
1. 1. דרישות מוקדמות
זמן משוער לסיום: שעה עד שעתיים
יש 2 מצבים לביצוע ה-codelab הזה: בדיקה מקומית או Aggregation Service. במצב בדיקה מקומית נדרשים מחשב מקומי ודפדפן Chrome (לא נדרש שימוש במשאב Google Cloud או יצירה שלו). במצב Aggregation Service נדרש פריסה מלאה של Aggregation Service ב-Google Cloud.
כדי לבצע את ה-codelab הזה בכל אחד מהמצבים, צריך לעמוד בכמה דרישות מוקדמות. כל דרישה מסומנת בהתאם, אם היא נדרשת לבדיקה מקומית או לשירות הצבירה.
1.1. השלמת ההרשמה והאימות (Aggregation Service)
כדי להשתמש בממשקי ה-API של ארגז החול לפרטיות, צריך לוודא שסיימתם את תהליך ההרשמה והאישור גם ב-Chrome וגם ב-Android.
1.2. הפעלת ממשקי API לשמירה על פרטיות בפרסום (בדיקה מקומית ושירות צבירה)
אנחנו נשתמש בארגז החול לפרטיות, ולכן מומלץ להפעיל את ממשקי ה-API של ארגז החול לפרטיות לפרסום.
בדפדפן, עוברים אל chrome://settings/adPrivacy ומפעילים את כל ממשקי ה-API של פרטיות המודעות.
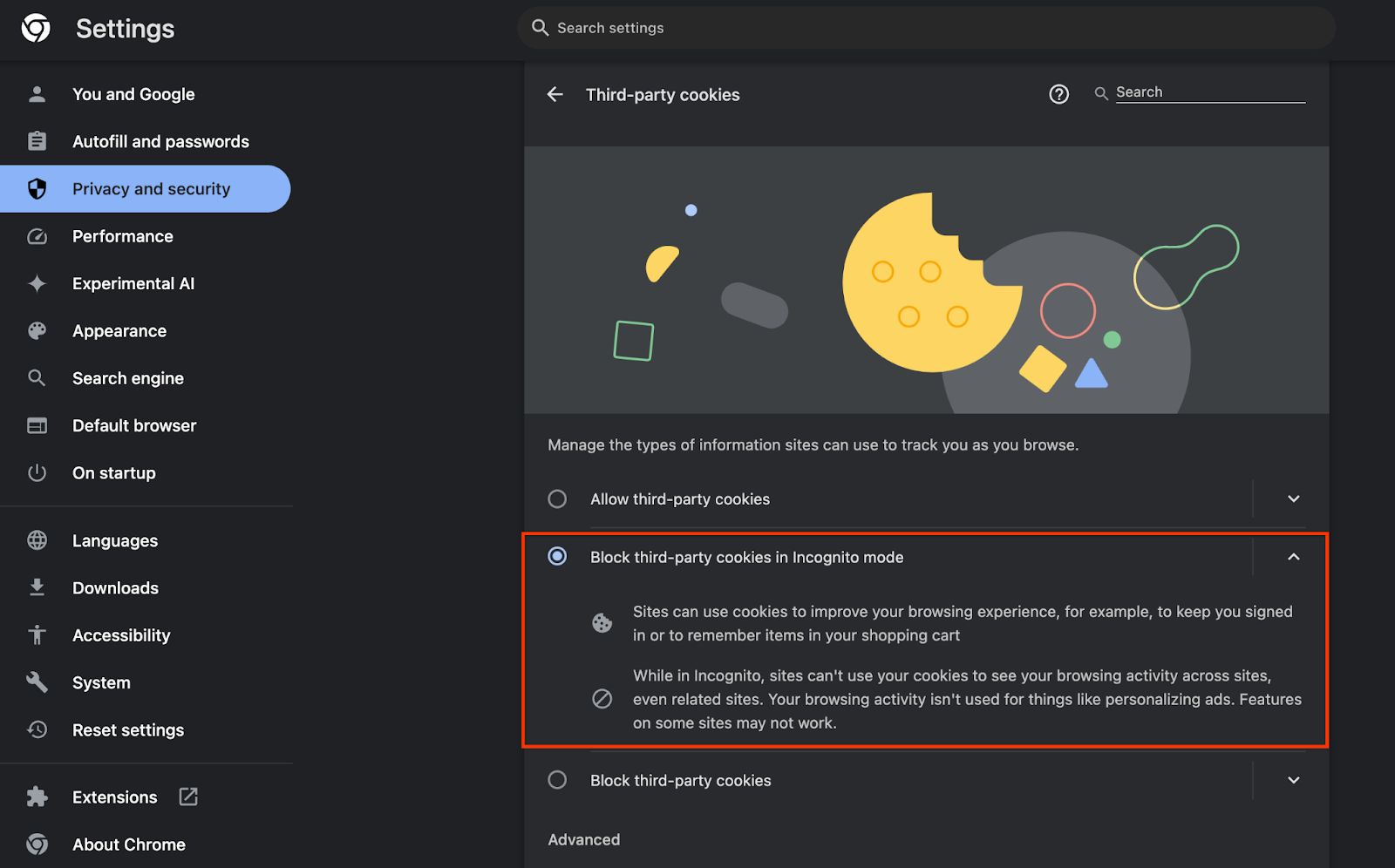
בנוסף, צריך לוודא שקובצי Cookie של צד שלישי מופעלים.
באתר chrome://settings/cookies, מוודאים שקובצי Cookie של צד שלישי לא נחסמים. יכול להיות שיוצגו אפשרויות שונות בתפריט ההגדרות הזה, בהתאם לגרסת Chrome שלכם, אבל ההגדרות המקובלות כוללות:
- "Block all third-party cookies" (חסימת כל קובצי ה-Cookie של צד שלישי) = מושבת
- "Block third-party cookies" (חסימת קובצי Cookie של צד שלישי) = DISABLED (מושבת)
- "Block third-party cookies in Incognito mode" (חסימת קובצי Cookie של צד שלישי במצב פרטי) = ENABLED (מופעל)
 הפעלת קובצי Cookie
הפעלת קובצי Cookie
1.3. הורדת הכלי לבדיקה מקומית (בדיקה מקומית)
כדי לבצע בדיקה מקומית, צריך להוריד את הכלי לבדיקה מקומית. הכלי ייצור דוחות סיכום מדוחות הניפוי באגים הלא מוצפנים.
אפשר להוריד את כלי הבדיקה המקומי מארכיוני ה-JAR של Cloud Functions ב-GitHub. היא צריכה להיקרא LocalTestingTool_{version}.jar.
1.4. אימות ההתקנה של JAVA JRE (שירות בדיקות מקומי ושירות צבירה)
פותחים את Terminal ומשתמשים ב-java --version כדי לבדוק אם Java או openJDK מותקנים במחשב.
 בדיקת הגרסה של Java.
בדיקת הגרסה של Java.
אם היא לא מותקנת, אפשר להוריד ולהתקין אותה מאתר Java או מאתר openJDK.
