
Nesta página, descrevemos como trabalhar com as APIs de aprendizado federado fornecidas pela Personalização no dispositivo para treinar um modelo com um processo de aprendizado de média federada e ruído gaussiano fixo.
Antes de começar
Antes de começar, conclua as seguintes etapas no seu dispositivo de teste:
Verifique se o módulo OnDevicePersonalization está instalado. O módulo ficou disponível como uma atualização automática em abril de 2024.
# List the modules installed on the device adb shell pm list packages --apex-only --show-versioncodeVerifique se o seguinte módulo está listado com um código de versão 341717000 ou mais recente:
package:com.google.android.ondevicepersonalization versionCode:341717000Se o módulo não estiver na lista, acesse Configurações > Segurança e privacidade > Atualizações > Atualização do sistema do Google Play para garantir que o dispositivo esteja atualizado. Selecione Atualizar conforme necessário.
Ative todos os novos recursos relacionados ao federated learning.
# Enable On-Device Personalization apk. adb shell device_config put on_device_personalization global_kill_switch false # Enable On-Device Personalization APIs. adb shell device_config put on_device_personalization enable_ondevicepersonalization_apis true # Enable On-Device Personalization overriding. adb shell device_config put on_device_personalization enable_personalization_status_override true adb shell device_config put on_device_personalization personalization_status_override_value true # Enable Federated Compute apk. adb shell device_config put on_device_personalization federated_compute_kill_switch false
Criar uma tarefa de aprendizado federado

Os números no diagrama são explicados com mais detalhes nas oito etapas a seguir.
Configurar um servidor de computação federada
O aprendizado federado é um map-reduce executado no servidor de computação federada (o redutor) e em um conjunto de clientes (os mapeadores). O servidor de computação federada mantém os metadados e as informações do modelo de cada tarefa de aprendizado federado em execução. Em detalhes:
- Um desenvolvedor de aprendizado federado cria uma nova tarefa e faz upload dos metadados de execução da tarefa e das informações do modelo para o servidor.
- Quando um cliente do Federated Compute inicia uma nova solicitação de atribuição de tarefa ao servidor, ele verifica a qualificação da tarefa e retorna as informações qualificadas.
- Quando um cliente da computação federada termina os cálculos locais, ele envia os resultados ao servidor. Em seguida, o servidor realiza a agregação e a adição de ruído nesses resultados de computação e aplica o resultado ao modelo final.
Para saber mais sobre esses conceitos, confira:
- Aprendizado federado: machine learning colaborativo sem dados de treinamento centralizados
- Towards Federated Learning at Scale: System Design (SysML 2019) (em inglês)
A ODP usa uma versão aprimorada do aprendizado federado, em que o ruído calibrado (centralizado) é aplicado aos agregados antes de ser aplicado ao modelo. A escala do ruído garante que os agregados preservem a privacidade diferencial.
Etapa 1. Criar um servidor de computação federada
Siga as instruções no projeto do Federated Compute para configurar seu próprio servidor.
Etapa 2. Preparar um SavedFunctionalModel
Prepare um arquivo 'FunctionalModel' salvo. Você pode usar 'functional_model_from_keras' para converter um 'Model' em 'FunctionalModel' e usar 'save_functional_model' para serializar esse 'FunctionalModel' como um 'SavedModel'.
functional_model = tff.learning.models.functional_model_from_keras(keras_model=model)
tff.learning.models.save_functional_model(functional_model, saved_model_path)
Etapa 3. Criar uma configuração de servidor de computação federada
Prepare um fcp_server_config.json que inclua políticas, configuração de aprendizado federado e configuração de privacidade diferencial. Exemplo:
# Identifies the set of client devices that will participate.
population_name: "my_new_population"
