
این صفحه نحوه کار با APIهای یادگیری فدرال ارائه شده توسط On-Device Personalization را برای آموزش یک مدل با فرآیند یادگیری میانگین فدرال و نویز گاوسی ثابت شرح میدهد.
قبل از اینکه شروع کنی
قبل از شروع، مراحل زیر را روی دستگاه آزمایشی خود انجام دهید:
مطمئن شوید که ماژول OnDevicePersonalization نصب شده است. این ماژول در آوریل 2024 به عنوان یک بهروزرسانی خودکار در دسترس قرار گرفت.
# List the modules installed on the device adb shell pm list packages --apex-only --show-versioncodeمطمئن شوید که ماژول زیر با کد نسخه 341717000 یا بالاتر فهرست شده است:
package:com.google.android.ondevicepersonalization versionCode:341717000اگر آن ماژول در فهرست نیست، برای اطمینان از بهروز بودن دستگاه خود، به تنظیمات > امنیت و حریم خصوصی > بهروزرسانیها > بهروزرسانی سیستم گوگل پلی بروید. در صورت لزوم، بهروزرسانی را انتخاب کنید.
فعال کردن تمام ویژگیهای جدید مرتبط با Fedrated Learning.
# Enable On-Device Personalization apk. adb shell device_config put on_device_personalization global_kill_switch false # Enable On-Device Personalization APIs. adb shell device_config put on_device_personalization enable_ondevicepersonalization_apis true # Enable On-Device Personalization overriding. adb shell device_config put on_device_personalization enable_personalization_status_override true adb shell device_config put on_device_personalization personalization_status_override_value true # Enable Federated Compute apk. adb shell device_config put on_device_personalization federated_compute_kill_switch false
ایجاد یک وظیفه یادگیری فدرال

اعداد موجود در نمودار در هشت مرحله زیر با جزئیات بیشتری توضیح داده شدهاند.
پیکربندی یک سرور محاسباتی فدرال
یادگیری فدرال یک نگاشت-کاهش است که روی سرور محاسبات فدرال (کاهشدهنده) و مجموعهای از کلاینتها (نگاشتکنندهها) اجرا میشود. سرور محاسبات فدرال، فرادادههای در حال اجرا و اطلاعات مدل هر وظیفه یادگیری فدرال را نگهداری میکند. در سطح بالا:
- یک توسعهدهنده Federated Learning یک وظیفه جدید ایجاد میکند و فرادادههای اجرای وظیفه و اطلاعات مدل را روی سرور آپلود میکند.
- وقتی یک کلاینت Federated Compute درخواست انتساب وظیفه جدیدی را به سرور ارسال میکند، سرور واجد شرایط بودن وظیفه را بررسی کرده و اطلاعات وظیفه واجد شرایط را برمیگرداند.
- زمانی که یک کلاینت Federated Compute محاسبات محلی را به پایان میرساند، نتایج محاسبات را به سرور ارسال میکند. سپس سرور روی این نتایج محاسبات، تجمیع و نویزگیری انجام میدهد و نتیجه را در مدل نهایی اعمال میکند.
برای آشنایی بیشتر با این مفاهیم، به موارد زیر توجه کنید:
- یادگیری فدرال: یادگیری ماشین مشارکتی بدون دادههای آموزشی متمرکز
- به سوی یادگیری فدرال در مقیاس: طراحی سیستم (SysML 2019)
ODP از یک نسخه بهبود یافته از یادگیری فدرال استفاده میکند، که در آن نویز کالیبره شده (متمرکز) قبل از اعمال به مدل، به مجموعها اعمال میشود. مقیاس نویز تضمین میکند که مجموعها حریم خصوصی تفاضلی را حفظ میکنند.
مرحله ۱. ایجاد یک سرور محاسباتی فدرال
برای راهاندازی سرور محاسبات فدرال خودتان، دستورالعملهای موجود در پروژه محاسبات فدرال را دنبال کنید.