1.5. הורדת aggregatable_report_converter (בדיקה מקומית ו-Aggregation Service)
אפשר להוריד עותק של aggregatable_report_converter ממאגר ההדגמות של ארגז החול לפרטיות ב-GitHub. במאגר GitHub מוזכר שימוש ב-IntelliJ או ב-Eclipse, אבל אף אחת מהן לא נדרשת. אם אתם לא משתמשים בכלים האלה, אתם יכולים להוריד את קובץ ה-JAR לסביבה המקומית.
1.6. הגדרת סביבת Cloud Platform (Aggregation Service)
כדי להשתמש ב-Aggregation Service, צריך להשתמש בסביבת מחשוב אמינה (TEE) שמשתמשת בספק שירותי ענן. ב-codelab הזה, שירות הצבירה יופעל ב-Google Cloud, אבל יש גם תמיכה ב-AWS.
כדי להגדיר את ה-CLI של gcloud, להוריד קבצים בינאריים ומודולים של Terraform וליצור משאבי Google Cloud עבור שירות הצבירה, צריך לפעול לפי הוראות הפריסה ב-GitHub.
השלבים העיקריים בהוראות הפריסה:
- מגדירים את ה-CLI של gcloud ואת Terraform בסביבה.
- יוצרים קטגוריה של Cloud Storage לאחסון מצב Terraform.
- מורידים את יחסי התלות.
- מעדכנים את
adtech_setup.auto.tfvarsומריצים אתadtech_setupTerraform. בנספח מופיעה דוגמה לקובץadtech_setup.auto.tfvars. שימו לב לשם של מאגר הנתונים שנוצר כאן – נשתמש בו ב-codelab כדי לאחסן את הקבצים שניצור. - מעדכנים את
dev.auto.tfvars, מתחזים לחשבון השירות של הפריסה ומריצים אתdevTerraform. בנספח מופיעה דוגמה לקובץdev.auto.tfvars. - אחרי שהפריסה מסתיימת, מעתיקים את
frontend_service_cloudfunction_urlמהפלט של Terraform. תצטרכו אותו כדי לשלוח בקשות ל-Aggregation Service בשלבים הבאים.
1.7. השלמת תהליך ההצטרפות ל-Aggregation Service (Aggregation Service)
כדי להשתמש ב-Aggregation Service, צריך להצטרף לתיאום. ממלאים את טופס ההצטרפות לשירות האגרגציה. צריך לציין את אתר הדיווח ופרטים נוספים, לבחור באפשרות Google Cloud ולהזין את כתובת חשבון השירות. חשבון השירות הזה נוצר בדרישה המוקדמת הקודמת (1.6. הגדרת סביבת Google Cloud). (הערה: אם משתמשים בשמות שמוגדרים כברירת מחדל, חשבון השירות יתחיל ב-worker-sa@).
השלמת תהליך ההצטרפות יכולה להימשך עד שבועיים.
1.8. קובעים את השיטה לקריאה לנקודות הקצה של ה-API (שירות הצבירה)
ב-codelab הזה מוצגות 2 אפשרויות לקריאה לנקודות הקצה של Aggregation Service API: cURL ו-Postman. cURL היא הדרך המהירה והקלה יותר לקרוא לנקודות הקצה של ה-API מהטרמינל, כי היא דורשת הגדרה מינימלית ולא נדרשת תוכנה נוספת. אבל אם אתם לא רוצים להשתמש ב-cURL, אתם יכולים להשתמש ב-Postman כדי להריץ ולשמור בקשות API לשימוש עתידי.
בסעיף 3.2. במאמר בנושא שימוש ב-Aggregation Service מוסבר בפירוט איך משתמשים בשתי האפשרויות. אתם יכולים לראות תצוגה מקדימה של השיטות האלה כדי להחליט באיזו שיטה להשתמש. אם בוחרים ב-Postman, מבצעים את ההגדרה הראשונית הבאה.
1.8.1. הגדרת סביבת עבודה
נרשמים לחשבון Postman. אחרי ההרשמה, סביבת עבודה נוצרת בשבילכם באופן אוטומטי.
 סביבת עבודה ב-Postman.
סביבת עבודה ב-Postman.
אם לא נוצרה לכם סביבת עבודה, עוברים לפריט הניווט העליון 'סביבות עבודה' ובוחרים באפשרות 'יצירת סביבת עבודה'.
בוחרים באפשרות 'Workspace ריק', לוחצים על 'הבא' ונותנים לו את השם 'ארגז החול לפרטיות של GCP'. בוחרים באפשרות 'אישי' ולוחצים על 'יצירה'.
מורידים את הגדרות ה-JSON של סביבת העבודה שהוגדרה מראש ואת הקובץ של הסביבה הגלובלית.
מייבאים את שני קובצי ה-JSON אל 'סביבת העבודה שלי' באמצעות הלחצן 'ייבוא'.
 לחצן הייבוא.
לחצן הייבוא.
הפעולה הזו תיצור את האוסף GCP Privacy Sandbox (ארגז החול לפרטיות ב-GCP) יחד עם בקשות ה-HTTP createJob ו-getJob.
1.8.2. הגדרת הרשאה
לוחצים על האוסף GCP ארגז החול לפרטיות ועוברים לכרטיסייה Authorization (הרשאה).
 לחצן ההרשאה.
לחצן ההרשאה.
תשתמשו בשיטה Bearer Token. בסביבת הטרמינל, מריצים את הפקודה הזו ומעתיקים את הפלט.