# Options you can choose:
# * TRAINING_ONLY: Only one training task will be generated under this
# population.
# * TRAINING_AND_EVAL: One training task and one evaluation task will be
# generated under this population.
# * EVAL_ONLY: Only one evaluation task will be generated under this
# population.
mode: TRAINING_AND_EVAL
policies {
# Policy for sampling on-device examples. It is checked every time a
# device attempts to start a new training.
min_separation_policy {
# The minimum number of rounds before the same client participated.
minimum_separation: 3
}
# Policy for releasing training results to developers. It is checked
# when uploading a new task to the Federated Compute Server.
model_release_policy {
# Server stops training when number of training rounds reaches this
# number.
num_max_training_rounds: 1000
}
}
# Federated learning setups. They are applied inside Task Builder.
federated_learning {
learning_process {
# Use FED_AVG to build federated learning process. Options you can
# choose:
# * FED_AVG: Federated Averaging algorithm
# (https://arxiv.org/abs/2003.00295)
# * FED_SDG: Federated SGD algorithm
# (https://arxiv.org/abs/1602.05629)
type: FED_AVG
# Optimizer used at client side training. Options you can choose:
# * ADAM
# * SGD
client_optimizer: SGD
# Learning rate used at client side training.
client_learning_rate: 0.01
# Optimizer used at server side training. Options you can choose:
# * ADAM
# * SGD
server_optimizer: ADAM
# Learning rate used at server side training.
sever_learning_rate: 1
runtime_config {
# Number of participating devices for each round of training.
report_goal: 2000
}
# List of metrics to be evaluated by the model during training and
# evaluation. Federated Compute Server provides a list of allowed
# metrics.
metrics {
name: "auc-roc"
}
metrics {
name: "binary_accuracy"
}
}
# Whether or not to generate a corresponding evaluation task under the same
# population. If this field isn't set, only one training task is
# generated under this population.
evaluation {
# The task id under the same population of the source training task that
# this evaluation task evaluates.
source_training_task_id: 1
# Decides how checkpoints from the training task are chosen for
# evaluation.
# * every_k_round: the evaluation task randomly picks one checkpoint
# from the past k rounds of training task checkpoints.
# * every_k_hour: the evaluation task randomly picks one checkpoint
# from the past k hours of training task checkpoints.
checkpoint_selector: "every_1_round"
# The traffic of this evaluation task in this population.
evaluation_traffic: 0.1
# Number of participating devices for each round of evaluation.
report_goal: 200
}
}
# Differential Privacy setups. They are applied inside the Task Builder.
differential_privacy {
# The DP aggregation algorithm you want to use. Options you can choose:
# * FIXED_GAUSSIAN: Federated Learning DP-SGD with fixed clipping norm
# described in "Learning Differentially Private Recurrent
# Language Models" (https://arxiv.org/abs/1710.06963).
# * ADAPTIVE_GAUSSIAN: Federated Learning DP-SGD with quantile-based clip
# norm estimation described in "Differentially Private
# Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
# * TREE: DP-FTRL algorithm described in "Practical and Private (Deep)
# Learning without Sampling or Shuffling"
# (https://arxiv.org/abs/2103.00039).
# * ADADPTIVE_TREE: DP-FTRL with adaptive clipping norm descirbed in
# "Differentially Private Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
type: FIXED_GAUSSIAN
# Noise multiplier for the Gaussian noise.
noise_multiplier: 0.1
# The value of the clipping norm.
clip_norm: 0.1
}
Etapa 4. Envie a configuração ZIP para o servidor de computação federada.
Envie o arquivo ZIP e fcp_server_config.json para o servidor de computação federada.
task_builder_client --task_builder_server='http://{federated_compute_server_endpoint}' --saved_model='saved_model' --task_config='fcp_server_config.json'
O endpoint do servidor de computação federada é o servidor que você configurou na etapa 1.
A biblioteca de operadores integrada do LiteRT só é compatível com um número limitado de operadores do TensorFlow (selecione operadores do TensorFlow). O conjunto de operadores compatíveis pode variar entre diferentes versões do módulo OnDevicePersonalization. Para garantir a compatibilidade, um processo de verificação do operador é realizado no criador de tarefas durante a criação da tarefa.
A versão mínima compatível do módulo OnDevicePersonalization será incluída nos metadados da tarefa. Essas informações podem ser encontradas na mensagem informativa do criador de tarefas.
I1023 22:16:53.058027 139653371516736 task_builder_client.py:109] Success! Tasks are built, and artifacts are uploaded to the cloud. I1023 22:16:53.058399 139653371516736 task_builder_client.py:112] applied_algorithms { learning_algo: FED_AVG client_optimizer: SGD server_optimizer: SGD dp_aggregator: FIXED_GAUSSIAN } metric_results { accepted_metrics: "binary_accuracy, binary_crossentropy, recall, precision, auc-roc, auc-pr" } dp_hyperparameters { dp_delta: 0.000001 dp_epsilon: 6.4 noise_multiplier: 1.0 dp_clip_norm: 1.0 num_training_rounds: 10000 } I1023 22:16:53.058594 139653371516736 task_builder_client.py:113] training_task { min_client_version: "341912000" } eval_task { min_client_version: "341812000" }O servidor de computação federada vai atribuir essa tarefa a todos os dispositivos equipados com um módulo OnDevicePersonalization com uma versão superior a 341812000.
