
۱. ۱. پیشنیازها
زمان تخمینی برای تکمیل: ۱-۲ ساعت
دو حالت برای انجام این کدلاگ وجود دارد: تست محلی یا سرویس تجمیع . حالت تست محلی به یک دستگاه محلی و مرورگر کروم نیاز دارد (بدون ایجاد/استفاده از منابع گوگل کلود). حالت سرویس تجمیع نیاز به استقرار کامل سرویس تجمیع در گوگل کلود دارد.
برای انجام این codelab در هر دو حالت، چند پیشنیاز لازم است. هر نیاز بر اساس اینکه آیا برای Local Testing یا Aggregation Service مورد نیاز است، مشخص شده است.
۱.۱. تکمیل ثبت نام و گواهی (خدمات تجمیع)
برای استفاده از APIهای Privacy Sandbox، تأیید کنید که مراحل ثبتنام و تأیید را برای Chrome و Android تکمیل کردهاید.
۱.۲. فعالسازی APIهای حریم خصوصی تبلیغات (سرویس تست و تجمیع محلی)
از آنجایی که ما از Privacy Sandbox استفاده خواهیم کرد، شما را تشویق میکنیم که APIهای تبلیغات Privacy Sandbox را فعال کنید.
در مرورگر خود، به chrome://settings/adPrivacy بروید و تمام APIهای حریم خصوصی تبلیغات را فعال کنید.
همچنین تأیید کنید که کوکیهای شخص ثالث شما فعال هستند .
از طریق chrome://settings/cookies ، مطمئن شوید که کوکیهای شخص ثالث مسدود نشدهاند. بسته به نسخه کروم شما، ممکن است گزینههای مختلفی را در این منوی تنظیمات مشاهده کنید، اما پیکربندیهای قابل قبول عبارتند از:
- "مسدود کردن همه کوکیهای شخص ثالث" = غیرفعال
- «مسدود کردن کوکیهای شخص ثالث» = غیرفعال
- «مسدود کردن کوکیهای شخص ثالث در حالت ناشناس» = فعال
 فعال کردن کوکیها
فعال کردن کوکیها
۱.۳. ابزار تست محلی (Local Testing) را دانلود کنید
تست محلی نیاز به دانلود ابزار تست محلی دارد. این ابزار گزارشهای خلاصهای از گزارشهای اشکالزدایی رمزگذاری نشده تولید میکند.
ابزار تست محلی برای دانلود در بایگانی Cloud Function JAR در GitHub موجود است. باید به عنوان LocalTestingTool_{version}.jar نامگذاری شود.
۱.۴. تأیید نصب JAVA و JRE (سرویس تست و تجمیع محلی)
«ترمینال» را باز کنید و با استفاده از java --version بررسی کنید که آیا جاوا یا openJDK روی دستگاه شما نصب شده است یا خیر.
 نسخه جاوا را بررسی کنید.
نسخه جاوا را بررسی کنید.
اگر نصب نشده است، میتوانید آن را از سایت جاوا یا سایت openJDK دانلود و نصب کنید.
۱.۵. دانلود aggregatable_report_converter (سرویس تست و تجمیع محلی)
میتوانید یک کپی از aggregatable_report_converter را از مخزن گیتهاب Privacy Sandbox Demos دانلود کنید. مخزن گیتهاب به استفاده از IntelliJ یا Eclipse اشاره میکند، اما هیچکدام الزامی نیستند. اگر از این ابزارها استفاده نمیکنید، فایل JAR را در محیط محلی خود دانلود کنید.
۱.۶. راهاندازی یک محیط پلتفرم ابری (سرویس تجمیع)
سرویس تجمیع نیاز به استفاده از یک محیط اجرای قابل اعتماد (Trusted Execution Environment) دارد که از یک ارائه دهنده ابری استفاده میکند. در این آزمایشگاه کد، سرویس تجمیع در Google Cloud مستقر خواهد شد، اما AWS نیز پشتیبانی میشود .
دستورالعملهای استقرار در گیتهاب را برای راهاندازی رابط خط فرمان gcloud، دانلود فایلهای باینری و ماژولهای Terraform و ایجاد منابع Google Cloud برای سرویس تجمیع دنبال کنید.
مراحل کلیدی در دستورالعملهای استقرار:
- رابط خط فرمان "gcloud" و Terraform را در محیط خود راهاندازی کنید.
