
Na tej stronie opisujemy, jak korzystać z interfejsów API sfederowanego uczenia się udostępnianych przez personalizację na urządzeniu, aby trenować model za pomocą procesu uczenia się z uśrednianiem sfederowanym i stałym szumem Gaussa.
Zanim zaczniesz
Zanim zaczniesz, wykonaj na urządzeniu testowym te czynności:
Sprawdź, czy moduł OnDevicePersonalization jest zainstalowany. Moduł został udostępniony w ramach automatycznej aktualizacji w kwietniu 2024 r.
# List the modules installed on the device adb shell pm list packages --apex-only --show-versioncodeSprawdź, czy na liście znajduje się ten moduł z kodem wersji 341717000 lub nowszym:
package:com.google.android.ondevicepersonalization versionCode:341717000Jeśli nie ma go na liście, otwórz Ustawienia > Bezpieczeństwo i prywatność > Aktualizacje > Aktualizacja systemowa Google Play, aby sprawdzić, czy urządzenie jest aktualne. W razie potrzeby kliknij Zaktualizuj.
Włącz wszystkie nowe funkcje związane z uczeniem sfederowanym.
# Enable On-Device Personalization apk. adb shell device_config put on_device_personalization global_kill_switch false # Enable On-Device Personalization APIs. adb shell device_config put on_device_personalization enable_ondevicepersonalization_apis true # Enable On-Device Personalization overriding. adb shell device_config put on_device_personalization enable_personalization_status_override true adb shell device_config put on_device_personalization personalization_status_override_value true # Enable Federated Compute apk. adb shell device_config put on_device_personalization federated_compute_kill_switch false
Tworzenie zadania sfederowanego uczenia się

Liczby na diagramie są bardziej szczegółowo opisane w 8 krokach poniżej.
Konfigurowanie serwera Federated Compute
Sfederowane uczenie się to proces map-reduce, który jest uruchamiany na serwerze obliczeń sfederowanych (reduktor) i na zestawie klientów (mapper). Serwer obliczeń sfederowanych przechowuje metadane i informacje o modelu każdego zadania sfederowanego uczenia się. Na najwyższym poziomie:
- Deweloper uczenia federacyjnego tworzy nowe zadanie i przesyła na serwer metadane dotyczące jego wykonywania oraz informacje o modelu.
- Gdy klient Federated Compute inicjuje nową prośbę o przydzielenie zadania do serwera, serwer sprawdza, czy zadanie kwalifikuje się do wykonania, i zwraca informacje o zakwalifikowanych zadaniach.
- Gdy klient Federated Compute zakończy obliczenia lokalne, wysyła ich wyniki na serwer. Serwer wykonuje następnie agregację i dodaje szum do tych wyników obliczeń, a potem stosuje je w modelu końcowym.
Więcej informacji o tych pojęciach znajdziesz w tych artykułach:
- Sfederowane uczenie się: wspólne uczenie maszynowe bez scentralizowanych danych treningowych
- Towards Federated Learning at Scale: System Design (SysML 2019)
ODP korzysta z ulepszonej wersji sfederowanego uczenia się, w której do zagregowanych danych przed zastosowaniem ich w modelu dodawany jest skalibrowany (scentralizowany) szum. Skala szumu zapewnia, że dane zbiorcze zachowują prywatność różnicową.
Krok 1. Tworzenie serwera Federated Compute
Aby skonfigurować własny serwer Federated Compute, postępuj zgodnie z instrukcjami w projekcie Federated Compute.
Krok 2. Przygotowywanie zapisanego modelu FunctionalModel
Przygotuj zapisany plik „FunctionalModel”. Możesz użyć funkcji 'functional_model_from_keras', aby przekonwertować „Model” na „FunctionalModel”, a następnie użyć funkcji „save_functional_model”, aby serializować ten „FunctionalModel” jako „SavedModel”.
functional_model = tff.learning.models.functional_model_from_keras(keras_model=model)
tff.learning.models.save_functional_model(functional_model, saved_model_path)
Krok 3. Tworzenie konfiguracji serwera Federated Compute
Przygotuj fcp_server_config.json, który zawiera zasady, konfigurację uczenia sfederowanego i konfigurację prywatności różnicowej. Przykład:
# Identifies the set of client devices that will participate.
population_name: "my_new_population"
