
১. ১. পূর্বশর্ত
সম্পন্ন করার আনুমানিক সময়: ১-২ ঘন্টা
এই কোডল্যাবটি সম্পাদনের জন্য দুটি মোড রয়েছে: স্থানীয় পরীক্ষা অথবা সমষ্টি পরিষেবা । স্থানীয় পরীক্ষা মোডের জন্য একটি স্থানীয় মেশিন এবং Chrome ব্রাউজার প্রয়োজন (কোনও Google ক্লাউড রিসোর্স তৈরি/ব্যবহার নেই)। সমষ্টি পরিষেবা মোডের জন্য Google ক্লাউডে সমষ্টি পরিষেবার সম্পূর্ণ স্থাপনা প্রয়োজন।
এই কোডল্যাবটি যেকোনো মোডে সম্পাদন করার জন্য, কয়েকটি পূর্বশর্ত প্রয়োজন। প্রতিটি প্রয়োজনীয়তা স্থানীয় পরীক্ষার জন্য বা সমষ্টিগত পরিষেবার জন্য প্রয়োজনীয় কিনা তা অনুসারে চিহ্নিত করা হয়।
১.১. সম্পূর্ণ তালিকাভুক্তি এবং প্রত্যয়ন (সমষ্টি পরিষেবা)
প্রাইভেসি স্যান্ডবক্স এপিআই ব্যবহার করতে, যাচাই করুন যে আপনি Chrome এবং Android উভয়ের জন্যই এনরোলমেন্ট এবং অ্যাটেস্টেশন সম্পন্ন করেছেন।
১.২. বিজ্ঞাপন গোপনীয়তা API (স্থানীয় পরীক্ষা এবং সমষ্টি পরিষেবা) সক্ষম করুন
যেহেতু আমরা প্রাইভেসি স্যান্ডবক্স ব্যবহার করব, তাই আমরা আপনাকে প্রাইভেসি স্যান্ডবক্স বিজ্ঞাপন API গুলি সক্ষম করতে উৎসাহিত করছি।
আপনার ব্রাউজারে, chrome://settings/adPrivacy এ যান এবং সমস্ত বিজ্ঞাপন গোপনীয়তা API সক্রিয় করুন।
আপনার তৃতীয় পক্ষের কুকিজ সক্রিয় আছে কিনা তাও যাচাই করুন।
chrome://settings/cookies থেকে, নিশ্চিত করুন যে তৃতীয় পক্ষের কুকিজ ব্লক করা হচ্ছে না। আপনার Chrome সংস্করণের উপর নির্ভর করে, আপনি এই সেটিংস মেনুতে বিভিন্ন বিকল্প দেখতে পাবেন, তবে গ্রহণযোগ্য কনফিগারেশনের মধ্যে রয়েছে:
- "সকল তৃতীয় পক্ষের কুকিজ ব্লক করুন" = অক্ষম করা হয়েছে
- "তৃতীয় পক্ষের কুকিজ ব্লক করুন" = অক্ষম করা হয়েছে
- "ছদ্মবেশী মোডে তৃতীয় পক্ষের কুকিজ ব্লক করুন" = সক্ষম করা হয়েছে
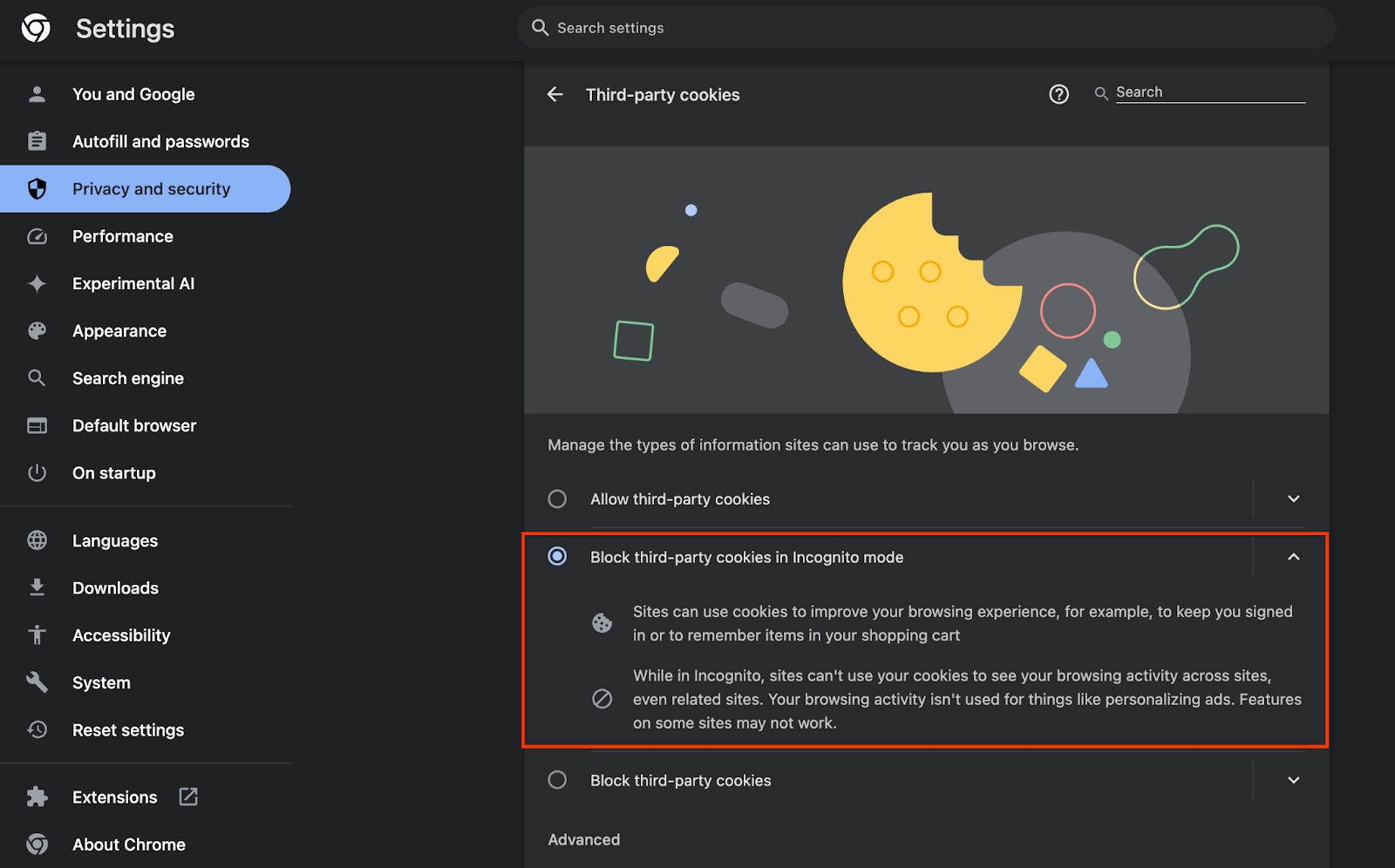 কুকিজ সক্রিয় করা
কুকিজ সক্রিয় করা
১.৩. লোকাল টেস্টিং টুল (লোকাল টেস্টিং) ডাউনলোড করুন।
লোকাল টেস্টিং এর জন্য লোকাল টেস্টিং টুল ডাউনলোড করতে হবে। টুলটি এনক্রিপ্ট না করা ডিবাগ রিপোর্ট থেকে সারাংশ রিপোর্ট তৈরি করবে।
লোকাল টেস্টিং টুলটি GitHub-এর ক্লাউড ফাংশন JAR আর্কাইভে ডাউনলোডের জন্য উপলব্ধ। এর নামকরণ করা উচিত LocalTestingTool_{version}.jar ।
১.৪. জাভা জেআরই ইনস্টল করা আছে কিনা তা যাচাই করুন (স্থানীয় পরীক্ষা এবং সমষ্টি পরিষেবা)
"টার্মিনাল" খুলুন এবং java --version ব্যবহার করে আপনার মেশিনে Java অথবা openJDK ইনস্টল করা আছে কিনা তা পরীক্ষা করুন।
 জাভা ভার্সনটি পরীক্ষা করুন।
জাভা ভার্সনটি পরীক্ষা করুন।
যদি এটি ইনস্টল না করা থাকে, তাহলে আপনি জাভা সাইট অথবা openJDK সাইট থেকে ডাউনলোড করে ইনস্টল করতে পারেন।
১.৫. aggregatable_report_converter (স্থানীয় পরীক্ষা এবং সমষ্টি পরিষেবা) ডাউনলোড করুন
আপনি Privacy Sandbox Demos GitHub রিপোজিটরি থেকে aggregatable_report_converter এর একটি কপি ডাউনলোড করতে পারেন। GitHub রিপোজিটরিতে IntelliJ বা Eclipse ব্যবহারের কথা উল্লেখ করা হয়েছে, কিন্তু দুটিরই প্রয়োজন নেই। যদি আপনি এই টুলগুলি ব্যবহার না করেন, তাহলে আপনার স্থানীয় পরিবেশে JAR ফাইলটি ডাউনলোড করুন।