Se o modelo incluir operações que não são compatíveis com nenhum módulo do OnDevicePersonalization, uma mensagem de erro será gerada durante a criação da tarefa.
common.TaskBuilderException: Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {'L2Loss': 'L2LossOp<CPUDevice, float>'} . Stop building remaining artifacts.Confira uma lista detalhada de operações flexíveis compatíveis no GitHub.
Criar um APK de computação federada do Android
Para criar um APK do Federated Compute do Android, especifique o endpoint do URL do servidor do Federated Compute no seu AndroidManifest.xml, a que o cliente do Federated Compute se conecta.
Etapa 5. Especifique o endpoint do URL do servidor de computação federada
Especifique o endpoint do URL do servidor de computação federada (que você configurou na etapa 1) no seu AndroidManifest.xml, a que o cliente de computação federada se conecta.
<!-- Contents of AndroidManifest.xml -->
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.odpsample" >
<application android:label="OdpSample">
<!-- XML resource that contains other ODP settings. -->
<property android:name="android.ondevicepersonalization.ON_DEVICE_PERSONALIZATION_CONFIG"
android:resource="@xml/OdpSettings"></property>
<!-- The service that ODP will bind to. -->
<service android:name="com.example.odpsample.SampleService"
android:exported="true" android:isolatedProcess="true" />
</application>
</manifest>
O arquivo de recursos XML especificado na tag <property> também precisa declarar a classe de serviço em uma tag <service> e especificar o endpoint de URL do servidor de computação federada a que o cliente de computação federada vai se conectar:
<!-- Contents of res/xml/OdpSettings.xml -->
<on-device-personalization>
<!-- Name of the service subclass -->
<service name="com.example.odpsample.SampleService">
<!-- If you want to use federated compute feature to train a model,
specify this tag. -->
<federated-compute-settings url="https://fcpserver.com/" />
</service>
</on-device-personalization>
Etapa 6: Implementar a API IsolatedWorker#onTrainingExample
Implemente a API pública de personalização no dispositivo IsolatedWorker#onTrainingExample para gerar dados de treinamento.
O código em execução no IsolatedProcess não tem acesso direto à rede, aos discos locais ou a outros serviços em execução no dispositivo. No entanto, as seguintes APIs estão disponíveis:
- "getRemoteData": dados imutáveis de chave-valor baixados de back-ends remotos operados por desenvolvedores, se aplicável.
- 'getLocalData': dados mutáveis de chave-valor persistidos localmente pelos desenvolvedores, se aplicável.
- "UserData": dados do usuário fornecidos pela plataforma.
- 'getLogReader': retorna um DAO para as tabelas REQUESTS e EVENTS.
Exemplo:
@Override public void onTrainingExample(
@NonNull TrainingExampleInput input,
@NonNull Consumer<TrainingExampleOutput> consumer) {
// Check if the incoming training task is the task we want.
if (input.getPopulationName() == "my_new_population") {
TrainingExampleOutput result = new TrainingExampleOutput.Builder():
RequestLogRecord record = this.getLogReader().getRequestLogRecord(1);
int count = 1;
// Iterate logging event table.
for (ContentValues contentValues: record.rows()) {
Features features = Features.newBuilder()
// Retrieve carrier from user info.
.putFeature("carrier", buildFeature(mUserData.getCarrier()))
// Retrieve features from logging info.
.putFeature("int_feature_1",
buildFeature(contentValues.get("int_feature_1")
result.addTrainingExample(
Example.newBuilder()
.setFeatures(features).build().toByteArray())
.addResumptionToken(
String.format("token%d", count).getBytes()))
.build();
count++;
}
consumer.accept(result.build());
}
}
Etapa 7: Programe uma tarefa de treinamento recorrente.
A personalização no dispositivo oferece um FederatedComputeScheduler para os desenvolvedores programarem ou cancelarem jobs de computação federada. Há diferentes opções para chamar o IsolatedWorker, seja em uma programação ou quando um download assíncrono é concluído. Confira exemplos dos dois a seguir.
Opção com base em programação. Chame a função
FederatedComputeScheduler#schedulenoIsolatedWorker#onExecute.@Override public void onExecute( @NonNull ExecuteInput input, @NonNull Consumer<ExecuteOutput> consumer ) { if (input != null && input.getAppParams() != null && input.getAppParams().getString("schedule_training") != null) { if (input.getAppParams().getString("schedule_training").isEmpty()) { consumer.accept(null); return; } TrainingInterval interval = new TrainingInterval.Builder() .setMinimumInterval(Duration.ofSeconds(10)) .setSchedulingMode(2) .build(); FederatedComputeScheduler.Params params = new FederatedComputeScheduler .Params(interval); FederatedComputeInput fcInput = new FederatedComputeInput.Builder() .setPopulationName( input.getAppParams().getString("schedule_training")).build(); mFCScheduler.schedule(params, fcInput); ExecuteOutput result = new ExecuteOutput.Builder().build(); consumer.accept(result); } }Opção "Download concluído". Chame
FederatedComputeScheduler#scheduleemIsolatedWorker#onDownloadCompletedse a programação de uma tarefa de treinamento depender de dados ou processos assíncronos.
