
На этой странице описано, как работать с API федеративного обучения, предоставляемыми функцией персонализации на устройстве, для обучения модели с использованием процесса федеративного усреднения и фиксированного гауссовского шума .
Прежде чем начать
Прежде чем начать, выполните следующие действия на вашем тестовом устройстве:
Убедитесь, что модуль OnDevicePersonalization установлен. Этот модуль стал доступен в качестве автоматического обновления в апреле 2024 года.
# List the modules installed on the device adb shell pm list packages --apex-only --show-versioncodeУбедитесь, что следующий модуль указан с кодом версии 341717000 или выше:
package:com.google.android.ondevicepersonalization versionCode:341717000Если этот модуль отсутствует в списке, перейдите в Настройки > Безопасность и конфиденциальность > Обновления > Обновление системы Google Play, чтобы убедиться, что ваше устройство обновлено. При необходимости выберите «Обновить» .
Включите все новые функции, связанные с федеративным обучением.
# Enable On-Device Personalization apk. adb shell device_config put on_device_personalization global_kill_switch false # Enable On-Device Personalization APIs. adb shell device_config put on_device_personalization enable_ondevicepersonalization_apis true # Enable On-Device Personalization overriding. adb shell device_config put on_device_personalization enable_personalization_status_override true adb shell device_config put on_device_personalization personalization_status_override_value true # Enable Federated Compute apk. adb shell device_config put on_device_personalization federated_compute_kill_switch false
Создайте задачу федеративного обучения.

Числа на диаграмме более подробно объясняются в следующих восьми шагах.
Настройка федеративного вычислительного сервера
Федеративное обучение — это алгоритм map-reduce, работающий на федеративном вычислительном сервере (редукторе) и наборе клиентов (мэпперах). Федеративный вычислительный сервер поддерживает метаданные и информацию о модели каждой задачи федеративного обучения. В общих чертах:
- Разработчик, использующий технологию федеративного обучения, создает новое задание и загружает на сервер как метаданные о ходе выполнения задания, так и информацию о модели.
- Когда клиент Federated Compute инициирует запрос на назначение новой задачи серверу, сервер проверяет соответствие задачи требованиям и возвращает информацию о подходящей задаче.
- После завершения локальных вычислений клиент федеративных вычислений отправляет результаты этих вычислений на сервер. Затем сервер выполняет агрегацию и шумоподавление этих результатов и применяет их к итоговой модели.
Чтобы узнать больше об этих понятиях, ознакомьтесь со следующей информацией:
- Федеративное обучение: совместное машинное обучение без централизованных обучающих данных.
- На пути к масштабируемому федеративному обучению: проектирование системы (SysML 2019)
ODP использует улучшенную версию федеративного обучения, в которой калиброванный (централизованный) шум применяется к агрегатам перед применением к модели. Масштаб шума гарантирует, что агрегаты сохранят дифференциальную конфиденциальность.
Шаг 1. Создайте федеративный вычислительный сервер.
Следуйте инструкциям в проекте Federated Compute, чтобы настроить собственный сервер федеративных вычислений.
Шаг 2. Подготовка сохраненной функциональной модели.
Подготовьте сохраненный файл «FunctionalModel» . Вы можете использовать функцию «functional_model_from_keras» для преобразования «Model» в «FunctionalModel» , а функцию «save_functional_model» — для сериализации этого файла «FunctionalModel» в файл «SavedModel» .
functional_model = tff.learning.models.functional_model_from_keras(keras_model=model)
tff.learning.models.save_functional_model(functional_model, saved_model_path)
Шаг 3. Создайте конфигурацию федеративного вычислительного сервера.
Подготовьте файл fcp_server_config.json , который будет содержать политики, настройки федеративного обучения и настройки дифференциальной конфиденциальности. Пример:
# Identifies the set of client devices that will participate.
population_name: "my_new_population"