gcloud auth print-identity-token
לאחר מכן מדביקים את ערך הטוקן בשדה Token (טוקן) בכרטיסייה Authorization (הרשאה) ב-Postman:
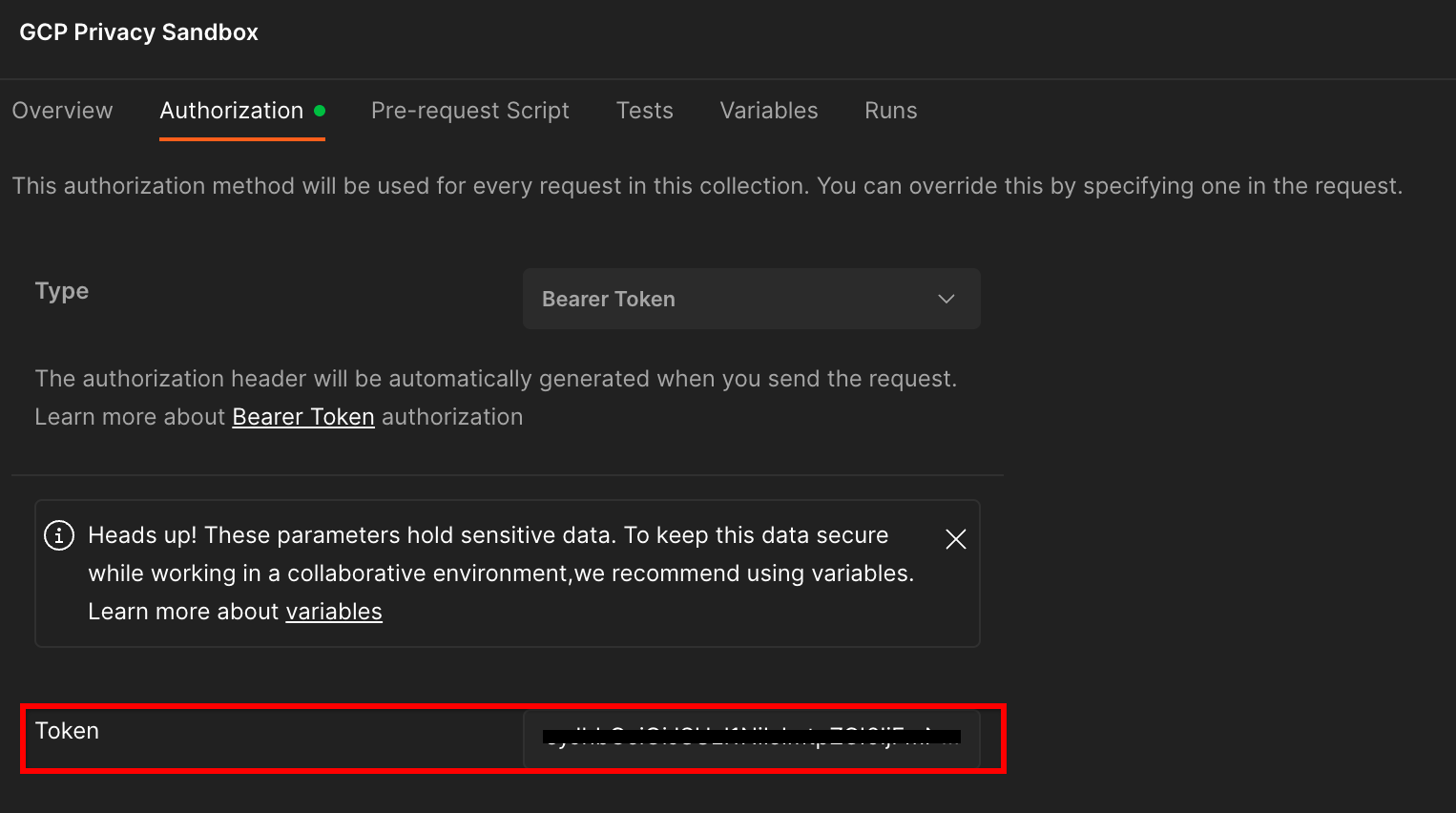 השדה Token (אסימון).
השדה Token (אסימון).
1.8.3. הגדרת הסביבה
עוברים אל 'סקירה מהירה של הסביבה' בפינה השמאלית העליונה:
 כפתור הצצה מהירה לסביבה.
כפתור הצצה מהירה לסביבה.
לוחצים על Edit (עריכה) ומעדכנים את הערך הנוכחי של environment (סביבה), region (אזור) ו-cloud-function-id (מזהה פונקציית הענן):
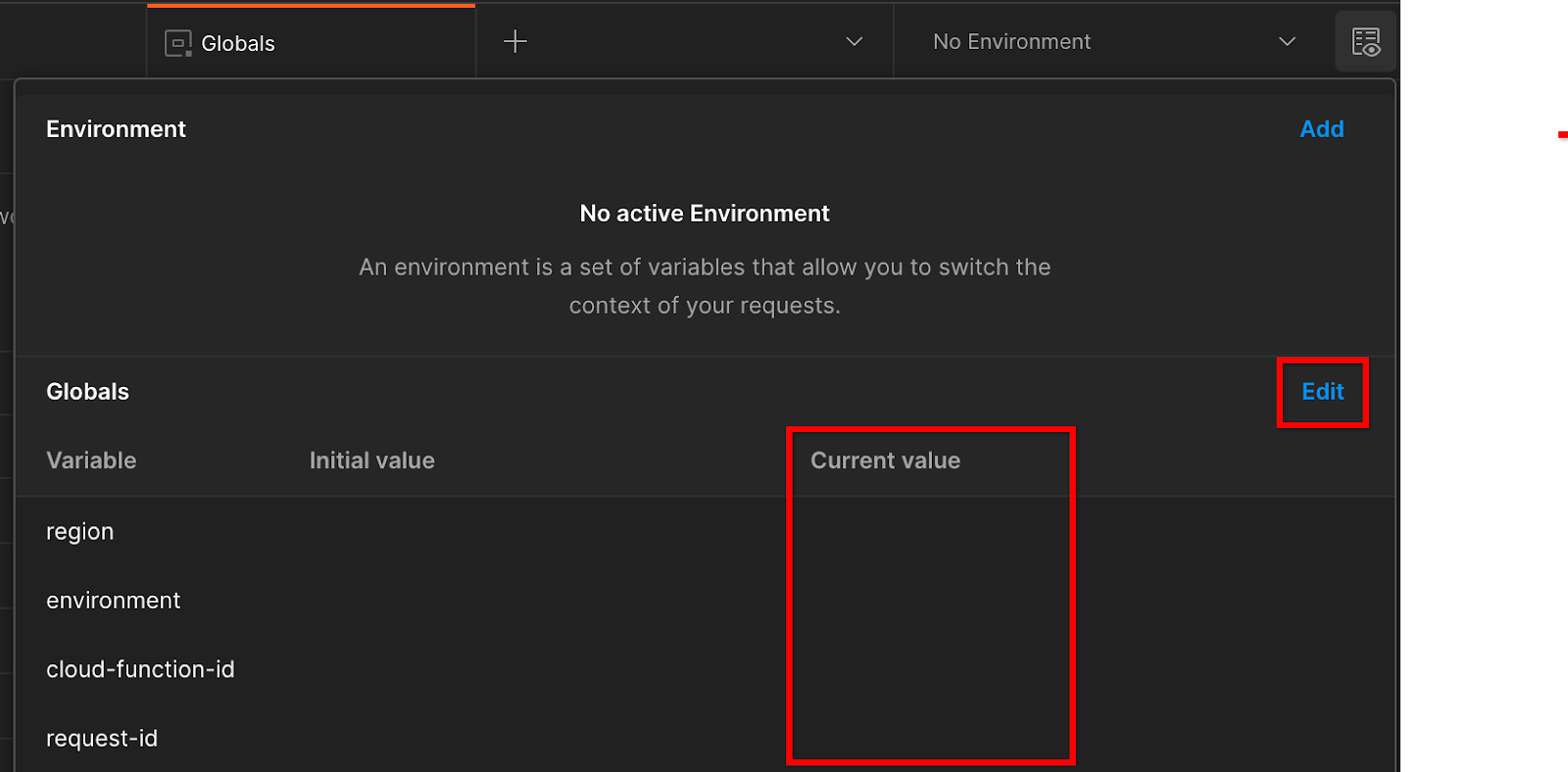 מגדירים את הערכים הנוכחיים.
מגדירים את הערכים הנוכחיים.
