
1. 1. المتطلبات الأساسية
الوقت المقدّر لإنهاء الدرس: من ساعة إلى ساعتين
هناك وضعان لتنفيذ هذا الدرس التطبيقي حول الترميز: الاختبار المحلي أو خدمة تجميع البيانات. يتطلّب وضع "الاختبار المحلي" جهازًا محليًا ومتصفّح Chrome (بدون إنشاء/استخدام موارد Google Cloud). يتطلّب وضع "خدمة تجميع البيانات" نشرًا كاملاً للخدمة على Google Cloud.
لإجراء هذا الدرس التطبيقي في أيّ من الوضعين، يجب استيفاء بعض المتطلبات الأساسية. يتم وضع علامة على كل شرط وفقًا لما إذا كان مطلوبًا لاستخدام ميزة "الاختبار المحلّي" أو "خدمة التجميع".
1-1- إكمال عملية التسجيل والتصديق (خدمة تجميع البيانات)
لاستخدام واجهات برمجة التطبيقات من "مبادرة حماية الخصوصية"، تأكَّد من إكمال التسجيل والشهادة لكلّ من Chrome وAndroid.
1.2. تفعيل واجهات برمجة التطبيقات المتعلّقة بالخصوصية في عرض الإعلانات (خدمة الاختبار المحلّي وخدمة تجميع البيانات)
بما أنّنا سنستخدم "مبادرة حماية الخصوصية"، ننصحك بتفعيل واجهات برمجة التطبيقات للإعلانات في "مبادرة حماية الخصوصية".
في المتصفّح، انتقِل إلى chrome://settings/adPrivacy وفعِّل جميع واجهات برمجة التطبيقات المتعلّقة بخصوصية الإعلانات.
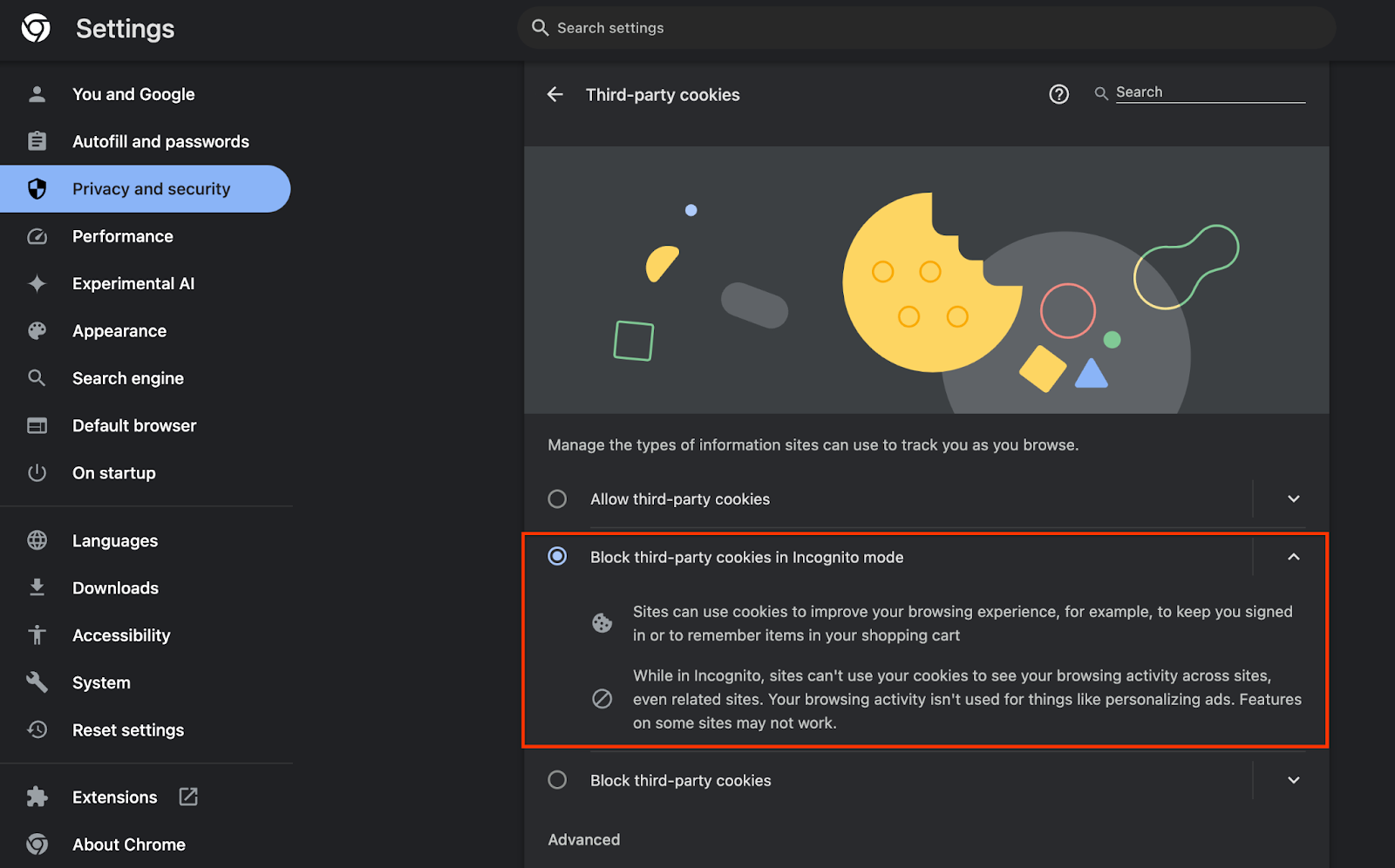
تأكَّد أيضًا من تفعيل ملفات تعريف الارتباط التابعة لجهات خارجية.