- یک مخزن ذخیرهسازی ابری برای ذخیره وضعیت Terraform ایجاد کنید.
- وابستگیها را دانلود کنید.
-
adtech_setup.auto.tfvarsرا بهروزرسانی کنید وadtech_setupTerraform را اجرا کنید. برای مشاهدهی نمونهای از فایلadtech_setup.auto.tfvarsبه پیوست مراجعه کنید. به نام سطل دادهای که در اینجا ایجاد میشود توجه کنید - این نام در codelab برای ذخیرهی فایلهایی که ایجاد میکنیم استفاده خواهد شد. -
dev.auto.tfvarsرا بهروزرسانی کنید، حساب سرویس deploy را جعل هویت کنید وdevTerraform را اجرا کنید. برای مشاهدهی یک نمونه فایلdev.auto.tfvarsبه پیوست مراجعه کنید. - پس از اتمام استقرار، آدرس
frontend_service_cloudfunction_urlرا از خروجی Terraform دریافت کنید ، که برای ارسال درخواست به سرویس تجمیع در مراحل بعدی مورد نیاز خواهد بود.
۱.۷. راهاندازی کامل سرویس تجمیع (سرویس تجمیع)
سرویس تجمیع برای استفاده از سرویس، نیاز به آموزش هماهنگکنندگان دارد. فرم آموزش سرویس تجمیع را با ارائه سایت گزارشدهی و سایر اطلاعات خود، انتخاب "Google Cloud" و وارد کردن آدرس حساب سرویس خود تکمیل کنید. این حساب سرویس در پیشنیاز قبلی (۱.۶. راهاندازی محیط Google Cloud) ایجاد میشود. (نکته: اگر از نامهای پیشفرض ارائه شده استفاده کنید، این حساب سرویس با "worker-sa@" شروع میشود).
حداکثر ۲ هفته برای تکمیل فرآیند پذیرش در نظر بگیرید.
۱.۸. روش خود را برای فراخوانی نقاط پایانی API (سرویس تجمیع) تعیین کنید
این آزمایشگاه کد دو گزینه برای فراخوانی نقاط پایانی API سرویس تجمیع ارائه میدهد: cURL و Postman . cURL راه سریعتر و آسانتر برای فراخوانی نقاط پایانی API از ترمینال شماست، زیرا به حداقل تنظیمات و هیچ نرمافزار اضافی نیاز ندارد. با این حال، اگر نمیخواهید از cURL استفاده کنید، میتوانید از Postman برای اجرا و ذخیره درخواستهای API برای استفادههای بعدی استفاده کنید.
در بخش ۳.۲. نحوهی استفاده از سرویس تجمیع، دستورالعملهای دقیقی برای استفاده از هر دو گزینه خواهید یافت. اکنون میتوانید پیشنمایشی از آنها را مشاهده کنید تا مشخص شود از کدام روش استفاده خواهید کرد. اگر Postman را انتخاب میکنید، تنظیمات اولیهی زیر را انجام دهید.
۱.۸.۱. تنظیم فضای کاری
برای یک حساب کاربری Postman ثبت نام کنید. پس از ثبت نام، یک فضای کاری به طور خودکار برای شما ایجاد می شود.
 فضای کاری پستچی.
فضای کاری پستچی.
اگر فضای کاری برای شما ایجاد نشده است، به آیتم ناوبری بالای «فضاهای کاری» بروید و «ایجاد فضای کاری» را انتخاب کنید.
«فضای کاری خالی» را انتخاب کنید، روی «بعدی» کلیک کنید و نام آن را «GCP Privacy Sandbox» بگذارید. «شخصی» را انتخاب کنید و روی «ایجاد» کلیک کنید.
فایلهای پیکربندی JSON و Global Environment از پیش پیکربندیشدهی فضای کاری را دانلود کنید.
هر دو فایل JSON را با استفاده از دکمهی «وارد کردن» به «فضای کاری من» وارد کنید.
 دکمهی وارد کردن.
دکمهی وارد کردن.
این کار مجموعه "GCP Privacy Sandbox" را به همراه درخواستهای HTTP مربوط createJob و getJob برای شما ایجاد میکند.
۱.۸.۲. تنظیم مجوز
روی مجموعه «GCP Privacy Sandbox» کلیک کنید و به برگه «Authorization» بروید.
 دکمهی مجوزدهی.
دکمهی مجوزدهی.