אפשר להשאיר את השדה request-id ריק כרגע, כי נמלא אותו בהמשך. בשדות האחרים, משתמשים בערכים מ-frontend_service_cloudfunction_url שהוחזר מהשלמת הפריסה של Terraform בדרישה המוקדמת 1.6. כתובת ה-URL היא בפורמט הבא: https://
2. 2. Codelab בנושא בדיקות מקומיות
זמן משוער לסיום הטיפול בבקשה: פחות משעה
אתם יכולים להשתמש בכלי לבדיקה מקומית במחשב שלכם כדי לבצע צבירה וליצור דוחות סיכום באמצעות דוחות ניפוי הבאגים הלא מוצפנים. לפני שמתחילים, צריך לוודא שביצעתם את כל הדרישות המוקדמות שמסומנות בתווית 'בדיקה מקומית'.
שלבים ב-Codelab
שלב 2.1. הפעלת דוח: הפעלת דיווח של Private Aggregation כדי לאסוף את הדוח.
שלב 2.2. יצירת דוח AVRO לניפוי באגים: המרת דוח JSON שנאסף לדוח בפורמט AVRO. השלב הזה דומה למצב שבו טכנולוגיות פרסום אוספות את הדוחות מנקודות הקצה של ה-API לדיווח וממירות את הדוחות בפורמט JSON לדוחות בפורמט AVRO.
שלב 2.3. אחזור מפתחות של באקט: מפתחות של באקט מתוכננים על ידי טכנולוגיות פרסום. ב-codelab הזה, מאחר שהקטגוריות מוגדרות מראש, צריך לאחזר את מפתחות הקטגוריות כמו שהם.
שלב 2.4. יצירת קובץ AVRO של דומיין פלט: אחרי אחזור מפתחות ה-bucket, יוצרים את קובץ ה-AVRO של דומיין הפלט.
שלב 2.5. יצירת דוח סיכום: אפשר להשתמש בכלי הבדיקה המקומית כדי ליצור דוחות סיכום בסביבה המקומית.
שלב 2.6. בדיקת דוחות הסיכום: בדיקת דוח הסיכום שנוצר על ידי הכלי לבדיקה מקומית.
2.1. דוח טריגרים
כדי להפעיל דוח של צבירה פרטית, אפשר להשתמש באתר ההדגמה של ארגז החול לפרטיות (https://privacy-sandbox-demos-news.dev/?env=gcp) או באתר שלכם (לדוגמה, https://adtechexample.com). אם אתם משתמשים באתר משלכם ולא השלמתם את ההרשמה, האימות והצירוף לשירות הצבירה, תצטרכו להשתמש בתכונה ניסיונית של Chrome ובמתג CLI.
בהדגמה הזו נשתמש באתר ההדגמה של ארגז החול לפרטיות. לוחצים על הקישור כדי לעבור לאתר, ואז אפשר לראות את הדוחות בכתובת chrome://private-aggregation-internals:
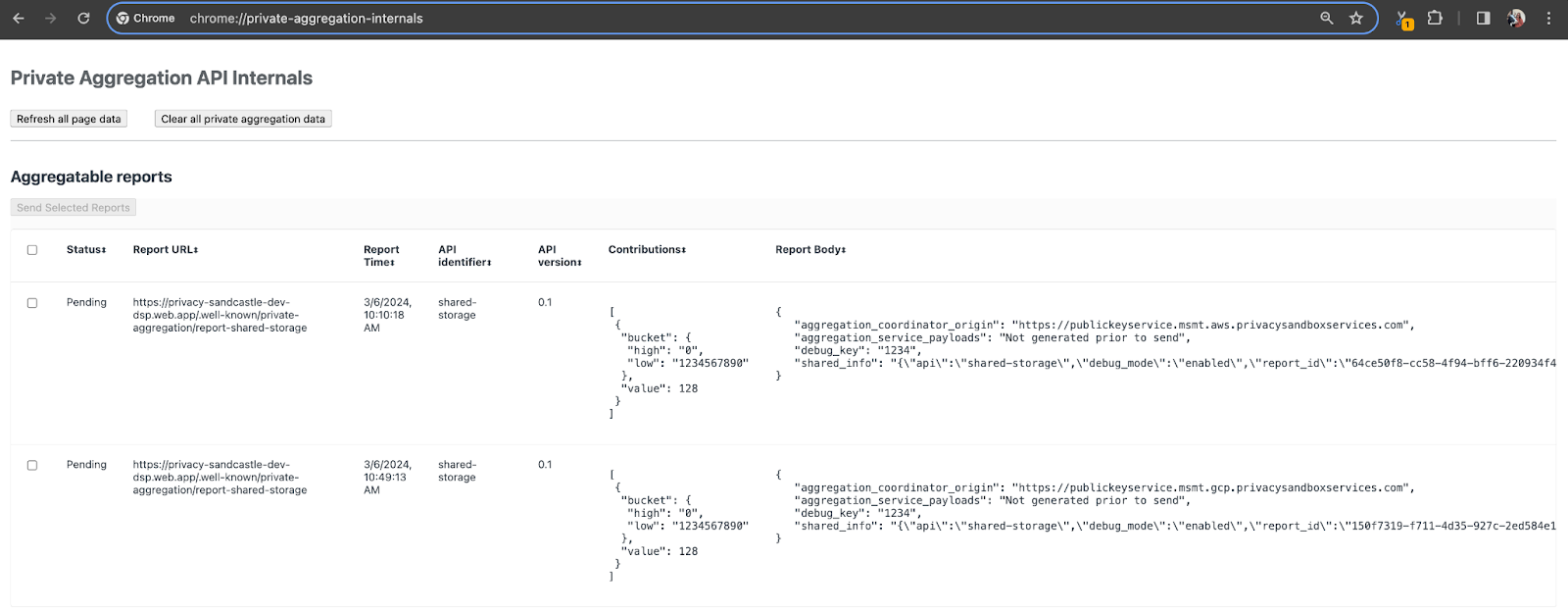 דף פנימי של Chrome.
דף פנימי של Chrome.
הדוח שנשלח לנקודת הקצה {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage מופיע גם ב'גוף הדוח' בדוחות שמוצגים בדף Chrome Internals.