من chrome://settings/cookies، تأكَّد من عدم حظر ملفات تعريف الارتباط التابعة لجهات خارجية. استنادًا إلى إصدار Chrome، قد تظهر لك خيارات مختلفة في قائمة الإعدادات هذه، ولكن تتضمّن الإعدادات المقبولة ما يلي:
- "حظر جميع ملفات تعريف الارتباط الخارجية" = غير مفعَّلة
- "حظر ملفات تعريف الارتباط التابعة لجهات خارجية" = DISABLED
- "حظر ملفات تعريف الارتباط التابعة لجهات خارجية في وضع التصفُّح المتخفي" = مفعَّلة
 تفعيل ملفات تعريف الارتباط
تفعيل ملفات تعريف الارتباط
1.3. تنزيل "أداة الاختبار المحلي" (الاختبار المحلي)
سيتطلّب استخدام ميزة "الاختبار المحلي" تنزيل "أداة الاختبار المحلي". ستنشئ الأداة تقارير ملخّصة من تقارير تصحيح الأخطاء غير المشفرة.
تتوفّر أداة "الاختبار المحلي" للتنزيل في أرشيفات JAR الخاصة بوظائف السحابة الإلكترونية في GitHub. يجب تسميته LocalTestingTool_{version}.jar.
1.4. التأكّد من تثبيت JAVA JRE (خدمة الاختبار والتجميع المحليَّين)
افتح "الوحدة الطرفية" واستخدِم java --version للتحقّق ممّا إذا كان جهازك مثبّتًا عليه Java أو openJDK.
 تحقَّق من إصدار Java.
تحقَّق من إصدار Java.
إذا لم يكن مثبّتًا، يمكنك تنزيله وتثبيته من موقع Java الإلكتروني أو موقع openJDK الإلكتروني.
1.5. تنزيل aggregatable_report_converter (أداة الاختبار المحلّي وخدمة تجميع البيانات)
يمكنك تنزيل نسخة من aggregatable_report_converter من مستودع GitHub الخاص بالحلول التجريبية في مبادرة حماية الخصوصية. يشير مستودع GitHub إلى استخدام IntelliJ أو Eclipse، ولكن لا يُشترط استخدام أي منهما. إذا كنت لا تستخدم هذه الأدوات، نزِّل ملف JAR إلى بيئتك المحلية بدلاً من ذلك.
1.6. إعداد بيئة Cloud Platform (خدمة تجميع البيانات)
تتطلّب "خدمة التجميع" استخدام "بيئة تنفيذ موثوقة" تستعين بمقدّم خدمات السحابة الإلكترونية. في هذا الدرس التطبيقي حول الترميز، سيتم نشر "خدمة التجميع" في Google Cloud، ولكن تتوفّر أيضًا خدمة AWS.
اتّبِع تعليمات النشر في GitHub لإعداد gcloud CLI وتنزيل البرامج الثنائية والوحدات النمطية لـ Terraform وإنشاء موارد Google Cloud لخدمة التجميع.
الخطوات الرئيسية في "تعليمات النشر":
- إعداد واجهة سطر الأوامر "gcloud" وTerraform في بيئتك
- أنشئ حزمة Cloud Storage لتخزين حالة Terraform.
- نزِّل العناصر التابعة.
- عدِّل
adtech_setup.auto.tfvarsوشغِّلadtech_setupTerraform. راجِع الملحق للاطّلاع على مثال لملفadtech_setup.auto.tfvars. دوِّن اسم حزمة البيانات التي تم إنشاؤها هنا، وسيتم استخدامها في الدرس العملي لتخزين الملفات التي ننشئها. - عدِّل
dev.auto.tfvars، وانتحِل هوية حساب خدمة النشر، وشغِّلdevTerraform. راجِع الملحق للاطّلاع على مثال لملفdev.auto.tfvars. - بعد اكتمال عملية النشر، احصل على
frontend_service_cloudfunction_urlمن ناتج Terraform، والذي سيكون مطلوبًا لتقديم طلبات إلى "خدمة التجميع" في الخطوات اللاحقة.
1.7. إكمال عملية إعداد "خدمة تجميع البيانات" (Aggregation Service)
تتطلّب "خدمة تجميع البيانات" إعدادها من قِبل المنسّقين لتتمكّن من استخدامها. أكمِل نموذج إعداد "خدمة التجميع" من خلال تقديم "الموقع الإلكتروني لإعداد التقارير" ومعلومات أخرى، واختَر "Google Cloud"، وأدخِل عنوان حساب الخدمة. يتم إنشاء حساب الخدمة هذا في المتطلّب الأساسي السابق (1.6. إعداد بيئة Google Cloud). (ملاحظة: إذا كنت تستخدم الأسماء التلقائية المقدَّمة، سيبدأ حساب الخدمة هذا بالعبارة "worker-sa@").
يُرجى الانتظار لمدة تصل إلى أسبوعَين حتى تكتمل عملية الإعداد.
1.8. تحديد طريقتك لاستدعاء نقاط نهاية واجهة برمجة التطبيقات (خدمة التجميع)
يوفّر هذا الدرس العملي خيارَين لاستدعاء نقاط نهاية Aggregation Service API: cURL وPostman. cURL هي الطريقة الأسرع والأسهل لاستدعاء نقاط نهاية واجهة برمجة التطبيقات من "وحدة التحكّم"، لأنّها تتطلّب الحد الأدنى من الإعداد ولا تحتاج إلى برامج إضافية. ومع ذلك، إذا كنت لا تريد استخدام cURL، يمكنك بدلاً من ذلك استخدام Postman لتنفيذ طلبات واجهة برمجة التطبيقات وحفظها لاستخدامها في المستقبل.
في الفقرة 3.2 استخدام "خدمة تجميع البيانات"، ستجد تعليمات مفصّلة حول استخدام كلا الخيارَين. يمكنك معاينتها الآن لتحديد الطريقة التي ستستخدمها. إذا اخترت Postman، عليك إجراء عملية الإعداد الأوّلي التالية.
1.8.1. إعداد مساحة العمل
اشترِك للحصول على حساب Postman. بعد الاشتراك، يتم إنشاء مساحة عمل لك تلقائيًا.