# Options you can choose:
# * TRAINING_ONLY: Only one training task will be generated under this
# population.
# * TRAINING_AND_EVAL: One training task and one evaluation task will be
# generated under this population.
# * EVAL_ONLY: Only one evaluation task will be generated under this
# population.
mode: TRAINING_AND_EVAL
policies {
# Policy for sampling on-device examples. It is checked every time a
# device attempts to start a new training.
min_separation_policy {
# The minimum number of rounds before the same client participated.
minimum_separation: 3
}
# Policy for releasing training results to developers. It is checked
# when uploading a new task to the Federated Compute Server.
model_release_policy {
# Server stops training when number of training rounds reaches this
# number.
num_max_training_rounds: 1000
}
}
# Federated learning setups. They are applied inside Task Builder.
federated_learning {
learning_process {
# Use FED_AVG to build federated learning process. Options you can
# choose:
# * FED_AVG: Federated Averaging algorithm
# (https://arxiv.org/abs/2003.00295)
# * FED_SDG: Federated SGD algorithm
# (https://arxiv.org/abs/1602.05629)
type: FED_AVG
# Optimizer used at client side training. Options you can choose:
# * ADAM
# * SGD
client_optimizer: SGD
# Learning rate used at client side training.
client_learning_rate: 0.01
# Optimizer used at server side training. Options you can choose:
# * ADAM
# * SGD
server_optimizer: ADAM
# Learning rate used at server side training.
sever_learning_rate: 1
runtime_config {
# Number of participating devices for each round of training.
report_goal: 2000
}
# List of metrics to be evaluated by the model during training and
# evaluation. Federated Compute Server provides a list of allowed
# metrics.
metrics {
name: "auc-roc"
}
metrics {
name: "binary_accuracy"
}
}
# Whether or not to generate a corresponding evaluation task under the same
# population. If this field isn't set, only one training task is
# generated under this population.
evaluation {
# The task id under the same population of the source training task that
# this evaluation task evaluates.
source_training_task_id: 1
# Decides how checkpoints from the training task are chosen for
# evaluation.
# * every_k_round: the evaluation task randomly picks one checkpoint
# from the past k rounds of training task checkpoints.
# * every_k_hour: the evaluation task randomly picks one checkpoint
# from the past k hours of training task checkpoints.
checkpoint_selector: "every_1_round"
# The traffic of this evaluation task in this population.
evaluation_traffic: 0.1
# Number of participating devices for each round of evaluation.
report_goal: 200
}
}
# Differential Privacy setups. They are applied inside the Task Builder.
differential_privacy {
# The DP aggregation algorithm you want to use. Options you can choose:
# * FIXED_GAUSSIAN: Federated Learning DP-SGD with fixed clipping norm
# described in "Learning Differentially Private Recurrent
# Language Models" (https://arxiv.org/abs/1710.06963).
# * ADAPTIVE_GAUSSIAN: Federated Learning DP-SGD with quantile-based clip
# norm estimation described in "Differentially Private
# Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
# * TREE: DP-FTRL algorithm described in "Practical and Private (Deep)
# Learning without Sampling or Shuffling"
# (https://arxiv.org/abs/2103.00039).
# * ADADPTIVE_TREE: DP-FTRL with adaptive clipping norm descirbed in
# "Differentially Private Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
type: FIXED_GAUSSIAN
# Noise multiplier for the Gaussian noise.
noise_multiplier: 0.1
# The value of the clipping norm.
clip_norm: 0.1
}
Шаг 4. Отправьте конфигурацию в формате ZIP на сервер федеративных вычислений.
Отправьте zip-файл и файл fcp_server_config.json на сервер федеративных вычислений.
task_builder_client --task_builder_server='http://{federated_compute_server_endpoint}' --saved_model='saved_model' --task_config='fcp_server_config.json'
Конечная точка Federated Compute Server — это сервер, который вы настроили на шаге 1.
Встроенная библиотека операторов LiteRT поддерживает лишь ограниченное количество операторов TensorFlow (Select TensorFlow operators). Поддерживаемый набор операторов может различаться в разных версиях модуля OnDevicePersonalization. Для обеспечения совместимости в процессе создания задачи в конструкторе задач выполняется проверка операторов.
Минимальная поддерживаемая версия модуля OnDevicePersonalization будет указана в метаданных задачи. Эту информацию можно найти в информационном сообщении конструктора задач.
I1023 22:16:53.058027 139653371516736 task_builder_client.py:109] Success! Tasks are built, and artifacts are uploaded to the cloud. I1023 22:16:53.058399 139653371516736 task_builder_client.py:112] applied_algorithms { learning_algo: FED_AVG client_optimizer: SGD server_optimizer: SGD dp_aggregator: FIXED_GAUSSIAN } metric_results { accepted_metrics: "binary_accuracy, binary_crossentropy, recall, precision, auc-roc, auc-pr" } dp_hyperparameters { dp_delta: 0.000001 dp_epsilon: 6.4 noise_multiplier: 1.0 dp_clip_norm: 1.0 num_training_rounds: 10000 } I1023 22:16:53.058594 139653371516736 task_builder_client.py:113] training_task { min_client_version: "341912000" } eval_task { min_client_version: "341812000" }Сервер Federated Compute назначит эту задачу всем устройствам, оснащенным модулем OnDevicePersonalization версии выше 341812000.