# Options you can choose:
# * TRAINING_ONLY: Only one training task will be generated under this
# population.
# * TRAINING_AND_EVAL: One training task and one evaluation task will be
# generated under this population.
# * EVAL_ONLY: Only one evaluation task will be generated under this
# population.
mode: TRAINING_AND_EVAL
policies {
# Policy for sampling on-device examples. It is checked every time a
# device attempts to start a new training.
min_separation_policy {
# The minimum number of rounds before the same client participated.
minimum_separation: 3
}
# Policy for releasing training results to developers. It is checked
# when uploading a new task to the Federated Compute Server.
model_release_policy {
# Server stops training when number of training rounds reaches this
# number.
num_max_training_rounds: 1000
}
}
# Federated learning setups. They are applied inside Task Builder.
federated_learning {
learning_process {
# Use FED_AVG to build federated learning process. Options you can
# choose:
# * FED_AVG: Federated Averaging algorithm
# (https://arxiv.org/abs/2003.00295)
# * FED_SDG: Federated SGD algorithm
# (https://arxiv.org/abs/1602.05629)
type: FED_AVG
# Optimizer used at client side training. Options you can choose:
# * ADAM
# * SGD
client_optimizer: SGD
# Learning rate used at client side training.
client_learning_rate: 0.01
# Optimizer used at server side training. Options you can choose:
# * ADAM
# * SGD
server_optimizer: ADAM
# Learning rate used at server side training.
sever_learning_rate: 1
runtime_config {
# Number of participating devices for each round of training.
report_goal: 2000
}
# List of metrics to be evaluated by the model during training and
# evaluation. Federated Compute Server provides a list of allowed
# metrics.
metrics {
name: "auc-roc"
}
metrics {
name: "binary_accuracy"
}
}
# Whether or not to generate a corresponding evaluation task under the same
# population. If this field isn't set, only one training task is
# generated under this population.
evaluation {
# The task id under the same population of the source training task that
# this evaluation task evaluates.
source_training_task_id: 1
# Decides how checkpoints from the training task are chosen for
# evaluation.
# * every_k_round: the evaluation task randomly picks one checkpoint
# from the past k rounds of training task checkpoints.
# * every_k_hour: the evaluation task randomly picks one checkpoint
# from the past k hours of training task checkpoints.
checkpoint_selector: "every_1_round"
# The traffic of this evaluation task in this population.
evaluation_traffic: 0.1
# Number of participating devices for each round of evaluation.
report_goal: 200
}
}
# Differential Privacy setups. They are applied inside the Task Builder.
differential_privacy {
# The DP aggregation algorithm you want to use. Options you can choose:
# * FIXED_GAUSSIAN: Federated Learning DP-SGD with fixed clipping norm
# described in "Learning Differentially Private Recurrent
# Language Models" (https://arxiv.org/abs/1710.06963).
# * ADAPTIVE_GAUSSIAN: Federated Learning DP-SGD with quantile-based clip
# norm estimation described in "Differentially Private
# Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
# * TREE: DP-FTRL algorithm described in "Practical and Private (Deep)
# Learning without Sampling or Shuffling"
# (https://arxiv.org/abs/2103.00039).
# * ADADPTIVE_TREE: DP-FTRL with adaptive clipping norm descirbed in
# "Differentially Private Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
type: FIXED_GAUSSIAN
# Noise multiplier for the Gaussian noise.
noise_multiplier: 0.1
# The value of the clipping norm.
clip_norm: 0.1
}
Krok 4. Prześlij konfigurację ZIP na serwer Federated Compute.
Prześlij plik ZIP i fcp_server_config.json na serwer obliczeń sfederowanych.
task_builder_client --task_builder_server='http://{federated_compute_server_endpoint}' --saved_model='saved_model' --task_config='fcp_server_config.json'
Punkt końcowy serwera Federated Compute to serwer skonfigurowany w kroku 1.
Wbudowana biblioteka operatorów LiteRT obsługuje tylko ograniczoną liczbę operatorów TensorFlow (wybierz operatory TensorFlow). Obsługiwany zestaw operatorów może się różnić w zależności od wersji modułu OnDevicePersonalization. Aby zapewnić zgodność, podczas tworzenia zadania w narzędziu do tworzenia zadań przeprowadzany jest proces weryfikacji operatora.
Minimalna obsługiwana wersja modułu OnDevicePersonalization zostanie uwzględniona w metadanych zadania. Informacje te znajdziesz w komunikacie informacyjnym narzędzia do tworzenia zadań.
I1023 22:16:53.058027 139653371516736 task_builder_client.py:109] Success! Tasks are built, and artifacts are uploaded to the cloud. I1023 22:16:53.058399 139653371516736 task_builder_client.py:112] applied_algorithms { learning_algo: FED_AVG client_optimizer: SGD server_optimizer: SGD dp_aggregator: FIXED_GAUSSIAN } metric_results { accepted_metrics: "binary_accuracy, binary_crossentropy, recall, precision, auc-roc, auc-pr" } dp_hyperparameters { dp_delta: 0.000001 dp_epsilon: 6.4 noise_multiplier: 1.0 dp_clip_norm: 1.0 num_training_rounds: 10000 } I1023 22:16:53.058594 139653371516736 task_builder_client.py:113] training_task { min_client_version: "341912000" } eval_task { min_client_version: "341812000" }Serwer obliczeń sfederowanych przypisze to zadanie do wszystkich urządzeń wyposażonych w moduł OnDevicePersonalization w wersji wyższej niż 341812000.
