
1. 1. ข้อกำหนดเบื้องต้น
เวลาที่ใช้โดยประมาณ: 1-2 ชั่วโมง
โหมดสำหรับการทำ Codelab นี้มี 2 โหมด ได้แก่ การทดสอบในเครื่องหรือบริการรวบรวมข้อมูล โหมดการทดสอบในเครื่องต้องใช้เครื่องในพื้นที่และเบราว์เซอร์ Chrome (ไม่ต้องสร้าง/ใช้ทรัพยากร Google Cloud) โหมดบริการรวมข้อมูลต้องมีการติดตั้งใช้งานบริการรวมข้อมูลอย่างเต็มรูปแบบใน Google Cloud
หากต้องการทำ Codelab นี้ในโหมดใดโหมดหนึ่ง คุณต้องมีข้อกำหนดเบื้องต้น 2-3 อย่าง ข้อกำหนดแต่ละข้อจะมีการทำเครื่องหมายตามความเหมาะสม ไม่ว่าจะเป็นข้อกำหนดสำหรับการทดสอบในพื้นที่หรือบริการรวบรวมข้อมูล
1.1 ลงทะเบียนและรับรองให้เสร็จสมบูรณ์ (บริการรวมข้อมูล)
หากต้องการใช้ Privacy Sandbox API ให้ตรวจสอบว่าคุณได้ทำการลงทะเบียนและการรับรองทั้งสำหรับ Chrome และ Android เสร็จสมบูรณ์แล้ว
1.2 เปิดใช้ Ad Privacy API (การทดสอบในเครื่องและบริการรวบรวมข้อมูล)
เนื่องจากเราจะใช้ Privacy Sandbox เราจึงขอแนะนำให้คุณเปิดใช้ Privacy Sandbox Ads API
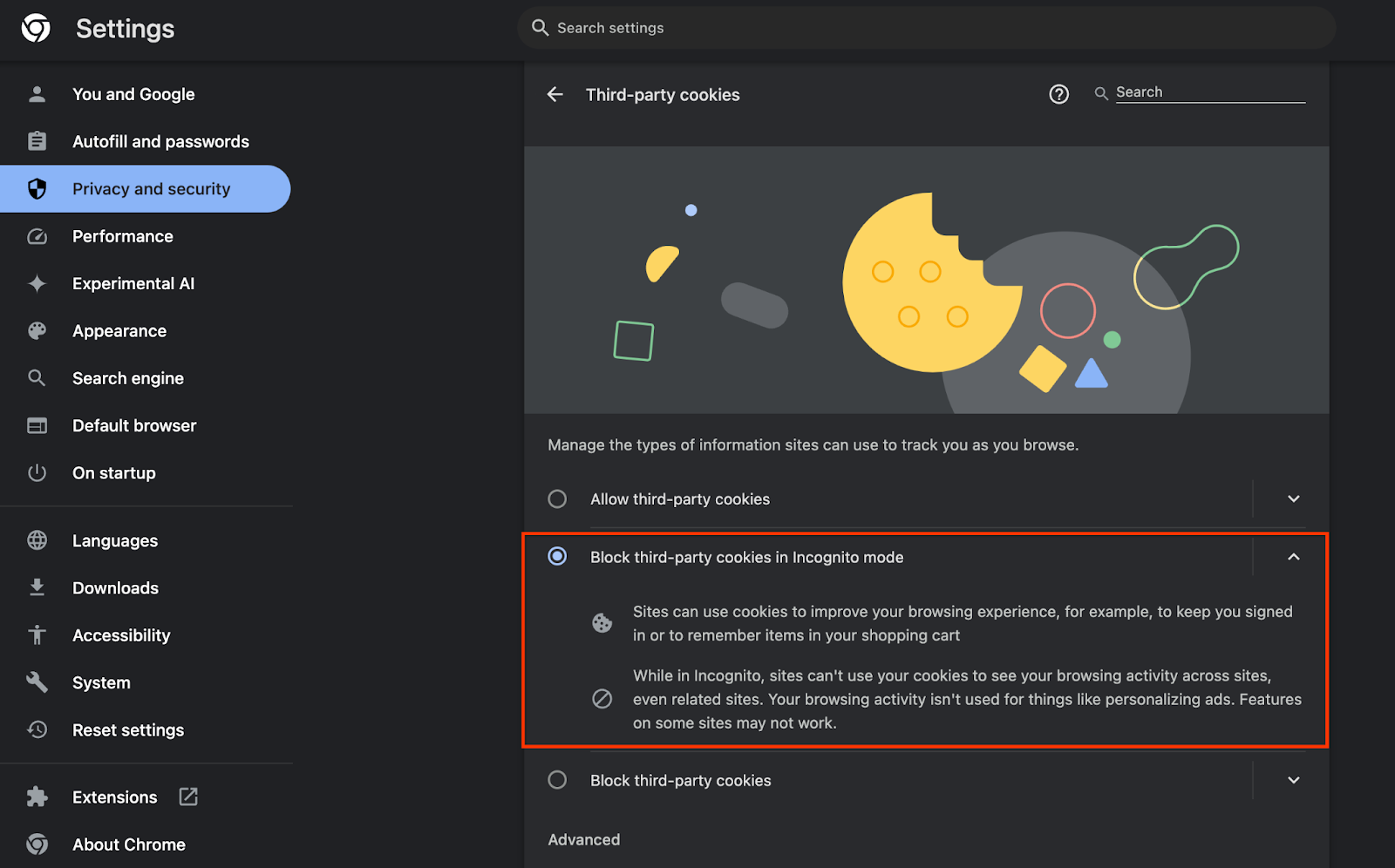
ไปที่ chrome://settings/adPrivacy ในเบราว์เซอร์ แล้วเปิดใช้ Ad Privacy API ทั้งหมด
และตรวจสอบว่าเปิดใช้คุกกี้ของบุคคลที่สามแล้ว
จาก chrome://settings/cookies ให้ตรวจสอบว่าไม่ได้บล็อกคุกกี้ของบุคคลที่สาม คุณอาจเห็นตัวเลือกที่แตกต่างกันในเมนูการตั้งค่านี้ ทั้งนี้ขึ้นอยู่กับเวอร์ชันของ Chrome แต่การกำหนดค่าที่ยอมรับได้ ได้แก่
- "บล็อกคุกกี้ของบุคคลที่สามทั้งหมด" = ปิดใช้
- "บล็อกคุกกี้ของบุคคลที่สาม" = ปิดใช้
- "บล็อกคุกกี้ของบุคคลที่สามในโหมดไม่ระบุตัวตน" = เปิดใช้
 การเปิดใช้คุกกี้
การเปิดใช้คุกกี้
1.3 ดาวน์โหลดเครื่องมือทดสอบในเครื่อง (Local Testing)
การทดสอบในพื้นที่ต้องดาวน์โหลดเครื่องมือทดสอบในพื้นที่ เครื่องมือจะสร้างรายงานสรุปจากรายงานการแก้ไขข้อบกพร่องที่ไม่ได้เข้ารหัส
เครื่องมือทดสอบในเครื่องพร้อมให้ดาวน์โหลดในที่เก็บถาวร JAR ของ Cloud Function ใน GitHub โดยควรตั้งชื่อว่า LocalTestingTool_{version}.jar