مرحله ۲. آمادهسازی یک FunctionalModel ذخیرهشده
یک فایل 'FunctionalModel' ذخیره شده آماده کنید. میتوانید از 'functional_model_from_keras' برای تبدیل یک 'Model' به 'FunctionalModel' استفاده کنید و از 'save_functional_model' برای سریالایز کردن این 'FunctionalModel' به عنوان 'SavedModel' استفاده کنید.
functional_model = tff.learning.models.functional_model_from_keras(keras_model=model)
tff.learning.models.save_functional_model(functional_model, saved_model_path)
مرحله ۳. ایجاد پیکربندی سرور محاسباتی فدرال
یک fcp_server_config.json آماده کنید که شامل سیاستها، تنظیمات یادگیری فدرال و تنظیمات حریم خصوصی دیفرانسیل باشد. مثال:
# Identifies the set of client devices that will participate.
population_name: "my_new_population"
# Options you can choose:
# * TRAINING_ONLY: Only one training task will be generated under this
# population.
# * TRAINING_AND_EVAL: One training task and one evaluation task will be
# generated under this population.
# * EVAL_ONLY: Only one evaluation task will be generated under this
# population.
mode: TRAINING_AND_EVAL
policies {
# Policy for sampling on-device examples. It is checked every time a
# device attempts to start a new training.
min_separation_policy {
# The minimum number of rounds before the same client participated.
minimum_separation: 3
}
# Policy for releasing training results to developers. It is checked
# when uploading a new task to the Federated Compute Server.
model_release_policy {
# Server stops training when number of training rounds reaches this
# number.
num_max_training_rounds: 1000
}
}
# Federated learning setups. They are applied inside Task Builder.
federated_learning {
learning_process {
# Use FED_AVG to build federated learning process. Options you can
# choose:
# * FED_AVG: Federated Averaging algorithm
# (https://arxiv.org/abs/2003.00295)
# * FED_SDG: Federated SGD algorithm
# (https://arxiv.org/abs/1602.05629)
type: FED_AVG
# Optimizer used at client side training. Options you can choose:
# * ADAM
# * SGD
client_optimizer: SGD
# Learning rate used at client side training.
client_learning_rate: 0.01
# Optimizer used at server side training. Options you can choose:
# * ADAM
# * SGD
server_optimizer: ADAM
# Learning rate used at server side training.
sever_learning_rate: 1
runtime_config {
# Number of participating devices for each round of training.
report_goal: 2000
}
# List of metrics to be evaluated by the model during training and
# evaluation. Federated Compute Server provides a list of allowed
# metrics.
metrics {
name: "auc-roc"
}
metrics {
name: "binary_accuracy"
}
}
# Whether or not to generate a corresponding evaluation task under the same
# population. If this field isn't set, only one training task is
# generated under this population.
evaluation {
# The task id under the same population of the source training task that
# this evaluation task evaluates.
source_training_task_id: 1
# Decides how checkpoints from the training task are chosen for
# evaluation.
# * every_k_round: the evaluation task randomly picks one checkpoint
# from the past k rounds of training task checkpoints.
# * every_k_hour: the evaluation task randomly picks one checkpoint
# from the past k hours of training task checkpoints.
checkpoint_selector: "every_1_round"
# The traffic of this evaluation task in this population.
evaluation_traffic: 0.1
# Number of participating devices for each round of evaluation.
report_goal: 200
}
}
# Differential Privacy setups. They are applied inside the Task Builder.
differential_privacy {
# The DP aggregation algorithm you want to use. Options you can choose:
# * FIXED_GAUSSIAN: Federated Learning DP-SGD with fixed clipping norm
# described in "Learning Differentially Private Recurrent
# Language Models" (https://arxiv.org/abs/1710.06963).
# * ADAPTIVE_GAUSSIAN: Federated Learning DP-SGD with quantile-based clip
# norm estimation described in "Differentially Private
# Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
# * TREE: DP-FTRL algorithm described in "Practical and Private (Deep)
# Learning without Sampling or Shuffling"
# (https://arxiv.org/abs/2103.00039).
# * ADADPTIVE_TREE: DP-FTRL with adaptive clipping norm descirbed in
# "Differentially Private Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
type: FIXED_GAUSSIAN
# Noise multiplier for the Gaussian noise.
noise_multiplier: 0.1
# The value of the clipping norm.
clip_norm: 0.1
}
مرحله ۴. پیکربندی فایل زیپ را به سرور Federated Compute ارسال کنید.
فایل زیپ و fcp_server_config.json را به سرور Federated Compute ارسال کنید.
task_builder_client --task_builder_server='http://{federated_compute_server_endpoint}' --saved_model='saved_model' --task_config='fcp_server_config.json'
نقطه پایانی Federated Compute Server همان سروری است که در مرحله 1 راهاندازی کردهاید.