১.৬. একটি ক্লাউড প্ল্যাটফর্ম পরিবেশ (সমষ্টি পরিষেবা) সেট আপ করুন
অ্যাগ্রিগেশন সার্ভিসের জন্য একটি ট্রাস্টেড এক্সিকিউশন এনভায়রনমেন্ট ব্যবহার করা প্রয়োজন যা একটি ক্লাউড প্রোভাইডার ব্যবহার করে। এই কোডল্যাবে, অ্যাগ্রিগেশন সার্ভিস গুগল ক্লাউডে স্থাপন করা হবে, তবে AWSও সমর্থিত ।
gcloud CLI সেটআপ করতে, Terraform বাইনারি এবং মডিউল ডাউনলোড করতে এবং Aggregation Service-এর জন্য Google Cloud রিসোর্স তৈরি করতে GitHub-এর ডিপ্লয়মেন্ট নির্দেশাবলী অনুসরণ করুন।
স্থাপনার নির্দেশাবলীর মূল ধাপগুলি:
- আপনার পরিবেশে "gcloud" CLI এবং Terraform সেট আপ করুন।
- টেরাফর্ম স্টেট সংরক্ষণের জন্য একটি ক্লাউড স্টোরেজ বাকেট তৈরি করুন।
- নির্ভরতা ডাউনলোড করুন।
-
adtech_setup.auto.tfvarsআপডেট করুন এবংadtech_setupTerraform চালান।adtech_setup.auto.tfvarsফাইলের উদাহরণের জন্য পরিশিষ্ট দেখুন। এখানে তৈরি করা ডেটা বাকেটের নামটি লক্ষ্য করুন - এটি কোডল্যাবে আমাদের তৈরি ফাইলগুলি সংরক্ষণ করার জন্য ব্যবহার করা হবে। -
dev.auto.tfvarsআপডেট করুন, deploy service অ্যাকাউন্টের ছদ্মবেশ ধারণ করুন এবংdevTerraform চালান।dev.auto.tfvarsফাইলের উদাহরণের জন্য পরিশিষ্ট দেখুন। - স্থাপনা সম্পূর্ণ হয়ে গেলে, Terraform আউটপুট থেকে
frontend_service_cloudfunction_urlক্যাপচার করুন , যা পরবর্তী ধাপগুলিতে Aggregation Service-এ অনুরোধ করার জন্য প্রয়োজন হবে।
১.৭. সম্পূর্ণ একত্রীকরণ পরিষেবা অনবোর্ডিং (একত্রীকরণ পরিষেবা)
পরিষেবাটি ব্যবহার করতে সক্ষম হওয়ার জন্য সমষ্টি পরিষেবার সমন্বয়কারীদের সাথে অনবোর্ডিং প্রয়োজন। আপনার রিপোর্টিং সাইট এবং অন্যান্য তথ্য প্রদান করে, "গুগল ক্লাউড" নির্বাচন করে এবং আপনার পরিষেবা অ্যাকাউন্টের ঠিকানা প্রবেশ করে সমষ্টি পরিষেবা অনবোর্ডিং ফর্মটি পূরণ করুন। এই পরিষেবা অ্যাকাউন্টটি পূর্ববর্তী পূর্বশর্ত (1.6. একটি Google ক্লাউড পরিবেশ সেট আপ করুন) অনুসারে তৈরি করা হয়। (ইঙ্গিত: আপনি যদি প্রদত্ত ডিফল্ট নামগুলি ব্যবহার করেন, তাহলে এই পরিষেবা অ্যাকাউন্টটি "worker-sa@" দিয়ে শুরু হবে)।
অনবোর্ডিং প্রক্রিয়া সম্পন্ন হওয়ার জন্য সর্বোচ্চ ২ সপ্তাহ সময় দিন।
১.৮. API এন্ডপয়েন্ট (অ্যাগ্রিগেশন সার্ভিস) কল করার জন্য আপনার পদ্ধতি নির্ধারণ করুন।
এই কোডল্যাবটি Aggregation Service API এন্ডপয়েন্ট কল করার জন্য দুটি বিকল্প প্রদান করে: cURL এবং Postman । cURL হল আপনার টার্মিনাল থেকে API এন্ডপয়েন্ট কল করার দ্রুত এবং সহজ উপায়, কারণ এর জন্য ন্যূনতম সেটআপ প্রয়োজন এবং কোনও অতিরিক্ত সফ্টওয়্যার প্রয়োজন হয় না। তবে, যদি আপনি cURL ব্যবহার করতে না চান, তাহলে আপনি ভবিষ্যতে ব্যবহারের জন্য API অনুরোধগুলি কার্যকর করতে এবং সংরক্ষণ করতে Postman ব্যবহার করতে পারেন।
৩.২. অ্যাগ্রিগেশন সার্ভিস ইউসেজ বিভাগে, আপনি উভয় বিকল্প ব্যবহারের জন্য বিস্তারিত নির্দেশাবলী পাবেন। আপনি কোন পদ্ধতিটি ব্যবহার করবেন তা নির্ধারণ করতে এখনই সেগুলি পূর্বরূপ দেখতে পারেন। আপনি যদি পোস্টম্যান নির্বাচন করেন, তাহলে নিম্নলিখিত প্রাথমিক সেটআপটি সম্পাদন করুন।
