
Aby zwiększyć ochronę prywatności użytkowników i zapobiegać śledzeniu między witrynami za pomocą kanałów bocznych, Chrome izoluje teraz większość interfejsów API do przechowywania danych i komunikacji w kontekstach podmiotów zewnętrznych w ramach procesu zwanego partycjonowaniem miejsca na dane.
Stan wdrożenia
Ta funkcja została włączona dla wszystkich użytkowników Chrome w wersji 115 lub nowszej. Podobne działania związane z podziałem pamięci są też wdrażane lub planowane w innych popularnych przeglądarkach, takich jak Firefox i Safari. Propozycja dotycząca partycjonowania pamięci na GitHubie jest otwarta na dalszą dyskusję.
Co to jest partycjonowanie pamięci?
Aby zapobiegać niektórym rodzajom śledzenia między witrynami, Chrome partycjonuje miejsce na dane oraz interfejsy API komunikacji w kontekstach podmiotów zewnętrznych.
Bez podziału pamięci witryna może łączyć dane z różnych witryn, aby śledzić użytkownika w internecie. Umożliwia też osadzonej witrynie wnioskowanie o określonych stanach użytkownika w witrynie najwyższego poziomu za pomocą technik kanału bocznego, takich jak ataki czasowe, XS-Leaks i COSI.
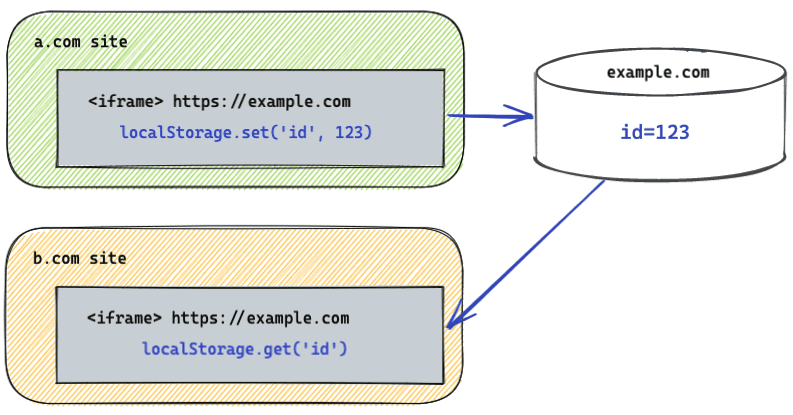
W przeszłości miejsce na dane było kluczowane tylko według pochodzenia. Oznacza to, że jeśli ramka iframe z domeny example.com jest umieszczona w domenach a.com i b.com, może poznać Twoje zwyczaje przeglądania tych 2 witryn, zapisując i pobierając identyfikator z pamięci. Gdy partycjonowanie pamięci na potrzeby podmiotów zewnętrznych jest włączone, miejsce na dane example.com jest podzielone na 2 partycje: jedną dla a.com i drugą dla b.com.
Ogólnie rzecz biorąc, partycjonowanie oznacza, że dane zapisywane przez interfejsy API pamięci masowej, takie jak Local Storage i IndexedDB, w ramce iframe nie są już dostępne dla wszystkich kontekstów o tym samym pochodzeniu. Zamiast tego dane te są teraz odseparowane i dostępne tylko w kontekstach, które mają to samo pochodzenie i tę samą witrynę najwyższego poziomu.