کتابخانه عملگر داخلی LiteRT فقط از تعداد محدودی از عملگرهای TensorFlow پشتیبانی میکند (عملگرهای TensorFlow را انتخاب کنید). مجموعه عملگرهای پشتیبانی شده ممکن است در نسخههای مختلف ماژول OnDevicePersonalization متفاوت باشد. برای اطمینان از سازگاری، یک فرآیند تأیید عملگر در طول ایجاد وظیفه در سازنده وظیفه انجام میشود.
حداقل نسخه ماژول OnDevicePersonalization که پشتیبانی میشود، در فراداده وظیفه گنجانده خواهد شد. این اطلاعات را میتوانید در پیام اطلاعاتی سازنده وظیفه پیدا کنید.
I1023 22:16:53.058027 139653371516736 task_builder_client.py:109] Success! Tasks are built, and artifacts are uploaded to the cloud. I1023 22:16:53.058399 139653371516736 task_builder_client.py:112] applied_algorithms { learning_algo: FED_AVG client_optimizer: SGD server_optimizer: SGD dp_aggregator: FIXED_GAUSSIAN } metric_results { accepted_metrics: "binary_accuracy, binary_crossentropy, recall, precision, auc-roc, auc-pr" } dp_hyperparameters { dp_delta: 0.000001 dp_epsilon: 6.4 noise_multiplier: 1.0 dp_clip_norm: 1.0 num_training_rounds: 10000 } I1023 22:16:53.058594 139653371516736 task_builder_client.py:113] training_task { min_client_version: "341912000" } eval_task { min_client_version: "341812000" }سرور Federated Compute این وظیفه را به تمام دستگاههای مجهز به ماژول OnDevicePersonalization با نسخهای بالاتر از 341812000 اختصاص خواهد داد.
اگر مدل شما شامل عملیاتی باشد که توسط هیچ یک از ماژولهای OnDevicePersonalization پشتیبانی نمیشوند، هنگام ایجاد وظیفه، یک پیام خطا ایجاد خواهد شد.
common.TaskBuilderException: Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {'L2Loss': 'L2LossOp<CPUDevice, float>'} . Stop building remaining artifacts.میتوانید لیست کاملی از flex op های پشتیبانی شده را در GitHub پیدا کنید.
دانلود APK ←
برای ایجاد یک APK محاسبات فدرال اندروید، باید نقطه پایانی URL سرور محاسبات فدرال را در AndroidManifest.xml خود که کلاینت محاسبات فدرال شما به آن متصل میشود، مشخص کنید.
مرحله ۵. نقطه پایانی URL سرور محاسباتی فدرال را مشخص کنید
نقطه پایانی URL سرور محاسبات فدرال (که در مرحله 1 تنظیم کردید) را در AndroidManifest.xml خود که کلاینت محاسبات فدرال شما به آن متصل میشود، مشخص کنید.
<!-- Contents of AndroidManifest.xml -->
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.odpsample" >
<application android:label="OdpSample">
<!-- XML resource that contains other ODP settings. -->
<property android:name="android.ondevicepersonalization.ON_DEVICE_PERSONALIZATION_CONFIG"
android:resource="@xml/OdpSettings"></property>
<!-- The service that ODP will bind to. -->
<service android:name="com.example.odpsample.SampleService"
android:exported="true" android:isolatedProcess="true" />
</application>
</manifest>
فایل منبع XML مشخص شده در تگ <property> باید کلاس سرویس را نیز در تگ <service> تعریف کند و نقطه پایانی URL سرور محاسباتی فدرال را که کلاینت محاسباتی فدرال به آن متصل خواهد شد، مشخص کند:
<!-- Contents of res/xml/OdpSettings.xml -->
<on-device-personalization>
<!-- Name of the service subclass -->
<service name="com.example.odpsample.SampleService">
<!-- If you want to use federated compute feature to train a model,
specify this tag. -->
<federated-compute-settings url="https://fcpserver.com/" />
</service>
</on-device-personalization>
مرحله ۶. پیادهسازی API مربوط به IsolatedWorker#onTrainingExample
برای تولید دادههای آموزشی، API عمومی IsolatedWorker#onTrainingExample مربوط به شخصیسازی روی دستگاه را پیادهسازی کنید.