יכול להיות שיופיעו כאן הרבה דוחות, אבל ב-Codelab הזה צריך להשתמש בדוח שניתן לצבירה, שהוא ספציפי ל-Google Cloud ונוצר על ידי נקודת הקצה של ניפוי הבאגים. כתובת ה-URL של הדוח תכיל את המחרוזת '/debug/', והמחרוזת aggregation_coordinator_origin field של 'גוף הדוח' תכיל את כתובת ה-URL הזו: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
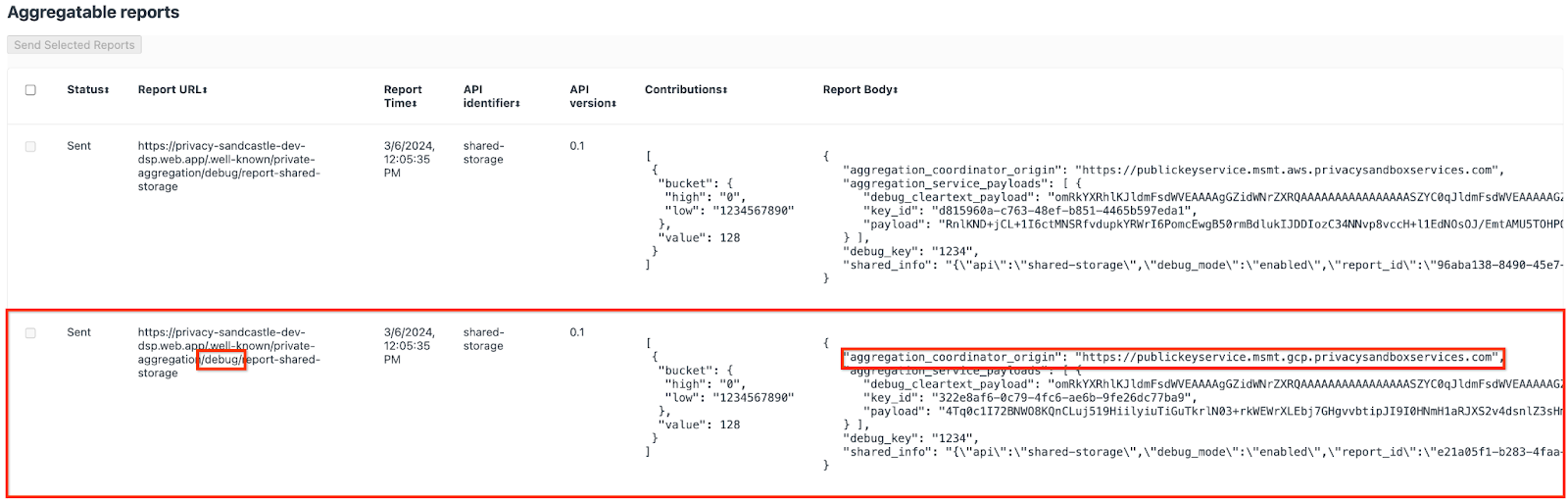 דוח ניפוי באגים ב-Google Cloud.
דוח ניפוי באגים ב-Google Cloud.
2.2. יצירת דוח ניתן לצבירה לניפוי באגים
מעתיקים את הדוח שנמצא ב-Report Body של chrome://private-aggregation-internals ויוצרים קובץ JSON בתיקייה privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar (במאגר שהורד בדרישה המוקדמת 1.5).
בדוגמה הזו אנחנו משתמשים ב-vim כי אנחנו משתמשים ב-Linux. אבל אתם יכולים להשתמש בכל עורך טקסט שתרצו.
vim report.json
מדביקים את הדוח ב-report.json ושומרים את הקובץ.
 קוד ה-JSON של הדוח.
קוד ה-JSON של הדוח.
אחרי שיש לכם את הנתונים האלה, אתם יכולים להשתמש ב-aggregatable_report_converter.jar כדי ליצור את הדוח המצטבר לניפוי באגים. הפעולה הזו יוצרת דוח שניתן לצבירה בשם report.avro בספרייה הנוכחית.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. אחזור מפתח הקטגוריה מהדוח
כדי ליצור את הקובץ output_domain.avro, צריך את מפתחות ה-bucket שאפשר לאחזר מהדוחות.
מפתחות הדלי מתוכננים על ידי טכנולוגיית הפרסום הדיגיטלי. עם זאת, במקרה הזה, מפתחות הדלי נוצרים על ידי האתר Privacy Sandbox Demo. מכיוון ש-Private Aggregation באתר הזה נמצא במצב ניפוי באגים, אפשר להשתמש ב-debug_cleartext_payload מ-Report Body כדי לקבל את מפתח הדלי.
אפשר להעתיק את debug_cleartext_payload מגוף הדוח.
 ניפוי באגים במטען ייעודי (payload) של טקסט ללא הצפנה.
ניפוי באגים במטען ייעודי (payload) של טקסט ללא הצפנה.
פותחים את goo.gle/ags-payload-decoder, מדביקים את debug_cleartext_payload בתיבה INPUT ולוחצים על Decode (פענוח).
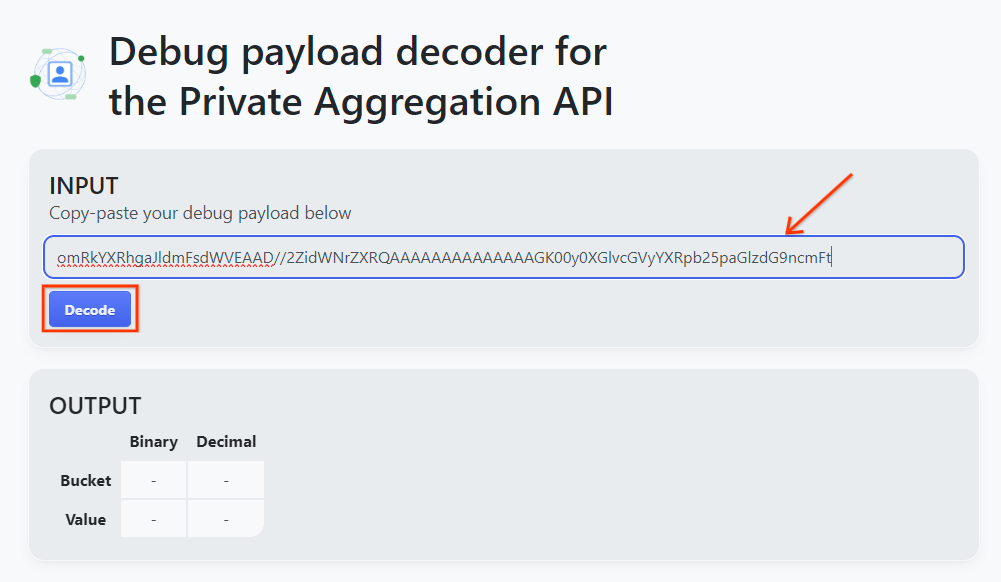 לחצן הפענוח.
לחצן הפענוח.
הדף מחזיר את הערך העשרוני של מפתח הדלי. זוהי דוגמה למפתח קטגוריה.
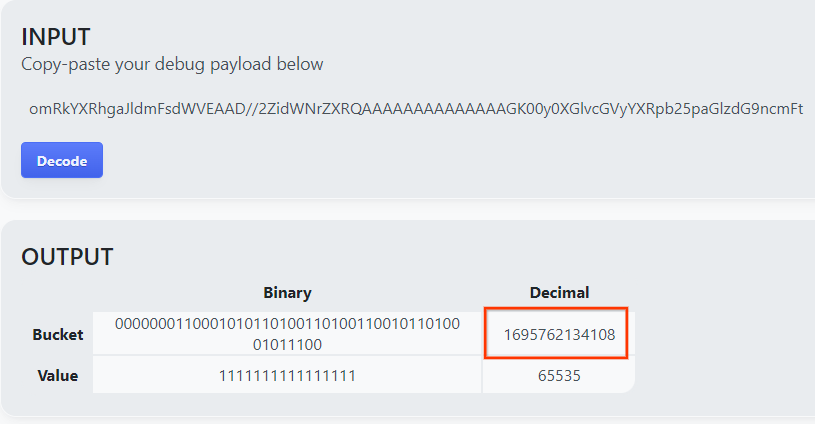 מפתח לדוגמה של קטגוריה.