Если ваша модель включает операции, не поддерживаемые ни одним из модулей OnDevicePersonalization, при создании задачи будет сгенерировано сообщение об ошибке.
common.TaskBuilderException: Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {'L2Loss': 'L2LossOp<CPUDevice, float>'} . Stop building remaining artifacts.Подробный список поддерживаемых гибких операций можно найти на GitHub .
Создание APK-файла для федеративных вычислений Android
Для создания APK-файла для федеративных вычислений Android необходимо указать URL-адрес сервера федеративных вычислений в файле AndroidManifest.xml , к которому подключается ваш клиент федеративных вычислений.
Шаг 5. Укажите URL-адрес конечной точки федеративного вычислительного сервера.
Укажите в файле AndroidManifest.xml конечную точку URL-адреса федеративного вычислительного сервера (которую вы настроили на шаге 1), к которой будет подключаться ваш клиент федеративных вычислений.
<!-- Contents of AndroidManifest.xml -->
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.odpsample" >
<application android:label="OdpSample">
<!-- XML resource that contains other ODP settings. -->
<property android:name="android.ondevicepersonalization.ON_DEVICE_PERSONALIZATION_CONFIG"
android:resource="@xml/OdpSettings"></property>
<!-- The service that ODP will bind to. -->
<service android:name="com.example.odpsample.SampleService"
android:exported="true" android:isolatedProcess="true" />
</application>
</manifest>
В XML-файле ресурсов, указанном в теге <property> , также должен быть объявлен класс службы в теге <service> и указан URL-адрес конечной точки федеративного вычислительного сервера, к которому будет подключаться клиент федеративных вычислений:
<!-- Contents of res/xml/OdpSettings.xml -->
<on-device-personalization>
<!-- Name of the service subclass -->
<service name="com.example.odpsample.SampleService">
<!-- If you want to use federated compute feature to train a model,
specify this tag. -->
<federated-compute-settings url="https://fcpserver.com/" />
</service>
</on-device-personalization>
Шаг 6. Реализуйте API IsolatedWorker#onTrainingExample
Реализуйте публичный API персонализации на устройстве IsolatedWorker#onTrainingExample для генерации обучающих данных.
Код, выполняющийся в IsolatedProcess , не имеет прямого доступа к сети, локальным дискам или другим службам, работающим на устройстве; однако доступны следующие API:
- 'getRemoteData' — неизменяемые данные типа ключ-значение, загружаемые с удаленных серверных частей, управляемых разработчиком, если таковые имеются.
- 'getLocalData' — Изменяемые данные в формате ключ-значение, сохраняемые разработчиками локально, если применимо.
- «UserData» — пользовательские данные, предоставляемые платформой.
- 'getLogReader' — возвращает объект DAO для таблиц REQUESTS и EVENTS.
Пример:
@Override public void onTrainingExample(
@NonNull TrainingExampleInput input,
@NonNull Consumer<TrainingExampleOutput> consumer) {
// Check if the incoming training task is the task we want.
if (input.getPopulationName() == "my_new_population") {
TrainingExampleOutput result = new TrainingExampleOutput.Builder():
RequestLogRecord record = this.getLogReader().getRequestLogRecord(1);
int count = 1;
// Iterate logging event table.
for (ContentValues contentValues: record.rows()) {
Features features = Features.newBuilder()
// Retrieve carrier from user info.
.putFeature("carrier", buildFeature(mUserData.getCarrier()))
// Retrieve features from logging info.
.putFeature("int_feature_1",
buildFeature(contentValues.get("int_feature_1")
result.addTrainingExample(
Example.newBuilder()
.setFeatures(features).build().toByteArray())
.addResumptionToken(
String.format("token%d", count).getBytes()))
.build();
count++;
}
consumer.accept(result.build());
}
}
Шаг 7. Запланируйте повторяющееся задание по обучению.
Функция персонализации на устройстве предоставляет разработчикам FederatedComputeScheduler для планирования или отмены задач федеративных вычислений. Существуют различные варианты вызова через IsolatedWorker : по расписанию или после завершения асинхронной загрузки. Примеры обоих вариантов приведены ниже.
Опция, основанная на расписании. Вызовите
FederatedComputeScheduler#scheduleвIsolatedWorker#onExecute.@Override public void onExecute( @NonNull ExecuteInput input, @NonNull Consumer<ExecuteOutput> consumer ) { if (input != null && input.getAppParams() != null && input.getAppParams().getString("schedule_training") != null) { if (input.getAppParams().getString("schedule_training").isEmpty()) { consumer.accept(null); return; } TrainingInterval interval = new TrainingInterval.Builder() .setMinimumInterval(Duration.ofSeconds(10)) .setSchedulingMode(2) .build(); FederatedComputeScheduler.Params params = new FederatedComputeScheduler .Params(interval); FederatedComputeInput fcInput = new FederatedComputeInput.Builder() .setPopulationName( input.getAppParams().getString("schedule_training")).build(); mFCScheduler.schedule(params, fcInput); ExecuteOutput result = new ExecuteOutput.Builder().build(); consumer.accept(result); } }Опция "Загрузка завершена". Вызовите
FederatedComputeScheduler#scheduleвIsolatedWorker#onDownloadCompletedесли планирование задачи обучения зависит от каких-либо асинхронных данных или процессов.