کدی که در IsolatedProcess اجرا میشود، هیچ دسترسی مستقیمی به شبکه، دیسکهای محلی یا سایر سرویسهای در حال اجرا روی دستگاه ندارد؛ با این حال، APIهای زیر در دسترس هستند:
- 'getRemoteData' - دادههای کلید-مقدار تغییرناپذیر که در صورت لزوم از بکاندهای کنترلشده توسط توسعهدهندگان از راه دور دانلود میشوند.
- 'getLocalData' - دادههای کلید-مقدار قابل تغییر که در صورت وجود، به صورت محلی توسط توسعهدهندگان ذخیره میشوند.
- «دادههای کاربر» - دادههای کاربر ارائه شده توسط پلتفرم.
- 'getLogReader' - یک DAO برای جداول REQUESTS و EVENTS برمیگرداند.
مثال:
@Override public void onTrainingExample(
@NonNull TrainingExampleInput input,
@NonNull Consumer<TrainingExampleOutput> consumer) {
// Check if the incoming training task is the task we want.
if (input.getPopulationName() == "my_new_population") {
TrainingExampleOutput result = new TrainingExampleOutput.Builder():
RequestLogRecord record = this.getLogReader().getRequestLogRecord(1);
int count = 1;
// Iterate logging event table.
for (ContentValues contentValues: record.rows()) {
Features features = Features.newBuilder()
// Retrieve carrier from user info.
.putFeature("carrier", buildFeature(mUserData.getCarrier()))
// Retrieve features from logging info.
.putFeature("int_feature_1",
buildFeature(contentValues.get("int_feature_1")
result.addTrainingExample(
Example.newBuilder()
.setFeatures(features).build().toByteArray())
.addResumptionToken(
String.format("token%d", count).getBytes()))
.build();
count++;
}
consumer.accept(result.build());
}
}
مرحله ۷. یک کار آموزشی دورهای را برنامهریزی کنید.
شخصیسازی روی دستگاه، یک FederatedComputeScheduler برای توسعهدهندگان فراهم میکند تا کارهای محاسباتی فدرال را زمانبندی یا لغو کنند. گزینههای مختلفی برای فراخوانی آن از طریق IsolatedWorker وجود دارد، چه به صورت زمانبندی شده و چه زمانی که دانلود ناهمزمان (async) کامل میشود. نمونههایی از هر دو در ادامه آمده است.
گزینه مبتنی بر زمانبندی. در
IsolatedWorker#onExecuteتابعFederatedComputeScheduler#scheduleفراخوانی کنید.@Override public void onExecute( @NonNull ExecuteInput input, @NonNull Consumer<ExecuteOutput> consumer ) { if (input != null && input.getAppParams() != null && input.getAppParams().getString("schedule_training") != null) { if (input.getAppParams().getString("schedule_training").isEmpty()) { consumer.accept(null); return; } TrainingInterval interval = new TrainingInterval.Builder() .setMinimumInterval(Duration.ofSeconds(10)) .setSchedulingMode(2) .build(); FederatedComputeScheduler.Params params = new FederatedComputeScheduler .Params(interval); FederatedComputeInput fcInput = new FederatedComputeInput.Builder() .setPopulationName( input.getAppParams().getString("schedule_training")).build(); mFCScheduler.schedule(params, fcInput); ExecuteOutput result = new ExecuteOutput.Builder().build(); consumer.accept(result); } }گزینهی «دانلود کامل». اگر زمانبندی یک وظیفهی آموزشی به هرگونه داده یا فرآیند ناهمزمان بستگی دارد،
FederatedComputeScheduler#scheduleدرIsolatedWorker#onDownloadCompletedفراخوانی کنید.
اعتبارسنجی
مراحل زیر نحوه تأیید صحت اجرای وظیفه Federated Learning را شرح میدهد.
مرحله ۸. تأیید کنید که آیا وظیفه Federated Learning به درستی اجرا میشود یا خیر.
در هر دور از تجمیع سمت سرور، یک نقطه بررسی مدل جدید و یک فایل متریک جدید ایجاد میشود.