מפתח לדוגמה של קטגוריה.
2.4. יצירת פלט AVRO של דומיין
עכשיו, אחרי שיש לנו את מפתח הדלי, ניצור את output_domain.avro באותה תיקייה שבה עבדנו. מוודאים שמחליפים את מפתח הקטגוריה במפתח הקטגוריה שאוחזר.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
הסקריפט יוצר את הקובץ output_domain.avro בתיקייה הנוכחית.
2.5. יצירת דוחות סיכום באמצעות הכלי לבדיקות מקומיות
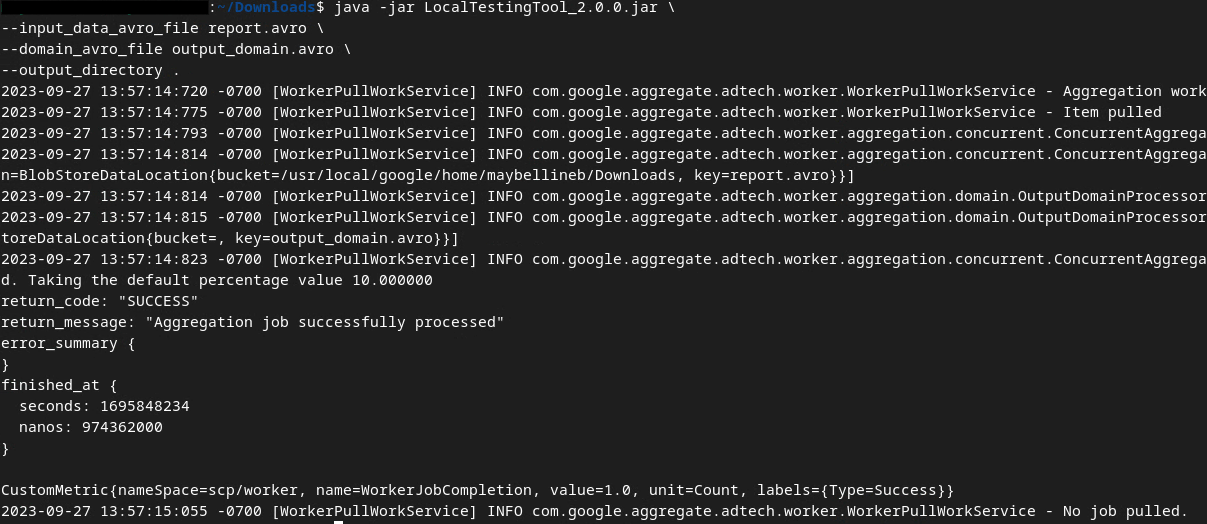
נשתמש ב-LocalTestingTool_{version}.jar שהורד בדרישה המוקדמת 1.3 כדי ליצור את דוחות הסיכום באמצעות הפקודה הבאה. מחליפים את {version} בגרסה שהורדתם. חשוב להעביר את LocalTestingTool_{version}.jar לספרייה הנוכחית, או להוסיף נתיב יחסי כדי להפנות למיקום הנוכחי שלו.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
אחרי הרצת הפקודה, אמור להופיע פלט דומה לזה: דוח output.avro נוצר בסיום התהליך.
 Output AVRO
Output AVRO
2.6. בדיקת דוח הסיכום
דוח הסיכום שנוצר הוא בפורמט AVRO. כדי לקרוא את הנתונים, צריך להמיר אותם מפורמט AVRO לפורמט JSON. מומלץ שספק הפרסום הדיגיטלי יכתוב קוד להמרה של דוחות AVRO בחזרה ל-JSON.
נשתמש ב-aggregatable_report_converter.jar כדי להמיר את דוח ה-AVRO בחזרה ל-JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
יוחזר דוח שדומה לדוגמה הבאה. יחד עם דוח output.json שנוצר באותה תיקייה.
 פלט JSON
פלט JSON
סיימתם את ה-Codelab!
סיכום: אספתם דוח ניפוי באגים, יצרתם קובץ דומיין של פלט והפקתם דוח סיכום באמצעות כלי הבדיקה המקומי שמדמה את התנהגות הצבירה של Aggregation Service.
השלבים הבאים: אחרי שהתנסיתם בכלי לבדיקה מקומית, אתם יכולים לנסות את אותה פעולה עם פריסה פעילה של Aggregation Service בסביבה שלכם. כדאי לעיין שוב בדרישות המוקדמות כדי לוודא שהגדרתם הכול למצב 'שירות צבירה', ואז להמשיך לשלב 3.
3. 3. Codelab בנושא Aggregation Service
זמן משוער לסיום: שעה אחת
לפני שמתחילים, צריך לוודא שביצעתם את כל הפעולות הנדרשות שמופיעות בקטע 'שירות צבירה'.
שלבים ב-Codelab
שלב 3.1. יצירת קלט של Aggregation Service: יצירת הדוחות של Aggregation Service שנשלחים בחבילות ל-Aggregation Service.
- שלב 3.1.1. דוח הטריגרים
- שלב 3.1.2. איסוף דוחות מצטברים
- שלב 3.1.3. המרת דוחות לפורמט AVRO
- שלב 3.1.4. יצירת קובץ AVRO של output_domain
- שלב 3.1.5. העברת דוחות לקטגוריה של Cloud Storage
שלב 3.2. שימוש בשירות Aggregation: שימוש ב-Aggregation Service API כדי ליצור דוחות סיכום ולבדוק אותם.
- שלב 3.2.1. שימוש בנקודת קצה
createJobכדי להוסיף קבוצות - שלב 3.2.2. שימוש בנקודת הקצה
getJobלאחזור סטטוס של קבוצת קבצים - שלב 3.2.3. בדיקת דוח הסיכום
3.1. יצירת קלט ל-Aggregation Service
ממשיכים ליצירת דוחות AVRO לאיגוד לחבילות לצורך שליחה ל-Aggregation Service. אפשר להריץ את פקודות השל ב-Cloud Shell של Google Cloud (בתנאי שהתלות מהדרישות המוקדמות משוכפלת לסביבת Cloud Shell) או בסביבת הפעלה מקומית.
3.1.1. דוח הטריגרים
לוחצים על הקישור כדי לעבור לאתר, ואז אפשר לראות את הדוחות בכתובת chrome://private-aggregation-internals:
דף פנימי של Chrome
הדוח שנשלח לנקודת הקצה {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage מופיע גם ב'גוף הדוח' של הדוחות שמוצגים בדף Chrome Internals.