Jeśli model zawiera operacje, które nie są obsługiwane przez żadne moduły OnDevicePersonalization, podczas tworzenia zadania pojawi się komunikat o błędzie.
common.TaskBuilderException: Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {'L2Loss': 'L2LossOp<CPUDevice, float>'} . Stop building remaining artifacts.Szczegółową listę obsługiwanych operacji elastycznych znajdziesz na GitHub.
Tworzenie pakietu APK na Androida na potrzeby obliczeń sfederowanych
Aby utworzyć pakiet APK obliczeń sfederowanych na Androida, musisz określić w AndroidManifest.xml punkt końcowy adresu URL serwera obliczeń sfederowanych, z którym łączy się klient obliczeń sfederowanych.
Krok 5. Określ punkt końcowy adresu URL serwera obliczeń sfederowanych
W AndroidManifest.xml określ URL punktu końcowego serwera Federated Compute (skonfigurowany w kroku 1), z którym łączy się klient Federated Compute.
<!-- Contents of AndroidManifest.xml -->
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.odpsample" >
<application android:label="OdpSample">
<!-- XML resource that contains other ODP settings. -->
<property android:name="android.ondevicepersonalization.ON_DEVICE_PERSONALIZATION_CONFIG"
android:resource="@xml/OdpSettings"></property>
<!-- The service that ODP will bind to. -->
<service android:name="com.example.odpsample.SampleService"
android:exported="true" android:isolatedProcess="true" />
</application>
</manifest>
Plik zasobu XML określony w tagu <property> musi też deklarować klasę usługi w tagu <service> i określać punkt końcowy adresu URL serwera obliczeń sfederowanych, z którym połączy się klient obliczeń sfederowanych:
<!-- Contents of res/xml/OdpSettings.xml -->
<on-device-personalization>
<!-- Name of the service subclass -->
<service name="com.example.odpsample.SampleService">
<!-- If you want to use federated compute feature to train a model,
specify this tag. -->
<federated-compute-settings url="https://fcpserver.com/" />
</service>
</on-device-personalization>
Krok 6. Wdrażanie interfejsu IsolatedWorker#onTrainingExample API
Wdróż publiczny interfejs On-Device Personalization APIIsolatedWorker#onTrainingExample, aby generować dane treningowe.
Kod działający w IsolatedProcess nie ma bezpośredniego dostępu do sieci, dysków lokalnych ani innych usług działających na urządzeniu. Dostępne są jednak te interfejsy API:
- „getRemoteData” – niezmienne dane w formie par klucz-wartość pobrane z zdalnych backendów obsługiwanych przez dewelopera (w stosownych przypadkach).
- „getLocalData” – zmienne dane w formacie klucz-wartość przechowywane lokalnie przez deweloperów, jeśli ma to zastosowanie.
- „UserData” – dane użytkownika przekazywane przez platformę.
- „getLogReader” – zwraca obiekt DAO dla tabel REQUESTS i EVENTS.
Przykład:
@Override public void onTrainingExample(
@NonNull TrainingExampleInput input,
@NonNull Consumer<TrainingExampleOutput> consumer) {
// Check if the incoming training task is the task we want.
if (input.getPopulationName() == "my_new_population") {
TrainingExampleOutput result = new TrainingExampleOutput.Builder():
RequestLogRecord record = this.getLogReader().getRequestLogRecord(1);
int count = 1;
// Iterate logging event table.
for (ContentValues contentValues: record.rows()) {
Features features = Features.newBuilder()
// Retrieve carrier from user info.
.putFeature("carrier", buildFeature(mUserData.getCarrier()))
// Retrieve features from logging info.
.putFeature("int_feature_1",
buildFeature(contentValues.get("int_feature_1")
result.addTrainingExample(
Example.newBuilder()
.setFeatures(features).build().toByteArray())
.addResumptionToken(
String.format("token%d", count).getBytes()))
.build();
count++;
}
consumer.accept(result.build());
}
}
Krok 7. Zaplanuj cykliczne zadanie trenowania.
Personalizacja na urządzeniu udostępnia deweloperom FederatedComputeScheduler do planowania i anulowania zadań obliczeń sfederowanych. Możesz wywołać go na różne sposoby za pomocą IsolatedWorker – zgodnie z harmonogramem lub po zakończeniu pobierania asynchronicznego. Przykłady znajdziesz poniżej.
