
Halaman ini menjelaskan cara menggunakan Federated Learning API yang disediakan oleh Personalisasi di Perangkat untuk melatih model dengan proses pembelajaran rata-rata gabungan dan derau Gaussian tetap.
Sebelum memulai
Sebelum memulai, selesaikan langkah-langkah berikut di perangkat pengujian Anda:
Pastikan modul OnDevicePersonalization diinstal. Modul ini tersedia sebagai update otomatis pada April 2024.
# List the modules installed on the device adb shell pm list packages --apex-only --show-versioncodePastikan modul berikut tercantum dengan kode versi 341717000 atau yang lebih tinggi:
package:com.google.android.ondevicepersonalization versionCode:341717000Jika modul tersebut tidak tercantum, buka Setelan > Keamanan & privasi > Update > Update sistem Google Play untuk memastikan perangkat Anda sudah diupdate. Pilih Update sesuai kebutuhan.
Mengaktifkan semua fitur baru terkait Federated Learning.
# Enable On-Device Personalization apk. adb shell device_config put on_device_personalization global_kill_switch false # Enable On-Device Personalization APIs. adb shell device_config put on_device_personalization enable_ondevicepersonalization_apis true # Enable On-Device Personalization overriding. adb shell device_config put on_device_personalization enable_personalization_status_override true adb shell device_config put on_device_personalization personalization_status_override_value true # Enable Federated Compute apk. adb shell device_config put on_device_personalization federated_compute_kill_switch false
Membuat tugas Federated Learning

Angka dalam diagram dijelaskan secara lebih mendetail dalam delapan langkah berikut.
Mengonfigurasi Server Federated Compute
Federated Learning adalah map-reduce yang berjalan di Server Federated Compute (reducer) dan sekumpulan klien (mapper). Server Federated Compute menyimpan informasi model dan metadata yang sedang berjalan dari setiap tugas Federated Learning. Pada dasarnya:
- Developer Federated Learning membuat tugas baru dan mengupload metadata yang menjalankan tugas dan informasi model ke server.
- Saat klien Federated Compute memulai permintaan penetapan tugas baru ke server, server akan memeriksa kelayakan tugas dan menampilkan informasi tugas yang memenuhi syarat.
- Setelah klien Federated Compute menyelesaikan komputasi lokal, klien akan mengirimkan hasil komputasi ini ke server. Server kemudian melakukan agregasi dan penambahan derau pada hasil komputasi ini serta menerapkan hasilnya ke model akhir.
Untuk mempelajari lebih lanjut konsep ini, lihat:
- Federated Learning: Machine Learning Kolaboratif tanpa Data Pelatihan Terpusat
- Menuju Federated Learning dalam Skala Besar: Desain Sistem (SysML 2019)
ODP menggunakan versi yang ditingkatkan dari Federated Learning, yang menerapkan derau terkalibrasi (terpusat) ke agregat sebelum diterapkan ke model. Skala derau memastikan bahwa agregat mempertahankan privasi diferensial.
Langkah 1. Membuat Server Federated Compute
Ikuti petunjuk di project Federated Compute untuk menyiapkan Server Federated Compute Anda sendiri.
Langkah 2. Menyiapkan Saved FunctionalModel
Siapkan file 'FunctionalModel' tersimpan. Anda dapat menggunakan 'functional_model_from_keras' untuk mengonversi 'Model' menjadi 'FunctionalModel' dan menggunakan 'save_functional_model' untuk melakukan serialisasi 'FunctionalModel' ini sebagai 'SavedModel'.
functional_model = tff.learning.models.functional_model_from_keras(keras_model=model)
tff.learning.models.save_functional_model(functional_model, saved_model_path)
Langkah 3. Membuat konfigurasi Server Federated Compute
Siapkan fcp_server_config.json yang mencakup kebijakan, penyiapan federated learning, dan penyiapan privasi diferensial. Contoh:
# Identifies the set of client devices that will participate.
population_name: "my_new_population"