Validação
As etapas a seguir descrevem como validar se a tarefa de aprendizado federado está sendo executada corretamente.
Etapa 8. Valide se a tarefa de aprendizado federado está sendo executada corretamente.
Um novo ponto de verificação do modelo e um novo arquivo de métricas são gerados em cada rodada de agregação do lado do servidor.
As métricas estão em um arquivo formatado em JSON de pares de chave-valor. O arquivo é gerado pela lista de Metrics definida na Etapa 3. Exemplo de um arquivo JSON de métricas representativas:
{"server/client_work/train/binary_accuracy":0.5384615659713745, "server/client_work/train/binary_crossentropy":0.694046676158905, "server/client_work/train/recall":0.20000000298023224, "server/client_work/train/precision":0.3333333432674408, "server/client_work/train/auc-roc":0.3500000238418579, "server/client_work/train/auc-pr":0.44386863708496094, "server/finalizer/update_non_finite":0.0}
Use algo semelhante ao script a seguir para receber métricas do modelo e monitorar a performance do treinamento:
import collections
import json
import matplotlib.pyplot as plt
from google.cloud import storage
# The population_name you set in fcp_server_config.json in Step 3.
POPULATION_NAME = 'my_new_population'
# The Google Cloud storage you set in Step 1.
GCS_BUCKET_NAME = 'fcp-gcs'
NUM_TRAINING_ROUND = 1000
storage_client = storage.Client()
bucket = storage_client.bucket(GCS_BUCKET_NAME)
metrics = collections.defaultdict(list)
for i in range(NUM_TRAINING_ROUND):
blob = bucket.blob('{}/{}/1/{}/s/0/metrics'.format(GCS_BUCKET_NAME, POPULATION_NAME, i+1))
with blob.open("r") as f:
metric = json.loads(f.read())
for metric_name in metric.keys():
metrics[metric_name].append(metric[metric_name])
for metric_name in metrics:
print(metric_name)
plt.plot(metrics[metric_name])
plt.show()
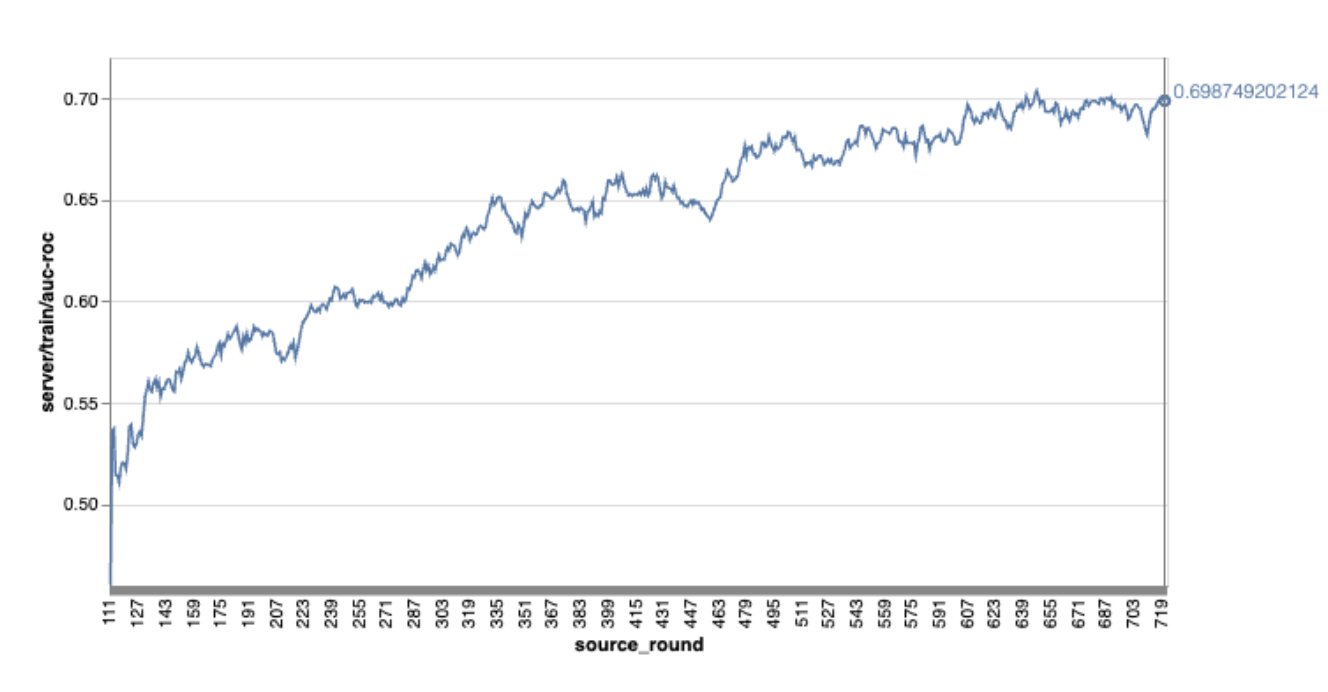
No gráfico de exemplo anterior:
- O eixo x é o número de treinamentos por rodada.