Opcja oparta na harmonogramie. Zadzwoń do firmy
FederatedComputeScheduler#schedule–IsolatedWorker#onExecute.@Override public void onExecute( @NonNull ExecuteInput input, @NonNull Consumer<ExecuteOutput> consumer ) { if (input != null && input.getAppParams() != null && input.getAppParams().getString("schedule_training") != null) { if (input.getAppParams().getString("schedule_training").isEmpty()) { consumer.accept(null); return; } TrainingInterval interval = new TrainingInterval.Builder() .setMinimumInterval(Duration.ofSeconds(10)) .setSchedulingMode(2) .build(); FederatedComputeScheduler.Params params = new FederatedComputeScheduler .Params(interval); FederatedComputeInput fcInput = new FederatedComputeInput.Builder() .setPopulationName( input.getAppParams().getString("schedule_training")).build(); mFCScheduler.schedule(params, fcInput); ExecuteOutput result = new ExecuteOutput.Builder().build(); consumer.accept(result); } }Opcja Pobieranie zakończone. Wywołaj funkcję
FederatedComputeScheduler#schedulewIsolatedWorker#onDownloadCompleted, jeśli zaplanowanie zadania trenowania zależy od danych lub procesów asynchronicznych.
Weryfikacja
Poniższe kroki opisują, jak sprawdzić, czy zadanie uczenia sfederowanego działa prawidłowo.
Krok 8. Sprawdź, czy zadanie uczenia sfederowanego działa prawidłowo.
Podczas każdej rundy agregacji po stronie serwera generowany jest nowy punkt kontrolny modelu i nowy plik z danymi o metrykach.
Dane są zapisane w pliku w formacie JSON zawierającym pary klucz-wartość. Plik jest generowany na podstawie listy Metrics zdefiniowanej w kroku 3. Przykładowy plik JSON z reprezentatywnymi danymi o skuteczności:
{"server/client_work/train/binary_accuracy":0.5384615659713745, "server/client_work/train/binary_crossentropy":0.694046676158905, "server/client_work/train/recall":0.20000000298023224, "server/client_work/train/precision":0.3333333432674408, "server/client_work/train/auc-roc":0.3500000238418579, "server/client_work/train/auc-pr":0.44386863708496094, "server/finalizer/update_non_finite":0.0}
Aby uzyskać dane modelu i monitorować skuteczność trenowania, możesz użyć skryptu podobnego do tego:
import collections
import json
import matplotlib.pyplot as plt
from google.cloud import storage
# The population_name you set in fcp_server_config.json in Step 3.
POPULATION_NAME = 'my_new_population'
# The Google Cloud storage you set in Step 1.
GCS_BUCKET_NAME = 'fcp-gcs'
NUM_TRAINING_ROUND = 1000
storage_client = storage.Client()
bucket = storage_client.bucket(GCS_BUCKET_NAME)
metrics = collections.defaultdict(list)
for i in range(NUM_TRAINING_ROUND):
blob = bucket.blob('{}/{}/1/{}/s/0/metrics'.format(GCS_BUCKET_NAME, POPULATION_NAME, i+1))
with blob.open("r") as f:
metric = json.loads(f.read())
for metric_name in metric.keys():
metrics[metric_name].append(metric[metric_name])
for metric_name in metrics:
print(metric_name)
plt.plot(metrics[metric_name])
plt.show()
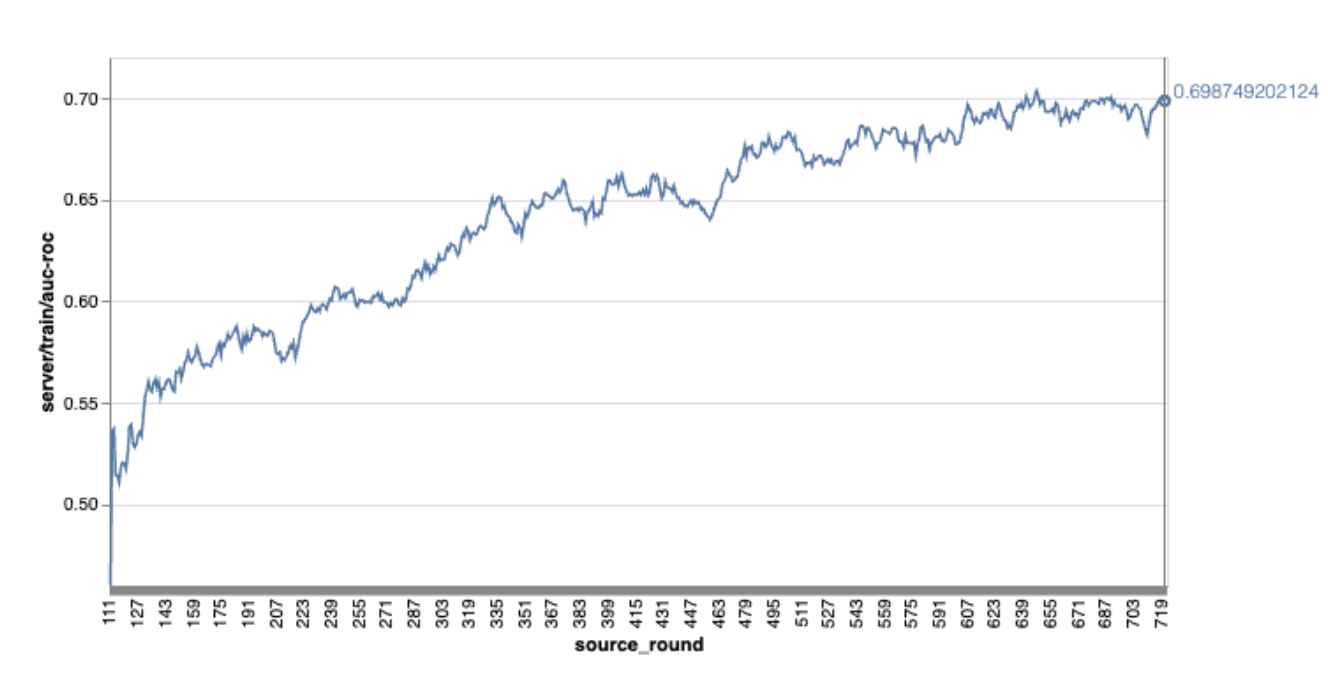
Zwróć uwagę, że na wykresie w poprzednim przykładzie:
- Oś X to liczba rund trenowania.