معیارها در یک فایل با فرمت JSON از جفتهای کلید-مقدار قرار دارند. این فایل توسط لیست Metrics که در مرحله 3 تعریف کردهاید، ایجاد میشود. نمونهای از یک فایل JSON معیارها به شرح زیر است:
{"server/client_work/train/binary_accuracy":0.5384615659713745, "server/client_work/train/binary_crossentropy":0.694046676158905, "server/client_work/train/recall":0.20000000298023224, "server/client_work/train/precision":0.3333333432674408, "server/client_work/train/auc-roc":0.3500000238418579, "server/client_work/train/auc-pr":0.44386863708496094, "server/finalizer/update_non_finite":0.0}
شما میتوانید از چیزی شبیه به اسکریپت زیر برای دریافت معیارهای مدل و نظارت بر عملکرد آموزش استفاده کنید:
import collections
import json
import matplotlib.pyplot as plt
from google.cloud import storage
# The population_name you set in fcp_server_config.json in Step 3.
POPULATION_NAME = 'my_new_population'
# The Google Cloud storage you set in Step 1.
GCS_BUCKET_NAME = 'fcp-gcs'
NUM_TRAINING_ROUND = 1000
storage_client = storage.Client()
bucket = storage_client.bucket(GCS_BUCKET_NAME)
metrics = collections.defaultdict(list)
for i in range(NUM_TRAINING_ROUND):
blob = bucket.blob('{}/{}/1/{}/s/0/metrics'.format(GCS_BUCKET_NAME, POPULATION_NAME, i+1))
with blob.open("r") as f:
metric = json.loads(f.read())
for metric_name in metric.keys():
metrics[metric_name].append(metric[metric_name])
for metric_name in metrics:
print(metric_name)
plt.plot(metrics[metric_name])
plt.show()
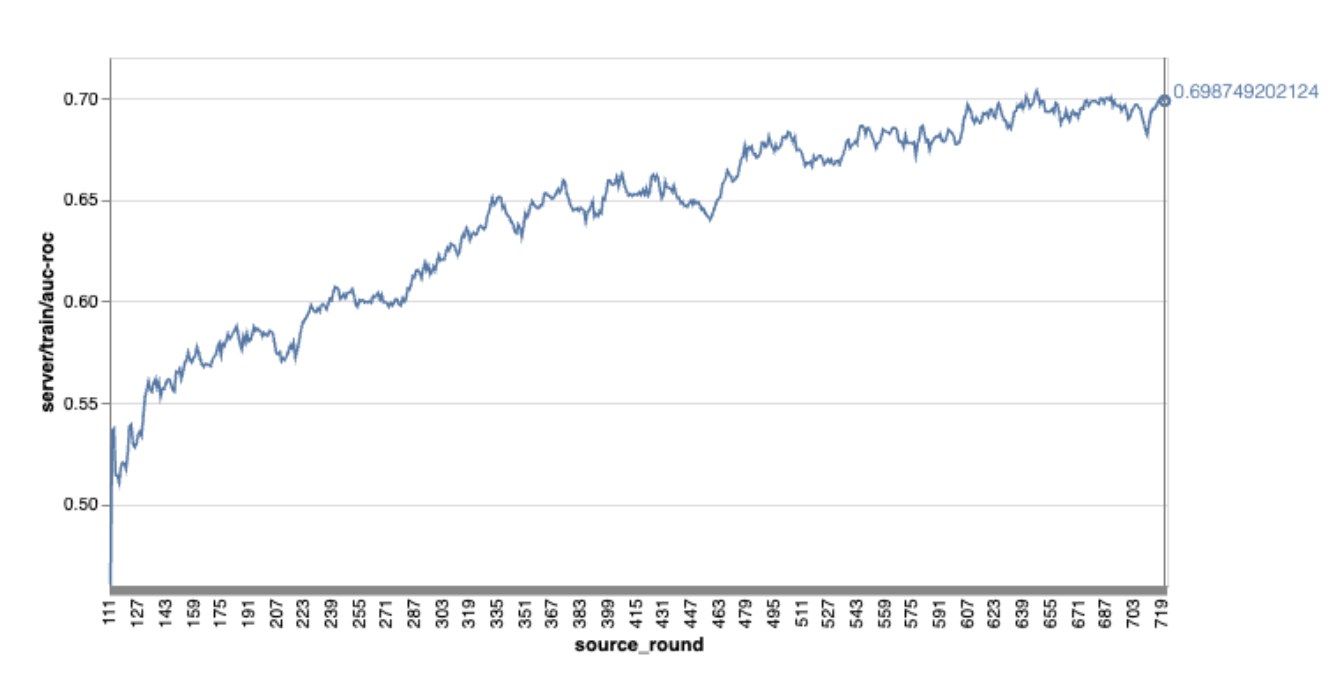
توجه داشته باشید که در نمودار مثال قبلی:
- محور x تعداد دورهای تمرین است.