# Options you can choose:
# * TRAINING_ONLY: Only one training task will be generated under this
# population.
# * TRAINING_AND_EVAL: One training task and one evaluation task will be
# generated under this population.
# * EVAL_ONLY: Only one evaluation task will be generated under this
# population.
mode: TRAINING_AND_EVAL
policies {
# Policy for sampling on-device examples. It is checked every time a
# device attempts to start a new training.
min_separation_policy {
# The minimum number of rounds before the same client participated.
minimum_separation: 3
}
# Policy for releasing training results to developers. It is checked
# when uploading a new task to the Federated Compute Server.
model_release_policy {
# Server stops training when number of training rounds reaches this
# number.
num_max_training_rounds: 1000
}
}
# Federated learning setups. They are applied inside Task Builder.
federated_learning {
learning_process {
# Use FED_AVG to build federated learning process. Options you can
# choose:
# * FED_AVG: Federated Averaging algorithm
# (https://arxiv.org/abs/2003.00295)
# * FED_SDG: Federated SGD algorithm
# (https://arxiv.org/abs/1602.05629)
type: FED_AVG
# Optimizer used at client side training. Options you can choose:
# * ADAM
# * SGD
client_optimizer: SGD
# Learning rate used at client side training.
client_learning_rate: 0.01
# Optimizer used at server side training. Options you can choose:
# * ADAM
# * SGD
server_optimizer: ADAM
# Learning rate used at server side training.
sever_learning_rate: 1
runtime_config {
# Number of participating devices for each round of training.
report_goal: 2000
}
# List of metrics to be evaluated by the model during training and
# evaluation. Federated Compute Server provides a list of allowed
# metrics.
metrics {
name: "auc-roc"
}
metrics {
name: "binary_accuracy"
}
}
# Whether or not to generate a corresponding evaluation task under the same
# population. If this field isn't set, only one training task is
# generated under this population.
evaluation {
# The task id under the same population of the source training task that
# this evaluation task evaluates.
source_training_task_id: 1
# Decides how checkpoints from the training task are chosen for
# evaluation.
# * every_k_round: the evaluation task randomly picks one checkpoint
# from the past k rounds of training task checkpoints.
# * every_k_hour: the evaluation task randomly picks one checkpoint
# from the past k hours of training task checkpoints.
checkpoint_selector: "every_1_round"
# The traffic of this evaluation task in this population.
evaluation_traffic: 0.1
# Number of participating devices for each round of evaluation.
report_goal: 200
}
}
# Differential Privacy setups. They are applied inside the Task Builder.
differential_privacy {
# The DP aggregation algorithm you want to use. Options you can choose:
# * FIXED_GAUSSIAN: Federated Learning DP-SGD with fixed clipping norm
# described in "Learning Differentially Private Recurrent
# Language Models" (https://arxiv.org/abs/1710.06963).
# * ADAPTIVE_GAUSSIAN: Federated Learning DP-SGD with quantile-based clip
# norm estimation described in "Differentially Private
# Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
# * TREE: DP-FTRL algorithm described in "Practical and Private (Deep)
# Learning without Sampling or Shuffling"
# (https://arxiv.org/abs/2103.00039).
# * ADADPTIVE_TREE: DP-FTRL with adaptive clipping norm descirbed in
# "Differentially Private Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
type: FIXED_GAUSSIAN
# Noise multiplier for the Gaussian noise.
noise_multiplier: 0.1
# The value of the clipping norm.
clip_norm: 0.1
}
Langkah 4. Kirimkan konfigurasi zip ke server Federated Compute.
Kirimkan file zip dan fcp_server_config.json ke server Federated Compute.
task_builder_client --task_builder_server='http://{federated_compute_server_endpoint}' --saved_model='saved_model' --task_config='fcp_server_config.json'
Endpoint Federated Compute Server adalah server yang Anda siapkan pada langkah 1.
Library operator bawaan LiteRT hanya mendukung sejumlah operator TensorFlow tertentu (Pilih operator TensorFlow). Set operator yang didukung dapat bervariasi di berbagai versi modul OnDevicePersonalization. Untuk memastikan kompatibilitas, proses verifikasi operator dilakukan dalam pembuat tugas selama pembuatan tugas.
Versi modul OnDevicePersonalization minimum yang didukung akan disertakan dalam metadata tugas. Informasi ini dapat ditemukan di pesan info pembuat tugas.
I1023 22:16:53.058027 139653371516736 task_builder_client.py:109] Success! Tasks are built, and artifacts are uploaded to the cloud. I1023 22:16:53.058399 139653371516736 task_builder_client.py:112] applied_algorithms { learning_algo: FED_AVG client_optimizer: SGD server_optimizer: SGD dp_aggregator: FIXED_GAUSSIAN } metric_results { accepted_metrics: "binary_accuracy, binary_crossentropy, recall, precision, auc-roc, auc-pr" } dp_hyperparameters { dp_delta: 0.000001 dp_epsilon: 6.4 noise_multiplier: 1.0 dp_clip_norm: 1.0 num_training_rounds: 10000 } I1023 22:16:53.058594 139653371516736 task_builder_client.py:113] training_task { min_client_version: "341912000" } eval_task { min_client_version: "341812000" }Server Federated Compute akan menetapkan tugas ini ke semua perangkat yang dilengkapi dengan modul OnDevicePersonalization dengan versi yang lebih tinggi dari 341812000.