Проверка
Следующие шаги описывают, как проверить правильность выполнения задачи федеративного обучения.
Шаг 8. Проверьте, правильно ли выполняется задача федеративного обучения.
На каждом этапе агрегации на стороне сервера генерируется новая контрольная точка модели и новый файл метрик.
Метрики хранятся в JSON-файле, содержащем пары ключ-значение. Файл генерируется на основе списка Metrics определенных вами на шаге 3. Пример типичного JSON-файла с метриками выглядит следующим образом:
{"server/client_work/train/binary_accuracy":0.5384615659713745, "server/client_work/train/binary_crossentropy":0.694046676158905, "server/client_work/train/recall":0.20000000298023224, "server/client_work/train/precision":0.3333333432674408, "server/client_work/train/auc-roc":0.3500000238418579, "server/client_work/train/auc-pr":0.44386863708496094, "server/finalizer/update_non_finite":0.0}
Для получения метрик модели и мониторинга производительности обучения можно использовать скрипт, аналогичный приведенному ниже:
import collections
import json
import matplotlib.pyplot as plt
from google.cloud import storage
# The population_name you set in fcp_server_config.json in Step 3.
POPULATION_NAME = 'my_new_population'
# The Google Cloud storage you set in Step 1.
GCS_BUCKET_NAME = 'fcp-gcs'
NUM_TRAINING_ROUND = 1000
storage_client = storage.Client()
bucket = storage_client.bucket(GCS_BUCKET_NAME)
metrics = collections.defaultdict(list)
for i in range(NUM_TRAINING_ROUND):
blob = bucket.blob('{}/{}/1/{}/s/0/metrics'.format(GCS_BUCKET_NAME, POPULATION_NAME, i+1))
with blob.open("r") as f:
metric = json.loads(f.read())
for metric_name in metric.keys():
metrics[metric_name].append(metric[metric_name])
for metric_name in metrics:
print(metric_name)
plt.plot(metrics[metric_name])
plt.show()
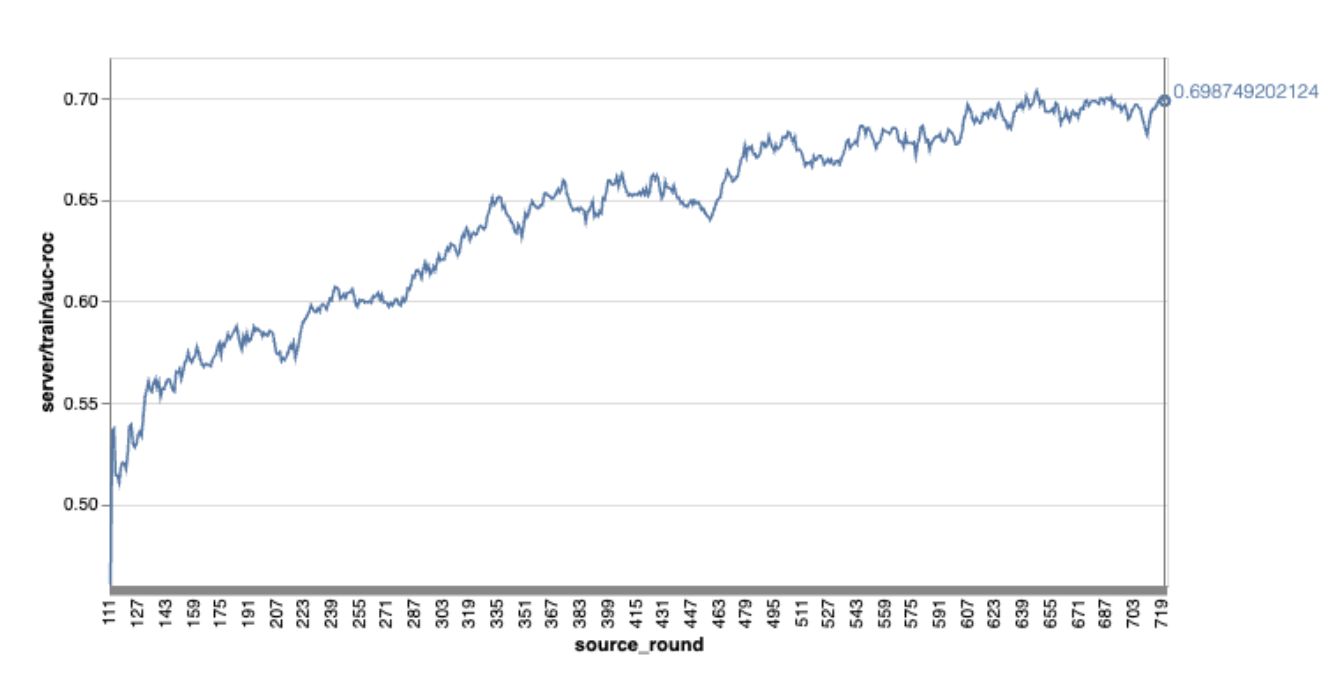
Обратите внимание, что на приведенном выше примере графика:
- По оси X отложено количество раундов тренировки.