Przed
Po
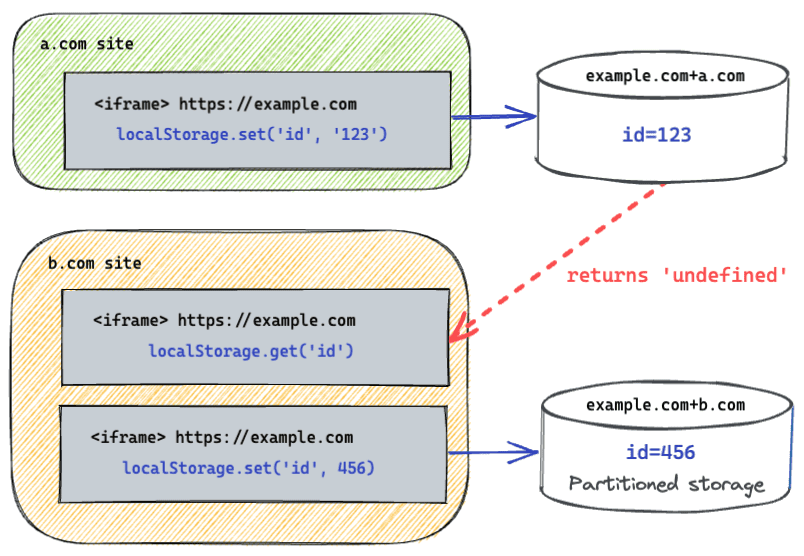
Partycjonowanie pamięci w przypadku połączonych elementów iframe
Złożoność partycjonowania pamięci masowej znacznie wzrasta, gdy ramki iframe są zagnieżdżone, zwłaszcza gdy ten sam pochodzenie pojawia się w łańcuchu wiele razy.
Na przykład A1 zawiera element iframe dla B, który zawiera element iframe dla A2, a zarówno A1, jak i A2 znajdują się w tej samej witrynie. Jeśli partycjonowanie uwzględnia tylko witrynę najwyższego poziomu i źródło bieżącej ramki, element iframe A2 może zostać błędnie potraktowany jako „pochodzący z tej samej witryny”, ponieważ współdzieli witrynę z elementem najwyższego poziomu (A1), mimo że pomiędzy nimi znajduje się element iframe B z innej witryny. Może to narazić A2 na ryzyko związane z bezpieczeństwem, np. clickjacking, jeśli A2 miałby domyślnie dostęp do niepodzielonej pamięci.
Aby rozwiązać ten problem, Chrome dodaje do klucza partycji pamięci „bit przodka”. Ten bit jest ustawiany, jeśli jakikolwiek dokument między bieżącą ramką iframe a witryną najwyższego poziomu pochodzi z innego źródła (z innej witryny). W tym przypadku witryna B jest witryną zewnętrzną, więc bit zostanie ustawiony dla komórki A2, a jej pamięć będzie oddzielona od komórki A1.
Jeśli łańcuch ramek iframe składa się wyłącznie z kontekstów tej samej witryny (np. witryna A1 zawiera A2, która z kolei zawiera A3), bit przodka nie będzie dodatkowo dzielić ich pamięci. W takich przypadkach pamięć pozostaje współdzielona i jest powiązana ze wspólnym źródłem i witryną najwyższego poziomu.
W przypadku witryn, które potrzebują dostępu bez partycji w połączonych ramkach iframe, Chrome eksperymentuje z rozszerzeniem interfejsu Storage Access API, aby umożliwić ten przypadek użycia. Interfejs Storage Access API wymaga, aby witryna w ramce jawnie wywoływała interfejs API, co zmniejsza ryzyko clickjackingu.
Zmiany w interfejsie API wynikające z podziału
Interfejsy API, na które ma wpływ podział, można podzielić na te grupy:
- Interfejsy API do przechowywania
- Interfejsy API do komunikacji
- Service Worker API
- Interfejsy API rozszerzeń
Interfejsy Storage API
- System limitów
- System limitów określa, ile miejsca na dysku jest przydzielane na potrzeby przechowywania danych. System limitów traktuje każdą partycję jako oddzielny zasobnik, aby określić, ile miejsca jest dozwolone i kiedy jest ono zwalniane.
navigator.storage.estimate()Metoda ta zawiera teraz informacje dotyczące partycji pamięci. Interfejsy API dostępne tylko w Chrome, takie jakwindow.webkitStorageInfoinavigator.webkitTemporaryStorage, zostały wycofane.- IndexedDB i pamięć podręczna korzystają z systemu limitów partycjonowanych.