- O eixo y é o valor de AUC-ROC de cada rodada.
Treinar um modelo de classificação de imagens na personalização no dispositivo
Neste tutorial, o conjunto de dados EMNIST é usado para demonstrar como executar uma tarefa de aprendizado federado no ODP.
Etapa 1. Crie um tff.learning.models.FunctionalModel
def get_image_classification_input_spec():
return (
tf.TensorSpec([None, 28, 28, 1], tf.float32),
tf.TensorSpec([None, 1], tf.int64),
)
def create_and_save_image_classification_functional_model(
model_path: str,
) -> None:
keras_model = emnist_models.create_original_fedavg_cnn_model(
only_digits=True
)
functional_model = tff.learning.models.functional_model_from_keras(
keras_model=keras_model,
input_spec=get_image_classification_input_spec(),
loss_fn=tf.keras.losses.SparseCategoricalCrossentropy(),
)
tff.learning.models.save_functional_model(functional_model, model_path)
- Você encontra os detalhes do modelo emnist keras em emnist_models.
- O TfLite ainda não tem um bom suporte para tf.sparse.SparseTensor ou tf.RaggedTensor. Tente usar tf.Tensor o máximo possível ao criar o modelo.
- O criador de tarefas da ODP vai substituir todas as métricas ao criar o processo de aprendizado. Não é necessário especificar nenhuma métrica. Esse assunto será abordado mais detalhadamente na Etapa 2. Crie a configuração do criador de tarefas.
Há suporte para dois tipos de entradas de modelo:
Tipo 1. Uma tupla(features_tensor, label_tensor).
- Ao criar o modelo, o input_spec tem esta aparência:
def get_input_spec(): return ( tf.TensorSpec([None, 28, 28, 1], tf.float32), tf.TensorSpec([None, 1], tf.int64), )- Combine o que foi dito acima com a seguinte implementação da API pública do ODP IsolatedWorker#onTrainingExamples para gerar dados de treinamento no dispositivo:
return tf.train.Example( features=tf.train.Features( feature={ 'x': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0] * 784) ), 'y': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()Tipo 2. Um
Tuple(Dict[feature_name, feature_tensor], label_tensor)- Ao criar o modelo, o input_spec tem esta aparência:
def get_input_spec() -> ( Tuple[collections.OrderedDict[str, tf.TensorSpec], tf.TensorSpec] ): return ( collections.OrderedDict( [('feature-1', tf.TensorSpec([None, 1], tf.float32)), ('feature-2', tf.TensorSpec([None, 1], tf.float32))] ), tf.TensorSpec([None, 1], tf.int64), )- Combine o que foi dito acima com a seguinte implementação da API pública da ODP IsolatedWorker#onTrainingExamples para gerar dados de treinamento:
return tf.train.Example( features=tf.train.Features( feature={ 'feature-1': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0]) ), 'feature-2': tf.train.Feature( float_list=tf.train.FloatList(value=[2.0]) ), 'my_label': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()- Não se esqueça de registrar o label_name na configuração do criador de tarefas.
mode: TRAINING_AND_EVAL # Task execution mode population_name: "my_example_model" label_name: "my_label"
O ODP processa a DP automaticamente ao criar o processo de aprendizado. Portanto, não é necessário adicionar ruído ao criar o modelo funcional.
A saída desse modelo funcional salvo deve ser semelhante ao exemplo no nosso repositório do GitHub.
Etapa 2. Criar a configuração do criador de tarefas
Você encontra exemplos de configuração do criador de tarefas no nosso repositório do GitHub.
Métricas de treinamento e avaliação
Como as métricas podem vazar dados do usuário, o criador de tarefas terá uma lista de métricas que o processo de aprendizado pode gerar e liberar. Confira a lista completa no nosso repositório do GitHub.