شما از روش "Bearer Token" استفاده خواهید کرد. از محیط ترمینال خود، این دستور را اجرا کنید و خروجی را کپی کنید.
gcloud auth print-identity-token
سپس، این مقدار توکن را در فیلد "Token" از تب مجوز Postman قرار دهید:
 فیلد "توکن".
فیلد "توکن".
۱.۸.۳. راهاندازی محیط
به بخش «نگاه سریع به محیط» در گوشه بالا سمت راست بروید:
 دکمهی نگاه سریع به محیط زیست
دکمهی نگاه سریع به محیط زیست
روی «ویرایش» کلیک کنید و «مقدار فعلی» مربوط به «محیط»، «منطقه» و «شناسه عملکرد ابر» را بهروزرسانی کنید:
 مقادیر فعلی را تنظیم کنید.
مقادیر فعلی را تنظیم کنید.
فعلاً میتوانید "request-id" را خالی بگذارید، زیرا بعداً آن را پر خواهیم کرد. برای سایر فیلدها، از مقادیر frontend_service_cloudfunction_url که از تکمیل موفقیتآمیز استقرار Terraform در پیشنیاز ۱.۶ بازگردانده شده است، استفاده کنید. URL از این قالب پیروی میکند: https://
۲. ۲. آزمایشگاه کد (Codelab) تست محلی
زمان تخمینی برای تکمیل: کمتر از ۱ ساعت
شما میتوانید از ابزار تست محلی روی دستگاه خود برای انجام تجمیع و تولید گزارشهای خلاصه با استفاده از گزارشهای اشکالزدایی رمزگذاری نشده استفاده کنید. قبل از شروع ، تأیید کنید که تمام پیشنیازهای دارای برچسب «تست محلی» را تکمیل کردهاید.
مراحل Codelab
مرحله ۲.۱. فعالسازی گزارش : گزارش تجمیع خصوصی را فعال کنید تا بتوانید گزارش را جمعآوری کنید.
مرحله ۲.۲. ایجاد گزارش اشکالزدایی AVRO : گزارش JSON جمعآوریشده را به یک گزارش با فرمت AVRO تبدیل کنید. این مرحله مشابه زمانی است که تکنسینهای تبلیغات گزارشها را از نقاط پایانی گزارشدهی API جمعآوری کرده و گزارشهای JSON را به گزارشهای با فرمت AVRO تبدیل میکنند.
مرحله ۲.۳. بازیابی کلیدهای سطل : کلیدهای سطل توسط تکنسینهای تبلیغات طراحی شدهاند. در این آزمایشگاه کد، از آنجایی که سطلها از پیش تعریف شدهاند، کلیدهای سطل را همانطور که ارائه شدهاند بازیابی کنید.
مرحله ۲.۴. ایجاد دامنه خروجی AVRO : پس از بازیابی کلیدهای سطل، فایل دامنه خروجی AVRO را ایجاد کنید.
مرحله ۲.۵. ایجاد گزارش خلاصه : از ابزار تست محلی برای ایجاد گزارشهای خلاصه در محیط محلی استفاده کنید.
مرحله ۲.۶. بررسی گزارشهای خلاصه : گزارش خلاصهای که توسط ابزار تست محلی ایجاد شده است را بررسی کنید.
۲.۱ گزارش محرک
برای فعالسازی یک گزارش تجمیع خصوصی، میتوانید از سایت آزمایشی Privacy Sandbox (https://privacy-sandbox-demos-news.dev/?env=gcp) یا سایت خودتان (مثلاً https://adtechexample.com) استفاده کنید. اگر از سایت خودتان استفاده میکنید و مراحل ثبتنام و گواهیدهی و راهاندازی سرویس تجمیع را تکمیل نکردهاید، باید از یک Chrome flag و سوئیچ CLI استفاده کنید.
برای این نسخه آزمایشی، ما از سایت آزمایشی Privacy Sandbox استفاده خواهیم کرد. برای رفتن به سایت، روی لینک کلیک کنید؛ سپس میتوانید گزارشها را در chrome://private-aggregation-internals مشاهده کنید:
 صفحه داخلی کروم.
صفحه داخلی کروم.
گزارشی که به نقطه پایانی {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage ارسال میشود، در «متن گزارش» گزارشهای نمایش داده شده در صفحه Chrome Internals نیز یافت میشود.