- Web Storage API
- Interfejs Web Storage API udostępnia mechanizmy, za pomocą których przeglądarki mogą przechowywać pary klucz-wartość. Istnieją 2 mechanizmy: pamięć lokalna i pamięć sesji. Nie podlegają one limitom, ale są nadal podzielone na partycje.
- Origin Private File System
- Interfejs File System Access API umożliwia witrynie odczytywanie lub zapisywanie zmian bezpośrednio w plikach i folderach na urządzeniu po przyznaniu dostępu przez użytkownika. Prywatny system plików pochodzenia umożliwia pochodzeniu przechowywanie prywatnych treści bezpośrednio na dysku. Te treści pozostają dostępne dla użytkowników, ale są teraz podzielone.
- Storage Bucket API
- Interfejs Storage Bucket API jest opracowywany na potrzeby Storage Standard, który konsoliduje różne interfejsy API pamięci, takie jak IndexedDB i localStorage, za pomocą nowej koncepcji zwanej zasobnikami. Dane przechowywane w zasobnikach i metadane z nimi powiązane są podzielone na partycje.
- Nagłówek Clear-Site-Data
- Umieszczenie w odpowiedzi nagłówka
Clear-Site-Dataumożliwia serwerowi żądanie wyczyszczenia danych przechowywanych w przeglądarce użytkownika. Możesz wyczyścić pamięć podręczną, pliki cookie i pamięć DOM. Użycie nagłówka powoduje wyczyszczenie miejsca na dane tylko w jednej partycji.
- Sklep Blob URL
- Adres URL obiektu blob umożliwia dostęp do blob, czyli obiektu zawierającego dane surowe. Bez partycjonowania pamięci adres URL obiektu blob wygenerowany w elemencie iframe pochodzącym od podmiotu zewnętrznego w jednej witrynie może być używany w elemencie iframe z tego samego źródła umieszczonym w innej witrynie. Jeśli np. elementy iframe są osadzone zarówno na stronie
a.com, jak ib.com, adres URL obiektu blob wygenerowany w elemencie iframe osadzonym na stroniea.commoże zostać przekazany do elementu iframe osadzonego na stronieb.comi użyty przez niego bez żadnych ograniczeń.example.comOd wersji Chrome 137 (wydanej 27 maja 2025 r.) adresy URL obiektów blob są dzielone na partycje we wszystkich przypadkach z wyjątkiem nawigacji najwyższego poziomu. Przypadki, które będą teraz blokowane, obejmują sytuacje, w których adresy URL Bloba z różnych partycji są używane z elementemfetch()lub jako wartość atrybutusrcw przypadku różnych elementów HTML. Nawigacje najwyższego poziomu, takie jak wywołaniewindow.open()lub kliknięcie linku z atrybutemtarget='_blank', do adresów URL Bloba nie będą blokowane, jeśli są w innej partycji, alenoopenerbędzie wymuszane, jeśli witryna adresu URL Bloba jest w innej witrynie niż witryna najwyższego poziomu strony inicjującej nawigację. Wymuszenienoopeneroznacza, że dokument inicjujący nawigację nie będzie mógł uzyskać uchwytu okna dla dokumentu z adresem URL obiektu blob, który otworzył. W poprzednim przykładzie partycjonowanie uniemożliwi ramce iframe na stronieb.compobranie zawartości adresu URL Bloba, ale nadal będzie mogła gowindow.open().
Interfejsy API komunikacji
Oprócz interfejsów API do przechowywania danych partycjonowane są też interfejsy API komunikacji, które umożliwiają komunikację między kontekstami w różnych domenach. Zmiany te dotyczą głównie interfejsów API, które umożliwiają wykrywanie innych kontekstów za pomocą transmisji lub spotkań w ramach tej samej domeny.
Ze względu na partycjonowanie te interfejsy API komunikacji uniemożliwiają ramkom iframe podmiotów zewnętrznych wymianę danych z kontekstami o tym samym pochodzeniu:
- Kanał nadawczy
- Interfejs Broadcast Channel API umożliwia komunikację między kontekstami przeglądania (oknami, kartami lub elementami iframe) i instancjami roboczymi w tej samej domenie.
