
In diesem Dokument wird der Ansatz zum Datenschutz für die Personalisierung auf dem Gerät (On-Device Personalization, ODP) speziell im Kontext des differenziellen Datenschutzes zusammengefasst. Andere Auswirkungen auf den Datenschutz und Designentscheidungen wie die Datenminimierung werden bewusst ausgelassen, um den Fokus dieses Dokuments beizubehalten.
Differential Privacy
Die differentielle Vertraulichkeit 1 ist ein weit verbreiteter Standard für den Datenschutz in der statistischen Datenanalyse und im maschinellen Lernen 2 3. Vereinfacht gesagt bedeutet das, dass ein Angreifer fast dasselbe über einen Nutzer aus der Ausgabe eines differenziell datenschutzfreundlichen Algorithmus erfährt, unabhängig davon, ob sein Datensatz im zugrunde liegenden Datensatz enthalten ist oder nicht. Das bedeutet einen starken Schutz für Einzelpersonen: Alle Rückschlüsse, die über eine Person gezogen werden, können nur auf aggregierte Eigenschaften des Datensatzes zurückgeführt werden, die mit oder ohne den Datensatz dieser Person gelten würden.
Im Kontext des maschinellen Lernens sollte die Ausgabe des Algorithmus als die trainierten Modellparameter betrachtet werden. Der Ausdruck fast dasselbe wird mathematisch durch zwei Parameter (ε, δ) quantifiziert, wobei ε in der Regel als kleine Konstante und δ≪1/(Anzahl der Nutzer) gewählt wird.
Datenschutzsemantik
Das ODP-Design soll sicherstellen, dass jeder Trainingslauf auf Nutzerebene (ε,δ)-differenziell privat ist. Im Folgenden wird beschrieben, wie wir diese Semantik erreichen.
Bedrohungsmodell
Wir definieren die verschiedenen Parteien und geben Annahmen zu jeder an:
- Nutzer:Der Nutzer, dem das Gerät gehört und der Produkte oder Dienste des Entwicklers nutzt. Ihre privaten Informationen sind für sie vollständig verfügbar.
- Vertrauenswürdige Ausführungsumgebung (Trusted Execution Environment, TEE): Daten und vertrauenswürdige Berechnungen, die in TEEs stattfinden, sind durch eine Vielzahl von Technologien vor Angreifern geschützt. Daher sind für die Berechnung und die Daten keine zusätzlichen Schutzmaßnahmen erforderlich. Bei vorhandenen TEEs können Projektadministratoren möglicherweise auf die darin enthaltenen Informationen zugreifen. Wir schlagen benutzerdefinierte Funktionen vor, um den Zugriff für einen Administrator zu unterbinden und zu prüfen, ob er nicht verfügbar ist.
- Der Angreifer hat möglicherweise zusätzliche Informationen über den Nutzer und vollen Zugriff auf alle Informationen, die das TEE verlassen (z. B. die veröffentlichten Modellparameter).
- Entwickler:Eine Person, die das Modell definiert und trainiert. Als nicht vertrauenswürdig eingestuft (und hat die vollen Möglichkeiten eines Angreifers).
Wir möchten ODP mit den folgenden Semantiken der differenziellen Vertraulichkeit entwickeln:
- Vertrauensgrenze:Aus der Sicht eines Nutzers besteht die Vertrauensgrenze aus dem Gerät des Nutzers und der TEE. Alle Informationen, die diese Vertrauensgrenze verlassen, sollten durch Differential Privacy geschützt werden.