 مساحة عمل Postman
مساحة عمل Postman
إذا لم يتم إنشاء مساحة عمل لك، انتقِل إلى عنصر التنقّل العلوي "مساحات العمل" واختَر "إنشاء مساحة عمل".
اختَر "مساحة عمل فارغة"، ثمّ انقر على "التالي" وأدخِل الاسم "GCP Privacy Sandbox". اختَر "شخصي" وانقر على "إنشاء".
نزِّل إعدادات JSON مساحة العمل التي تم إعدادها مسبقًا وملفات البيئة العامة.
استورِد ملفَي JSON إلى "مساحة العمل الخاصة بي" باستخدام الزر "استيراد".
 زر "استيراد"
زر "استيراد"
سيؤدي ذلك إلى إنشاء مجموعة "مبادرة حماية الخصوصية في Google Cloud Platform" لك بالإضافة إلى طلبَي HTTP createJob وgetJob.
1.8.2. إعداد التفويض
انقر على مجموعة "مبادرة حماية الخصوصية في Google Cloud" وانتقِل إلى علامة التبويب "تفويض".
 زر التفويض
زر التفويض
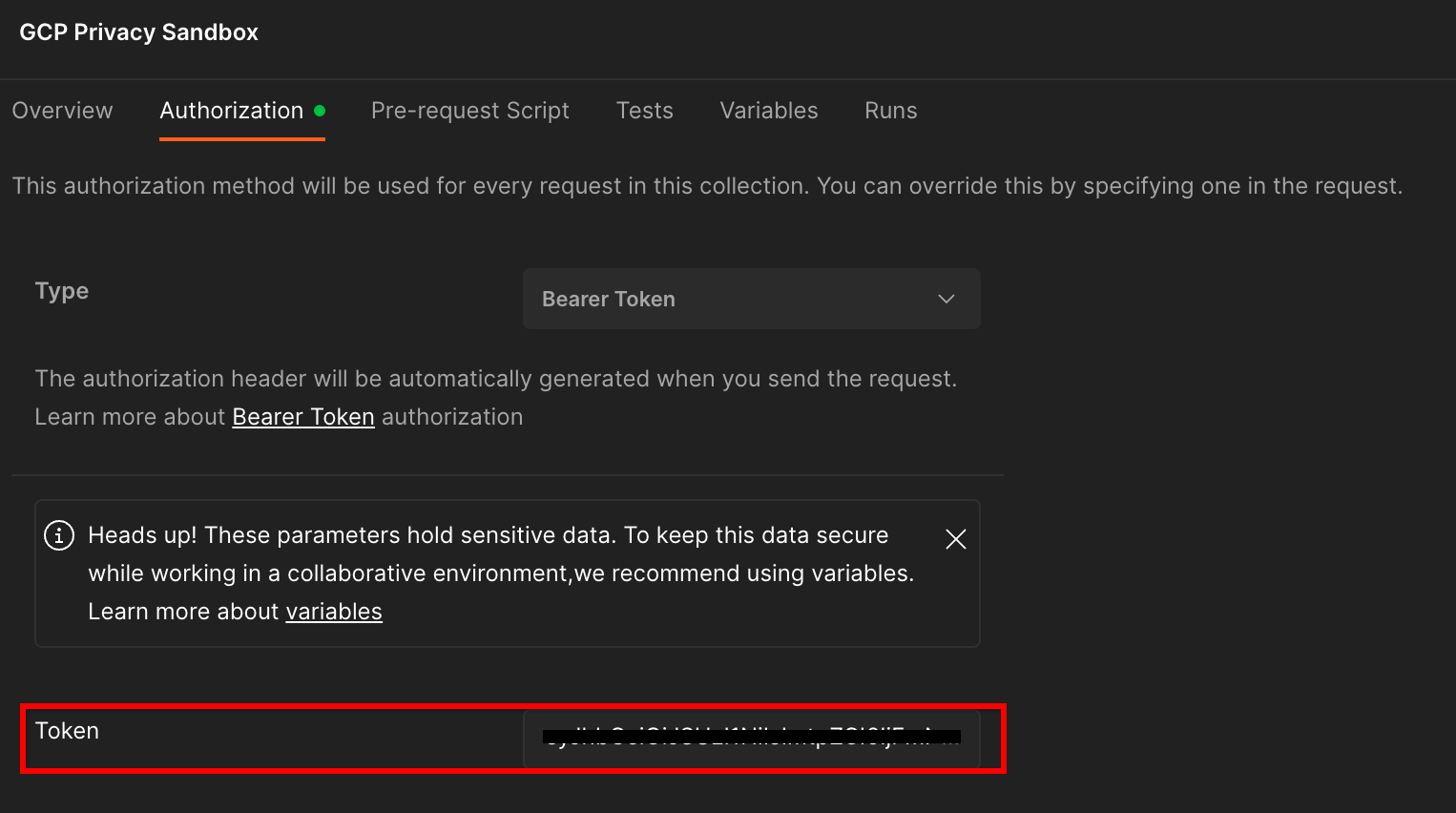
ستستخدم طريقة "رمز الدخول المميز". من بيئة "الوحدة الطرفية"، شغِّل الأمر التالي وانسخ الناتج.