- Nie proponujemy zmiany działania elementu iframe w różnych witrynach
postMessage(), ponieważ relacja między tymi kontekstami jest już jasno określona.
- SharedWorker
- Interfejs SharedWorker API udostępnia proces roboczy, do którego można uzyskać dostęp w kontekstach przeglądania o tym samym pochodzeniu.
- Web Locks
- Interfejs Web Locks API umożliwia kodowi działającemu w jednej karcie lub instancji roboczej w tej samej domenie uzyskanie blokady udostępnionego zasobu podczas wykonywania określonych działań.
Service Worker API
Interfejs Service Worker API umożliwia witrynom wykonywanie zadań w tle. Witryny rejestrują moduły service worker, które tworzą nowe konteksty modułu, aby odpowiadać na zdarzenia. Tradycyjnie te instancje robocze mogły komunikować się z dowolnym kontekstem tego samego pochodzenia. Jednak ze względu na to, że service worker może zmieniać czas trwania żądań nawigacyjnych, istnieje ryzyko wycieku informacji z różnych witryn, np. wykrywania historii.
Z tego powodu skrypty service worker zarejestrowane w kontekście innej firmy są teraz dzielone na partycje.
Interfejsy API rozszerzeń
Rozszerzenia to programy, które pozwalają użytkownikom dostosowywać sposób przeglądania.
Strony rozszerzeń (strony ze schematem chrome-extension://) można umieszczać na stronach internetowych. W tym scenariuszu strony rozszerzenia nadal mają dostęp do partycji najwyższego poziomu.
Rozszerzenia mogą też osadzać inne witryny. W takim przypadku osadzone witryny będą miały dostęp do partycji najwyższego poziomu, o ile rozszerzenie ma dla nich uprawnienia hosta.
Więcej informacji znajdziesz w dokumentacji rozszerzenia.
Prezentacja: testowanie partycjonowania pamięci
Witryna demonstracyjna: https://storage-partitioning-demo-site-a.glitch.me/
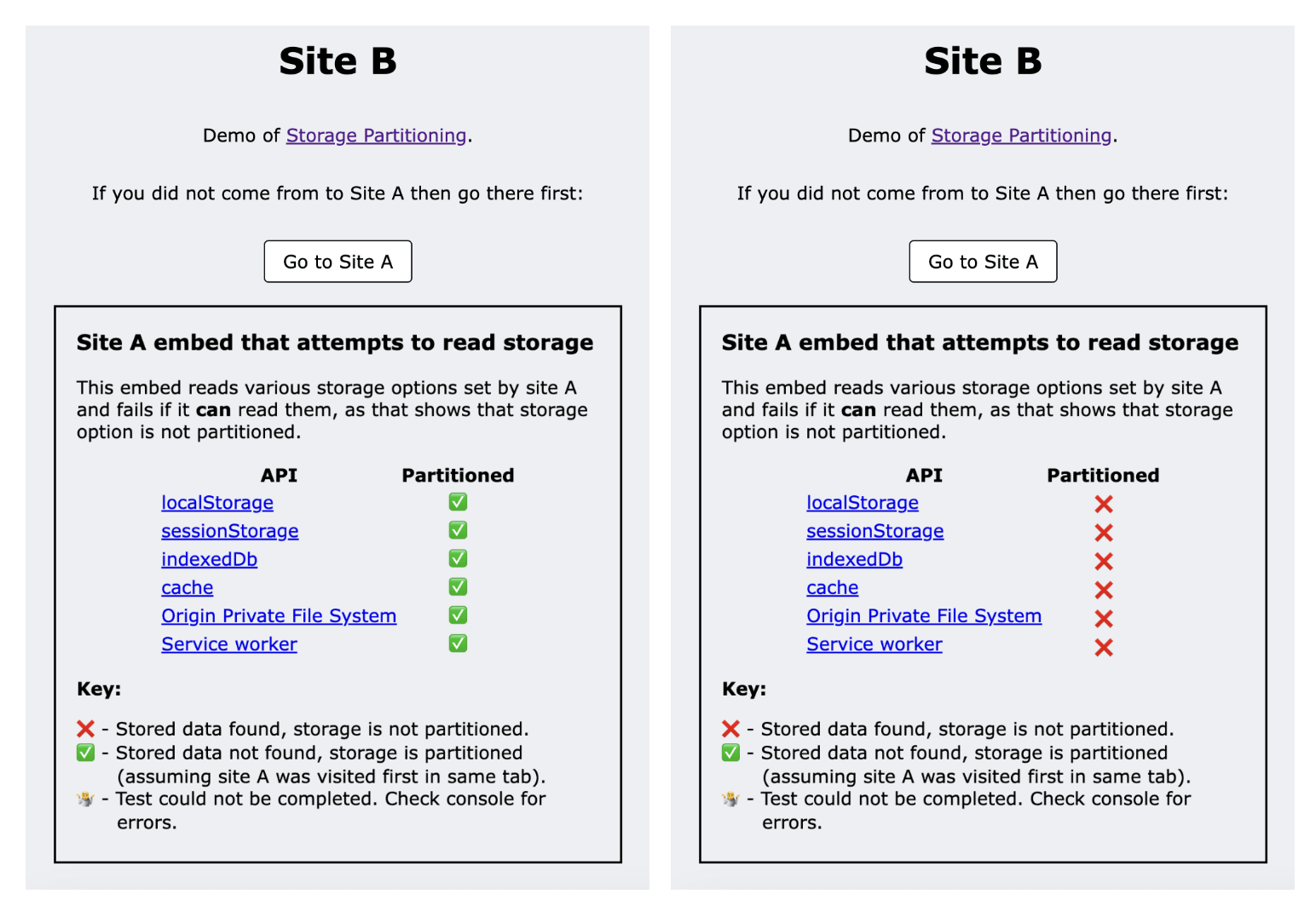