1.4. ตรวจสอบว่าได้ติดตั้ง JAVA JRE แล้ว (บริการทดสอบและการรวบรวมข้อมูลในเครื่อง)
เปิด "Terminal" แล้วใช้ java --version เพื่อตรวจสอบว่าเครื่องของคุณติดตั้ง Java หรือ openJDK หรือไม่
 ตรวจสอบเวอร์ชัน Java
ตรวจสอบเวอร์ชัน Java
หากยังไม่ได้ติดตั้ง คุณสามารถดาวน์โหลดและติดตั้งจากเว็บไซต์ Java หรือเว็บไซต์ openJDK
1.5. ดาวน์โหลด aggregatable_report_converter (การทดสอบในเครื่องและบริการรวมข้อมูล)
คุณดาวน์โหลดสำเนาของ aggregatable_report_converter ได้จากที่เก็บ GitHub ของการสาธิต Privacy Sandbox ที่เก็บ GitHub กล่าวถึงการใช้ IntelliJ หรือ Eclipse แต่ทั้ง 2 อย่างนี้ไม่ได้เป็นข้อกำหนด หากไม่ได้ใช้เครื่องมือเหล่านี้ ให้ดาวน์โหลดไฟล์ JAR ไปยังสภาพแวดล้อมในเครื่องแทน
1.6. ตั้งค่าสภาพแวดล้อมของ Cloud Platform (บริการรวบรวมข้อมูล)
บริการรวบรวมข้อมูลกำหนดให้ใช้สภาพแวดล้อมการดำเนินการที่เชื่อถือได้ซึ่งใช้ผู้ให้บริการระบบคลาวด์ ในโค้ดแล็บนี้ เราจะติดตั้งใช้งานบริการรวบรวมข้อมูลใน Google Cloud แต่ AWS ก็รองรับด้วย
ทำตามวิธีการติดตั้งใช้งานใน GitHub เพื่อตั้งค่า gcloud CLI, ดาวน์โหลดไบนารีและโมดูล Terraform รวมถึงสร้างทรัพยากร Google Cloud สำหรับบริการรวบรวมข้อมูล
ขั้นตอนสำคัญในวิธีการติดตั้งใช้งานมีดังนี้
- ตั้งค่า "gcloud" CLI และ Terraform ในสภาพแวดล้อมของคุณ
- สร้าง Bucket ของ Cloud Storage เพื่อจัดเก็บสถานะ Terraform
- ดาวน์โหลดทรัพยากร Dependency
- อัปเดต
adtech_setup.auto.tfvarsแล้วเรียกใช้adtech_setupTerraform ดูตัวอย่างไฟล์adtech_setup.auto.tfvarsได้ที่ภาคผนวก จดชื่อของที่เก็บข้อมูลที่สร้างขึ้นที่นี่ ซึ่งจะใช้ใน Codelab เพื่อจัดเก็บไฟล์ที่เราสร้าง - อัปเดต
dev.auto.tfvarsแอบอ้างบัญชีบริการที่ใช้ในการติดตั้งใช้งาน และเรียกใช้devTerraform ดูตัวอย่างไฟล์dev.auto.tfvarsได้ที่ภาคผนวก - เมื่อการติดตั้งใช้งานเสร็จสมบูรณ์แล้ว บันทึก