gcloud auth print-identity-token
بعد ذلك، ألصِق قيمة الرمز المميّز في حقل "الرمز المميّز" ضمن علامة التبويب "التفويض" في Postman:
 حقل "الرمز المميز"
حقل "الرمز المميز"
1.8.3. إعداد البيئة
انتقِل إلى "نظرة سريعة على البيئة" في أعلى يسار الشاشة:
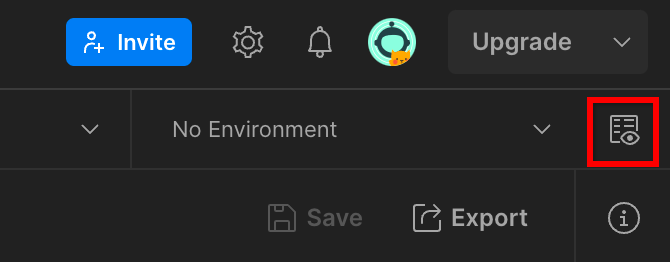 زر "نظرة سريعة على البيئة"
زر "نظرة سريعة على البيئة"
انقر على "تعديل" (Edit) وعدِّل "القيمة الحالية" (Current Value) لكلّ من "البيئة" (environment) و"المنطقة" (region) و "رقم تعريف وظيفة السحابة الإلكترونية" (cloud-function-id):
 ضبط القيم الحالية
ضبط القيم الحالية
يمكنك ترك حقل "request-id" فارغًا في الوقت الحالي، وسنملأه لاحقًا. بالنسبة إلى الحقول الأخرى، استخدِم القيم من frontend_service_cloudfunction_url التي تمّ عرضها بعد إكمال عملية نشر Terraform بنجاح في المتطلّب الأساسي 1.6. يتّبع عنوان URL التنسيق التالي: https://
2. 2. درس تطبيقي حول الترميز للاختبار المحلي
الوقت المقدّر لإنهاء الدرس: أقل من ساعة واحدة
يمكنك استخدام أداة الاختبار المحلي على جهازك لتنفيذ عملية تجميع البيانات وإنشاء تقارير ملخّصة باستخدام تقارير تصحيح الأخطاء غير المشفّرة. قبل البدء، تأكَّد من إكمال جميع المتطلبات الأساسية التي تحمل التصنيف "الاختبار المحلي".
خطوات الدرس التطبيقي حول الترميز
الخطوة 2.1: تقرير المشغّل: يمكنك تفعيل إعداد التقارير في Private Aggregation API لتتمكّن من جمع التقرير.
الخطوة 2.2. إنشاء تقرير تصحيح أخطاء AVRO: لتحويل تقرير JSON الذي تم جمعه إلى تقرير بتنسيق AVRO ستكون هذه الخطوة مشابهة للحالات التي تجمع فيها تكنولوجيات الإعلان التقارير من نقاط نهاية إعداد التقارير في واجهة برمجة التطبيقات وتحوّل تقارير JSON إلى تقارير بتنسيق AVRO.
الخطوة 2.3. استرداد مفاتيح الحزمة: يتم تصميم مفاتيح الحزمة من قِبل شركات تكنولوجيا الإعلان. في هذا الدرس العملي، بما أنّ المجموعات محدّدة مسبقًا، عليك استرداد مفاتيح المجموعات كما هو موضّح.
الخطوة 2.4. إنشاء ملف AVRO لنطاق الإخراج: بعد استرداد مفاتيح الحزمة، أنشئ ملف AVRO لنطاق الإخراج.
الخطوة 2.5. إنشاء تقرير ملخّص: استخدِم "أداة الاختبار المحلّي" لتتمكّن من إنشاء تقارير ملخّصة في البيئة المحلية.
الخطوة 2.6. مراجعة التقارير الموجَزة: راجِع "التقرير الموجَز" الذي تنشئه "أداة الاختبار المحلي".
2.1. تقرير المشغّل
لتفعيل تقرير تجميع البيانات الخاص، يمكنك استخدام موقع الحلول التجريبية في مبادرة حماية الخصوصية (https://privacy-sandbox-demos-news.dev/?env=gcp) أو موقعك الإلكتروني (مثل https://adtechexample.com). إذا كنت تستخدم موقعك الإلكتروني ولم تكمل عملية الإعداد في "خدمة التسجيل والشهادة وتجميع البيانات "، عليك استخدام ميزة تجريبية في Chrome ومفتاح واجهة سطر الأوامر.
في هذا العرض التوضيحي، سنستخدم الموقع الإلكتروني التجريبي لمبادرة Privacy Sandbox. اتّبِع الرابط للانتقال إلى الموقع الإلكتروني، ثم يمكنك الاطّلاع على التقارير على chrome://private-aggregation-internals:
 صفحة Chrome الداخلية
صفحة Chrome الداخلية
يمكن العثور على التقرير الذي يتم إرساله إلى نقطة النهاية {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage أيضًا في "نص التقرير" للتقارير المعروضة في صفحة Chrome Internals.
قد تظهر لك هنا العديد من التقارير، ولكن في هذا الدرس التطبيقي حول الترميز، استخدِم التقرير القابل للتجميع الخاص بـ Google Cloud والذي تم إنشاؤه من خلال نقطة تصحيح الأخطاء. سيتضمّن "عنوان URL للتقرير" السلسلة "/debug/"، وسيتضمّن aggregation_coordinator_origin field "نص التقرير" عنوان URL التالي: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
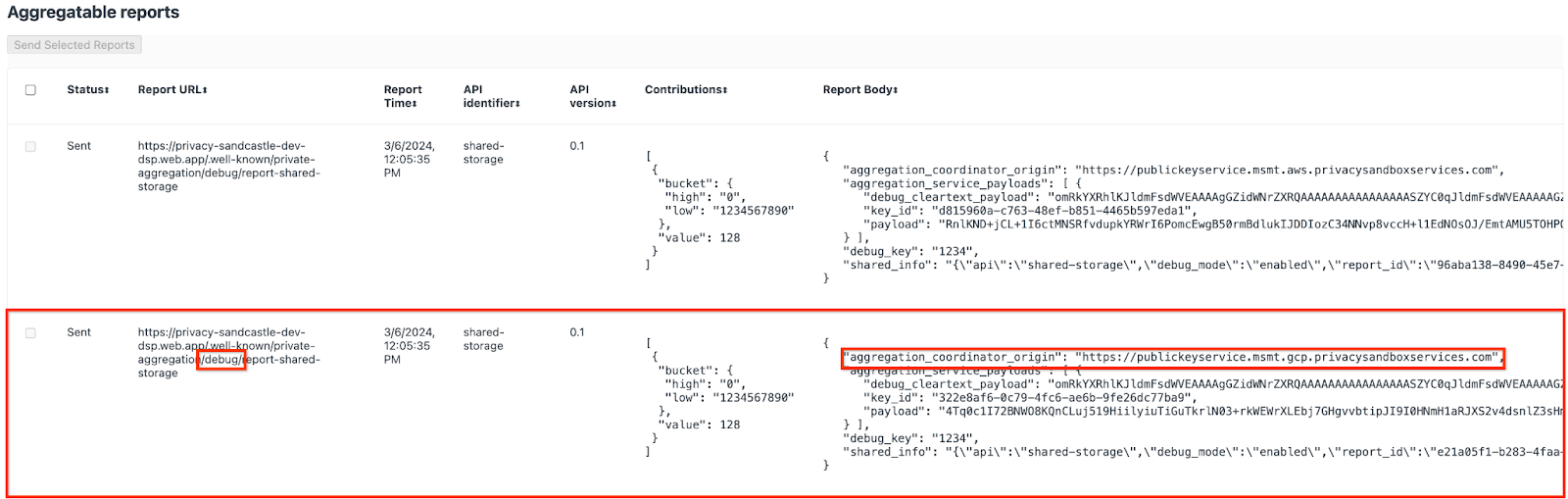 تقرير تصحيح الأخطاء في Google Cloud
تقرير تصحيح الأخطاء في Google Cloud
2.2. إنشاء تقرير قابل للتجميع لتصحيح الأخطاء
انسخ التقرير الذي تم العثور عليه في "نص التقرير" ضمن chrome://private-aggregation-internals وأنشئ ملف JSON في المجلد privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar (ضمن المستودع الذي تم تنزيله في المتطلبات الأساسية 1.5).