- По оси Y отложено значение auc-roc для каждого раунда.
Обучение модели классификации изображений с учетом персонализации на устройстве.
В этом руководстве набор данных EMNIST используется для демонстрации того, как запустить задачу федеративного обучения на наборе данных ODP.
Шаг 1. Создайте объект tff.learning.models.FunctionalModel.
def get_image_classification_input_spec():
return (
tf.TensorSpec([None, 28, 28, 1], tf.float32),
tf.TensorSpec([None, 1], tf.int64),
)
def create_and_save_image_classification_functional_model(
model_path: str,
) -> None:
keras_model = emnist_models.create_original_fedavg_cnn_model(
only_digits=True
)
functional_model = tff.learning.models.functional_model_from_keras(
keras_model=keras_model,
input_spec=get_image_classification_input_spec(),
loss_fn=tf.keras.losses.SparseCategoricalCrossentropy(),
)
tff.learning.models.save_functional_model(functional_model, model_path)
- Подробную информацию о модели emnist keras можно найти в файле emnist_models .
- В TfLite пока отсутствует хорошая поддержка tf.sparse.SparseTensor и tf.RaggedTensor . Старайтесь как можно чаще использовать tf.Tensor при построении модели.
- При построении процесса обучения конструктор задач ODP перезапишет все метрики, указывать какие-либо метрики дополнительно не требуется. Эта тема будет более подробно рассмотрена на шаге 2. Создайте конфигурацию конструктора задач .
Поддерживаются два типа входных данных для модели:
Тип 1. Кортеж (features_tensor, label_tensor).
- При создании модели параметр input_spec выглядит следующим образом:
def get_input_spec(): return ( tf.TensorSpec([None, 28, 28, 1], tf.float32), tf.TensorSpec([None, 1], tf.int64), )- Для генерации обучающих данных на устройстве совместите описанный выше код со следующей реализацией публичного API ODP IsolatedWorker#onTrainingExamples :
return tf.train.Example( features=tf.train.Features( feature={ 'x': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0] * 784) ), 'y': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()Тип 2.
Tuple(Dict[feature_name, feature_tensor], label_tensor)- При создании модели параметр input_spec выглядит следующим образом:
def get_input_spec() -> ( Tuple[collections.OrderedDict[str, tf.TensorSpec], tf.TensorSpec] ): return ( collections.OrderedDict( [('feature-1', tf.TensorSpec([None, 1], tf.float32)), ('feature-2', tf.TensorSpec([None, 1], tf.float32))] ), tf.TensorSpec([None, 1], tf.int64), )- Для генерации обучающих данных совместите описанный выше код со следующей реализацией публичного API ODP IsolatedWorker#onTrainingExamples :
return tf.train.Example( features=tf.train.Features( feature={ 'feature-1': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0]) ), 'feature-2': tf.train.Feature( float_list=tf.train.FloatList(value=[2.0]) ), 'my_label': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()- Не забудьте зарегистрировать label_name в конфигурации построителя задач.
mode: TRAINING_AND_EVAL # Task execution mode population_name: "my_example_model" label_name: "my_label"
ODP автоматически обрабатывает динамический программный код при построении процесса обучения. Поэтому нет необходимости добавлять какой-либо шум при создании функциональной модели.
Результат работы сохранённой функциональной модели должен выглядеть так же, как в примере в нашем репозитории GitHub.
Шаг 2. Создайте конфигурацию конструктора задач.
Примеры конфигурации конструктора задач можно найти в нашем репозитории на GitHub.
Показатели обучения и оценки
Учитывая, что метрики могут приводить к утечке пользовательских данных, в Task Builder будет список метрик, которые процесс обучения может генерировать и публиковать. Полный список вы найдете в нашем репозитории на GitHub.