Jika model Anda menyertakan operasi yang tidak didukung oleh modul OnDevicePersonalization, pesan error akan dibuat selama pembuatan tugas.
common.TaskBuilderException: Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {'L2Loss': 'L2LossOp<CPUDevice, float>'} . Stop building remaining artifacts.Anda dapat menemukan daftar lengkap operasi fleksibel yang didukung di GitHub.
Membuat APK Android Federated Compute
Untuk membuat APK Federated Compute Android, Anda harus menentukan endpoint URL Server Federated Compute di AndroidManifest.xml, yang terhubung ke Klien Federated Compute Anda.
Langkah 5. Menentukan endpoint URL Server Federated Compute
Tentukan endpoint URL Server Federated Compute (yang Anda siapkan pada Langkah 1) di AndroidManifest.xml, yang terhubung ke Federated Compute Client Anda.
<!-- Contents of AndroidManifest.xml -->
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.odpsample" >
<application android:label="OdpSample">
<!-- XML resource that contains other ODP settings. -->
<property android:name="android.ondevicepersonalization.ON_DEVICE_PERSONALIZATION_CONFIG"
android:resource="@xml/OdpSettings"></property>
<!-- The service that ODP will bind to. -->
<service android:name="com.example.odpsample.SampleService"
android:exported="true" android:isolatedProcess="true" />
</application>
</manifest>
File resource XML yang ditentukan dalam tag <property> juga harus mendeklarasikan class layanan dalam tag <service>, dan menentukan endpoint URL Server Komputasi Gabungan yang akan dihubungkan oleh Klien komputasi gabungan:
<!-- Contents of res/xml/OdpSettings.xml -->
<on-device-personalization>
<!-- Name of the service subclass -->
<service name="com.example.odpsample.SampleService">
<!-- If you want to use federated compute feature to train a model,
specify this tag. -->
<federated-compute-settings url="https://fcpserver.com/" />
</service>
</on-device-personalization>
Langkah 6. Mengimplementasikan API IsolatedWorker#onTrainingExample
Terapkan API publik Personalisasi Di Perangkat IsolatedWorker#onTrainingExample untuk membuat data pelatihan.
Kode yang berjalan di IsolatedProcess tidak memiliki akses langsung ke jaringan, disk lokal, atau layanan lain yang berjalan di perangkat; namun, API berikut tersedia:
- 'getRemoteData' - Data nilai kunci yang tidak dapat diubah yang didownload dari backend jarak jauh yang dioperasikan developer, jika berlaku.
- 'getLocalData' - Data nilai kunci yang dapat diubah dan dipertahankan secara lokal oleh developer, jika berlaku.
- 'UserData' - Data pengguna yang disediakan oleh platform.
- 'getLogReader' - Menampilkan DAO untuk tabel REQUESTS dan EVENTS.
Contoh:
@Override public void onTrainingExample(
@NonNull TrainingExampleInput input,
@NonNull Consumer<TrainingExampleOutput> consumer) {
// Check if the incoming training task is the task we want.
if (input.getPopulationName() == "my_new_population") {
TrainingExampleOutput result = new TrainingExampleOutput.Builder():
RequestLogRecord record = this.getLogReader().getRequestLogRecord(1);
int count = 1;
// Iterate logging event table.
for (ContentValues contentValues: record.rows()) {
Features features = Features.newBuilder()
// Retrieve carrier from user info.
.putFeature("carrier", buildFeature(mUserData.getCarrier()))
// Retrieve features from logging info.
.putFeature("int_feature_1",
buildFeature(contentValues.get("int_feature_1")
result.addTrainingExample(
Example.newBuilder()
.setFeatures(features).build().toByteArray())
.addResumptionToken(
String.format("token%d", count).getBytes()))
.build();
count++;
}
consumer.accept(result.build());
}
}
Langkah 7. Menjadwalkan tugas pelatihan berulang.
Personalisasi Di Perangkat menyediakan FederatedComputeScheduler bagi developer untuk menjadwalkan atau membatalkan tugas komputasi gabungan. Ada berbagai opsi untuk memanggilnya melalui IsolatedWorker, baik berdasarkan jadwal atau saat download asinkron selesai. Contoh keduanya ada di bawah.
Opsi Berbasis Jadwal. Hubungi
FederatedComputeScheduler#schedulediIsolatedWorker#onExecute.@Override public void onExecute( @NonNull ExecuteInput input, @NonNull Consumer<ExecuteOutput> consumer ) { if (input != null && input.getAppParams() != null && input.getAppParams().getString("schedule_training") != null) { if (input.getAppParams().getString("schedule_training").isEmpty()) { consumer.accept(null); return; } TrainingInterval interval = new TrainingInterval.Builder() .setMinimumInterval(Duration.ofSeconds(10)) .setSchedulingMode(2) .build(); FederatedComputeScheduler.Params params = new FederatedComputeScheduler .Params(interval); FederatedComputeInput fcInput = new FederatedComputeInput.Builder() .setPopulationName( input.getAppParams().getString("schedule_training")).build(); mFCScheduler.schedule(params, fcInput); ExecuteOutput result = new ExecuteOutput.Builder().build(); consumer.accept(result); } }Opsi Download Selesai. Panggil
FederatedComputeScheduler#schedulediIsolatedWorker#onDownloadCompletedjika penjadwalan tugas pelatihan bergantung pada data atau proses asinkron.