- محور y مقدار auc-roc هر دور است.
آموزش یک مدل طبقهبندی تصویر روی شخصیسازی روی دستگاه
در این آموزش، از مجموعه داده EMNIST برای نشان دادن نحوه اجرای یک وظیفه یادگیری فدرال در ODP استفاده میشود.
مرحله ۱. ایجاد یک tff.learning.models.FunctionalModel
def get_image_classification_input_spec():
return (
tf.TensorSpec([None, 28, 28, 1], tf.float32),
tf.TensorSpec([None, 1], tf.int64),
)
def create_and_save_image_classification_functional_model(
model_path: str,
) -> None:
keras_model = emnist_models.create_original_fedavg_cnn_model(
only_digits=True
)
functional_model = tff.learning.models.functional_model_from_keras(
keras_model=keras_model,
input_spec=get_image_classification_input_spec(),
loss_fn=tf.keras.losses.SparseCategoricalCrossentropy(),
)
tff.learning.models.save_functional_model(functional_model, model_path)
- میتوانید جزئیات مدل keras مربوط به emnist را در emnist_models پیدا کنید.
- TfLite هنوز پشتیبانی خوبی از tf.sparse.SparseTensor یا tf.RaggedTensor ندارد. سعی کنید تا حد امکان هنگام ساخت مدل از tf.Tensor استفاده کنید.
- سازنده وظیفه ODP هنگام ساخت فرآیند یادگیری ، تمام معیارها را بازنویسی میکند، نیازی به مشخص کردن هیچ معیاری نیست. این موضوع در مرحله 2 بیشتر پوشش داده خواهد شد. پیکربندی سازنده وظیفه را ایجاد کنید .
دو نوع ورودی مدل پشتیبانی میشوند:
نوع ۱. یک چندتایی (features_tensor, label_tensor).
- هنگام ایجاد مدل، input_spec به صورت زیر خواهد بود:
def get_input_spec(): return ( tf.TensorSpec([None, 28, 28, 1], tf.float32), tf.TensorSpec([None, 1], tf.int64), )- موارد قبلی را با پیادهسازی زیر از API عمومی ODP به نام IsolatedWorker#onTrainingExamples جفت کنید تا دادههای آموزشی روی دستگاه تولید شود:
return tf.train.Example( features=tf.train.Features( feature={ 'x': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0] * 784) ), 'y': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()نوع ۲. یک
Tuple(Dict[feature_name, feature_tensor], label_tensor)- هنگام ایجاد مدل، input_spec به صورت زیر خواهد بود:
def get_input_spec() -> ( Tuple[collections.OrderedDict[str, tf.TensorSpec], tf.TensorSpec] ): return ( collections.OrderedDict( [('feature-1', tf.TensorSpec([None, 1], tf.float32)), ('feature-2', tf.TensorSpec([None, 1], tf.float32))] ), tf.TensorSpec([None, 1], tf.int64), )- برای تولید دادههای آموزشی، موارد قبلی را با پیادهسازی زیر از API عمومی ODP به نام IsolatedWorker#onTrainingExamples جفت کنید:
return tf.train.Example( features=tf.train.Features( feature={ 'feature-1': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0]) ), 'feature-2': tf.train.Feature( float_list=tf.train.FloatList(value=[2.0]) ), 'my_label': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()- فراموش نکنید که label_name را در پیکربندی سازنده وظیفه ثبت کنید.
mode: TRAINING_AND_EVAL # Task execution mode population_name: "my_example_model" label_name: "my_label"
ODP هنگام ساخت فرآیند یادگیری، DP را به طور خودکار مدیریت میکند. بنابراین نیازی به اضافه کردن هیچ نویزی هنگام ایجاد مدل عملکردی نیست.
خروجی این مدل تابعی ذخیره شده باید شبیه نمونه موجود در مخزن گیتهاب ما باشد.
مرحله ۲. پیکربندی سازنده وظیفه را ایجاد کنید
میتوانید نمونههایی از پیکربندی task builder را در مخزن گیتهاب ما پیدا کنید.