১.৮.১. কর্মক্ষেত্র স্থাপন করুন
পোস্টম্যান অ্যাকাউন্টের জন্য সাইন আপ করুন। সাইন আপ করার পরে, আপনার জন্য স্বয়ংক্রিয়ভাবে একটি কর্মক্ষেত্র তৈরি হয়ে যাবে।
 একটি পোস্টম্যানের কর্মক্ষেত্র।
একটি পোস্টম্যানের কর্মক্ষেত্র।
যদি আপনার জন্য কোনও ওয়ার্কস্পেস তৈরি না করা হয়, তাহলে "ওয়ার্কস্পেস" শীর্ষ নেভিগেশন আইটেমে যান এবং "ওয়ার্কস্পেস তৈরি করুন" নির্বাচন করুন।
"খালি কর্মক্ষেত্র" নির্বাচন করুন, পরবর্তী ক্লিক করুন এবং এর নাম দিন "GCP গোপনীয়তা স্যান্ডবক্স"। "ব্যক্তিগত" নির্বাচন করুন এবং "তৈরি করুন" এ ক্লিক করুন।
আগে থেকে কনফিগার করা ওয়ার্কস্পেস JSON কনফিগারেশন এবং গ্লোবাল এনভায়রনমেন্ট ফাইলগুলি ডাউনলোড করুন।
"আমদানি" বোতামটি ব্যবহার করে "আমার কর্মক্ষেত্রে" উভয় JSON ফাইল আমদানি করুন।
 আমদানি বোতাম।
আমদানি বোতাম।
এটি আপনার জন্য createJob এবং getJob HTTP অনুরোধের সাথে "GCP Privacy Sandbox" সংগ্রহ তৈরি করবে।
১.৮.২। অনুমোদন সেট আপ করুন
"GCP প্রাইভেসি স্যান্ডবক্স" সংগ্রহে ক্লিক করুন এবং "অনুমোদন" ট্যাবে যান।
 অনুমোদন বোতাম।
অনুমোদন বোতাম।
তুমি "Bearer Token" পদ্ধতি ব্যবহার করবে। তোমার টার্মিনাল পরিবেশ থেকে, এই কমান্ডটি চালাও এবং আউটপুটটি কপি করো।
gcloud auth print-identity-token
তারপর, পোস্টম্যান অনুমোদন ট্যাবের "টোকেন" ক্ষেত্রে এই টোকেন মানটি পেস্ট করুন:
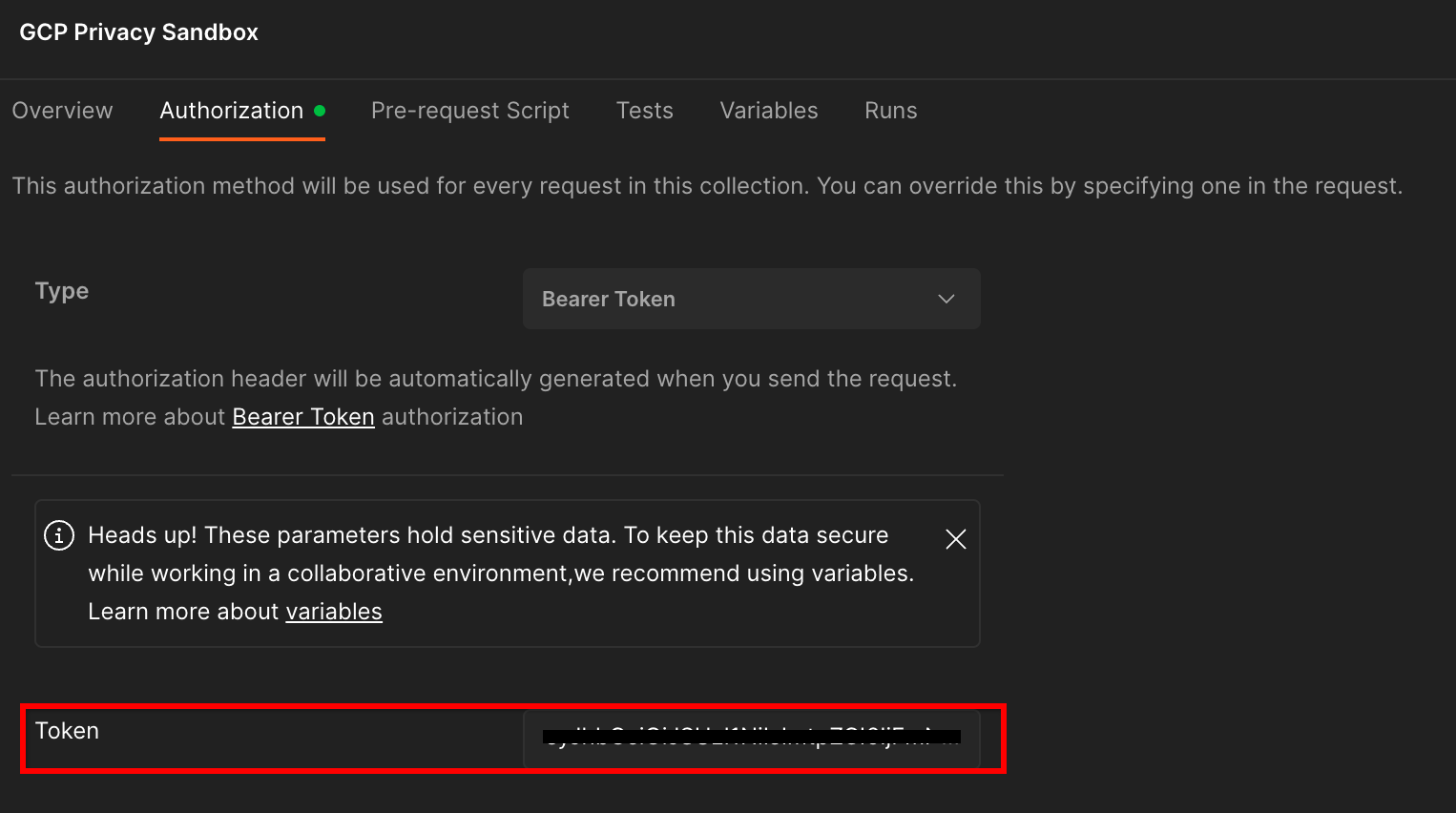 "টোকেন" ক্ষেত্র।
"টোকেন" ক্ষেত্র।
১.৮.৩. পরিবেশ স্থাপন করুন
উপরের ডানদিকের কোণায় "পরিবেশের দ্রুত চেহারা" বিভাগে যান:
 পরিবেশের দ্রুত দেখার বোতাম।
পরিবেশের দ্রুত দেখার বোতাম।
"সম্পাদনা" এ ক্লিক করুন এবং "পরিবেশ", "অঞ্চল" এবং "ক্লাউড-ফাংশন-আইডি" এর "বর্তমান মান" আপডেট করুন:
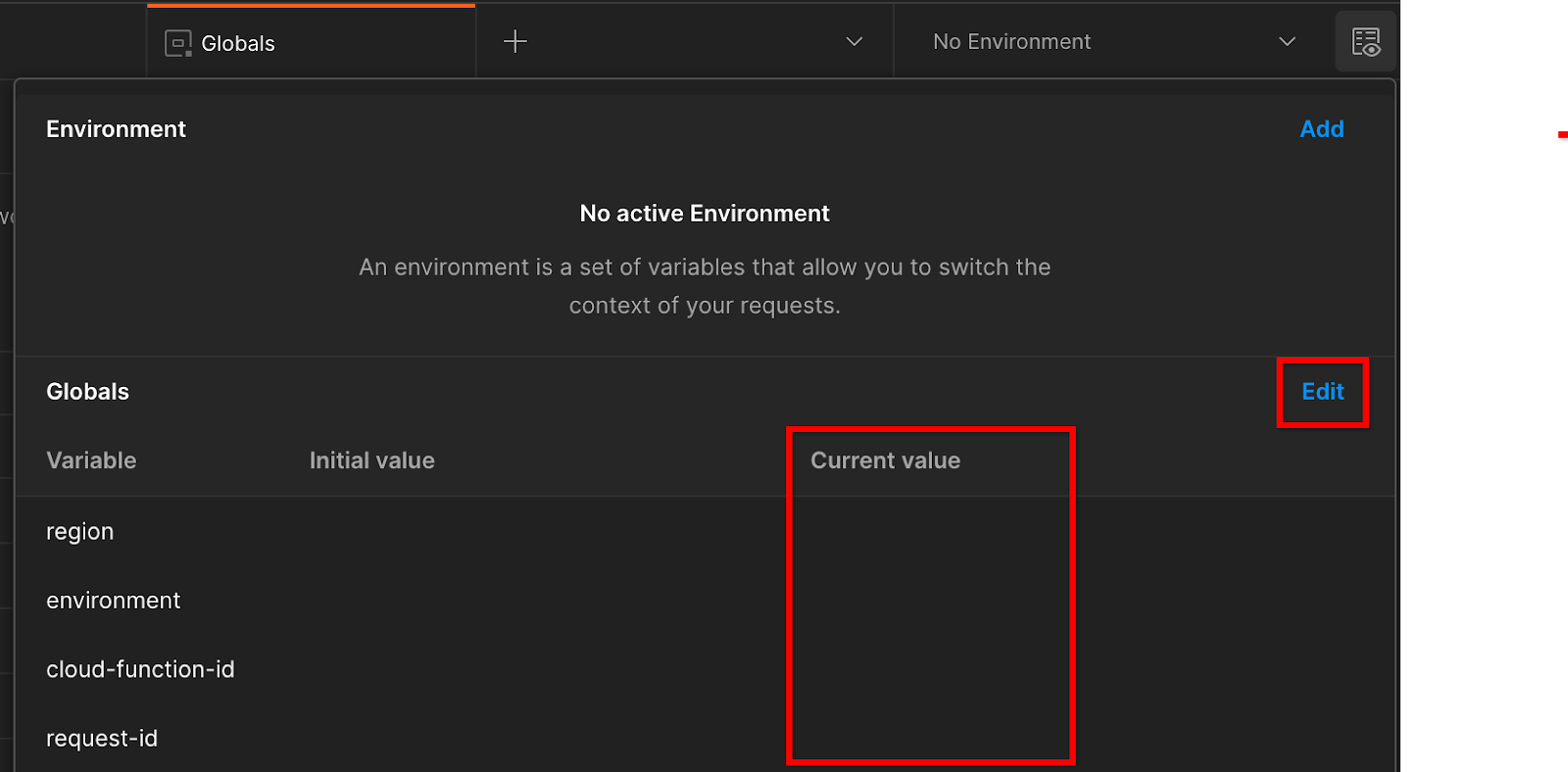 বর্তমান মান নির্ধারণ করুন।
বর্তমান মান নির্ধারণ করুন।
"request-id" আপাতত খালি রাখতে পারেন, কারণ আমরা পরে এটি পূরণ করব। অন্যান্য ক্ষেত্রগুলির জন্য, frontend_service_cloudfunction_url থেকে মানগুলি ব্যবহার করুন, যা Prerequisite 1.6-এ Terraform স্থাপনার সফল সমাপ্তির পরে ফিরে এসেছে। URL এই ফর্ম্যাটটি অনুসরণ করে: https://
২. ২. স্থানীয় পরীক্ষার কোডল্যাব
সম্পূর্ণ করার আনুমানিক সময়: <1 ঘন্টা
এনক্রিপ্ট না করা ডিবাগ রিপোর্ট ব্যবহার করে একত্রিতকরণ এবং সারাংশ প্রতিবেদন তৈরি করতে আপনি আপনার মেশিনের স্থানীয় পরীক্ষার সরঞ্জাম ব্যবহার করতে পারেন। শুরু করার আগে , যাচাই করুন যে আপনি "স্থানীয় পরীক্ষা" লেবেলযুক্ত সমস্ত পূর্বশর্ত পূরণ করেছেন।
কোডল্যাবের ধাপগুলি
ধাপ ২.১. ট্রিগার রিপোর্ট : রিপোর্ট সংগ্রহ করতে সক্ষম হওয়ার জন্য ব্যক্তিগত সমষ্টি প্রতিবেদন চালু করুন।
ধাপ ২.২. ডিবাগ AVRO রিপোর্ট তৈরি করুন : সংগৃহীত JSON রিপোর্টকে AVRO ফর্ম্যাটেড রিপোর্টে রূপান্তর করুন। এই ধাপটি বিজ্ঞাপন প্রযুক্তিবিদরা API রিপোর্টিং এন্ডপয়েন্ট থেকে রিপোর্ট সংগ্রহ করে JSON রিপোর্টগুলিকে AVRO ফর্ম্যাটেড রিপোর্টে রূপান্তর করার মতোই হবে।