Validasi
Langkah-langkah berikut menjelaskan cara memvalidasi apakah tugas Federated Learning berjalan dengan benar.
Langkah 8. Validasi apakah tugas Federated Learning berjalan dengan baik.
Checkpoint model baru dan file metrik baru dibuat di setiap putaran agregasi sisi server.
Metrik berada dalam file berformat JSON dari pasangan nilai kunci. File dibuat oleh daftar Metrics yang Anda tentukan di Langkah 3. Contoh file JSON metrik representatif adalah sebagai berikut:
{"server/client_work/train/binary_accuracy":0.5384615659713745, "server/client_work/train/binary_crossentropy":0.694046676158905, "server/client_work/train/recall":0.20000000298023224, "server/client_work/train/precision":0.3333333432674408, "server/client_work/train/auc-roc":0.3500000238418579, "server/client_work/train/auc-pr":0.44386863708496094, "server/finalizer/update_non_finite":0.0}
Anda dapat menggunakan sesuatu yang mirip dengan skrip berikut untuk mendapatkan metrik model dan memantau performa pelatihan:
import collections
import json
import matplotlib.pyplot as plt
from google.cloud import storage
# The population_name you set in fcp_server_config.json in Step 3.
POPULATION_NAME = 'my_new_population'
# The Google Cloud storage you set in Step 1.
GCS_BUCKET_NAME = 'fcp-gcs'
NUM_TRAINING_ROUND = 1000
storage_client = storage.Client()
bucket = storage_client.bucket(GCS_BUCKET_NAME)
metrics = collections.defaultdict(list)
for i in range(NUM_TRAINING_ROUND):
blob = bucket.blob('{}/{}/1/{}/s/0/metrics'.format(GCS_BUCKET_NAME, POPULATION_NAME, i+1))
with blob.open("r") as f:
metric = json.loads(f.read())
for metric_name in metric.keys():
metrics[metric_name].append(metric[metric_name])
for metric_name in metrics:
print(metric_name)
plt.plot(metrics[metric_name])
plt.show()
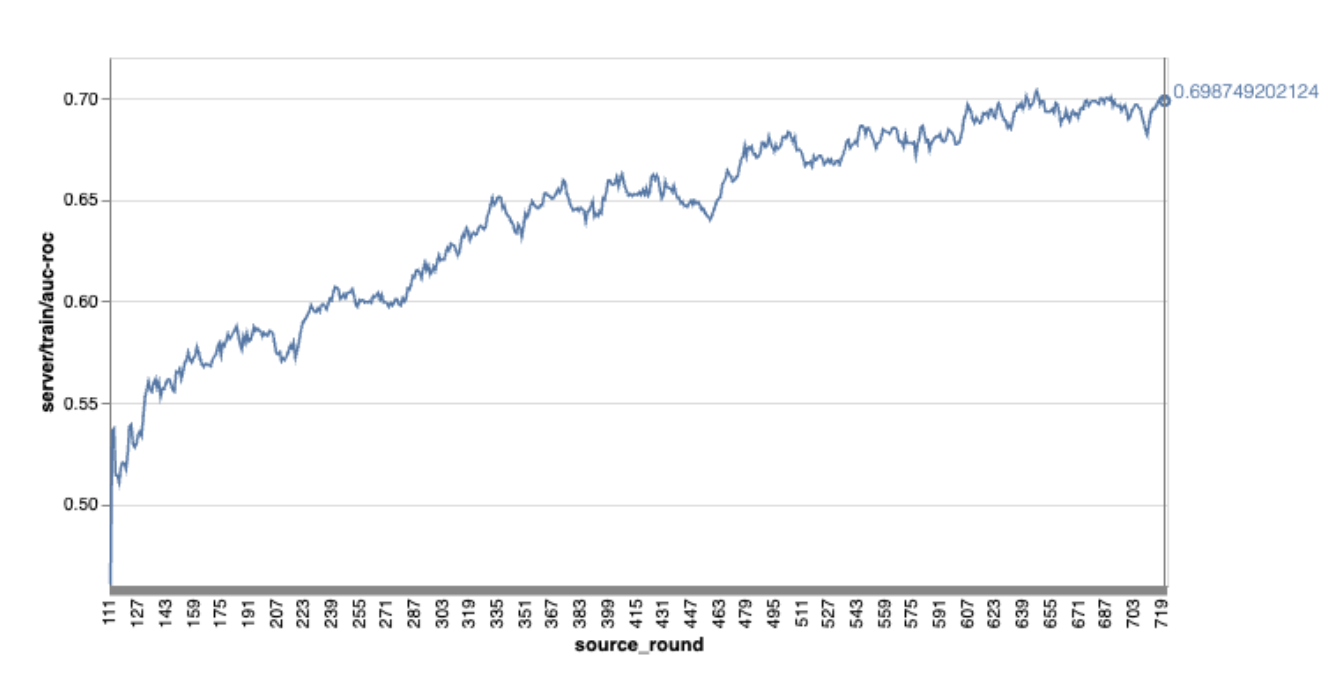
Perhatikan bahwa dalam grafik contoh sebelumnya:
- Sumbu x adalah jumlah pelatihan putaran.