Confira um exemplo de lista de métricas ao criar uma configuração de criador de tarefas:
federated_learning { learning_process { metrics { name: "binary_accuracy" } metrics { name: "binary_crossentropy" } metrics { name: "recall" } metrics { name: "precision" } metrics { name: "auc-roc" } metrics { name: "auc-pr" } } }
Se as métricas que você quer não estiverem na lista, entre em contato com nossa equipe.
Configurações de DP
Há algumas configurações relacionadas ao DP que precisam ser especificadas:
policies { min_separation_policy { minimum_separation: 1 } model_release_policy { num_max_training_rounds: 1000 dp_target_epsilon: 10 dp_delta: 0.000001 } } differential_privacy { type: FIXED_GAUSSIAN clip_norm: 0.1 noise_multiplier: 0.1 }dp_target_epsilonounoise_mulitipilerestá presente para passar na validação: (noise_to_epsilonepislon_to_noise).- Você pode encontrar essas configurações padrão no nosso repositório do GitHub.
Etapa 3. Faça upload do modelo salvo e da configuração do criador de tarefas para o armazenamento em nuvem de qualquer desenvolvedor.
Não se esqueça de atualizar os campos artifact_building ao fazer upload da configuração do criador de tarefas.
Etapa 4. (Opcional) Testar a criação de artefatos sem criar uma nova tarefa
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint}
O modelo de exemplo é validado com a verificação de operações flexíveis e de dp. Você pode adicionar skip_flex_ops_check e skip_dp_check para ignorar durante a validação. Esse modelo não pode ser implantado na versão atual do cliente ODP devido a algumas operações flexíveis ausentes.
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint} --skip_flex_ops_check=True --skip_dp_check=True
flex_ops_check: a biblioteca de operadores integrados do TensorFlow Lite é compatível apenas com um número limitado de operadores do TensorFlow (compatibilidade entre operadores do TensorFlow Lite e do TensorFlow). Todas as operações incompatíveis do TensorFlow precisam ser instaladas usando o delegado flexível (Android.bp). Se um modelo tiver operações sem suporte, entre em contato para registrá-las:
Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {...}A melhor maneira de depurar um criador de tarefas é iniciar um localmente:
# Starts a server at localhost:5000 bazel run //python/taskbuilder:task_builder # Links to a server at localhost:5000 by removing task_builder_server flag bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --skip_flex_ops_check=True --skip_dp_check=True
É possível encontrar os artefatos resultantes no Cloud Storage especificado na configuração. Ele precisa ser algo parecido com o exemplo no nosso repositório do GitHub.
Etapa 5. Crie artefatos e um novo par de tarefas de treinamento e avaliação no servidor do FCP.
Remova a flag build_artifact_only, e os artefatos criados serão enviados para o servidor do FCP. Verifique se um par de tarefas de treinamento e avaliação foi criado com sucesso.
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config.pbtxt --task_builder_server=${task_builder_server_endpoint}
Etapa 6: Preparar o lado do cliente para o FCP
- Implemente a API pública da ODP
IsolatedWorker#onTrainingExamplespara gerar dados de treinamento. - Chame
FederatedComputeScheduler#schedule. - Confira alguns exemplos no nosso repositório de origem do Android.
Etapa 7: Monitoramento
Métricas do servidor
Encontre as instruções de configuração no nosso repositório do GitHub.