- Oś Y to wartość AUC-ROC w każdej rundzie.
Trenowanie modelu klasyfikacji obrazów na podstawie personalizacji na urządzeniu
W tym samouczku używamy zbioru danych EMNIST, aby pokazać, jak uruchomić zadanie sfederowanego uczenia się na platformie ODP.
Krok 1. Utwórz tff.learning.models.FunctionalModel
def get_image_classification_input_spec():
return (
tf.TensorSpec([None, 28, 28, 1], tf.float32),
tf.TensorSpec([None, 1], tf.int64),
)
def create_and_save_image_classification_functional_model(
model_path: str,
) -> None:
keras_model = emnist_models.create_original_fedavg_cnn_model(
only_digits=True
)
functional_model = tff.learning.models.functional_model_from_keras(
keras_model=keras_model,
input_spec=get_image_classification_input_spec(),
loss_fn=tf.keras.losses.SparseCategoricalCrossentropy(),
)
tff.learning.models.save_functional_model(functional_model, model_path)
- Szczegóły modelu emnist keras znajdziesz w emnist_models.
- TfLite nie obsługuje jeszcze dobrze tensorów tf.sparse.SparseTensor ani tf.RaggedTensor. Podczas tworzenia modelu staraj się jak najczęściej używać tf.Tensor.
- Kreator zadań ODP zastąpi wszystkie dane podczas tworzenia procesu uczenia się, więc nie musisz określać żadnych danych. Ten temat omówimy dokładniej w kroku 2. Utwórz konfigurację kreatora zadań.
Obsługiwane są 2 typy danych wejściowych modelu:
Typ 1. Krotka(features_tensor, label_tensor).
- Podczas tworzenia modelu specyfikacja input_spec wygląda tak:
def get_input_spec(): return ( tf.TensorSpec([None, 28, 28, 1], tf.float32), tf.TensorSpec([None, 1], tf.int64), )- Połącz powyższe z tą implementacją publicznego interfejsu API ODP IsolatedWorker#onTrainingExamples, aby generować dane do trenowania na urządzeniu:
return tf.train.Example( features=tf.train.Features( feature={ 'x': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0] * 784) ), 'y': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()Typ 2.
Tuple(Dict[feature_name, feature_tensor], label_tensor)- Podczas tworzenia modelu specyfikacja input_spec wygląda tak:
def get_input_spec() -> ( Tuple[collections.OrderedDict[str, tf.TensorSpec], tf.TensorSpec] ): return ( collections.OrderedDict( [('feature-1', tf.TensorSpec([None, 1], tf.float32)), ('feature-2', tf.TensorSpec([None, 1], tf.float32))] ), tf.TensorSpec([None, 1], tf.int64), )- Aby wygenerować dane do trenowania, połącz powyższe z tą implementacją publicznego interfejsu API ODP IsolatedWorker#onTrainingExamples:
return tf.train.Example( features=tf.train.Features( feature={ 'feature-1': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0]) ), 'feature-2': tf.train.Feature( float_list=tf.train.FloatList(value=[2.0]) ), 'my_label': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()- Nie zapomnij zarejestrować elementu label_name w konfiguracji narzędzia do tworzenia zadań.
mode: TRAINING_AND_EVAL # Task execution mode population_name: "my_example_model" label_name: "my_label"
Podczas tworzenia procesu uczenia ODP automatycznie obsługuje DP. Dlatego podczas tworzenia modelu funkcjonalnego nie trzeba dodawać żadnych szumów.
Dane wyjściowe tego zapisanego modelu funkcyjnego powinny wyglądać jak przykładowe dane w naszym repozytorium GitHub.
Krok 2. Tworzenie konfiguracji kreatora zadań
Przykłady konfiguracji narzędzia do tworzenia zadań znajdziesz w naszym repozytorium GitHub.