- Sumbu y adalah nilai auc-roc setiap putaran.
Melatih Model Klasifikasi Gambar untuk Personalisasi di Perangkat
Dalam tutorial ini, set data EMNIST digunakan untuk menunjukkan cara menjalankan tugas federated learning di ODP.
Langkah 1. Membuat tff.learning.models.FunctionalModel
def get_image_classification_input_spec():
return (
tf.TensorSpec([None, 28, 28, 1], tf.float32),
tf.TensorSpec([None, 1], tf.int64),
)
def create_and_save_image_classification_functional_model(
model_path: str,
) -> None:
keras_model = emnist_models.create_original_fedavg_cnn_model(
only_digits=True
)
functional_model = tff.learning.models.functional_model_from_keras(
keras_model=keras_model,
input_spec=get_image_classification_input_spec(),
loss_fn=tf.keras.losses.SparseCategoricalCrossentropy(),
)
tff.learning.models.save_functional_model(functional_model, model_path)
- Anda dapat menemukan detail model emnist keras di emnist_models.
- TfLite belum memiliki dukungan yang baik untuk tf.sparse.SparseTensor atau tf.RaggedTensor. Coba gunakan tf.Tensor sebanyak mungkin saat membangun model.
- Pembuat Tugas ODP akan mengganti semua metrik saat membangun proses pembelajaran, sehingga tidak perlu menentukan metrik apa pun. Topik tersebut akan dibahas lebih lanjut di Langkah 2. Buat konfigurasi builder tugas.
Dua jenis input model yang didukung:
Jenis 1. Tuple(features_tensor, label_tensor).
- Saat membuat model, input_spec akan terlihat seperti:
def get_input_spec(): return ( tf.TensorSpec([None, 28, 28, 1], tf.float32), tf.TensorSpec([None, 1], tf.int64), )- Gabungkan kode di atas dengan penerapan ODP public API IsolatedWorker#onTrainingExamples berikut untuk menghasilkan data pelatihan di perangkat:
return tf.train.Example( features=tf.train.Features( feature={ 'x': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0] * 784) ), 'y': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()Jenis 2.
Tuple(Dict[feature_name, feature_tensor], label_tensor)- Saat membuat model, input_spec akan terlihat seperti:
def get_input_spec() -> ( Tuple[collections.OrderedDict[str, tf.TensorSpec], tf.TensorSpec] ): return ( collections.OrderedDict( [('feature-1', tf.TensorSpec([None, 1], tf.float32)), ('feature-2', tf.TensorSpec([None, 1], tf.float32))] ), tf.TensorSpec([None, 1], tf.int64), )- Gabungkan kode di atas dengan penerapan API publik ODP IsolatedWorker#onTrainingExamples berikut untuk menghasilkan data pelatihan:
return tf.train.Example( features=tf.train.Features( feature={ 'feature-1': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0]) ), 'feature-2': tf.train.Feature( float_list=tf.train.FloatList(value=[2.0]) ), 'my_label': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()- Jangan lupa untuk mendaftarkan label_name dalam konfigurasi pembuat tugas.
mode: TRAINING_AND_EVAL # Task execution mode population_name: "my_example_model" label_name: "my_label"
ODP menangani DP secara otomatis saat membangun proses pembelajaran. Jadi, tidak perlu menambahkan derau saat membuat model fungsional.
Output model fungsional yang disimpan ini akan terlihat seperti contoh di repositori GitHub kami.
Langkah 2. Buat konfigurasi pembuat tugas
Anda dapat menemukan contoh konfigurasi pembuat tugas di repositori GitHub kami.
Metrik pelatihan dan evaluasi
Mengingat metrik dapat membocorkan data pengguna, Pembuat Tugas akan memiliki daftar metrik yang dapat dihasilkan dan dirilis oleh proses pembelajaran. Anda dapat menemukan daftar lengkap di repositori GitHub kami.