ممکن است گزارشهای زیادی اینجا ببینید، اما برای این آزمایشگاه کد، از گزارش تجمیعی که مختص Google Cloud است و توسط debug endpoint تولید میشود، استفاده کنید . "Report URL" شامل "/debug/" خواهد بود و aggregation_coordinator_origin field از "Report Body" شامل این URL خواهد بود: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
 گزارش اشکالزدایی گوگل کلود
گزارش اشکالزدایی گوگل کلود
۲.۲. ایجاد گزارش تجمیعی اشکالزدایی
گزارش موجود در «متن گزارش» chrome://private-aggregation-internals را کپی کنید و یک فایل JSON در پوشه privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar (در مخزن دانلود شده در پیشنیاز ۱.۵) ایجاد کنید.
در این مثال، ما از vim استفاده میکنیم زیرا از لینوکس استفاده میکنیم. اما شما میتوانید از هر ویرایشگر متنی که میخواهید استفاده کنید.
vim report.json
گزارش را در report.json قرار دهید و فایل خود را ذخیره کنید.
 کد JSON گزارش.
کد JSON گزارش.
وقتی این را داشتید، aggregatable_report_converter.jar برای کمک به ایجاد گزارش تجمیعی اشکالزدایی استفاده کنید. این یک گزارش تجمیعی به نام report.avro در دایرکتوری فعلی شما ایجاد میکند.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
۲.۳. دریافت کلید سطل از گزارش
برای ایجاد فایل output_domain.avro ، به کلیدهای سطلی نیاز دارید که میتوان آنها را از گزارشها بازیابی کرد.
کلیدهای سطل توسط تکنسین تبلیغات طراحی میشوند. با این حال، در این مورد، سایت Privacy Sandbox Demo کلیدهای سطل را ایجاد میکند. از آنجایی که تجمیع خصوصی برای این سایت در حالت اشکالزدایی است، میتوانیم از debug_cleartext_payload از "Report Body" برای دریافت کلید سطل استفاده کنیم.
ادامه دهید و debug_cleartext_payload را از بدنه گزارش کپی کنید.
 اشکالزدایی Cleartext Payload.
اشکالزدایی Cleartext Payload.
goo.gle/ags-payload-decoder را باز کنید و debug_cleartext_payload خود را در کادر "INPUT" قرار دهید و روی "Decode" کلیک کنید.
 دکمه رمزگشایی.
دکمه رمزگشایی.
این صفحه مقدار اعشاری کلید سطل را برمیگرداند. در زیر یک نمونه کلید سطل آمده است.
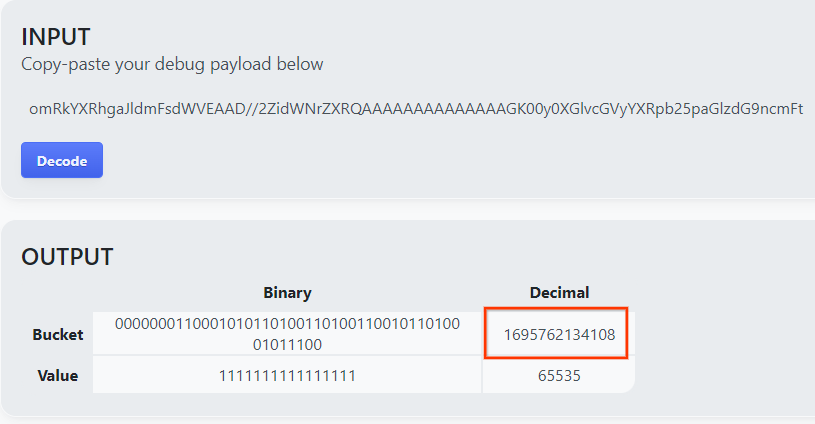 یک نمونه کلید سطلی.
یک نمونه کلید سطلی.
۲.۴ ایجاد دامنه خروجی AVRO
حالا که کلید bucket را داریم، بیایید فایل output_domain.avro را در همان پوشهای که در آن کار میکردیم ایجاد کنیم. مطمئن شوید که به جای bucket key، کلید bucket بازیابی شده را قرار دادهاید.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
اسکریپت، فایل output_domain.avro را در پوشه فعلی شما ایجاد میکند.
