکاربر xv را کدگذاری میکند (و پارامترهای θv را دارد). این دو کدگذاری با استفاده از f() ترکیب میشوند تا پیشبینی نهایی مدل را تولید کنند. به عنوان مثال، در یک مدل توصیه فیلم، xu ویژگیهای کاربر و xv ویژگیهای فیلم هستند.
چنین مدلهایی برای معماری سیستم توزیعشدهی مذکور بسیار مناسب هستند (زیرا ویژگیهای کاربر و غیرکاربر را از هم جدا میکنند).
مدلهای فاکتورگیری شده با استفاده از کمینهسازی متناوب خصوصی تفاضلی (DPAM) آموزش داده خواهند شد، که بین بهینهسازی پارامترهای θu (در حالی که θv ثابت است) و برعکس، متناوباً تغییر میکند. نشان داده شده است که الگوریتمهای DPAM در تنظیمات مختلف 411 ، به ویژه در حضور ویژگیهای عمومی ، به کاربرد بهتری دست مییابند.
منابع
- ۱ : دورک و همکاران. کالیبراسیون نویز نسبت به حساسیت در تحلیل دادههای خصوصی، TCC'06
- ۲ : اداره سرشماری ایالات متحده. درک حریم خصوصی تفاضلی، ۲۰۲۰
- ۳ : یادگیری فدرال با ضمانتهای رسمی افتراقی حریم خصوصی، پست وبلاگ گوگل هوش مصنوعی، ۲۰۲۰
- ۴ : جین و همکاران. شخصیسازی مدل با حریم خصوصی متفاوت، NeurIPS'21
- 5 : کریچن و همکاران. آموزش خصوصی با ویژگی های عمومی، 2023
- ۶ : سانگ و همکاران. گرادیان نزولی تصادفی با بهروزرسانیهای خصوصی تفاضلی، GlobalSIP'13
- ۷ : کمینهسازی ریسک تجربی با رویکرد خصوصیسازی تفاضلی: الگوریتمهای کارآمد و کرانهای خطای دقیق، FOCS'14
- ۸ : آبادی و همکاران. یادگیری عمیق با حریم خصوصی تفاضلی، CCS '16
- 9 : اسمیت و همکاران. الگوریتمهای (تقریباً) بهینه برای آموزش آنلاین خصوصی در تنظیمات اطلاعات کامل و راهزن، NeurIPS'13
- ۱۰ : کایروز و همکاران، یادگیری عملی و خصوصی (عمیق) بدون نمونهگیری یا درهمآمیختگی، ICML'21
- 11 : چین و همکاران. حداقل مربعات متناوب خصوصی، ICML'21