Wskaźniki trenowania i oceny
Dane mogą ujawniać dane użytkowników, dlatego w Kreatorze zadań będzie dostępna lista danych, które proces uczenia może generować i udostępniać. Pełną listę znajdziesz w naszym repozytorium GitHub.
Oto przykładowa lista danych podczas tworzenia nowej konfiguracji narzędzia do tworzenia zadań:
federated_learning { learning_process { metrics { name: "binary_accuracy" } metrics { name: "binary_crossentropy" } metrics { name: "recall" } metrics { name: "precision" } metrics { name: "auc-roc" } metrics { name: "auc-pr" } } }
Jeśli interesujące Cię rodzaje danych nie znajdują się na tej liście, skontaktuj się z nami.
Konfiguracje DP
Należy określić kilka konfiguracji związanych z DP:
policies { min_separation_policy { minimum_separation: 1 } model_release_policy { num_max_training_rounds: 1000 dp_target_epsilon: 10 dp_delta: 0.000001 } } differential_privacy { type: FIXED_GAUSSIAN clip_norm: 0.1 noise_multiplier: 0.1 }- Aby weryfikacja zakończyła się powodzeniem, musi być obecny warunek
dp_target_epsilonlubnoise_mulitipiler: (noise_to_epsilonepislon_to_noise). - Te ustawienia domyślne znajdziesz w naszym repozytorium GitHub.
- Aby weryfikacja zakończyła się powodzeniem, musi być obecny warunek
Krok 3. Prześlij zapisany model i konfigurację narzędzia do tworzenia zadań do dowolnego miejsca w chmurze dewelopera.
Pamiętaj, aby podczas przesyłania konfiguracji narzędzia do tworzenia zadań zaktualizować pola artifact_building.
Krok 4. (opcjonalnie) Testowanie tworzenia artefaktów bez tworzenia nowego zadania
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint}
Model próbny jest weryfikowany za pomocą sprawdzania operacji elastycznych i sprawdzania DP. Aby pominąć weryfikację, możesz dodać skip_flex_ops_check i skip_dp_check (tego modelu nie można wdrożyć w bieżącej wersji klienta ODP z powodu kilku brakujących operacji elastycznych).
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint} --skip_flex_ops_check=True --skip_dp_check=True
flex_ops_check: wbudowana biblioteka operatorów TensorFlow Lite obsługuje tylko ograniczoną liczbę operatorów TensorFlow (zgodność operatorów TensorFlow Lite i TensorFlow). Wszystkie niezgodne operacje TensorFlow muszą być zainstalowane przy użyciu delegata elastycznego (Android.bp). Jeśli model zawiera nieobsługiwane operacje, skontaktuj się z nami, aby je zarejestrować:
Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {...}Najlepszym sposobem na debugowanie narzędzia do tworzenia zadań jest uruchomienie go lokalnie:
# Starts a server at localhost:5000 bazel run //python/taskbuilder:task_builder # Links to a server at localhost:5000 by removing task_builder_server flag bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --skip_flex_ops_check=True --skip_dp_check=True
Wynikowe artefakty znajdziesz w miejscu w Cloud Storage określonym w konfiguracji. Powinien on wyglądać podobnie do przykładu w naszym repozytorium GitHub.
Krok 5. Utwórz artefakty i na serwerze FCP utwórz nową parę zadań szkoleniowych i oceniających.
Usuń flagę build_artifact_only, a zbudowane artefakty zostaną przesłane na serwer FCP. Sprawdź, czy para zadań trenowania i oceny została utworzona.
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config.pbtxt --task_builder_server=${task_builder_server_endpoint}
Krok 6. Przygotowanie do korzystania z FCP po stronie klienta
- Wdrożyć publiczny interfejs API platformy ODP
IsolatedWorker#onTrainingExamples, aby generować dane treningowe. - Zadzwoń pod numer
FederatedComputeScheduler#schedule. - Kilka przykładów znajdziesz w naszym repozytorium kodu źródłowego Androida.
Krok 7. Monitorowanie
Dane dotyczące serwera
Instrukcje konfiguracji znajdziesz w naszym repozytorium GitHub.