في هذا المثال، سنستخدم vim لأنّنا نستخدم نظام التشغيل Linux. يمكنك استخدام أي محرِّر نصوص تريده.
vim report.json
الصِق التقرير في report.json واحفظ الملف.
 رمز JSON الخاص بالتقرير
رمز JSON الخاص بالتقرير
بعد الحصول على ذلك، استخدِم aggregatable_report_converter.jar للمساعدة في إنشاء تقرير تصحيح الأخطاء القابل للتجميع. يؤدي ذلك إلى إنشاء تقرير قابل للتجميع باسم report.avro في الدليل الحالي.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. استرداد مفتاح المجموعة من التقرير
لإنشاء ملف output_domain.avro، تحتاج إلى مفاتيح الحزمة التي يمكن استردادها من التقارير.
يتم تصميم مفاتيح المجموعات من خلال تكنولوجيا الإعلان، ولكن في هذه الحالة، ينشئ الموقع الإلكتروني العرض التوضيحي لمبادرة حماية الخصوصية مفاتيح المجموعات. بما أنّ التجميع الخاص لهذا الموقع الإلكتروني في وضع تصحيح الأخطاء، يمكننا استخدام debug_cleartext_payload من "نص التقرير" للحصول على مفتاح المجموعة.
يمكنك نسخ debug_cleartext_payload من نص التقرير.
 تصحيح الأخطاء في البيانات الأساسية للنص العادي.
تصحيح الأخطاء في البيانات الأساسية للنص العادي.
افتح goo.gle/ags-payload-decoder والصِق debug_cleartext_payload في مربّع "INPUT" وانقر على "Decode".
 زر فك الترميز
زر فك الترميز
تعرض الصفحة القيمة العشرية لمفتاح المجموعة. في ما يلي مثال على مفتاح مجموعة.
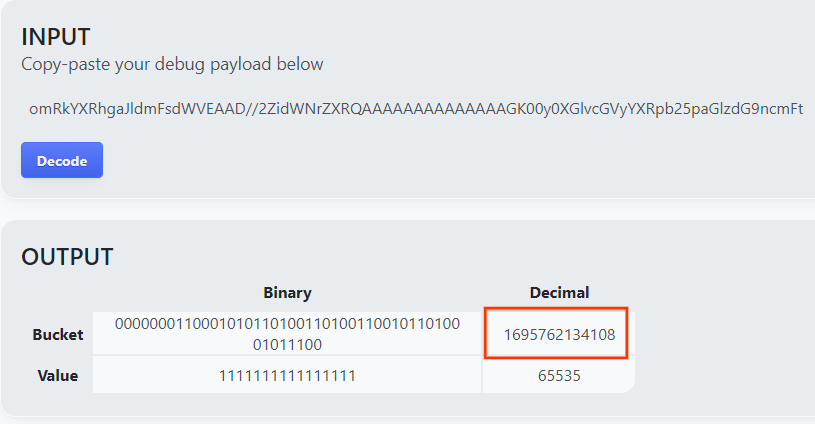 مفتاح مجموعة نموذجية
مفتاح مجموعة نموذجية
2.4. إنشاء ملف AVRO لنطاق الإخراج
بعد الحصول على مفتاح الحزمة، لننشئ output_domain.avro في المجلد نفسه الذي نعمل فيه. تأكَّد من استبدال مفتاح الحزمة بمفتاح الحزمة الذي استرددته.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
ينشئ النص البرمجي الملف output_domain.avro في المجلد الحالي.
2.5. إنشاء "تقارير الملخّص" باستخدام "أداة الاختبار المحلّي"
سنستخدم LocalTestingTool_{version}.jar الذي تم تنزيله في المتطلّب الأساسي 1.3 لإنشاء التقارير الموجزة باستخدام الأمر التالي. استبدِل {version} بالإصدار الذي نزّلته. تذكَّر نقل LocalTestingTool_{version}.jar إلى الدليل الحالي أو إضافة مسار نسبي للإشارة إلى موقعه الحالي.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
من المفترض أن يظهر لك شيء مشابه لما يلي بعد تنفيذ الأمر. يتم إنشاء تقرير output.avro بعد اكتمال هذه العملية.