יכול להיות שיופיעו כאן הרבה דוחות, אבל ב-Codelab הזה צריך להשתמש בדוח שניתן לצבירה, שהוא ספציפי ל-Google Cloud ונוצר על ידי נקודת הקצה של ניפוי הבאגים. כתובת ה-URL של הדוח תכיל את המחרוזת '/debug/', והמחרוזת aggregation_coordinator_origin field של 'גוף הדוח' תכיל את כתובת ה-URL הזו: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
דוח ניפוי באגים ב-Google Cloud.
3.1.2. איסוף דוחות מצטברים
אוספים את הדוחות המצטברים מנקודות הקצה המוכרות של ה-API המתאים.
- צבירה פרטית:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - דוחות שיוך (Attribution) – דוח סיכום:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
ב-codelab הזה, אנחנו מבצעים את איסוף הדוחות באופן ידני. בסביבת הייצור, ספקי טכנולוגיית פרסום צפויים לאסוף ולהמיר את הדוחות באופן פרוגרמטי.
נעתיק את דוח ה-JSON בקטע Report Body (גוף הדוח) מ-chrome://private-aggregation-internals.
בדוגמה הזו אנחנו משתמשים ב-vim כי אנחנו משתמשים ב-Linux. אבל אתם יכולים להשתמש בכל עורך טקסט שתרצו.
vim report.json
מדביקים את הדוח ב-report.json ושומרים את הקובץ.
דוח JSON
3.1.3. המרת דוחות לפורמט AVRO
דוחות שמתקבלים מנקודות הקצה .well-known הם בפורמט JSON וצריך להמיר אותם לפורמט דוח AVRO. אחרי שיש לכם את דוח ה-JSON, עוברים למיקום שבו מאוחסן report.json ומשתמשים ב-aggregatable_report_converter.jar כדי ליצור את דוח האגרגציה לניפוי באגים. הפעולה הזו יוצרת דוח שניתן לצבירה בשם report.avro בספרייה הנוכחית.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. יצירת קובץ AVRO של output_domain
כדי ליצור את הקובץ output_domain.avro, צריך את מפתחות ה-bucket שאפשר לאחזר מהדוחות.
מפתחות הדלי מתוכננים על ידי טכנולוגיית הפרסום הדיגיטלי. עם זאת, במקרה הזה, מפתחות הדלי נוצרים על ידי האתר Privacy Sandbox Demo. מכיוון ש-Private Aggregation באתר הזה נמצא במצב ניפוי באגים, אפשר להשתמש ב-debug_cleartext_payload מ-Report Body כדי לקבל את מפתח הדלי.
אפשר להעתיק את debug_cleartext_payload מגוף הדוח.
ניפוי באגים במטען ייעודי (payload) של טקסט ללא הצפנה.
פותחים את goo.gle/ags-payload-decoder, מדביקים את debug_cleartext_payload בתיבה INPUT ולוחצים על Decode (פענוח).
לחצן הפענוח.
הדף מחזיר את הערך העשרוני של מפתח הדלי. זוהי דוגמה למפתח קטגוריה.
מפתח לדוגמה של קטגוריה.
עכשיו, אחרי שיש לנו את מפתח הדלי, ניצור את output_domain.avro באותה תיקייה שבה עבדנו. מוודאים שמחליפים את מפתח הקטגוריה במפתח הקטגוריה שאוחזר.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
הסקריפט יוצר את הקובץ output_domain.avro בתיקייה הנוכחית.
3.1.5. העברת דוחות לקטגוריה של Cloud Storage
אחרי שיוצרים את דוחות ה-AVRO ואת דומיין הפלט, ממשיכים להעברת הדוחות ודומיין הפלט אל הקטגוריה ב-Cloud Storage (שציינתם בדרישה המוקדמת 1.6).
אם ה-CLI של gcloud מוגדר בסביבה המקומית, משתמשים בפקודות הבאות כדי להעתיק את הקבצים לתיקיות המתאימות.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
אחרת, מעלים את הקבצים באופן ידני לקטגוריה. יוצרים תיקייה בשם reports ומעלים אליה את הקובץ report.avro. יוצרים תיקייה בשם output_domains ומעלים אליה את הקובץ output_domain.avro.
3.2. שימוש בשירות Aggregation
בשלב 1.8 של הדרישות המוקדמות, בחרתם אם להשתמש ב-curl או ב-Postman כדי לשלוח בקשות API לנקודות הקצה של שירות הצבירה. בהמשך מפורטות הוראות לשתי האפשרויות.
אם העבודה נכשלת עם שגיאה, אפשר לעיין במאמרי העזרה שלנו לפתרון בעיות ב-GitHub כדי לקבל מידע נוסף על המשך הפעולה.
3.2.1. שימוש בנקודת קצה createJob כדי להוסיף קבוצות
כדי ליצור משימה, משתמשים בהוראות הבאות ל-curl או ל-Postman.
curl
בטרמינל, יוצרים קובץ של גוף הבקשה (body.json) ומדביקים בו את אובייקט ה-JSON הבא. חשוב לעדכן את ערכי ה-placeholder. מידע נוסף על המשמעות של כל שדה מופיע במאמרי העזרה של ה-API.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
מריצים את הבקשה הבאה. מחליפים את ה-placeholders בכתובת ה-URL של בקשת curl בערכים מ-frontend_service_cloudfunction_url, שמוצג אחרי השלמה מוצלחת של הפריסה של Terraform בדרישה המוקדמת 1.6.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
אחרי ששירות הצבירה יאשר את הבקשה, תקבלו תגובה מסוג HTTP 202. קודי תגובה אפשריים אחרים מתועדים במפרטי ה-API.
Postman
בנקודת הקצה createJob, נדרש גוף בקשה כדי לספק ל-Aggregation Service את המיקום ואת שמות הקבצים של דוחות שאפשר לצבור, דומיינים של פלט ודוחות סיכום.
עוברים לכרטיסייה createJob Body (גוף) של הבקשה:
 הכרטיסייה 'גוף'
הכרטיסייה 'גוף'
מחליפים את מצייני המיקום ב-JSON שסופק. מידע נוסף על השדות האלה ועל המשמעות שלהם זמין במאמרי העזרה של ה-API.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
שולחים את בקשת ה-API createJob:
 כפתור השליחה
כפתור השליחה
קוד התגובה מופיע בחלק התחתון של הדף:
 קוד תגובה
קוד תגובה
אחרי ששירות הצבירה יאשר את הבקשה, תקבלו תגובה מסוג HTTP 202. קודי תגובה אפשריים אחרים מתועדים במפרטי ה-API.
3.2.2. שימוש בנקודת הקצה getJob לאחזור סטטוס של קבוצת קבצים
כדי לקבל משימה, משתמשים בהוראות הבאות של curl או Postman.
curl
מריצים את הבקשה הבאה בטרמינל. מחליפים את ה-placeholder בכתובת ה-URL בערכים מ-frontend_service_cloudfunction_url, שהיא אותה כתובת URL שבה השתמשתם בבקשת createJob. בפרמטר job_request_id, צריך להשתמש בערך מהג'וב שיצרתם באמצעות נקודת הקצה createJob.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
התוצאה צריכה להחזיר את הסטטוס של בקשת העבודה עם סטטוס HTTP של 200. החלק Body בבקשה מכיל את המידע הנדרש כמו job_status, return_message ו-error_messages (אם העבודה נכשלה).