Вот примерный список метрик, который отображается при создании новой конфигурации конструктора задач:
federated_learning { learning_process { metrics { name: "binary_accuracy" } metrics { name: "binary_crossentropy" } metrics { name: "recall" } metrics { name: "precision" } metrics { name: "auc-roc" } metrics { name: "auc-pr" } } }
Если интересующие вас показатели отсутствуют в текущем списке, свяжитесь с нами.
Конфигурации DP
Необходимо указать несколько параметров конфигурации, связанных с DP:
policies { min_separation_policy { minimum_separation: 1 } model_release_policy { num_max_training_rounds: 1000 dp_target_epsilon: 10 dp_delta: 0.000001 } } differential_privacy { type: FIXED_GAUSSIAN clip_norm: 0.1 noise_multiplier: 0.1 }- Для прохождения проверки необходимо наличие либо
dp_target_epsilon, либоnoise_mulitipiler: (noise_to_epsilonepislon_to_noise). - Эти настройки по умолчанию вы можете найти в нашем репозитории на GitHub.
- Для прохождения проверки необходимо наличие либо
Шаг 3. Загрузите сохраненную модель и конфигурацию конструктора задач в облачное хранилище любого разработчика.
Не забудьте обновить поля artifact_building при загрузке конфигурации построителя задач.
Шаг 4. (необязательно) Проверьте процесс создания артефакта, не создавая новую задачу.
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint}
Пример модели проверяется как с помощью проверки гибких операций (flex ops check), так и с помощью проверки DP (dp check); вы можете добавить skip_flex_ops_check и skip_dp_check , чтобы обойти проверку во время ее выполнения (эта модель не может быть развернута в текущей версии клиента ODP из-за отсутствия некоторых гибких операций).
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint} --skip_flex_ops_check=True --skip_dp_check=True
flex_ops_check: встроенная библиотека операторов TensorFlow Lite поддерживает лишь ограниченное количество операторов TensorFlow ( совместимость TensorFlow Lite и операторов TensorFlow ). Все несовместимые операторы TensorFlow необходимо установить с помощью делегата flex ( Android.bp ). Если модель содержит неподдерживаемые операции, свяжитесь с нами для их регистрации:
Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {...}Лучший способ отладки конструктора задач — запустить его локально:
# Starts a server at localhost:5000 bazel run //python/taskbuilder:task_builder # Links to a server at localhost:5000 by removing task_builder_server flag bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --skip_flex_ops_check=True --skip_dp_check=True
Полученные артефакты можно найти в облачном хранилище, указанном в конфигурации. Оно должно выглядеть примерно так, как в примере в нашем репозитории GitHub .
Шаг 5. Создайте артефакты и запустите новую пару задач обучения и оценки на сервере FCP.
Удалите флаг build_artifact_only , и созданные артефакты будут загружены на сервер FCP. Вам следует убедиться, что пара задач обучения и оценки успешно создана.
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config.pbtxt --task_builder_server=${task_builder_server_endpoint}
Шаг 6. Подготовьте клиентскую часть FCP.
- Реализуйте публичный API ODP
IsolatedWorker#onTrainingExamplesдля генерации обучающих данных. - Вызовите
FederatedComputeScheduler#schedule. - Несколько примеров вы найдете в нашем репозитории исходного кода Android.
Шаг 7. Мониторинг
Метрики сервера
Инструкции по настройке вы найдете в нашем репозитории на GitHub.