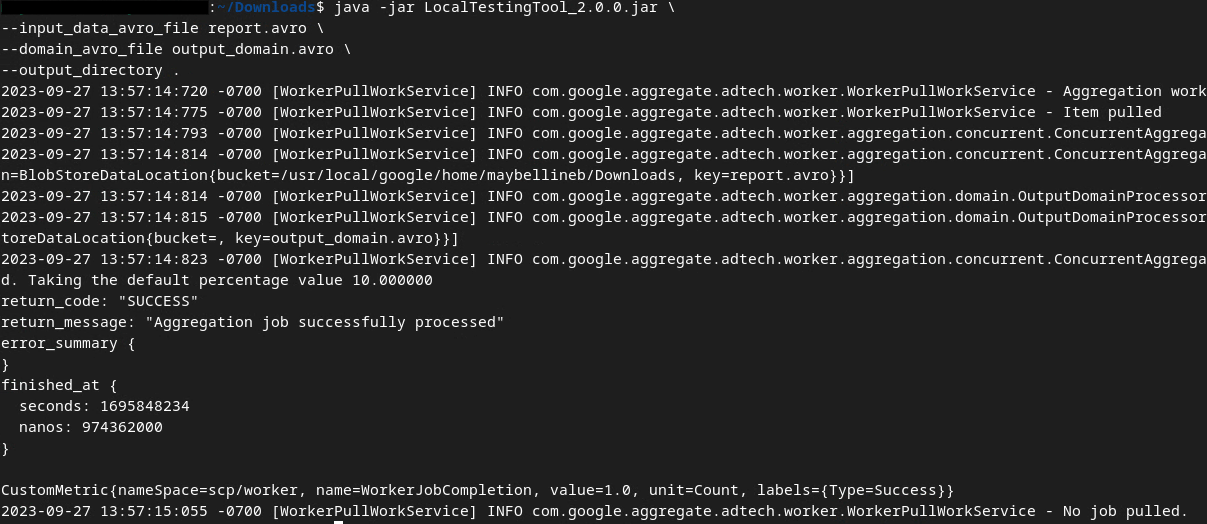 إخراج AVRO
إخراج AVRO
2.6. مراجعة التقرير الموجز
يكون تقرير الملخّص الذي يتم إنشاؤه بتنسيق AVRO. ولكي تتمكّن من قراءة هذا الملف، عليك تحويله من تنسيق AVRO إلى تنسيق JSON. من المفترض أن تكتب تكنولوجيا الإعلان رمزًا برمجيًا لتحويل تقارير AVRO إلى JSON.
سنستخدم aggregatable_report_converter.jar لتحويل تقرير AVRO إلى JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
يؤدي ذلك إلى عرض تقرير مشابه لما يلي. بالإضافة إلى تقرير output.json تم إنشاؤه في المجلد نفسه.
 إخراج JSON
إخراج JSON
اكتمل الدرس التطبيقي حول الترميز.
الملخّص: جمعت تقرير تصحيح الأخطاء، وأنشأت ملف نطاق الإخراج، وأنشأت تقريرًا موجزًا باستخدام أداة الاختبار المحلية التي تحاكي سلوك التجميع في "خدمة تجميع البيانات".
الخطوات التالية: بعد تجربة "أداة الاختبار المحلي"، يمكنك تجربة التمرين نفسه مع نشر مباشر لـ "خدمة تجميع البيانات" في بيئتك الخاصة. راجِع المتطلبات الأساسية للتأكّد من أنّك أعددت كل شيء لوضع "خدمة التجميع"، ثم انتقِل إلى الخطوة 3.
3- 3- درس تطبيقي حول الترميز في Aggregation Service
الوقت المقدّر لإنهاء الدرس: ساعة واحدة
قبل البدء، تأكَّد من إكمال جميع المتطلبات الأساسية التي تحمل التصنيف "خدمة التجميع".
خطوات الدرس التطبيقي حول الترميز
الخطوة 3.1. إنشاء بيانات الإدخال في "خدمة تجميع البيانات": يمكنك إنشاء تقارير "خدمة تجميع البيانات" التي يتم تجميعها في حِزم من أجل "خدمة تجميع البيانات".
- الخطوة 3.1.1. تقرير المشغِّل
- الخطوة 3.1.2. جمع التقارير القابلة للتجميع
- الخطوة 3.1.3. تحويل التقارير إلى تنسيق AVRO
- الخطوة 3.1.4. إنشاء ملف AVRO الخاص بـ output_domain
- الخطوة 3.1.5. نقل التقارير إلى حزمة Cloud Storage
الخطوة 3.2. استخدام "خدمة تجميع البيانات": استخدِم واجهة برمجة التطبيقات الخاصة بـ "خدمة تجميع البيانات" لإنشاء "التقارير الموجَزة" ومراجعتها.
- الخطوة 3.2.1. استخدام نقطة نهاية
createJobلإنشاء مجموعات - الخطوة 3.2.2. استخدام نقطة نهاية
getJobلاسترداد حالة الدُفعة - الخطوة 3.2.3. مراجعة التقرير الموجز
3.1. إنشاء بيانات الإدخال في "خدمة تجميع البيانات"
انتقِل إلى إنشاء تقارير AVRO لتجميعها في "خدمة تجميع البيانات". يمكن تنفيذ أوامر shell في هذه الخطوات ضِمن Cloud Shell من Google Cloud (طالما تم استنساخ التبعيات من "المتطلبات الأساسية" إلى بيئة Cloud Shell) أو في بيئة تنفيذ محلية.
3.1.1. تقرير المشغِّل
اتّبِع الرابط للانتقال إلى الموقع الإلكتروني، ثم يمكنك الاطّلاع على التقارير على chrome://private-aggregation-internals:
صفحة Chrome الداخلية
يمكن العثور على التقرير الذي يتم إرساله إلى نقطة النهاية {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage أيضًا في "نص التقرير" للتقارير المعروضة في صفحة Chrome Internals.