- Angreifer:Vollständiger Schutz durch Differential Privacy in Bezug auf den Angreifer. Jede Einheit außerhalb der Vertrauensgrenze kann ein Angreifer sein. Das schließt den Entwickler und andere Nutzer ein, die möglicherweise zusammenarbeiten. Der Angreifer kann mit allen Informationen außerhalb der Vertrauensgrenze (z. B. dem veröffentlichten Modell), allen Nebeninformationen über den Nutzer und unendlichen Ressourcen keine zusätzlichen privaten Daten über den Nutzer ableiten, die über die bereits in den Nebeninformationen enthaltenen Daten hinausgehen, bis hin zu den durch das Datenschutzbudget vorgegebenen Wahrscheinlichkeiten. Das bedeutet insbesondere einen vollständigen Schutz der Differenziellen Vertraulichkeit in Bezug auf den Entwickler. Alle Informationen, die an den Entwickler weitergegeben werden (z. B. Parameter des trainierten Modells oder aggregierte Schlussfolgerungen), sind durch Differential Privacy geschützt.
Parameter für lokales Modell
Die bisherige Datenschutzsemantik berücksichtigt den Fall, in dem einige der Modellparameter lokal auf dem Gerät sind, z. B. ein Modell, das eine nutzerspezifische Einbettung für jeden Nutzer enthält, die nicht für alle Nutzer freigegeben ist. Bei solchen Modellen bleiben diese lokalen Parameter innerhalb der Vertrauensgrenze (sie werden nicht veröffentlicht) und müssen nicht geschützt werden, während freigegebene Modellparameter veröffentlicht werden (und durch differenzielle Datenschutzmaßnahmen geschützt sind). Dies wird manchmal als Billboard-Datenschutzmodell 4 bezeichnet.
Öffentliche Funktionen
In bestimmten Anwendungen sind einige Funktionen öffentlich. Bei einem Problem mit Filmempfehlungen sind die Merkmale eines Films (Regisseur, Genre oder Erscheinungsjahr des Films) beispielsweise öffentliche Informationen, die keinen Schutz erfordern. Merkmale, die sich auf den Nutzer beziehen (z. B. demografische Informationen oder welche Filme der Nutzer gesehen hat), sind hingegen private Daten, die geschützt werden müssen.
Die öffentlichen Informationen werden als öffentliche Feature-Matrix formalisiert. Im vorherigen Beispiel würde diese Matrix eine Zeile pro Film und eine Spalte pro Film-Feature enthalten. Sie ist für alle Parteien verfügbar. Der differenziell private Trainingsalgorithmus kann diese Matrix verwenden, ohne dass sie geschützt werden muss (siehe z. B. 5). Die ODP-Plattform plant, solche Algorithmen zu implementieren.
Datenschutz bei Vorhersagen oder Inferenz
Die Inferenz basiert auf den Modellparametern und Eingabe-Features. Die Modellparameter werden mit Differential Privacy-Semantik trainiert. Hier wird die Rolle von Eingabefeatures erläutert.
In einigen Anwendungsfällen, in denen der Entwickler bereits vollen Zugriff auf die für die Inferenz verwendeten Funktionen hat, besteht kein Datenschutzrisiko durch die Inferenz und das Inferenzresultat ist möglicherweise für den Entwickler sichtbar.
In anderen Fällen (wenn für die Inferenz verwendete Funktionen privat und für den Entwickler nicht zugänglich sind) kann das Inferenz-Ergebnis für den Entwickler verborgen werden. Dies kann beispielsweise dadurch geschehen, dass die Inferenz (und alle nachgelagerten Prozesse, die das Inferenz-Ergebnis verwenden) auf dem Gerät in einem vom Betriebssystem verwalteten Prozess und Anzeigebereich mit eingeschränkter Kommunikation außerhalb dieses Prozesses ausgeführt werden.