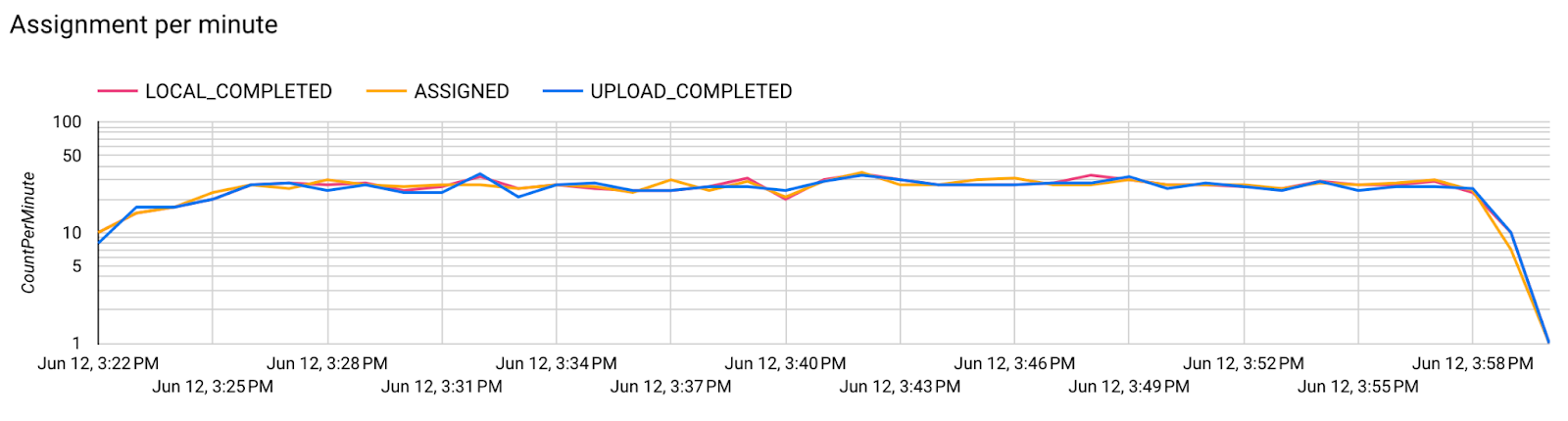
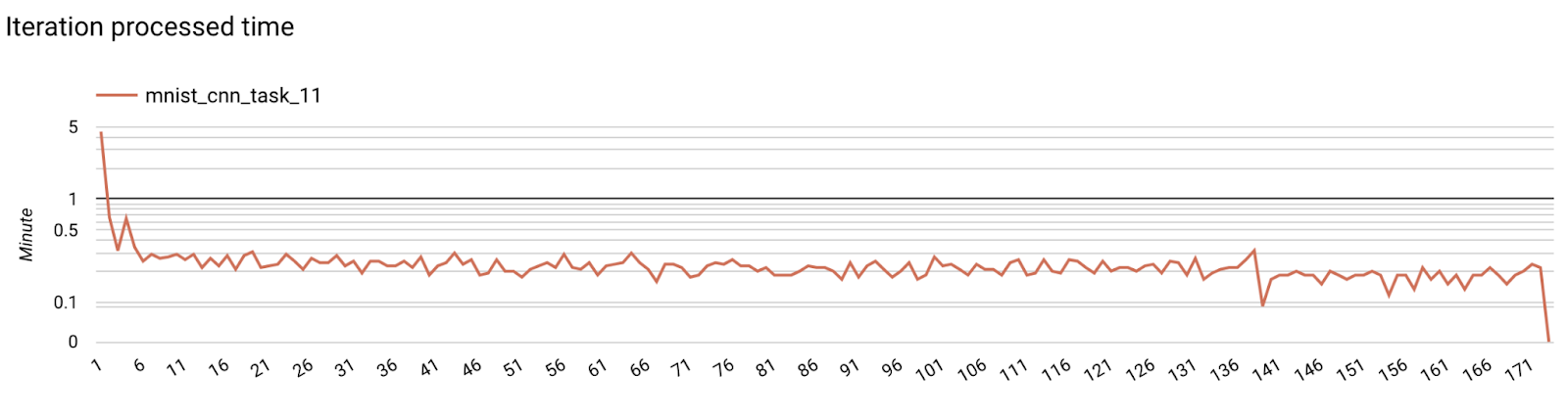
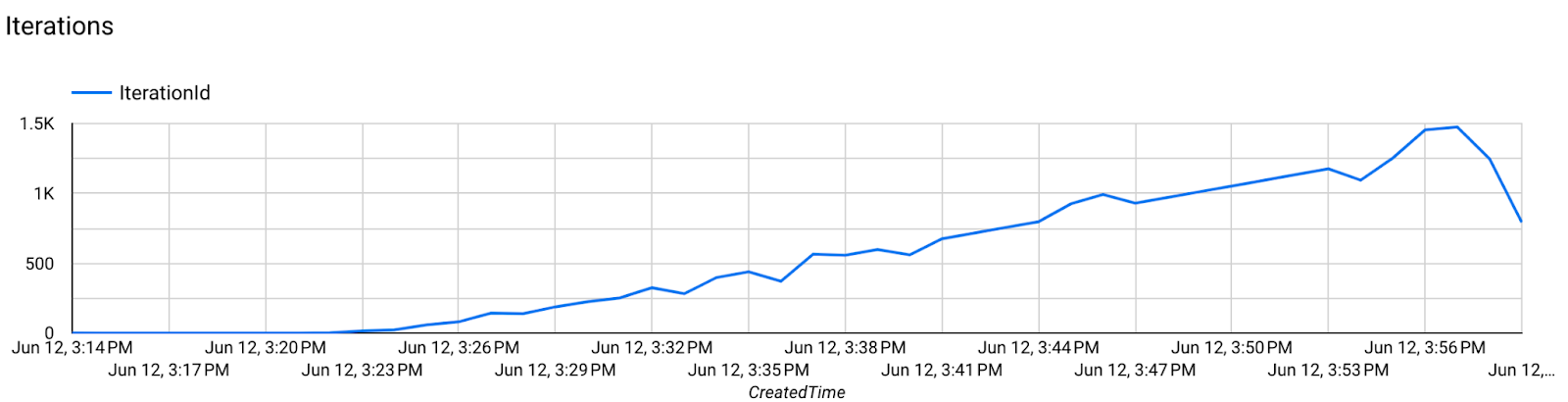
- Метрики модели
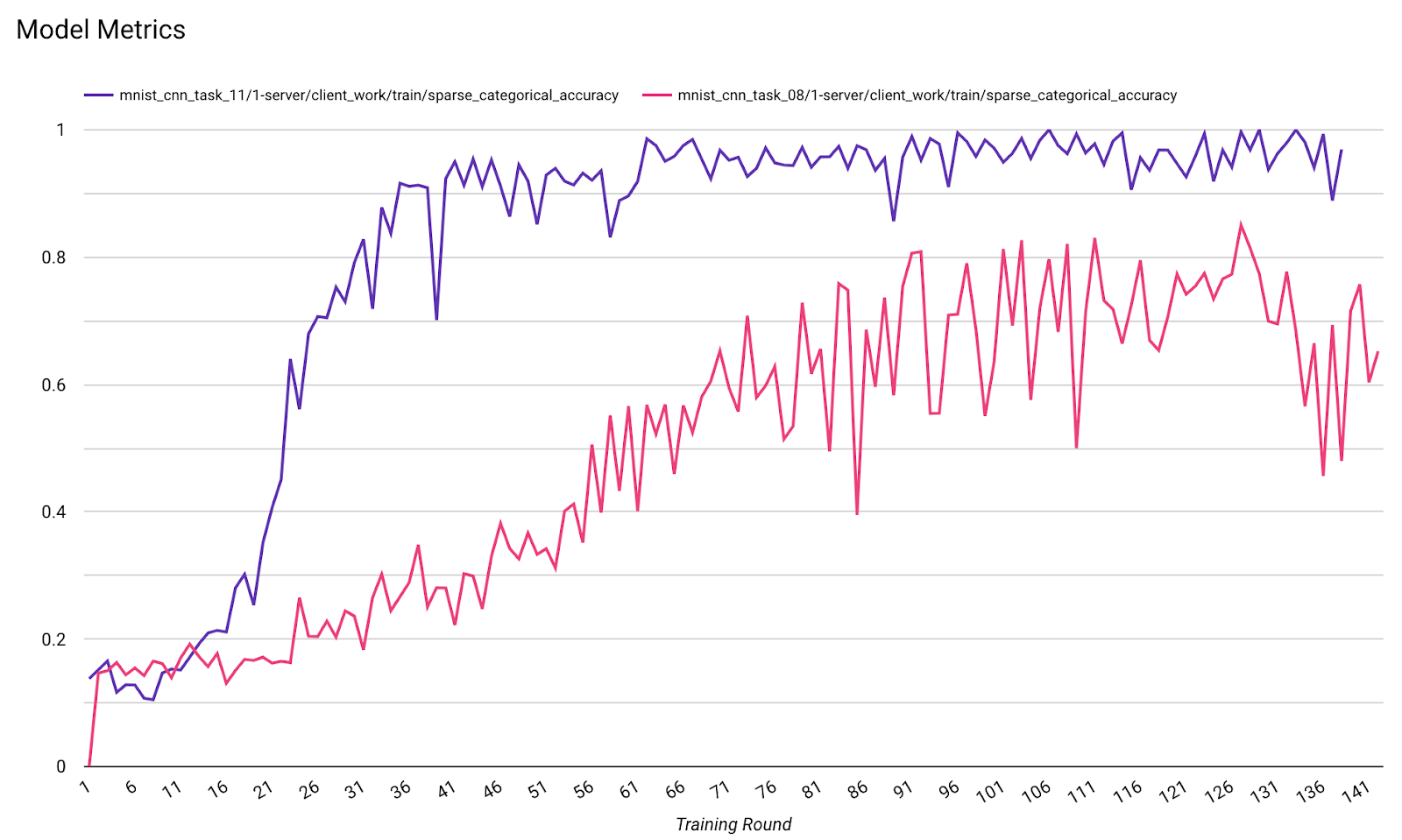
На одной диаграмме можно сравнить показатели разных запусков. Например:
- Фиолетовая линия соответствует значению
noise_multiplier0.1. - Розовая линия соответствует значению
noise_multipiler0.3.