قد تظهر لك هنا العديد من التقارير، ولكن في هذا الدرس التطبيقي حول الترميز، استخدِم التقرير القابل للتجميع الخاص بـ Google Cloud والذي تم إنشاؤه من خلال نقطة تصحيح الأخطاء. سيتضمّن "عنوان URL للتقرير" السلسلة "/debug/"، وسيتضمّن aggregation_coordinator_origin field "نص التقرير" عنوان URL التالي: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
تقرير تصحيح الأخطاء في Google Cloud
3.1.2. جمع التقارير القابلة للتجميع
اجمع تقاريرك القابلة للتجميع من نقاط النهاية المعروفة لواجهة برمجة التطبيقات المعنية.
- التجميع الخاص:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - Attribution Reporting - تقرير الملخّص:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
في هذا الدرس التطبيقي حول الترميز، نجمع التقارير يدويًا. في مرحلة الإنتاج، من المتوقّع أن يجمع مزوّدو تكنولوجيا الإعلان التقارير ويحوّلونها آليًا.
لننسخ تقرير JSON في "نص التقرير" من chrome://private-aggregation-internals.
في هذا المثال، نستخدم vim لأنّنا نستعمل نظام التشغيل Linux. يمكنك استخدام أي محرِّر نصوص تريده.
vim report.json
الصِق التقرير في report.json واحفظ الملف.
تقرير JSON
3.1.3. تحويل التقارير إلى تنسيق AVRO
تكون التقارير الواردة من نقاط النهاية .well-known بتنسيق JSON ويجب تحويلها إلى تنسيق تقرير AVRO. بعد الحصول على تقرير JSON، انتقِل إلى المكان الذي يتم فيه تخزين report.json واستخدِم aggregatable_report_converter.jar للمساعدة في إنشاء تقرير مجمّع لتصحيح الأخطاء. يؤدي ذلك إلى إنشاء تقرير قابل للتجميع باسم report.avro في الدليل الحالي.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. إنشاء output_domain AVRO
لإنشاء ملف output_domain.avro، تحتاج إلى مفاتيح الحزمة التي يمكن استردادها من التقارير.
يتم تصميم مفاتيح المجموعات من خلال تكنولوجيا الإعلان، ولكن في هذه الحالة، ينشئ الموقع الإلكتروني العرض التوضيحي لمبادرة حماية الخصوصية مفاتيح المجموعات. بما أنّ التجميع الخاص لهذا الموقع الإلكتروني في وضع تصحيح الأخطاء، يمكننا استخدام debug_cleartext_payload من "نص التقرير" للحصول على مفتاح المجموعة.
يمكنك نسخ debug_cleartext_payload من نص التقرير.
تصحيح الأخطاء في البيانات الأساسية للنص العادي.
افتح goo.gle/ags-payload-decoder والصِق debug_cleartext_payload في مربّع "INPUT" وانقر على "Decode".
زر فك الترميز
تعرض الصفحة القيمة العشرية لمفتاح المجموعة. في ما يلي مثال على مفتاح مجموعة.
مفتاح مجموعة نموذجية
بعد الحصول على مفتاح الحزمة، لننشئ output_domain.avro في المجلد نفسه الذي نعمل فيه. تأكَّد من استبدال مفتاح الحزمة بمفتاح الحزمة الذي استرددته.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
ينشئ النص البرمجي الملف output_domain.avro في المجلد الحالي.
3.1.5. نقل التقارير إلى حزمة Cloud Storage
بعد إنشاء تقارير AVRO ونطاق الإخراج، انتقِل إلى نقل التقارير ونطاق الإخراج إلى الحزمة في Cloud Storage (التي أشرت إليها في المتطلّب الأساسي 1.6).
إذا كان لديك إعداد gcloud CLI في بيئتك المحلية، استخدِم الأوامر التالية لنسخ الملفات إلى المجلدات المناسبة.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
بخلاف ذلك، حمِّل الملفات يدويًا إلى الحزمة. أنشئ مجلدًا باسم "تقارير" وحمِّل ملف report.avro فيه. أنشئ مجلدًا باسم "output_domains" وحمِّل ملف output_domain.avro إليه.
3.2. استخدام "خدمة تجميع البيانات"
تذكَّر في المتطلب الأساسي 1.8 أنّك اخترت curl أو Postman لإجراء طلبات إلى نقاط نهاية Aggregation Service. في ما يلي تعليمات لكلا الخيارَين.
إذا تعذّر إكمال مهمتك بسبب حدوث خطأ، يمكنك الاطّلاع على مستندات تحديد المشاكل وحلّها في GitHub للحصول على مزيد من المعلومات حول كيفية المتابعة.
3.2.1. استخدام نقطة نهاية createJob لإنشاء مجموعات
استخدِم إحدى تعليمات curl أو Postman التالية لإنشاء مهمة.
curl
في "الوحدة الطرفية"، أنشئ ملف نص الطلب (body.json) والصِق فيه عنصر JSON التالي. احرص على تعديل قيم العناصر النائبة. يُرجى الرجوع إلى مستندات واجهة برمجة التطبيقات هذه للحصول على مزيد من المعلومات حول ما يمثّله كل حقل.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
نفِّذ الطلب التالي. استبدِل العناصر النائبة في عنوان URL لطلب curl بالقيم من frontend_service_cloudfunction_url، والتي يتم إخراجها بعد إكمال عملية نشر Terraform بنجاح في المتطلّب الأساسي 1.6.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
من المفترض أن تتلقّى الردّ HTTP 202 بعد أن تقبل خدمة التجميع الطلب. تم توثيق رموز الاستجابة الأخرى المحتملة في مواصفات واجهة برمجة التطبيقات.
Postman
بالنسبة إلى نقطة النهاية createJob، يجب توفير نص الطلب من أجل تزويد "خدمة التجميع" بموقع وأسماء ملفات التقارير القابلة للتجميع ونطاقات الإخراج والتقارير الموجزة.