۲.۵. ایجاد گزارشهای خلاصه با استفاده از ابزار تست محلی
ما LocalTestingTool_{version}.jar که در پیشنیاز ۱.۳ دانلود شده بود، برای ایجاد گزارشهای خلاصه با استفاده از دستور زیر استفاده خواهیم کرد. {version} را با نسخهای که دانلود کردهاید جایگزین کنید. به یاد داشته باشید که LocalTestingTool_{version}.jar را به دایرکتوری فعلی منتقل کنید، یا یک مسیر نسبی برای ارجاع به مکان فعلی آن اضافه کنید.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
پس از اجرای دستور، باید چیزی شبیه به تصویر زیر را مشاهده کنید. پس از تکمیل این کار، یک فایل report output.avro ایجاد میشود.
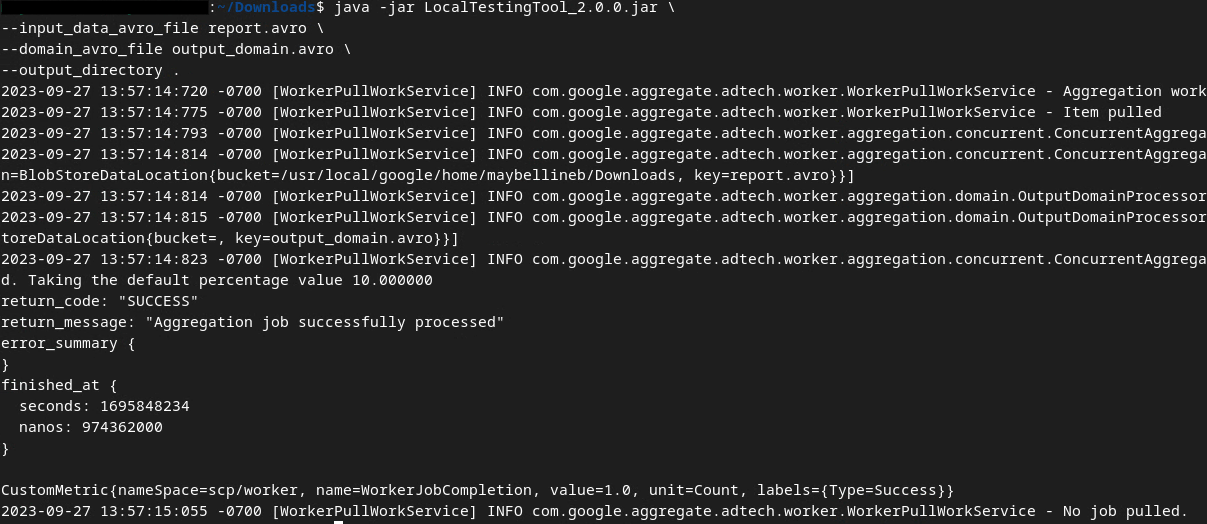 خروجی AVRO
خروجی AVRO
۲.۶. خلاصه گزارش را مرور کنید
گزارش خلاصهای که ایجاد میشود در قالب AVRO است. برای اینکه بتوانید آن را بخوانید، باید آن را از AVRO به قالب JSON تبدیل کنید. در حالت ایدهآل، تکنسین تبلیغات باید کدی بنویسد که گزارشهای AVRO را به JSON تبدیل کند.
ما از aggregatable_report_converter.jar برای تبدیل مجدد گزارش AVRO به JSON استفاده خواهیم کرد.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
این دستور گزارشی مشابه گزارش زیر را به همراه گزارشی با فایل output.json که در همان دایرکتوری ایجاد شده است، برمیگرداند.
 خروجی JSON
خروجی JSON
کدلب کامل شد!
خلاصه: شما یک گزارش اشکالزدایی جمعآوری کردهاید، یک فایل دامنه خروجی ساختهاید و با استفاده از ابزار تست محلی که رفتار تجمیع سرویس تجمیع را شبیهسازی میکند، یک گزارش خلاصه ایجاد کردهاید.
مراحل بعدی: اکنون که با ابزار تست محلی آزمایش کردهاید، میتوانید همین تمرین را با یک پیادهسازی زنده از سرویس تجمیع در محیط خودتان انجام دهید. پیشنیازها را دوباره بررسی کنید تا مطمئن شوید همه چیز را برای حالت "سرویس تجمیع" تنظیم کردهاید، سپس به مرحله ۳ بروید.
۳. ۳. سرویس تجمیع Codelab
زمان تخمینی برای تکمیل: ۱ ساعت
قبل از شروع ، مطمئن شوید که تمام پیشنیازهای دارای برچسب «سرویس تجمیع» را تکمیل کردهاید.