معیارهای آموزش و ارزیابی
با توجه به اینکه معیارها ممکن است دادههای کاربر را فاش کنند، Task Builder فهرستی از معیارهایی را که فرآیند یادگیری میتواند تولید و منتشر کند، در اختیار خواهد داشت. میتوانید فهرست کامل را در مخزن GitHub ما پیدا کنید.
در اینجا یک لیست معیار نمونه هنگام ایجاد پیکربندی سازنده وظیفه جدید آورده شده است:
federated_learning { learning_process { metrics { name: "binary_accuracy" } metrics { name: "binary_crossentropy" } metrics { name: "recall" } metrics { name: "precision" } metrics { name: "auc-roc" } metrics { name: "auc-pr" } } }
اگر معیارهای مورد نظر شما در لیست فعلی نیست، با ما تماس بگیرید.
پیکربندیهای DP
چند پیکربندی مرتبط با DP وجود دارد که نیاز به مشخص کردن دارند:
policies { min_separation_policy { minimum_separation: 1 } model_release_policy { num_max_training_rounds: 1000 dp_target_epsilon: 10 dp_delta: 0.000001 } } differential_privacy { type: FIXED_GAUSSIAN clip_norm: 0.1 noise_multiplier: 0.1 }- برای قبولی در اعتبارسنجی، یا
dp_target_epsilonیاnoise_mulitipilerوجود دارد: (noise_to_epsilonepislon_to_noise). - میتوانید این تنظیمات پیشفرض را در مخزن گیتهاب ما پیدا کنید.
- برای قبولی در اعتبارسنجی، یا
مرحله ۳. مدل ذخیره شده و پیکربندی سازنده وظیفه را در فضای ابری هر توسعهدهندهای آپلود کنید
به یاد داشته باشید که هنگام آپلود پیکربندی سازنده وظیفه، فیلدهای artifact_building را بهروزرسانی کنید.
مرحله ۴. (اختیاری) آزمایش ساخت مصنوعات بدون ایجاد یک وظیفه جدید
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint}
مدل نمونه از طریق بررسی flex ops و بررسی dp اعتبارسنجی میشود؛ میتوانید skip_flex_ops_check و skip_dp_check برای دور زدن در حین اعتبارسنجی اضافه کنید (این مدل به دلیل فقدان چند flex ops نمیتواند در نسخه فعلی کلاینت ODP مستقر شود).
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint} --skip_flex_ops_check=True --skip_dp_check=True
flex_ops_check: کتابخانه عملگر داخلی TensorFlow Lite فقط از تعداد محدودی از عملگرهای TensorFlow پشتیبانی میکند ( سازگاری با عملگر TensorFlow Lite و TensorFlow ). همه عملیاتهای ناسازگار tensorflow باید با استفاده از نماینده flex ( Android.bp ) نصب شوند. اگر مدلی شامل عملیاتهای پشتیبانی نشده است، برای ثبت آنها با ما تماس بگیرید:
Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {...}بهترین راه برای اشکالزدایی یک سازندهی وظیفه، شروع آن به صورت محلی است:
# Starts a server at localhost:5000 bazel run //python/taskbuilder:task_builder # Links to a server at localhost:5000 by removing task_builder_server flag bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --skip_flex_ops_check=True --skip_dp_check=True
میتوانید مصنوعات حاصل را در فضای ذخیرهسازی ابری مشخصشده در پیکربندی پیدا کنید. این باید چیزی شبیه به نمونه موجود در مخزن گیتهاب ما باشد.
مرحله ۵. مصنوعات را بسازید و یک جفت جدید از وظایف آموزش و ارزیابی را روی سرور FCP ایجاد کنید.
پرچم build_artifact_only را حذف کنید تا مصنوعات ساخته شده در سرور FCP آپلود شوند. باید بررسی کنید که یک جفت وظیفه آموزش و ارزیابی با موفقیت ایجاد شده باشند.
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config.pbtxt --task_builder_server=${task_builder_server_endpoint}
مرحله ۶. سمت کلاینت FCP را آماده کنید
- برای تولید دادههای آموزشی، API عمومی ODP
IsolatedWorker#onTrainingExamplesرا پیادهسازی کنید. - تابع
FederatedComputeScheduler#scheduleفراخوانی کنید. - چند نمونه را در مخزن کد اندروید ما پیدا کنید.