Berikut adalah contoh daftar metrik saat membuat konfigurasi pembuat tugas baru:
federated_learning { learning_process { metrics { name: "binary_accuracy" } metrics { name: "binary_crossentropy" } metrics { name: "recall" } metrics { name: "precision" } metrics { name: "auc-roc" } metrics { name: "auc-pr" } } }
Jika metrik yang Anda minati tidak ada dalam daftar saat ini, hubungi kami.
Konfigurasi DP
Ada beberapa konfigurasi terkait DP yang perlu ditentukan:
policies { min_separation_policy { minimum_separation: 1 } model_release_policy { num_max_training_rounds: 1000 dp_target_epsilon: 10 dp_delta: 0.000001 } } differential_privacy { type: FIXED_GAUSSIAN clip_norm: 0.1 noise_multiplier: 0.1 }dp_target_epsilonataunoise_mulitipilerada untuk lulus validasi: (noise_to_epsilonepislon_to_noise).- Anda dapat menemukan setelan default ini di repositori GitHub kami.
Langkah 3. Mengupload model tersimpan dan konfigurasi pembuat tugas ke penyimpanan cloud developer mana pun
Jangan lupa untuk memperbarui kolom artifact_building saat mengupload konfigurasi pembuat tugas.
Langkah 4. (opsional) Menguji pembuatan artefak tanpa membuat tugas baru
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint}
Model contoh divalidasi melalui pemeriksaan operasi fleksibel dan pemeriksaan DP; Anda dapat menambahkan skip_flex_ops_check dan skip_dp_check untuk melewati validasi (model ini tidak dapat di-deploy ke klien ODP versi saat ini karena beberapa operasi fleksibel tidak ada).
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint} --skip_flex_ops_check=True --skip_dp_check=True
flex_ops_check: library operator bawaan TensorFlow Lite hanya mendukung sejumlah kecil operator TensorFlow (Kompatibilitas operator TensorFlow Lite dan TensorFlow). Semua operasi tensorflow yang tidak kompatibel harus diinstal menggunakan delegasi flex (Android.bp). Jika model berisi operasi yang tidak didukung, hubungi kami untuk mendaftarkannya:
Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {...}Cara terbaik untuk men-debug pembuat tugas adalah dengan memulai tugas secara lokal:
# Starts a server at localhost:5000 bazel run //python/taskbuilder:task_builder # Links to a server at localhost:5000 by removing task_builder_server flag bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --skip_flex_ops_check=True --skip_dp_check=True
Anda dapat menemukan artefak yang dihasilkan di penyimpanan cloud yang ditentukan dalam konfigurasi. Seharusnya terlihat seperti contoh di repositori GitHub kami.
Langkah 5. Bangun artefak dan buat pasangan baru tugas pelatihan dan evaluasi di server FCP.
Hapus tanda build_artifact_only dan artefak yang dibuat akan diupload ke server FCP. Anda harus memeriksa apakah pasangan tugas pelatihan dan evaluasi berhasil dibuat
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config.pbtxt --task_builder_server=${task_builder_server_endpoint}
Langkah 6. Menyiapkan sisi klien FCP
- Terapkan ODP public API
IsolatedWorker#onTrainingExamplesuntuk membuat data pelatihan. - Panggil
FederatedComputeScheduler#schedule. - Temukan beberapa contoh di repositori sumber Android kami.
Langkah 7. Pemantauan
Metrik server
Temukan petunjuk penyiapan di repositori GitHub kami.