W wersji demonstracyjnej używane są 2 witryny: witryna A i witryna B.
- Gdy odwiedzasz witrynę A w kontekście najwyższego poziomu, ustawia ona dane przy użyciu różnych metod przechowywania.
- Witryna B osadza stronę z witryny A, a osadzony element próbuje odczytać ustawione wcześniej opcje pamięci.
- Gdy witryna A jest umieszczona w witrynie B, nie ma dostępu do tych danych, gdy pamięć jest podzielona na partycje, więc odczytywanie się nie udaje.
- W wersji demonstracyjnej na podstawie tego, czy odczyt się powiódł, czy nie, można sprawdzić, czy dane są podzielone na partycje.
Obecnie możesz wyłączyć podział pamięci w Chrome za pomocą --disable-features=ThirdPartyStoragePartitioning przełącznika wiersza poleceń. Uwaga: ten przełącznik wiersza poleceń jest przeznaczony do celów programistycznych i testowych i może zostać usunięty lub zmieniony w przyszłych wersjach Chrome.
W ten sam sposób możesz przetestować inne przeglądarki, aby sprawdzić ich stan partycjonowania.
Prośba o dodatkowy czas na migrację
W przypadku witryn, które potrzebują więcej czasu na przeniesienie zależności, okres próbny wycofania funkcji DisableThirdPartyStoragePartitioning3 został przedłużony. Ta wersja próbna oferuje witrynom najwyższego poziomu tymczasowy mechanizm umożliwiający włączenie niepartycjonowanego miejsca na dane, procesów roboczych usługi i interfejsów API komunikacji w kontekstach podmiotów zewnętrznych osadzonych na ich stronach.
Więcej informacji znajdziesz w artykule Przedłużenie okresu próbnego wycofania partycjonowania pamięci.
Angażowanie się i przesyłanie opinii
- GitHub przeczytaj oryginalną propozycję, zadawaj pytania i uczestnicz w dyskusji.
- Zgłaszanie błędów: jeśli uważasz, że coś nie działa zgodnie z oczekiwaniami, zgłoś błąd w trackerze Chromium.