Trainingsablauf
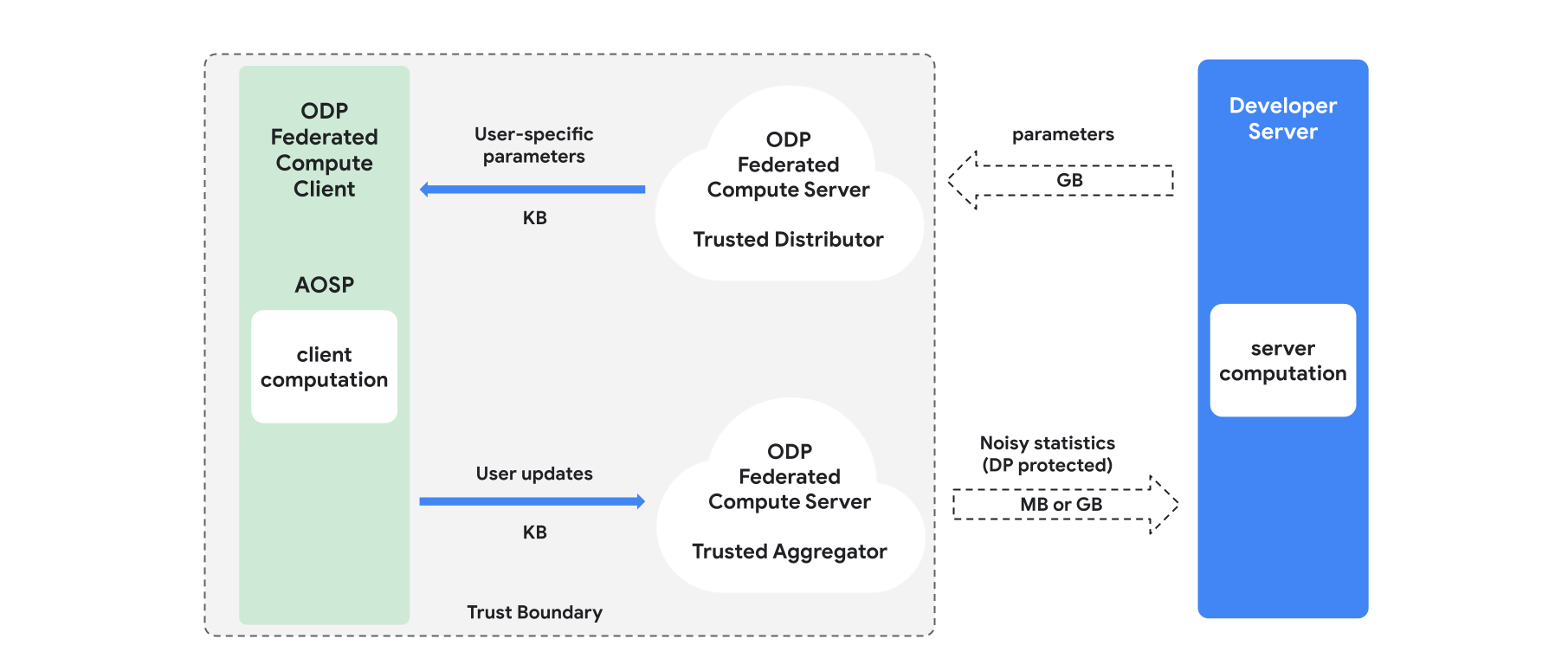
Übersicht
In diesem Abschnitt finden Sie einen Überblick über die Architektur und den Trainingsprozess (siehe Abbildung 1). ODP implementiert die folgenden Komponenten:
Ein vertrauenswürdiger Distributor, z. B. Federated Select, Trusted Download oder Private Information Retrieval, der die Rolle des Broadcastings von Modellparametern übernimmt. Es wird davon ausgegangen, dass der vertrauenswürdige Distributor eine Teilmenge von Parametern an jeden Client senden kann, ohne preiszugeben, welche Parameter von welchem Client heruntergeladen wurden. Durch diese „teilweise Übertragung“ kann das System die Belastung des Endnutzergeräts minimieren: Anstatt eine vollständige Kopie des Modells zu senden, wird nur ein Teil der Modellparameter an einen bestimmten Nutzer gesendet.
Ein vertrauenswürdiger Aggregator, der Informationen von mehreren Clients (z.B. Gradienten oder andere Statistiken) zusammenfasst, Rauschen hinzufügt und das Ergebnis an den Server sendet. Es wird davon ausgegangen, dass es vertrauenswürdige Kanäle zwischen dem Client und dem Aggregator sowie zwischen dem Client und dem Distributor gibt.