ধাপ ২.৩. বাকেট কীগুলি পুনরুদ্ধার করুন : বাকেট কীগুলি বিজ্ঞাপন প্রযুক্তিবিদদের দ্বারা ডিজাইন করা হয়েছে। এই কোডল্যাবে, যেহেতু বাকেটগুলি পূর্বনির্ধারিত, তাই প্রদত্ত বাকেট কীগুলি পুনরুদ্ধার করুন।
ধাপ ২.৪. আউটপুট ডোমেইন AVRO তৈরি করুন : বাকেট কীগুলি পুনরুদ্ধার করা হয়ে গেলে, আউটপুট ডোমেইন AVRO ফাইল তৈরি করুন।
ধাপ ২.৫. সারাংশ প্রতিবেদন তৈরি করুন : স্থানীয় পরিবেশে সারাংশ প্রতিবেদন তৈরি করতে স্থানীয় পরীক্ষার সরঞ্জামটি ব্যবহার করুন।
ধাপ ২.৬. সারাংশ প্রতিবেদন পর্যালোচনা করুন : স্থানীয় পরীক্ষার সরঞ্জাম দ্বারা তৈরি সারাংশ প্রতিবেদন পর্যালোচনা করুন।
২.১. ট্রিগার রিপোর্ট
একটি ব্যক্তিগত সমষ্টি প্রতিবেদন ট্রিগার করতে, আপনি প্রাইভেসি স্যান্ডবক্স ডেমো সাইট (https://privacy-sandbox-demos-news.dev/?env=gcp) অথবা আপনার নিজস্ব সাইট (যেমন, https://adtechexample.com) ব্যবহার করতে পারেন। আপনি যদি নিজের সাইট ব্যবহার করেন এবং আপনি এখনও এনরোলমেন্ট এবং অ্যাটেস্টেশন এবং সমষ্টি পরিষেবা অনবোর্ডিং সম্পন্ন না করে থাকেন, তাহলে আপনাকে একটি Chrome ফ্ল্যাগ এবং CLI সুইচ ব্যবহার করতে হবে।
এই ডেমোর জন্য, আমরা প্রাইভেসি স্যান্ডবক্স ডেমো সাইট ব্যবহার করব। সাইটে যেতে লিঙ্কটি অনুসরণ করুন; তারপর, আপনি chrome://private-aggregation-internals এ রিপোর্টগুলি দেখতে পারেন:
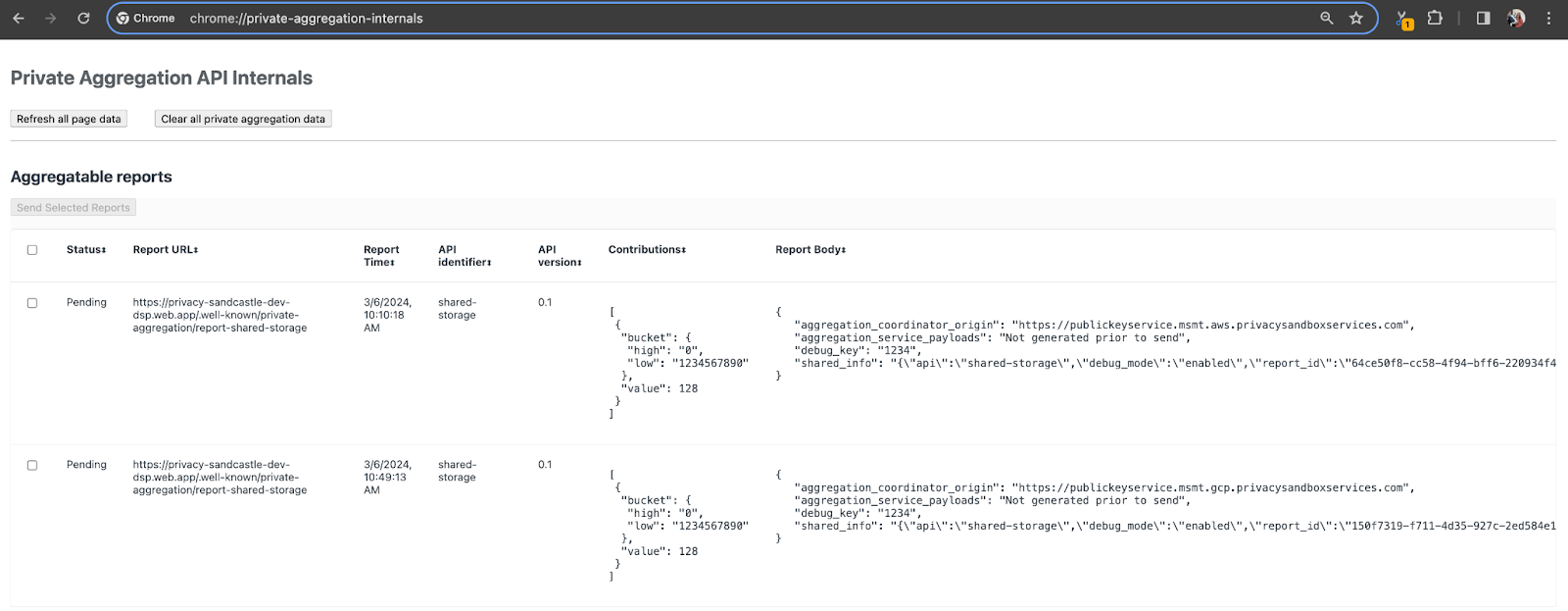 Chrome অভ্যন্তরীণ পৃষ্ঠা।
Chrome অভ্যন্তরীণ পৃষ্ঠা।
{reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage এন্ডপয়েন্টে পাঠানো রিপোর্টটি Chrome Internals পৃষ্ঠায় প্রদর্শিত রিপোর্টের "রিপোর্ট বডি" তেও পাওয়া যায়।
আপনি এখানে অনেক রিপোর্ট দেখতে পাবেন, কিন্তু এই কোডল্যাবের জন্য, গুগল ক্লাউড-নির্দিষ্ট এবং ডিবাগ এন্ডপয়েন্ট দ্বারা তৈরি করা অ্যাগ্রিগেটেবল রিপোর্ট ব্যবহার করুন । "রিপোর্ট URL"-এ "/debug/" থাকবে এবং "রিপোর্ট বডি"-এর aggregation_coordinator_origin field এই URL থাকবে: https://publickeyservice.msmt.gcp.privacysandboxservices.com।
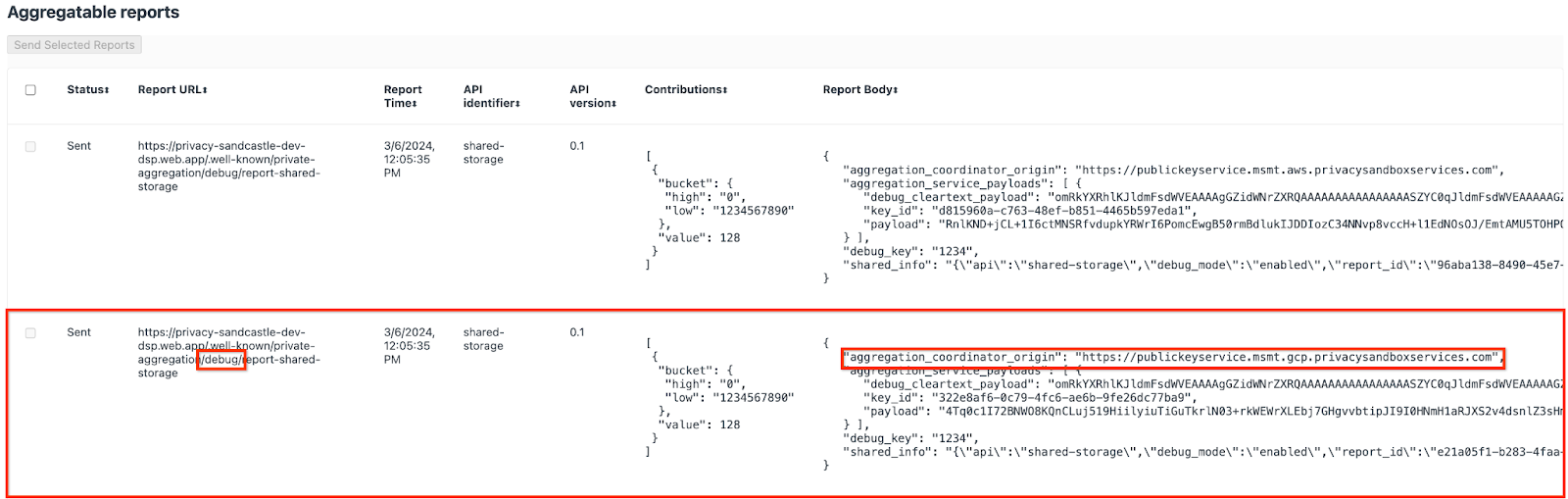 গুগল ক্লাউড ডিবাগ রিপোর্ট।
গুগল ক্লাউড ডিবাগ রিপোর্ট।
২.২. ডিবাগ এগ্রিগেটেবল রিপোর্ট তৈরি করুন
chrome://private-aggregation-internals এর "Report Body" তে পাওয়া রিপোর্টটি কপি করুন এবং privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar ফোল্ডারে (Prequesite 1.5 এ ডাউনলোড করা রিপোজিটরির মধ্যে) একটি JSON ফাইল তৈরি করুন।
এই উদাহরণে, আমরা লিনাক্স ব্যবহার করছি বলে vim ব্যবহার করছি। কিন্তু আপনি আপনার পছন্দের যেকোনো টেক্সট এডিটর ব্যবহার করতে পারেন।
vim report.json
রিপোর্টটি report.json এ পেস্ট করুন এবং আপনার ফাইলটি সংরক্ষণ করুন।
 রিপোর্টের JSON কোড।
রিপোর্টের JSON কোড।
একবার আপনার কাছে এটি হয়ে গেলে, ডিবাগ অ্যাগ্রিগেটেবল রিপোর্ট তৈরি করতে aggregatable_report_converter.jar ব্যবহার করুন। এটি আপনার বর্তমান ডিরেক্টরিতে report.avro নামে একটি অ্যাগ্রিগেটেবল রিপোর্ট তৈরি করে।