مرحله ۷. نظارت
معیارهای سرور
دستورالعملهای راهاندازی را در مخزن گیتهاب ما بیابید.
- معیارهای مدل
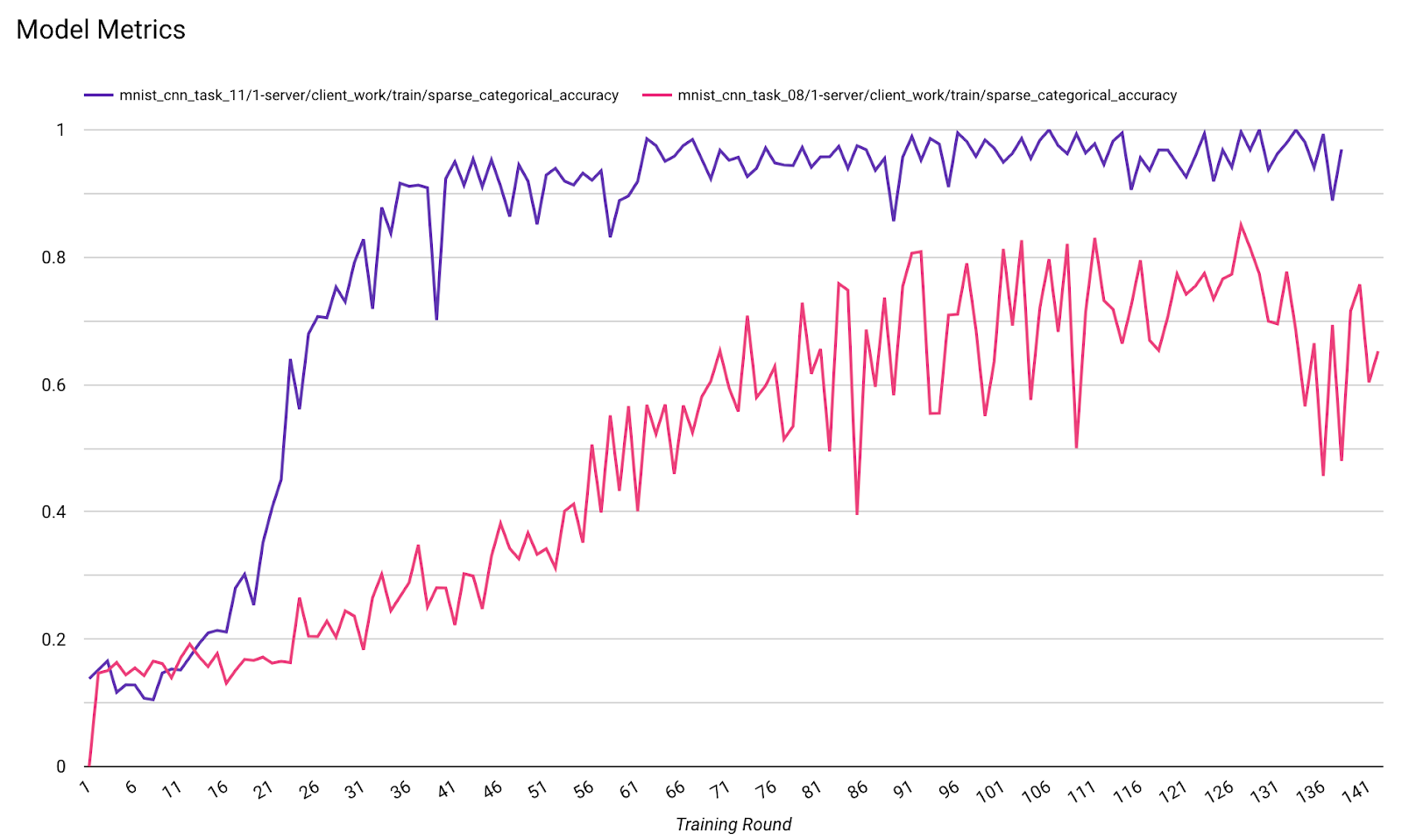
میتوان معیارها را از اجراهای مختلف در یک نمودار مقایسه کرد. برای مثال:
- خط بنفش با
noise_multiplier0.1 است - خط صورتی با
noise_multipiler0.3 است