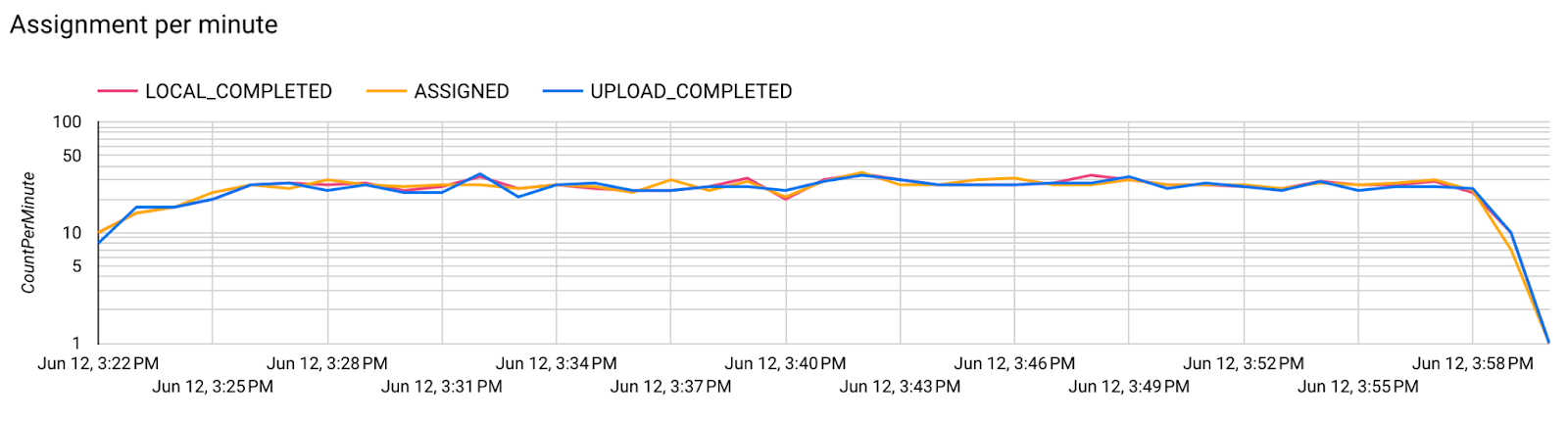
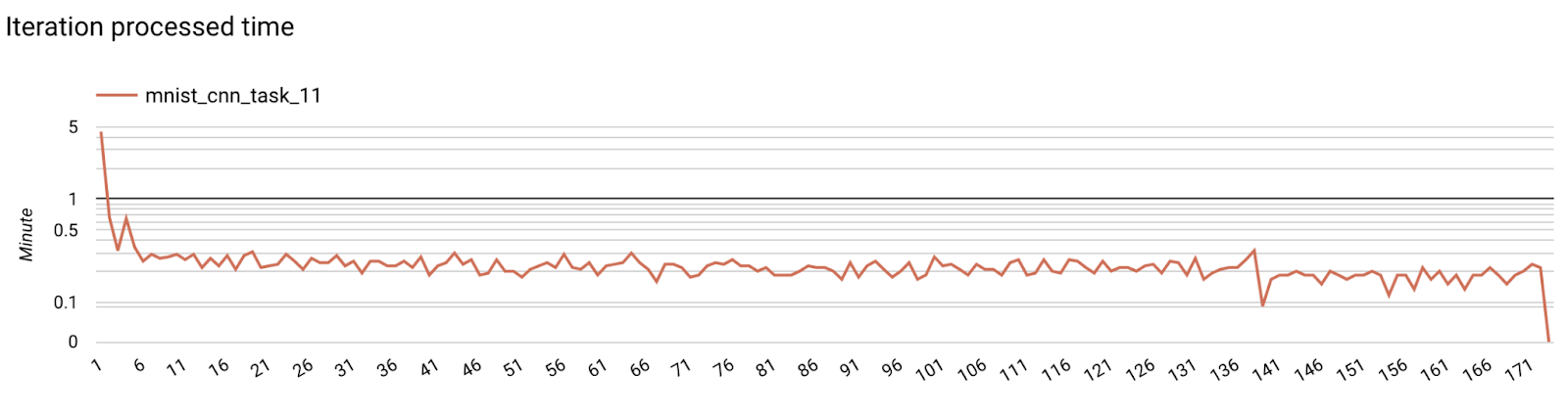
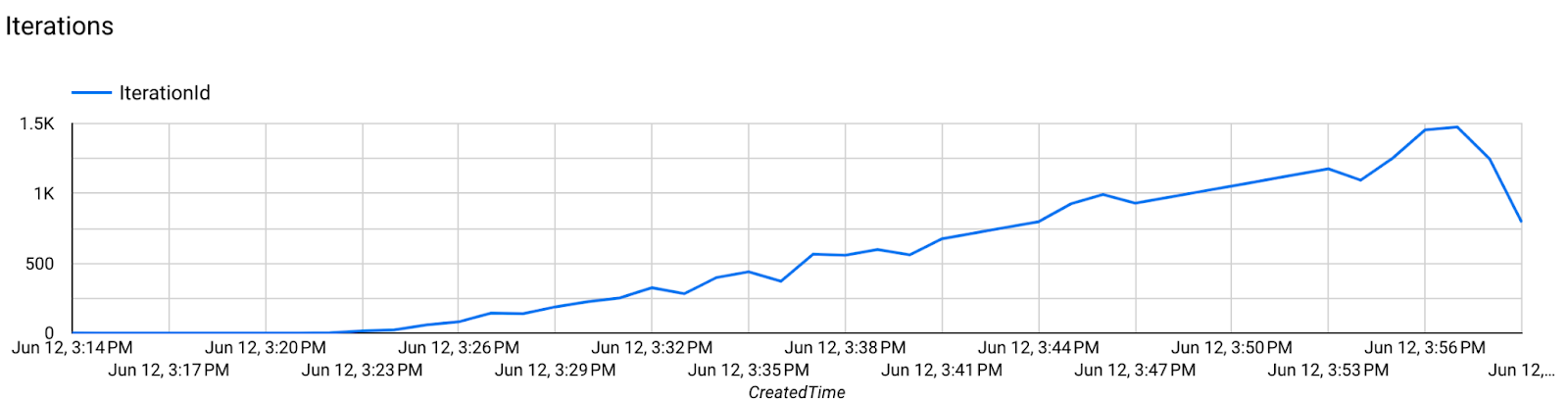
- Métricas de modelos
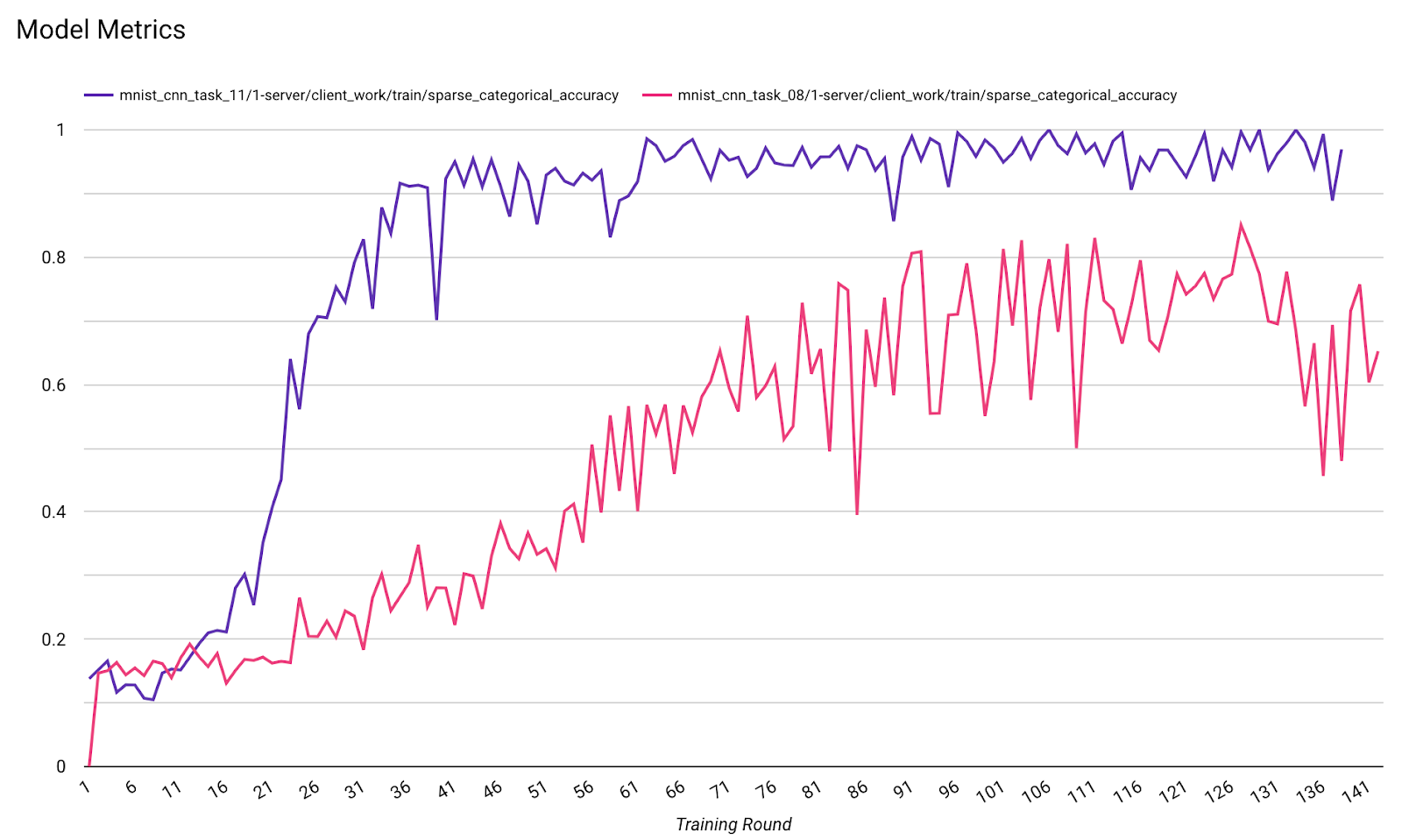
É possível comparar métricas de diferentes execuções em um diagrama. Exemplo:
- A linha roxa é com
noise_multiplier0,1 - A linha rosa é com
noise_multipiler0,3