مراحل Codelab
مرحله ۳.۱. ایجاد ورودی سرویس تجمیع : گزارشهای سرویس تجمیع را که برای سرویس تجمیع دستهبندی شدهاند، ایجاد کنید.
- مرحله ۳.۱.۱. گزارش تریگر
- مرحله ۳.۱.۲. جمعآوری گزارشهای قابل جمعآوری
- مرحله ۳.۱.۳. تبدیل گزارشها به AVRO
- مرحله ۳.۱.۴. ایجاد output_domain AVRO
- مرحله ۳.۱.۵. انتقال گزارشها به فضای ذخیرهسازی ابری
مرحله ۳.۲. کاربرد سرویس تجمیع : از API سرویس تجمیع برای ایجاد گزارشهای خلاصه و بررسی گزارشهای خلاصه استفاده کنید.
- مرحله ۳.۲.۱. استفاده از
createJobEndpoint برای دسته بندی - مرحله ۳.۲.۲. استفاده از
getJobEndpoint برای بازیابی وضعیت دستهای - مرحله ۳.۲.۳. بررسی خلاصه گزارش
۳.۱. ایجاد ورودی سرویس تجمیع
برای ایجاد گزارشهای AVRO جهت دستهبندی در سرویس تجمیع، ادامه دهید. دستورات shell در این مراحل میتوانند در Cloud Shell گوگل کلود (تا زمانی که وابستگیهای پیشنیازها در محیط Cloud Shell شما کلون شده باشند) یا در یک محیط اجرای محلی اجرا شوند.
۳.۱.۱ گزارش تریگر
برای رفتن به سایت، روی لینک کلیک کنید؛ سپس میتوانید گزارشها را در chrome://private-aggregation-internals مشاهده کنید:
صفحه داخلی کروم
گزارشی که به نقطه پایانی {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage ارسال میشود، در «متن گزارش» گزارشهای نمایش داده شده در صفحه Chrome Internals نیز یافت میشود.
ممکن است گزارشهای زیادی اینجا ببینید، اما برای این آزمایشگاه کد، از گزارش تجمیعی که مختص Google Cloud است و توسط debug endpoint تولید میشود، استفاده کنید . "Report URL" شامل "/debug/" خواهد بود و aggregation_coordinator_origin field از "Report Body" شامل این URL خواهد بود: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
گزارش اشکالزدایی گوگل کلود
۳.۱.۲ جمعآوری گزارشهای قابل جمعآوری
گزارشهای قابل جمعآوری خود را از نقاط پایانی شناختهشدهی API مربوطهتان جمعآوری کنید.
- تجمیع خصوصی:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - گزارش انتساب - گزارش خلاصه:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
برای این آزمایشگاه کد، ما جمعآوری گزارش را به صورت دستی انجام میدهیم. در مرحله تولید، انتظار میرود تکنسینهای تبلیغات گزارشها را به صورت برنامهنویسی جمعآوری و تبدیل کنند.
بیایید گزارش JSON را از chrome://private-aggregation-internals در "Report Body" کپی کنیم.
در این مثال، ما از vim استفاده میکنیم زیرا از لینوکس استفاده میکنیم. اما شما میتوانید از هر ویرایشگر متنی که میخواهید استفاده کنید.
vim report.json
گزارش را در report.json قرار دهید و فایل خود را ذخیره کنید.
گزارش JSON
۳.۱.۳ تبدیل گزارشها به AVRO
گزارشهای دریافتی از نقاط انتهایی .well-known در قالب JSON هستند و باید به قالب گزارش AVRO تبدیل شوند. پس از دریافت گزارش JSON، به محل ذخیره report.json بروید و aggregatable_report_converter.jar برای ایجاد گزارش تجمیعی اشکالزدایی استفاده کنید. این کار یک گزارش تجمیعی به نام report.avro در دایرکتوری فعلی شما ایجاد میکند.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
۳.۱.۴ ایجاد output_domain AVRO
برای ایجاد فایل output_domain.avro ، به کلیدهای سطلی نیاز دارید که میتوان آنها را از گزارشها بازیابی کرد.
کلیدهای سطل توسط تکنسین تبلیغات طراحی میشوند. با این حال، در این مورد، سایت Privacy Sandbox Demo کلیدهای سطل را ایجاد میکند. از آنجایی که تجمیع خصوصی برای این سایت در حالت اشکالزدایی است، میتوانیم از debug_cleartext_payload از "Report Body" برای دریافت کلید سطل استفاده کنیم.