DP-Trainingsalgorithmen, die in dieser Infrastruktur ausgeführt werden. Jeder Trainingsalgorithmus besteht aus verschiedenen Berechnungen, die auf den verschiedenen Komponenten (Server, Client, Aggregator, Distributor) ausgeführt werden.
Eine typische Trainingsrunde besteht aus den folgenden Schritten:
- Der Server überträgt Modellparameter an den vertrauenswürdigen Distributor.
- Clientseitige Berechnung
- Jedes Clientgerät erhält das Broadcast-Modell (oder die für den Nutzer relevanten Parameter).
- Jeder Client führt eine Berechnung durch, z. B. die Berechnung von Gradienten oder anderen ausreichenden Statistiken.
- Jeder Client sendet das Ergebnis der Berechnung an den vertrauenswürdigen Aggregator.
- Der vertrauenswürdige Aggregator erfasst und aggregiert Statistiken von Clients und schützt sie mithilfe geeigneter Mechanismen für differenziellen Datenschutz. Anschließend sendet er das Ergebnis an den Server.
- Serverberechnung
- Der (nicht vertrauenswürdige) Server führt Berechnungen für die differenziell datenschutzgeschützten Statistiken aus (z. B. werden differenziell datenschutzgeschützte aggregierte Gradienten verwendet, um die Modellparameter zu aktualisieren).
Faktorisierte Modelle und differenziell privater alternierender Minimierung
Die ODP-Plattform plant, allgemeine differenziell private Trainingsalgorithmen bereitzustellen, die auf jede Modellarchitektur angewendet werden können, z. B. DP-SGD 6 7 8 oder DP-FTRL 9 10 sowie Algorithmen, die auf faktorisierte Modelle spezialisiert sind.
Faktorisierte Modelle sind Modelle, die in Untermodelle (Encoder oder Towers genannt) zerlegt werden können. Angenommen, Sie haben ein Modell der Form f(u(θu, xu), v(θv, xv)), wobei u() Nutzer-Features xu (mit Parametern θu) und v() Nicht-Nutzer-Features xv (mit Parametern θv) codiert. Die beiden Codierungen werden mit f() kombiniert, um die endgültige Modellvorhersage zu erstellen. In einem Filmempfehlungsmodell sind xu beispielsweise die Nutzer-Features und xv die Film-Features.
Solche Modelle eignen sich gut für die oben erwähnte Architektur des verteilten Systems, da sie die Nutzer- und Nichtnutzer-Funktionen trennen.
Faktorisierte Modelle werden mit Differentially Private Alternating Minimization (DPAM) trainiert. Dabei wird abwechselnd zwischen der Optimierung der Parameter θu (während θv fixiert ist) und umgekehrt gewechselt. DPAM-Algorithmen haben sich in verschiedenen Situationen als nützlicher erwiesen 4 11, insbesondere bei öffentlichen Funktionen.
Verweise
- 1: Dwork et al. Calibrating Noise to Sensitivity in Private Data Analysis, TCC'06
- 2: US Census Bureau. Differential Privacy verstehen, 2020
- 3: Federated Learning with Formal Differential Privacy Guarantees, Google AI Blogpost, 2020
- 4: Jain et al. Differentially Private Model Personalization, NeurIPS'21
- 5: Krichene et al. Private Learning with Public Features, 2023
- 6: Song et al. Stochastic gradient descent with differentially private updates, GlobalSIP'13
- 7: Differentially Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds, FOCS'14
- 8: Abadi et al. Deep Learning with Differential Privacy, CCS '16
- 9: Smith et al. (Nearly) Optimal Algorithms for Private Online Learning in Full-information and Bandit Settings, NeurIPS'13
- 10: Kairouz et al., Practical and Private (Deep) Learning without Sampling or Shuffling, ICML'21
- 11: Chien et al. Private Alternating Least Squares, ICML'21