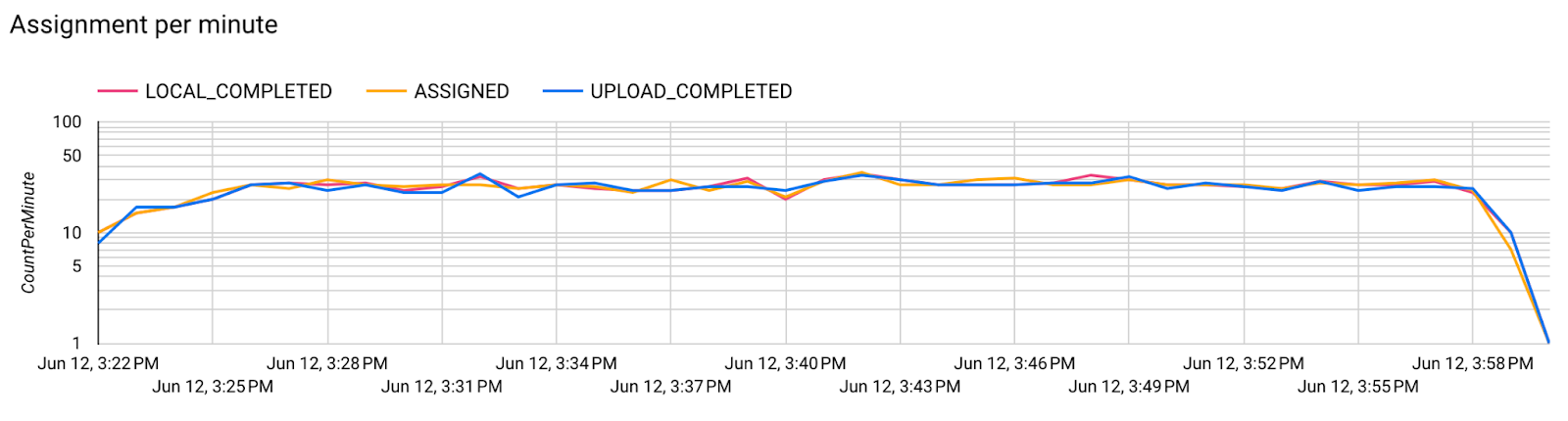
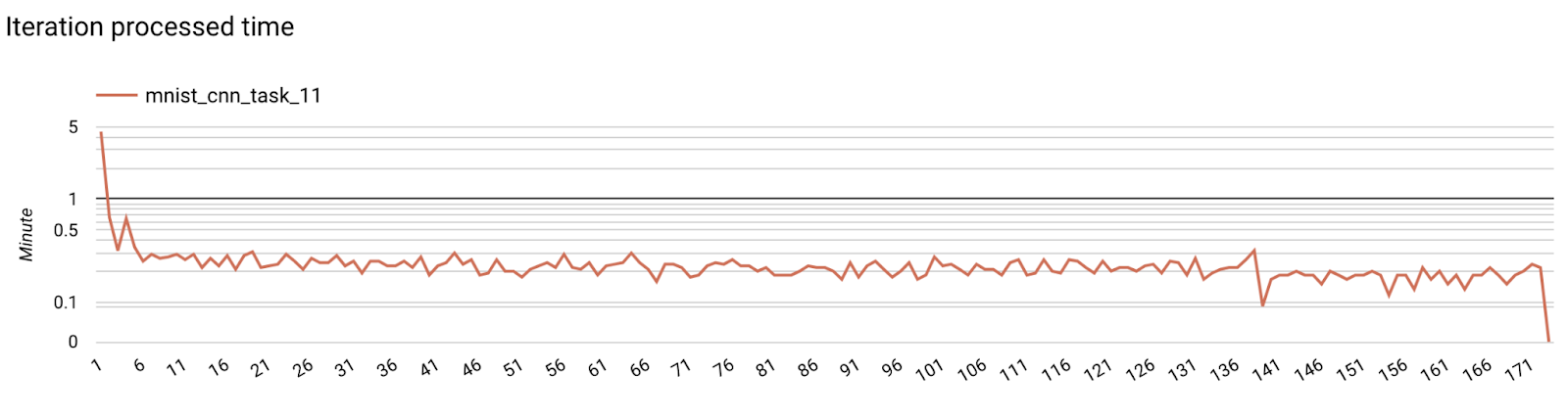
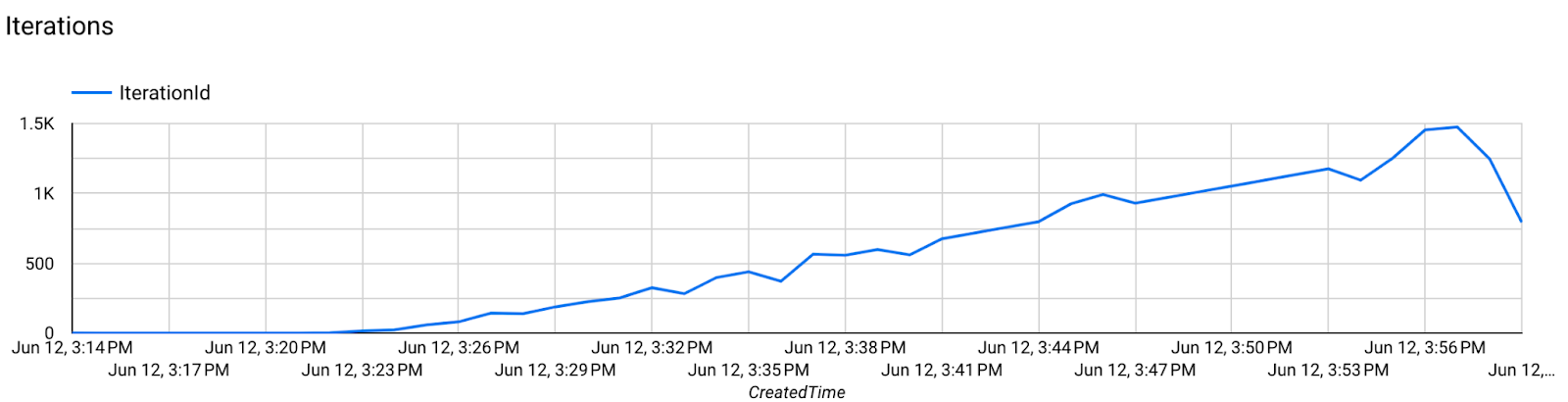
- Metrik Model
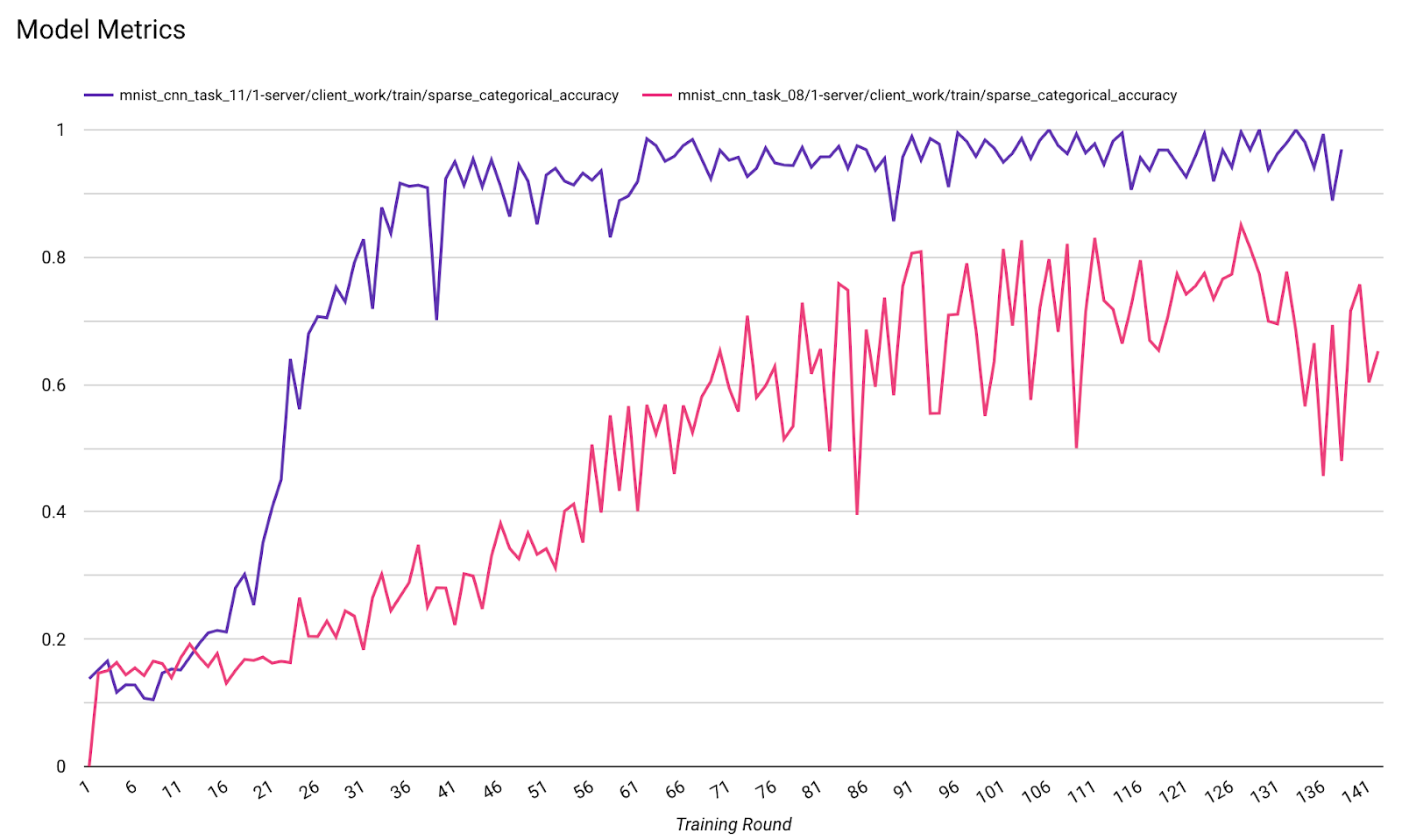
Anda dapat membandingkan metrik dari proses yang berbeda dalam satu diagram. Contoh:
- Garis ungu adalah dengan
noise_multiplier0,1 - Garis merah muda adalah dengan
noise_multipiler0,3