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
২.৩. রিপোর্ট থেকে বাকেট কীটি উদ্ধার করুন
output_domain.avro ফাইলটি তৈরি করতে, আপনার রিপোর্ট থেকে উদ্ধার করা যেতে পারে এমন বাকেট কীগুলির প্রয়োজন।
বাকেট কীগুলি বিজ্ঞাপন প্রযুক্তিবিদ দ্বারা ডিজাইন করা হয়। তবে, এই ক্ষেত্রে, সাইটের প্রাইভেসি স্যান্ডবক্স ডেমো বাকেট কীগুলি তৈরি করে। যেহেতু এই সাইটের জন্য ব্যক্তিগত সমষ্টি ডিবাগ মোডে রয়েছে, তাই আমরা "রিপোর্ট বডি" থেকে debug_cleartext_payload ব্যবহার করে বাকেট কীটি পেতে পারি।
রিপোর্ট বডি থেকে debug_cleartext_payload কপি করুন।
 ক্লিয়ারটেক্সট পেলোড ডিবাগ করুন।
ক্লিয়ারটেক্সট পেলোড ডিবাগ করুন।
goo.gle/ags-payload-decoder খুলুন এবং "INPUT" বাক্সে আপনার debug_cleartext_payload পেস্ট করুন এবং "Decode" এ ক্লিক করুন।
 ডিকোড বোতাম।
ডিকোড বোতাম।
পৃষ্ঠাটি বাকেট কী-এর দশমিক মান প্রদান করে। নিচে একটি নমুনা বাকেট কী দেওয়া হল।
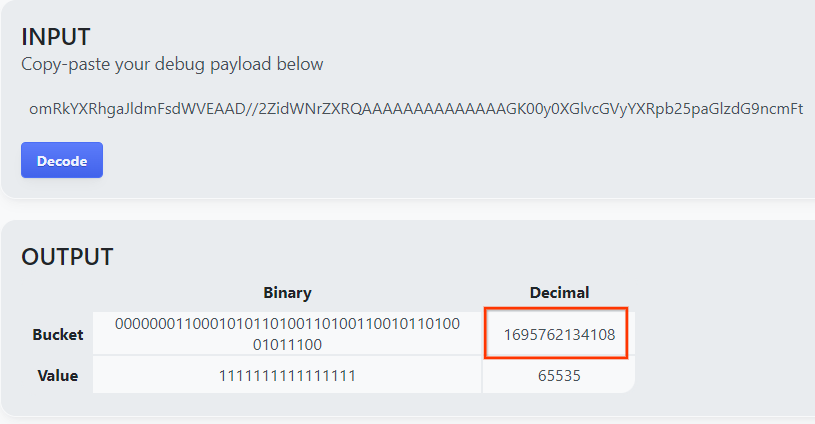 একটি নমুনা বালতি চাবি।
একটি নমুনা বালতি চাবি।
২.৪. আউটপুট ডোমেইন AVRO তৈরি করুন
এখন যেহেতু আমাদের কাছে বাকেট কী আছে, আসুন আমরা যে ফোল্ডারে কাজ করছি সেই ফোল্ডারেই output_domain.avro তৈরি করি। যাচাই করুন যে আপনি যে বাকেট কীটি উদ্ধার করেছেন তা দিয়ে বাকেট কীটি প্রতিস্থাপন করেছেন।
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
স্ক্রিপ্টটি আপনার বর্তমান ফোল্ডারে output_domain.avro ফাইল তৈরি করে।
২.৫. লোকাল টেস্টিং টুল ব্যবহার করে সারাংশ প্রতিবেদন তৈরি করুন
আমরা নিম্নলিখিত কমান্ড ব্যবহার করে সারাংশ প্রতিবেদন তৈরি করতে Prerequisite 1.3 এ ডাউনলোড করা LocalTestingTool_{version}.jar ব্যবহার করব। {version} কে আপনার ডাউনলোড করা সংস্করণ দিয়ে প্রতিস্থাপন করুন। LocalTestingTool_{version}.jar কে বর্তমান ডিরেক্টরিতে স্থানান্তর করতে ভুলবেন না, অথবা এর বর্তমান অবস্থান উল্লেখ করার জন্য একটি আপেক্ষিক পথ যোগ করুন।
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
কমান্ডটি চালানোর পরে আপনি নিচের মতো কিছু দেখতে পাবেন। এটি সম্পন্ন হওয়ার পরে একটি রিপোর্ট output.avro তৈরি করা হবে।
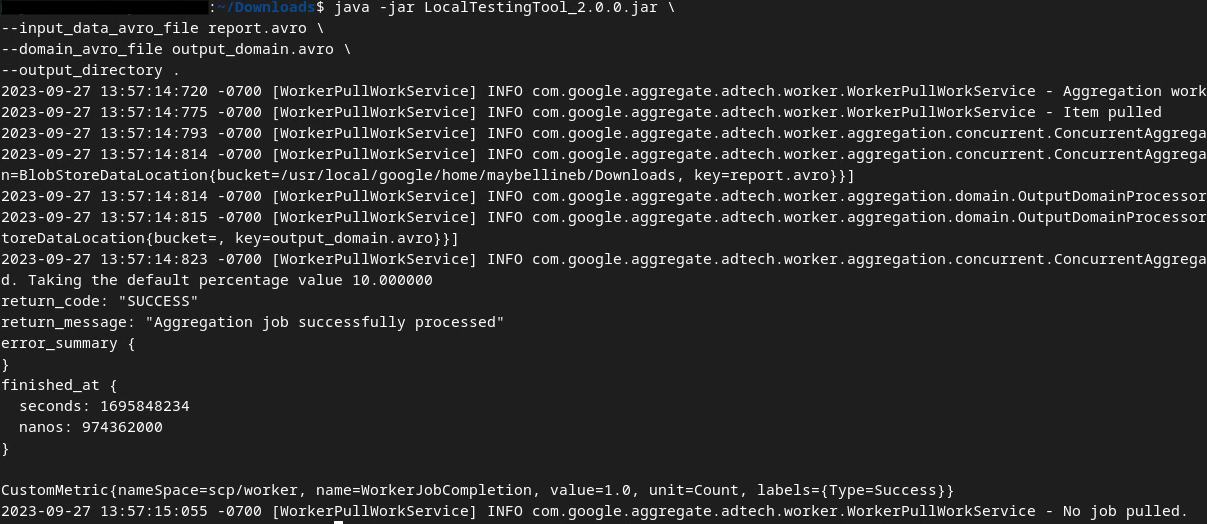 আউটপুট AVRO
আউটপুট AVRO
২.৬। সারাংশ প্রতিবেদনটি পর্যালোচনা করুন।
তৈরি করা সারাংশ প্রতিবেদনটি AVRO ফর্ম্যাটে। এটি পড়তে সক্ষম হওয়ার জন্য, আপনাকে এটি AVRO থেকে JSON ফর্ম্যাটে রূপান্তর করতে হবে। আদর্শভাবে, বিজ্ঞাপন প্রযুক্তিবিদকে AVRO প্রতিবেদনগুলিকে JSON-এ রূপান্তর করার জন্য কোড লিখতে হবে।
AVRO রিপোর্টটিকে JSON-এ রূপান্তর করতে আমরা aggregatable_report_converter.jar ব্যবহার করব।
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
এটি নিম্নলিখিতটির মতো একটি প্রতিবেদন প্রদান করে। একই ডিরেক্টরিতে তৈরি একটি প্রতিবেদন output.json সহ।
 আউটপুট JSON
আউটপুট JSON
কোডল্যাব সম্পূর্ণ!