Postman
כדי לבדוק את הסטטוס של בקשת העבודה, אפשר להשתמש בנקודת הקצה getJob. בקטע Params (פרמטרים) של הבקשה getJob, מעדכנים את הערך job_request_id לערך job_request_id שנשלח בבקשה createJob.
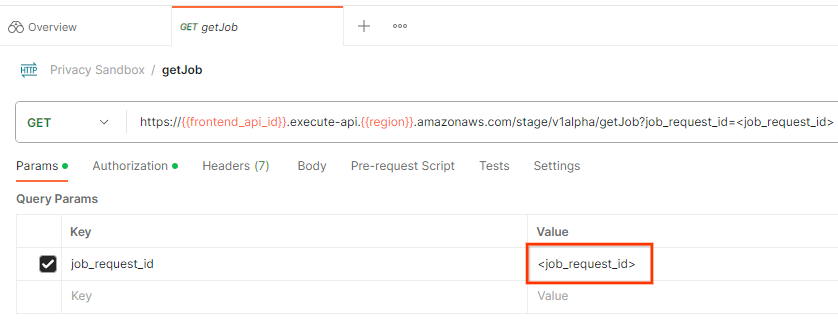 מזהה בקשת עבודה
מזהה בקשת עבודה
שולחים את הבקשה getJob:
 כפתור השליחה
כפתור השליחה
התוצאה צריכה להחזיר את הסטטוס של בקשת העבודה עם סטטוס HTTP של 200. החלק Body בבקשה מכיל את המידע הנדרש כמו job_status, return_message ו-error_messages (אם העבודה נכשלה).
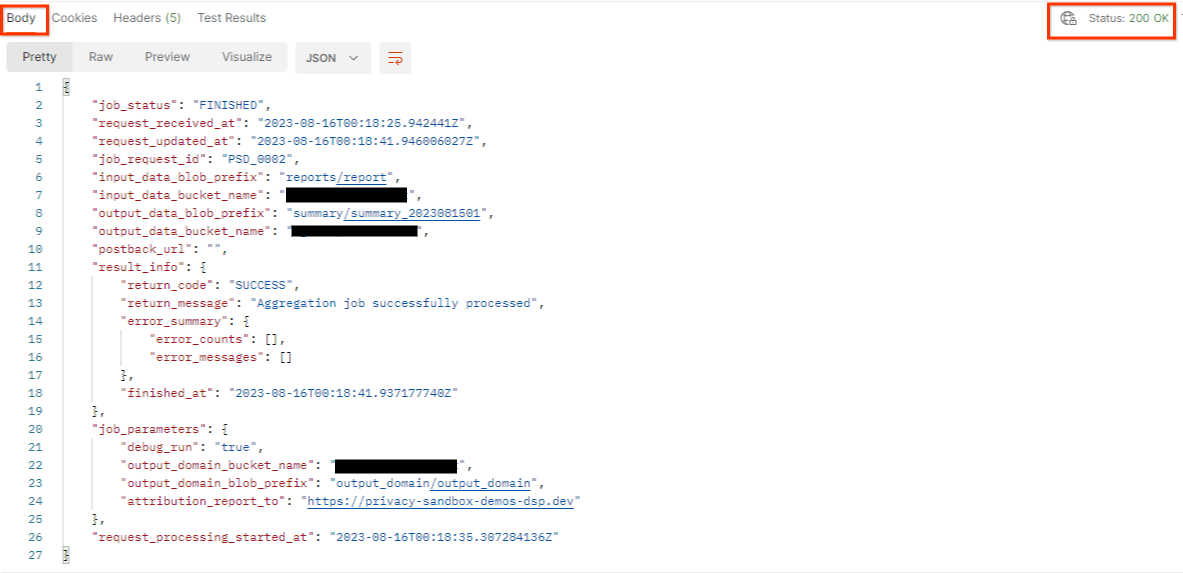 תגובת JSON
תגובת JSON
3.2.3. בדיקת דוח הסיכום
אחרי שתקבלו את הדוח המסכם בקטגוריית הפלט של Cloud Storage, תוכלו להוריד אותו לסביבה המקומית. דוחות הסיכום הם בפורמט AVRO ואפשר להמיר אותם בחזרה ל-JSON. אפשר להשתמש בפקודה הזו כדי לקרוא את הדוח באמצעות aggregatable_report_converter.jar.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
הפונקציה מחזירה JSON של ערכים מצטברים של כל מפתח bucket, שדומה לזה שמופיע בהמשך.
 דוח סיכום.
דוח סיכום.
אם הערך של createJob בבקשה הוא true, תקבלו את דוח הסיכום בתיקיית הניפוי באגים שנמצאת ב-output_data_blob_prefix.debug_run הדוח הוא בפורמט AVRO ואפשר להמיר אותו ל-JSON באמצעות הפקודה הקודמת.
הדוח מכיל את מפתח הסיווג, את המדד ללא רעשי רקע ואת הרעש שנוסף למדד ללא רעשי רקע כדי ליצור את דוח הסיכום. הדוח אמור להיראות כך:
 דוח עם רעשי רקע
דוח עם רעשי רקע
ההערות מכילות גם את הערכים in_reports או in_domain (או את שניהם), שמשמעותם:
- in_reports – מפתח הסיווג לקבוצה זמין בדוחות הניתנים לצבירה.
- in_domain – מפתח הקטגוריה זמין בקובץ הפלט output_domain AVRO.
סיימתם את ה-Codelab!
סיכום: פרסתם את שירות הצבירה בסביבת הענן שלכם, אספתם דוח ניפוי באגים, יצרתם קובץ פלט של דומיין, אחסנתם את הקבצים האלה בקטגוריה של Cloud Storage והפעלתם משימה בהצלחה.
השלבים הבאים: ממשיכים להשתמש בשירות הצבירה בסביבה שלכם, או מוחקים את משאבי הענן שיצרתם זה עתה לפי הוראות הניקוי בשלב 4.
4. 4. ניקוי תלונות
כדי למחוק את המשאבים שנוצרו בשביל שירות הצבירה באמצעות Terraform, משתמשים בפקודה destroy בתיקיות adtech_setup ו-dev (או בסביבה אחרת):
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
כדי למחוק את קטגוריית האחסון ב-Cloud Storage שכוללת את הדוחות הניתנים לצבירה ואת דוחות הסיכום:
$ gcloud storage buckets delete gs://my-bucket
אפשר גם לבחור להחזיר את הגדרות קובצי ה-Cookie ב-Chrome ממצב 1.2 למצב הקודם שלהן.
5. 5. נספח
קובץ adtech_setup.auto.tfvars לדוגמה
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
קובץ dev.auto.tfvars לדוגמה
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20