انتقِل إلى علامة التبويب "النص" (Body) الخاصة بطلب createJob:
 علامة التبويب "النص الأساسي"
علامة التبويب "النص الأساسي"
استبدِل العناصر النائبة ضمن ملف JSON المقدَّم. لمزيد من المعلومات حول هذه الحقول وما تمثّله، يُرجى الرجوع إلى مستندات واجهة برمجة التطبيقات.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
"إرسال" طلب البيانات من واجهة برمجة التطبيقات createJob:
 زر الإرسال
زر الإرسال
يمكن العثور على رمز الاستجابة في النصف السفلي من الصفحة:
 رمز الاستجابة
رمز الاستجابة
من المفترض أن تتلقّى الردّ HTTP 202 بعد أن تقبل خدمة التجميع الطلب. تم توثيق رموز الاستجابة الأخرى المحتملة في مواصفات واجهة برمجة التطبيقات.
3.2.2. استخدام نقطة نهاية getJob لاسترداد حالة الدُفعة
استخدِم إحدى تعليمات curl أو Postman التالية للحصول على مهمة.
curl
نفِّذ الطلب التالي في "الوحدة الطرفية". استبدِل العناصر النائبة في عنوان URL بالقيم من frontend_service_cloudfunction_url، وهو عنوان URL نفسه الذي استخدمته في طلب createJob. بالنسبة إلى "job_request_id"، استخدِم القيمة من مهمة الإنشاء التي أجريتها باستخدام نقطة النهاية createJob.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
يجب أن تعرض النتيجة حالة طلب الوظيفة مع حالة HTTP 200. يحتوي "نص" الطلب على المعلومات اللازمة، مثل job_status وreturn_message وerror_messages (في حال حدوث خطأ في المهمة).
Postman
للتحقّق من حالة طلب الوظيفة، يمكنك استخدام نقطة النهاية getJob. في قسم "المَعلمات" (Params) لطلب getJob، عدِّل قيمة job_request_id إلى job_request_id التي تم إرسالها في طلب createJob.
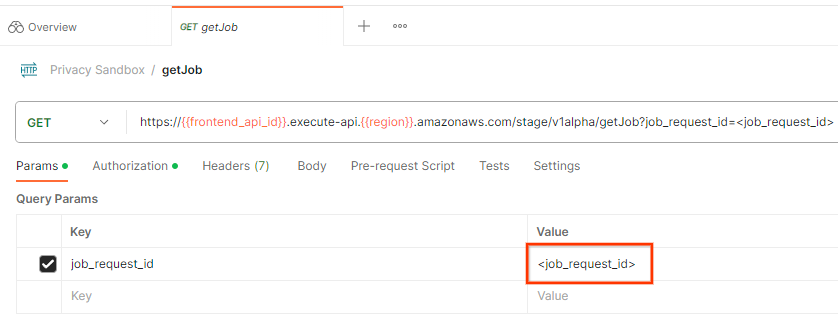 معرّف طلب الوظيفة
معرّف طلب الوظيفة
أرسِل طلب getJob:
 زر الإرسال
زر الإرسال
يجب أن تعرض النتيجة حالة طلب الوظيفة مع حالة HTTP 200. يحتوي "نص" الطلب على المعلومات اللازمة، مثل job_status وreturn_message وerror_messages (في حال حدوث خطأ في المهمة).
 استجابة JSON
استجابة JSON
3.2.3. مراجعة التقرير الموجز
بعد تلقّي تقرير الملخّص في حزمة Cloud Storage الناتجة، يمكنك تنزيله إلى بيئتك المحلية. تكون التقارير الموجزة بتنسيق AVRO ويمكن تحويلها مرة أخرى إلى JSON. يمكنك استخدام aggregatable_report_converter.jar لقراءة تقريرك باستخدام هذا الأمر.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
تعرض هذه السمة ملف JSON يتضمّن القيم المجمّعة لكل مفتاح مجموعة يشبه ما يلي.
 تقرير موجز
تقرير موجز
إذا كان طلب createJob يتضمّن debug_run بالقيمة "صحيح"، يمكنك تلقّي التقرير الموجز في مجلد تصحيح الأخطاء الموجود في output_data_blob_prefix. يكون التقرير بتنسيق AVRO ويمكن تحويله إلى JSON باستخدام الأمر السابق.
يحتوي التقرير على مفتاح المجموعة والمقياس غير المشوّش والتشويش الذي تتم إضافته إلى المقياس غير المشوّش لتكوين التقرير الموجز. يكون التقرير مشابهاً لما يلي.
 تقرير مشوّش
تقرير مشوّش
تحتوي التعليقات التوضيحية أيضًا على "in_reports" أو "in_domain" (أو كليهما)، ما يعني:
- in_reports: يتوفّر مفتاح المجموعة داخل التقارير القابلة للتجميع.
- in_domain: يتوفّر مفتاح المجموعة داخل ملف AVRO الخاص بـ output_domain.
اكتمل الدرس التطبيقي حول الترميز.
الملخّص: لقد نشرت "خدمة التجميع" في بيئة السحابة الإلكترونية الخاصة بك، وجمّعت تقرير تصحيح الأخطاء، وأنشأت ملف نطاق الإخراج، وخزّنت هذه الملفات في حزمة Cloud Storage، ونفّذت مهمة بنجاح.
الخطوات التالية: واصِل استخدام "خدمة التجميع" في بيئتك، أو احذف موارد السحابة الإلكترونية التي أنشأتها للتو باتّباع تعليمات التنظيف في الخطوة 4.
4. 4. الإزالة
لحذف الموارد التي تم إنشاؤها لخدمة "التجميع" باستخدام Terraform، استخدِم أمر destroy في المجلدَين adtech_setup وdev (أو أي بيئة أخرى):
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
لحذف حزمة Cloud Storage التي تحتوي على التقارير القابلة للتجميع والتقارير الموجزة، اتّبِع الخطوات التالية:
$ gcloud storage buckets delete gs://my-bucket
يمكنك أيضًا اختيار إعادة إعدادات ملفات تعريف الارتباط في Chrome من "المتطلب الأساسي 1.2" إلى حالتها السابقة.
5- 5- الملحق
مثال على ملف adtech_setup.auto.tfvars
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
مثال على ملف dev.auto.tfvars
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20