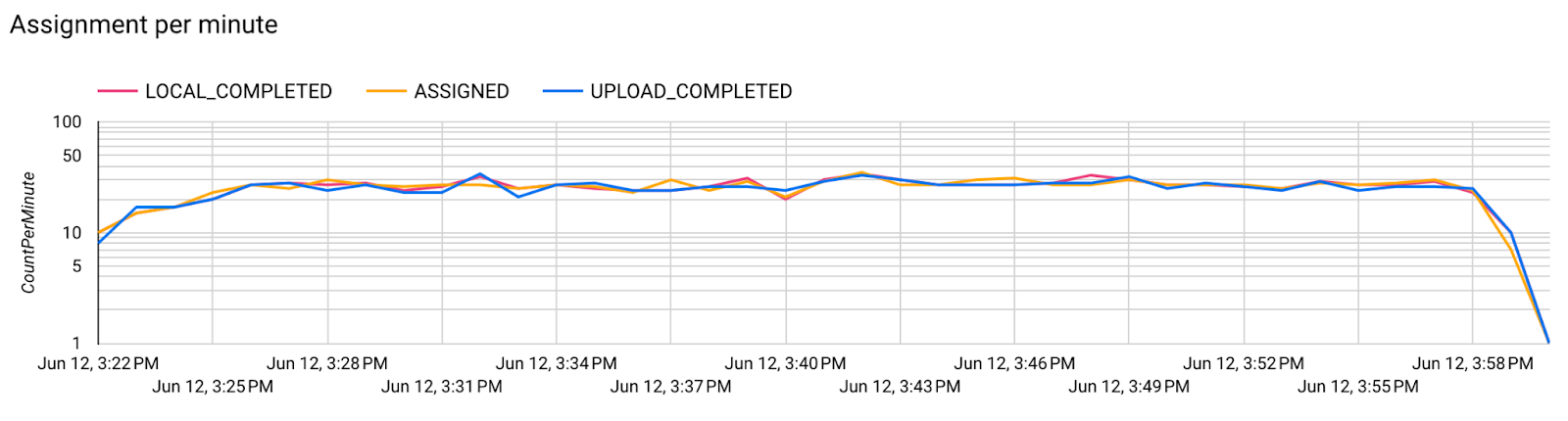
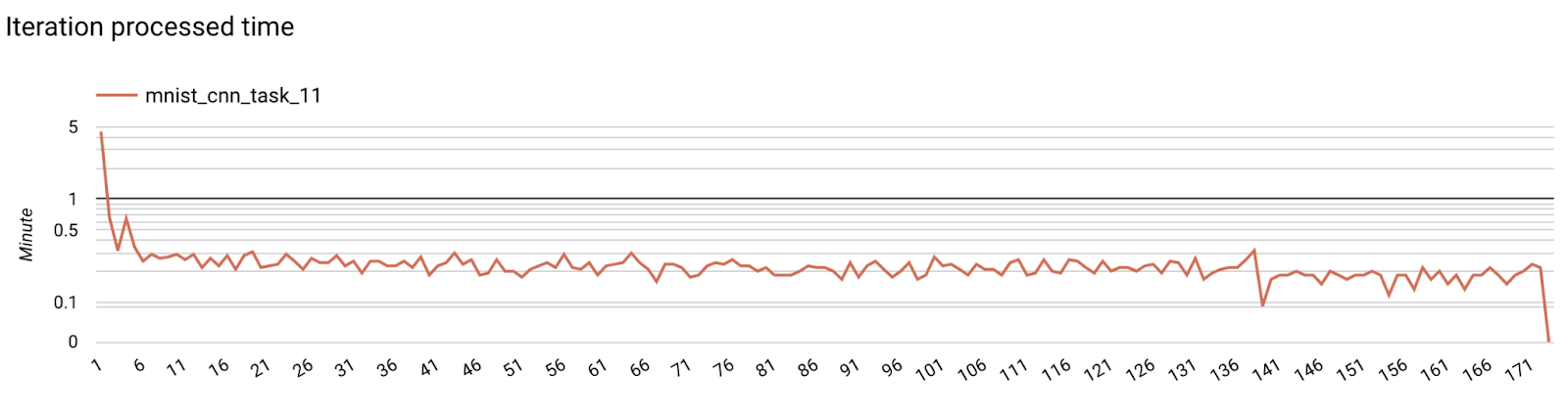
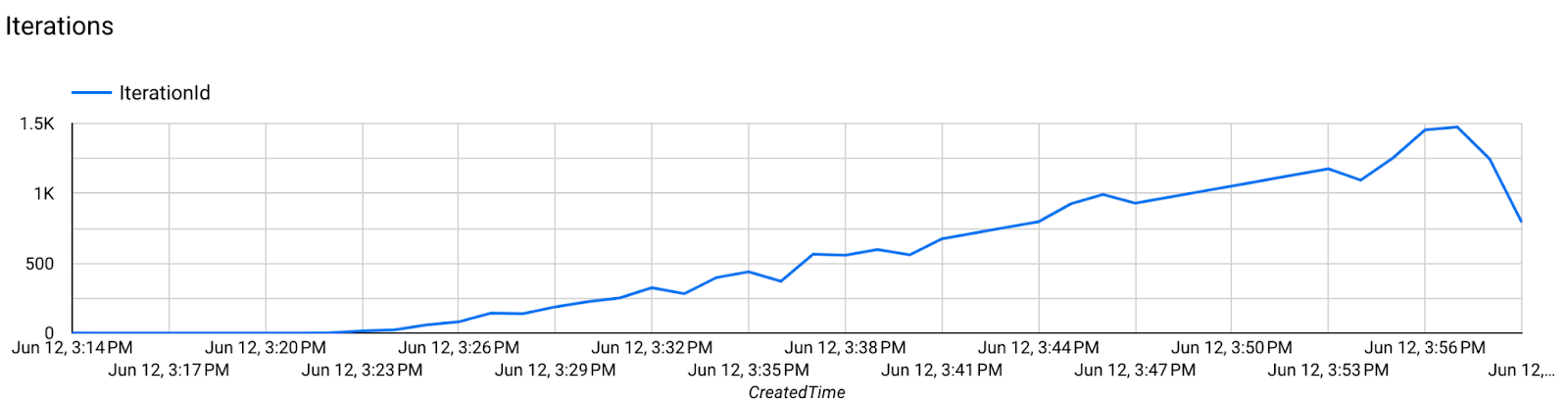
- Wskaźniki dotyczące modelu
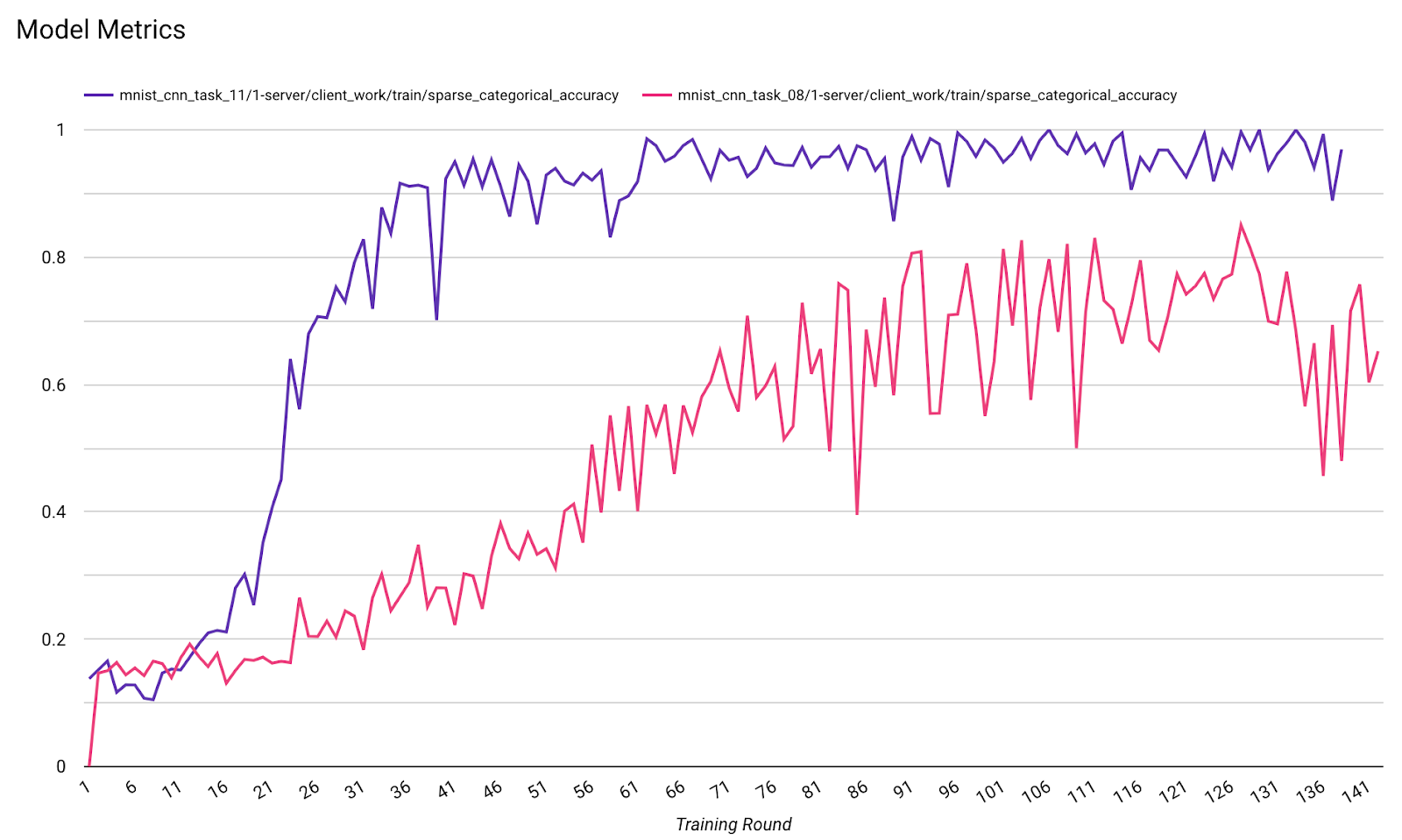
W jednym diagramie można porównać dane z różnych przebiegów. Na przykład:
- Fioletowa linia to
noise_multiplier0,1 - Różowa linia ma wartość
noise_multipiler0,3.