সারাংশ: আপনি একটি ডিবাগ রিপোর্ট সংগ্রহ করেছেন, একটি আউটপুট ডোমেন ফাইল তৈরি করেছেন এবং স্থানীয় পরীক্ষার সরঞ্জাম ব্যবহার করে একটি সারাংশ রিপোর্ট তৈরি করেছেন যা সমষ্টি পরিষেবার সমষ্টি আচরণকে অনুকরণ করে।
পরবর্তী ধাপ: এখন যেহেতু আপনি লোকাল টেস্টিং টুলটি ব্যবহার করে দেখেছেন, তাই আপনার নিজের পরিবেশে অ্যাগ্রিগেশন সার্ভিসের লাইভ ডিপ্লয়মেন্টের মাধ্যমে একই অনুশীলনটি চেষ্টা করতে পারেন। "অ্যাগ্রিগেশন সার্ভিস" মোডের জন্য সবকিছু সেট আপ করেছেন কিনা তা নিশ্চিত করার জন্য পূর্বশর্তগুলি পুনরায় দেখুন, তারপর ধাপ 3 এ যান।
৩. ৩. একত্রীকরণ পরিষেবা কোডল্যাব
সম্পন্ন করার আনুমানিক সময়: ১ ঘন্টা
শুরু করার আগে , যাচাই করুন যে আপনি "সমষ্টি পরিষেবা" লেবেলযুক্ত সমস্ত পূর্বশর্ত পূরণ করেছেন।
কোডল্যাবের ধাপগুলি
ধাপ ৩.১. সমষ্টি পরিষেবা ইনপুট তৈরি : সমষ্টি পরিষেবার জন্য ব্যাচ করা সমষ্টি পরিষেবা প্রতিবেদন তৈরি করুন।
- ধাপ ৩.১.১। ট্রিগার রিপোর্ট
- ধাপ ৩.১.২। সমষ্টিগত প্রতিবেদন সংগ্রহ করুন
- ধাপ ৩.১.৩. রিপোর্টগুলিকে AVRO তে রূপান্তর করুন
- ধাপ ৩.১.৪। আউটপুট_ডোমেইন AVRO তৈরি করুন
- ধাপ ৩.১.৫। রিপোর্টগুলিকে ক্লাউড স্টোরেজ বাকেটে সরান
ধাপ ৩.২. সমষ্টি পরিষেবার ব্যবহার : সারাংশ প্রতিবেদন তৈরি করতে এবং সারাংশ প্রতিবেদনগুলি পর্যালোচনা করতে সমষ্টি পরিষেবা API ব্যবহার করুন।
- ধাপ ৩.২.১. ব্যাচে
createJobএন্ডপয়েন্ট ব্যবহার করা - ধাপ ৩.২.২. ব্যাচের অবস্থা পুনরুদ্ধার করতে
getJobEndpoint ব্যবহার করা - ধাপ ৩.২.৩. সারাংশ প্রতিবেদন পর্যালোচনা করা
৩.১. একত্রীকরণ পরিষেবা ইনপুট তৈরি
অ্যাগ্রিগেশন সার্ভিসে ব্যাচিংয়ের জন্য AVRO রিপোর্ট তৈরি করতে এগিয়ে যান। এই ধাপগুলিতে শেল কমান্ডগুলি Google ক্লাউডের ক্লাউড শেলের মধ্যে চালানো যেতে পারে (যতক্ষণ না পূর্বশর্তগুলির নির্ভরতাগুলি আপনার ক্লাউড শেল পরিবেশে ক্লোন করা হয়) অথবা স্থানীয় এক্সিকিউশন পরিবেশে।
৩.১.১। ট্রিগার রিপোর্ট
সাইটে যেতে লিঙ্কটি অনুসরণ করুন; তারপর, আপনি chrome://private-aggregation-internals এ রিপোর্টগুলি দেখতে পারেন:
Chrome ইন্টার্নাল পৃষ্ঠা
{reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage এন্ডপয়েন্টে পাঠানো রিপোর্টটি Chrome Internals পৃষ্ঠায় প্রদর্শিত রিপোর্টের "রিপোর্ট বডি" তেও পাওয়া যায়।
আপনি এখানে অনেক রিপোর্ট দেখতে পাবেন, কিন্তু এই কোডল্যাবের জন্য, গুগল ক্লাউড-নির্দিষ্ট এবং ডিবাগ এন্ডপয়েন্ট দ্বারা তৈরি করা অ্যাগ্রিগেটেবল রিপোর্ট ব্যবহার করুন । "রিপোর্ট URL"-এ "/debug/" থাকবে এবং "রিপোর্ট বডি"-এর aggregation_coordinator_origin field এই URL থাকবে: https://publickeyservice.msmt.gcp.privacysandboxservices.com।
গুগল ক্লাউড ডিবাগ রিপোর্ট।
৩.১.২. সমষ্টিগত প্রতিবেদন সংগ্রহ করুন
আপনার সংশ্লিষ্ট API-এর .well-known endpoints থেকে আপনার সমষ্টিগত প্রতিবেদন সংগ্রহ করুন।
- ব্যক্তিগত সমষ্টি:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - অ্যাট্রিবিউশন রিপোর্টিং - সারাংশ রিপোর্ট:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
এই কোডল্যাবের জন্য, আমরা রিপোর্ট সংগ্রহ ম্যানুয়ালি করি। উৎপাদনে, বিজ্ঞাপন প্রযুক্তিবিদদের কাছ থেকে আশা করা হয় যে তারা প্রোগ্রাম্যাটিকভাবে রিপোর্ট সংগ্রহ এবং রূপান্তর করবেন।
চলুন, chrome://private-aggregation-internals থেকে "Report Body" তে JSON রিপোর্টটি কপি করি।
এই উদাহরণে, আমরা লিনাক্স ব্যবহার করছি বলে vim ব্যবহার করছি। কিন্তু আপনি আপনার পছন্দের যেকোনো টেক্সট এডিটর ব্যবহার করতে পারেন।
vim report.json
রিপোর্টটি report.json এ পেস্ট করুন এবং আপনার ফাইলটি সংরক্ষণ করুন।
JSON রিপোর্ট করুন
৩.১.৩. রিপোর্টগুলিকে AVRO তে রূপান্তর করুন
.well-known endpoints থেকে প্রাপ্ত রিপোর্টগুলি JSON ফর্ম্যাটে থাকে এবং AVRO রিপোর্ট ফর্ম্যাটে রূপান্তর করতে হয়। JSON রিপোর্টটি হয়ে গেলে, report.json কোথায় সংরক্ষণ করা হয় সেখানে যান এবং ডিবাগ aggregatable রিপোর্ট তৈরি করতে aggregatable_report_converter.jar ব্যবহার করুন। এটি আপনার বর্তমান ডিরেক্টরিতে report.avro নামে একটি aggregatable রিপোর্ট তৈরি করে।
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
৩.১.৪। আউটপুট_ডোমেইন AVRO তৈরি করুন