ادامه دهید و debug_cleartext_payload را از بدنه گزارش کپی کنید.
اشکالزدایی Cleartext Payload.
goo.gle/ags-payload-decoder را باز کنید و debug_cleartext_payload خود را در کادر "INPUT" قرار دهید و روی "Decode" کلیک کنید.
دکمه رمزگشایی.
این صفحه مقدار اعشاری کلید سطل را برمیگرداند. در زیر یک نمونه کلید سطل آمده است.
یک نمونه کلید سطلی.
حالا که کلید bucket را داریم، بیایید فایل output_domain.avro را در همان پوشهای که در آن کار میکردیم ایجاد کنیم. مطمئن شوید که به جای bucket key، کلید bucket بازیابی شده را قرار دادهاید.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
اسکریپت، فایل output_domain.avro را در پوشه فعلی شما ایجاد میکند.
۳.۱.۵ انتقال گزارشها به فضای ذخیرهسازی ابری
پس از ایجاد گزارشها و دامنه خروجی AVRO، گزارشها و دامنه خروجی را به سطل موجود در فضای ذخیرهسازی ابری (که در پیشنیاز ۱.۶ به آن اشاره کردید) منتقل کنید.
اگر تنظیمات gcloud CLI را در محیط محلی خود دارید، از دستورات زیر برای کپی کردن فایلها در پوشههای مربوطه استفاده کنید.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
در غیر این صورت، فایلها را به صورت دستی در باکت خود آپلود کنید. پوشهای به نام "reports" ایجاد کنید و فایل report.avro را در آنجا آپلود کنید. پوشهای به نام "output_domains" ایجاد کنید و فایل output_domain.avro در آنجا آپلود کنید.
۳.۲. کاربرد سرویس تجمیع
به یاد داشته باشید که در پیشنیاز ۱.۸، برای ارسال درخواستهای API به نقاط انتهایی سرویس تجمیع، curl یا Postman را انتخاب کردید. دستورالعملهای هر دو گزینه در ادامه آمده است.
اگر کار شما با خطا مواجه شد، برای اطلاعات بیشتر در مورد نحوه ادامه، مستندات عیبیابی ما را در GitHub بررسی کنید.
۳.۲.۱ استفاده از createJob Endpoint برای دسته بندی
برای ایجاد یک job از یکی از دستورالعملهای curl یا Postman زیر استفاده کنید.
حلقه زدن
در «ترمینال» خود، یک فایل بدنه درخواست ( body.json ) ایجاد کنید و شیء JSON زیر را در آن جایگذاری کنید. حتماً مقادیر placeholder را بهروزرسانی کنید. برای اطلاعات بیشتر در مورد اینکه هر فیلد نشاندهنده چیست، به این مستندات API مراجعه کنید.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
درخواست زیر را اجرا کنید. مقادیر موجود در آدرس URL درخواست curl را با مقادیر frontend_service_cloudfunction_url که پس از اتمام موفقیتآمیز استقرار Terraform در پیشنیاز ۱.۶ خروجی داده میشود، جایگزین کنید.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
پس از پذیرش درخواست توسط سرویس تجمیع، باید پاسخ HTTP 202 دریافت کنید. سایر کدهای پاسخ ممکن در مشخصات API مستند شدهاند .
پستچی
برای نقطه پایانی createJob ، یک بدنه درخواست لازم است تا مکان و نام فایلهای گزارشهای قابل تجمیع، دامنههای خروجی و گزارشهای خلاصه را به سرویس تجمیع ارائه دهد.
به تب "Body" درخواست createJob بروید:
 تب بدنه
تب بدنه
جاینگهدارها را در JSON ارائه شده جایگزین کنید. برای اطلاعات بیشتر در مورد این فیلدها و آنچه که نشان میدهند، به مستندات API مراجعه کنید.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
درخواست API createJob را "ارسال" کنید:
 دکمه ارسال
دکمه ارسال
کد پاسخ را میتوانید در نیمه پایینی صفحه پیدا کنید:
 کد پاسخ
کد پاسخ
پس از پذیرش درخواست توسط سرویس تجمیع، باید پاسخ HTTP 202 دریافت کنید. سایر کدهای پاسخ ممکن در مشخصات API مستند شدهاند .