output_domain.avro ফাইলটি তৈরি করতে, আপনার রিপোর্ট থেকে উদ্ধার করা যেতে পারে এমন বাকেট কীগুলির প্রয়োজন।
বাকেট কীগুলি বিজ্ঞাপন প্রযুক্তিবিদ দ্বারা ডিজাইন করা হয়। তবে, এই ক্ষেত্রে, সাইটের প্রাইভেসি স্যান্ডবক্স ডেমো বাকেট কীগুলি তৈরি করে। যেহেতু এই সাইটের জন্য ব্যক্তিগত সমষ্টি ডিবাগ মোডে রয়েছে, তাই আমরা "রিপোর্ট বডি" থেকে debug_cleartext_payload ব্যবহার করে বাকেট কীটি পেতে পারি।
রিপোর্ট বডি থেকে debug_cleartext_payload কপি করুন।
ক্লিয়ারটেক্সট পেলোড ডিবাগ করুন।
goo.gle/ags-payload-decoder খুলুন এবং "INPUT" বাক্সে আপনার debug_cleartext_payload পেস্ট করুন এবং "Decode" এ ক্লিক করুন।
ডিকোড বোতাম।
পৃষ্ঠাটি বাকেট কী-এর দশমিক মান প্রদান করে। নিচে একটি নমুনা বাকেট কী দেওয়া হল।
একটি নমুনা বালতি চাবি।
এখন যেহেতু আমাদের কাছে বাকেট কী আছে, আসুন আমরা যে ফোল্ডারে কাজ করছি সেই ফোল্ডারেই output_domain.avro তৈরি করি। যাচাই করুন যে আপনি যে বাকেট কীটি উদ্ধার করেছেন তা দিয়ে বাকেট কীটি প্রতিস্থাপন করেছেন।
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
স্ক্রিপ্টটি আপনার বর্তমান ফোল্ডারে output_domain.avro ফাইল তৈরি করে।
৩.১.৫। রিপোর্টগুলিকে ক্লাউড স্টোরেজ বাকেটে স্থানান্তর করুন
AVRO রিপোর্ট এবং আউটপুট ডোমেইন তৈরি হয়ে গেলে, রিপোর্ট এবং আউটপুট ডোমেইনগুলিকে ক্লাউড স্টোরেজের বাকেটে স্থানান্তর করতে এগিয়ে যান (যা আপনি পূর্বশর্ত 1.6 এ উল্লেখ করেছেন)।
যদি আপনার স্থানীয় পরিবেশে gcloud CLI সেটআপ থাকে, তাহলে সংশ্লিষ্ট ফোল্ডারে ফাইলগুলি অনুলিপি করতে নিম্নলিখিত কমান্ডগুলি ব্যবহার করুন।
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
অন্যথায়, ফাইলগুলি ম্যানুয়ালি আপনার বাকেটে আপলোড করুন। "reports" নামে একটি ফোল্ডার তৈরি করুন এবং সেখানে report.avro ফাইলটি আপলোড করুন। "output_domains" নামে একটি ফোল্ডার তৈরি করুন এবং সেখানে output_domain.avro ফাইলটি আপলোড করুন।
৩.২. সমষ্টি পরিষেবার ব্যবহার
পূর্বশর্ত ১.৮-এ মনে রাখবেন যে আপনি অ্যাগ্রিগেশন সার্ভিস এন্ডপয়েন্টগুলিতে API অনুরোধ করার জন্য curl অথবা Postman নির্বাচন করেছেন। উভয় বিকল্পের জন্য নির্দেশাবলী নিম্নরূপ।
যদি আপনার কাজটি কোনও ত্রুটির কারণে ব্যর্থ হয়, তাহলে কীভাবে এগিয়ে যাবেন সে সম্পর্কে আরও তথ্যের জন্য GitHub-এ আমাদের সমস্যা সমাধানের ডকুমেন্টেশন দেখুন।
৩.২.১. ব্যাচে createJob এন্ডপয়েন্ট ব্যবহার করা
চাকরি তৈরি করতে নিম্নলিখিত কার্ল অথবা পোস্টম্যান নির্দেশাবলীর যেকোনো একটি ব্যবহার করুন।
কার্ল করা
আপনার "টার্মিনালে", একটি অনুরোধের বডি ফাইল ( body.json ) তৈরি করুন এবং নিম্নলিখিত JSON অবজেক্টটি পেস্ট করুন। প্লেসহোল্ডার মানগুলি আপডেট করতে ভুলবেন না। প্রতিটি ক্ষেত্র কী প্রতিনিধিত্ব করে সে সম্পর্কে আরও তথ্যের জন্য এই API ডকুমেন্টেশনটি দেখুন।
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
নিম্নলিখিত অনুরোধটি কার্যকর করুন। কার্ল অনুরোধের URL-এর স্থানধারকগুলিকে frontend_service_cloudfunction_url থেকে মান দিয়ে প্রতিস্থাপন করুন, যা Prerequisite 1.6-এ Terraform স্থাপনের সফল সমাপ্তির পরে আউটপুট হবে।
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
অ্যাগ্রিগেশন সার্ভিস কর্তৃক অনুরোধটি গৃহীত হওয়ার পরে আপনি একটি HTTP 202 প্রতিক্রিয়া পাবেন। অন্যান্য সম্ভাব্য প্রতিক্রিয়া কোডগুলি API স্পেসিফিকেশনে নথিভুক্ত করা হয়েছে।
ডাকপিয়ন
createJob এন্ডপয়েন্টের জন্য, অ্যাগ্রিগেশন সার্ভিসকে অ্যাগ্রিগেটেবল রিপোর্ট, আউটপুট ডোমেন এবং সারাংশ রিপোর্টের অবস্থান এবং ফাইলের নাম প্রদান করার জন্য একটি অনুরোধ বডি প্রয়োজন।
createJob অনুরোধের "বডি" ট্যাবে নেভিগেট করুন:
 বডি ট্যাব
বডি ট্যাব
প্রদত্ত JSON-এর মধ্যে স্থানধারকগুলি প্রতিস্থাপন করুন। এই ক্ষেত্রগুলি এবং তারা কী প্রতিনিধিত্ব করে সে সম্পর্কে আরও তথ্যের জন্য, API ডকুমেন্টেশন দেখুন।
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
createJob API অনুরোধটি "পাঠান":
 পাঠান বোতাম
পাঠান বোতাম
প্রতিক্রিয়া কোডটি পৃষ্ঠার নীচের অর্ধেক অংশে পাওয়া যাবে:
 প্রতিক্রিয়া কোড
প্রতিক্রিয়া কোড
অ্যাগ্রিগেশন সার্ভিস কর্তৃক অনুরোধটি গৃহীত হওয়ার পরে আপনি একটি HTTP 202 প্রতিক্রিয়া পাবেন। অন্যান্য সম্ভাব্য প্রতিক্রিয়া কোডগুলি API স্পেসিফিকেশনে নথিভুক্ত করা হয়েছে।
৩.২.২. ব্যাচের অবস্থা পুনরুদ্ধারের জন্য getJob Endpoint ব্যবহার করা
চাকরি পেতে নিচের কার্ল অথবা পোস্টম্যান নির্দেশাবলীর যেকোনো একটি ব্যবহার করুন।
কার্ল করা
আপনার টার্মিনালে নিম্নলিখিত অনুরোধটি কার্যকর করুন। URL-এর স্থানধারকগুলিকে frontend_service_cloudfunction_url থেকে মান দিয়ে প্রতিস্থাপন করুন, যা createJob অনুরোধের জন্য ব্যবহৃত URL-এর মতোই। "job_request_id"-এর জন্য, createJob এন্ডপয়েন্ট দিয়ে তৈরি করা কাজের মান ব্যবহার করুন।
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
ফলাফলটি আপনার চাকরির অনুরোধের স্থিতি 200 HTTP স্থিতি সহ ফেরত দেবে। অনুরোধ "বডি" তে job_status , return_message এবং error_messages (যদি চাকরিটি ত্রুটিপূর্ণ হয়ে থাকে) এর মতো প্রয়োজনীয় তথ্য রয়েছে।
ডাকপিয়ন
চাকরির অনুরোধের অবস্থা পরীক্ষা করতে, আপনি getJob এন্ডপয়েন্ট ব্যবহার করতে পারেন। getJob অনুরোধের "প্যারামিটার" বিভাগে, job_request_id মানটি createJob অনুরোধে পাঠানো job_request_id এ আপডেট করুন।
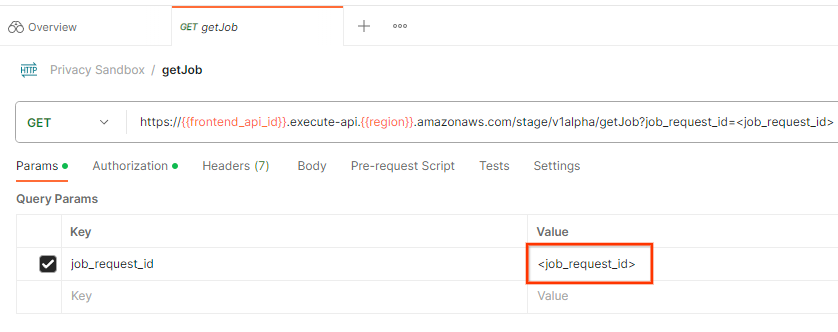 চাকরির অনুরোধ আইডি
চাকরির অনুরোধ আইডি
getJob অনুরোধটি "পাঠান":
 পাঠান বোতাম
পাঠান বোতাম
ফলাফলটি আপনার চাকরির অনুরোধের স্থিতি 200 HTTP স্থিতি সহ ফেরত দেবে। অনুরোধ "বডি" তে job_status , return_message এবং error_messages (যদি চাকরিটি ত্রুটিপূর্ণ হয়ে থাকে) এর মতো প্রয়োজনীয় তথ্য রয়েছে।
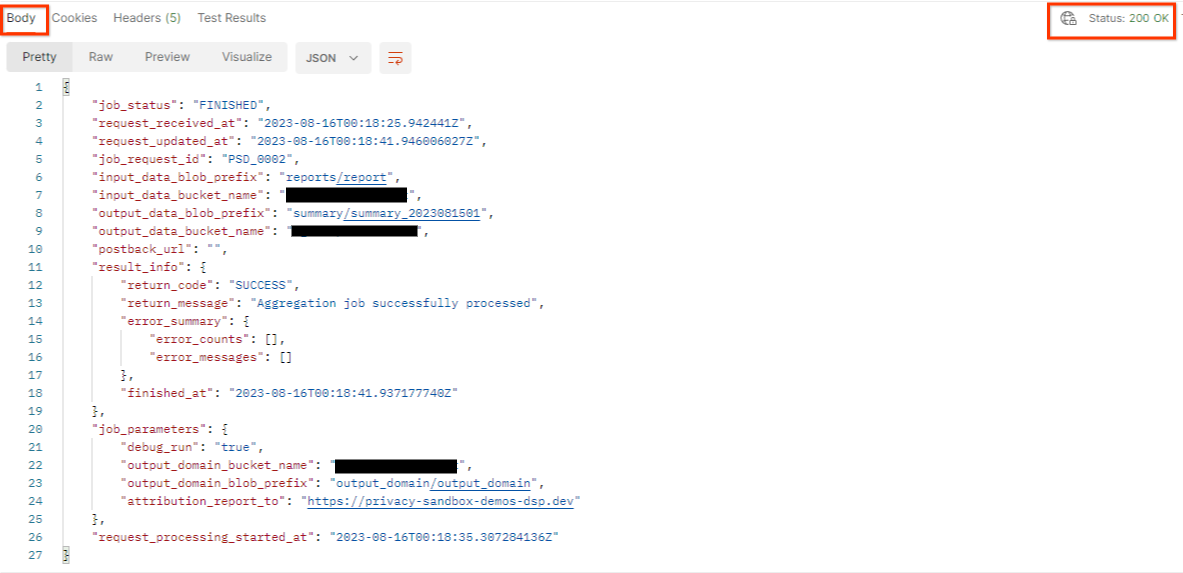 প্রতিক্রিয়া JSON
প্রতিক্রিয়া JSON
৩.২.৩. সারাংশ প্রতিবেদন পর্যালোচনা করা
আপনার আউটপুট ক্লাউড স্টোরেজ বাকেটে আপনার সারাংশ প্রতিবেদনটি পাওয়ার পর, আপনি এটি আপনার স্থানীয় পরিবেশে ডাউনলোড করতে পারেন। সারাংশ প্রতিবেদনগুলি AVRO ফর্ম্যাটে থাকে এবং JSON-এ রূপান্তরিত করা যায়। আপনি এই কমান্ড ব্যবহার করে আপনার প্রতিবেদনটি পড়তে aggregatable_report_converter.jar ব্যবহার করতে পারেন।
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
এটি প্রতিটি বাকেট কী-এর সমষ্টিগত মানের একটি json প্রদান করে যা দেখতে নিচের মতো।
 সারসংক্ষেপ প্রতিবেদন।
সারসংক্ষেপ প্রতিবেদন।
যদি আপনার createJob অনুরোধে debug_run সত্য হিসেবে অন্তর্ভুক্ত থাকে, তাহলে আপনি output_data_blob_prefix এ অবস্থিত ডিবাগ ফোল্ডারে আপনার সারাংশ প্রতিবেদনটি পেতে পারেন। প্রতিবেদনটি AVRO ফর্ম্যাটে এবং পূর্ববর্তী কমান্ড ব্যবহার করে JSON-এ রূপান্তর করা যেতে পারে।
রিপোর্টটিতে বাকেট কী, অশব্দহীন মেট্রিক এবং সারাংশ প্রতিবেদন তৈরির জন্য অশব্দহীন মেট্রিকের সাথে যোগ করা শব্দ রয়েছে। রিপোর্টটি নিম্নলিখিতটির মতোই।
 নয়েজড রিপোর্ট
নয়েজড রিপোর্ট
টীকাগুলিতে "in_reports" বা "in_domain" (অথবা উভয়) থাকে, যার অর্থ:
- in_reports - বাকেট কীটি সমষ্টিগত প্রতিবেদনের ভিতরে উপলব্ধ।
- in_domain - বাকেট কীটি output_domain AVRO ফাইলের ভিতরে পাওয়া যায়।
কোডল্যাব সম্পূর্ণ!
সারাংশ: আপনি আপনার নিজস্ব ক্লাউড পরিবেশে অ্যাগ্রিগেশন সার্ভিস স্থাপন করেছেন, একটি ডিবাগ রিপোর্ট সংগ্রহ করেছেন, একটি আউটপুট ডোমেন ফাইল তৈরি করেছেন, এই ফাইলগুলিকে একটি ক্লাউড স্টোরেজ বাকেটে সংরক্ষণ করেছেন এবং একটি সফল কাজ চালিয়েছেন!
পরবর্তী ধাপ: আপনার পরিবেশে অ্যাগ্রিগেশন সার্ভিস ব্যবহার চালিয়ে যান, অথবা ধাপ ৪-এ দেওয়া ক্লিন-আপ নির্দেশাবলী অনুসরণ করে আপনার তৈরি করা ক্লাউড রিসোর্সগুলি মুছে ফেলুন।
৪. ৪. পরিষ্কার-পরিচ্ছন্নতা
Terraform ব্যবহার করে Aggregation Service-এর জন্য তৈরি করা রিসোর্সগুলি মুছে ফেলতে, adtech_setup এবং dev (অথবা অন্যান্য পরিবেশ) ফোল্ডারে destroy কমান্ডটি ব্যবহার করুন:
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
আপনার সমষ্টিগত প্রতিবেদন এবং সারাংশ প্রতিবেদন ধারণকারী ক্লাউড স্টোরেজ বাকেটটি মুছে ফেলার জন্য:
$ gcloud storage buckets delete gs://my-bucket
আপনি আপনার Chrome কুকি সেটিংসকে Prerequisite 1.2 থেকে পূর্ববর্তী অবস্থায় ফিরিয়ে আনতেও পারেন।
৫. ৫. পরিশিষ্ট
উদাহরণ adtech_setup.auto.tfvars ফাইল
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
উদাহরণ dev.auto.tfvars ফাইল
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20