۳.۲.۲. استفاده از getJob Endpoint برای بازیابی وضعیت دستهای
برای پیدا کردن شغل از یکی از دستورالعملهای curl یا Postman زیر استفاده کنید.
حلقه زدن
درخواست زیر را در ترمینال خود اجرا کنید. جاهای خالی (placeholders) در URL را با مقادیر frontend_service_cloudfunction_url جایگزین کنید، که همان URL ای است که برای درخواست createJob استفاده کردید. برای "job_request_id"، از مقداری که از job ایجاد شده با نقطه پایانی createJob استفاده کردید، استفاده کنید.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
نتیجه باید وضعیت درخواست کار شما را با وضعیت HTTP 200 برگرداند. درخواست "Body" شامل اطلاعات لازم مانند job_status ، return_message و error_messages (در صورت بروز خطا در کار) است.
پستچی
برای بررسی وضعیت درخواست کار، میتوانید از نقطه پایانی getJob استفاده کنید. در بخش "Params" از درخواست getJob ، مقدار job_request_id را به job_request_id که در درخواست createJob ارسال شده بود، بهروزرسانی کنید.
 شناسه درخواست کار
شناسه درخواست کار
درخواست getJob را "ارسال" میکند:
 دکمه ارسال
دکمه ارسال
نتیجه باید وضعیت درخواست کار شما را با وضعیت HTTP 200 برگرداند. درخواست "Body" شامل اطلاعات لازم مانند job_status ، return_message و error_messages (در صورت بروز خطا در کار) است.
 پاسخ JSON
پاسخ JSON
۳.۲.۳ بررسی خلاصه گزارش
پس از دریافت گزارش خلاصه خود در مخزن ذخیرهسازی ابری خروجی، میتوانید آن را در محیط محلی خود دانلود کنید. گزارشهای خلاصه با فرمت AVRO هستند و میتوانند به JSON تبدیل شوند. میتوانید با استفاده از این دستور، aggregatable_report_converter.jar برای خواندن گزارش خود استفاده کنید.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
این یک json از مقادیر تجمیعشدهی هر کلید سطل را برمیگرداند که مشابه زیر است.
 گزارش خلاصه.
گزارش خلاصه.
اگر درخواست createJob شما شامل debug_run به صورت true باشد، میتوانید گزارش خلاصه خود را در پوشه debug که در output_data_blob_prefix قرار دارد، دریافت کنید. این گزارش با فرمت AVRO است و میتوان آن را با استفاده از دستور قبلی به JSON تبدیل کرد.
این گزارش شامل کلید سطل، معیار بدون نویز و نویزی است که برای تشکیل گزارش خلاصه به معیار بدون نویز اضافه شده است. گزارش مشابه زیر است.
 گزارش نویزدار
گزارش نویزدار
این حاشیهنویسیها همچنین حاوی «in_reports» یا «in_domain» (یا هر دو) هستند که به معنی زیر است:
- in_reports - کلید bucket در داخل گزارشهای تجمیعی موجود است.
- in_domain - کلید سطل در داخل فایل output_domain AVRO موجود است.
کدلب کامل شد!
خلاصه: شما سرویس تجمیع را در محیط ابری خود مستقر کردهاید، یک گزارش اشکالزدایی جمعآوری کردهاید، یک فایل دامنه خروجی ساختهاید، این فایلها را در یک مخزن ذخیرهسازی ابری ذخیره کردهاید و یک کار موفق را اجرا کردهاید!
مراحل بعدی: به استفاده از سرویس تجمیع در محیط خود ادامه دهید، یا منابع ابری که اخیراً ایجاد کردهاید را با پیروی از دستورالعملهای پاکسازی در مرحله ۴ حذف کنید.
۴. ۴. پاکسازی
برای حذف منابع ایجاد شده برای سرویس تجمیع با استفاده از Terraform، از دستور destroy در پوشههای adtech_setup و dev (یا محیط دیگر) استفاده کنید:
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
برای حذف مخزن ذخیرهسازی ابری که گزارشهای تجمیعی و گزارشهای خلاصه شما را در خود جای داده است:
$ gcloud storage buckets delete gs://my-bucket
همچنین میتوانید تنظیمات کوکی کروم خود را از پیشنیاز ۱.۲ به حالت قبلی برگردانید.
۵. ۵. پیوست
مثال فایل adtech_setup.auto.tfvars
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
مثال فایل dev.auto.tfvars
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20