frontend_service_cloudfunction_urlจากเอาต์พุตของ Terraform ซึ่งจะต้องใช้เพื่อส่งคำขอไปยังบริการรวมข้อมูลในขั้นตอนต่อๆ ไป
1.7 ทําการเริ่มต้นใช้งานบริการรวมข้อมูลให้เสร็จสมบูรณ์ (บริการรวมข้อมูล)
บริการรวมข้อมูลกำหนดให้ต้องเริ่มต้นใช้งานกับผู้ประสานงานจึงจะใช้บริการได้ กรอกแบบฟอร์มการเริ่มต้นใช้งานบริการรวบรวมข้อมูลโดยระบุเว็บไซต์รายงานและข้อมูลอื่นๆ เลือก "Google Cloud" และป้อนที่อยู่บัญชีบริการ บัญชีบริการนี้จะสร้างขึ้นในข้อกำหนดเบื้องต้นก่อนหน้า (1.6. ตั้งค่าสภาพแวดล้อม Google Cloud) (เคล็ดลับ: หากคุณใช้ชื่อเริ่มต้นที่ระบุไว้ บัญชีบริการนี้จะขึ้นต้นด้วย "worker-sa@")
โปรดรอไม่เกิน 2 สัปดาห์เพื่อให้กระบวนการเริ่มต้นใช้งานเสร็จสมบูรณ์
1.8 กำหนดวิธีเรียกใช้ปลายทาง API (บริการรวบรวมข้อมูล)
Codelab นี้มี 2 ตัวเลือกสำหรับการเรียกใช้ปลายทาง API ของบริการรวบรวมข้อมูล ได้แก่ cURL และ Postman cURL เป็นวิธีที่รวดเร็วและง่ายกว่าในการเรียกใช้ปลายทาง API จากเทอร์มินัล เนื่องจากต้องมีการตั้งค่าเพียงเล็กน้อยและไม่ต้องใช้ซอฟต์แวร์เพิ่มเติม อย่างไรก็ตาม หากไม่ต้องการใช้ cURL คุณสามารถใช้ Postman แทนเพื่อเรียกใช้และบันทึกคำขอ API ไว้ใช้ในอนาคตได้
ในส่วนที่ 3.2 การใช้งานบริการรวมข้อมูล คุณจะเห็นวิธีการโดยละเอียดในการใช้ทั้ง 2 ตัวเลือก คุณสามารถดูตัวอย่างได้ตอนนี้เพื่อพิจารณาว่าคุณจะใช้วิธีใด หากเลือก Postman ให้ทำการตั้งค่าเริ่มต้นต่อไปนี้
1.8.1. ตั้งค่าพื้นที่ทำงาน
ลงชื่อสมัครใช้บัญชี Postman เมื่อลงชื่อสมัครใช้แล้ว ระบบจะสร้างพื้นที่ทำงานให้คุณโดยอัตโนมัติ
 พื้นที่ทำงาน Postman
พื้นที่ทำงาน Postman
หากระบบไม่ได้สร้างพื้นที่ทำงานให้คุณ ให้ไปที่รายการการนำทางด้านบน "พื้นที่ทำงาน" แล้วเลือก "สร้างพื้นที่ทำงาน"
เลือก "พื้นที่ทำงานเปล่า" คลิกถัดไป แล้วตั้งชื่อว่า "GCP Privacy Sandbox" เลือก "ส่วนตัว" แล้วคลิก "สร้าง"
ดาวน์โหลดการกำหนดค่า JSON ของพื้นที่ทำงานที่กำหนดค่าไว้ล่วงหน้าและไฟล์สภาพแวดล้อมส่วนกลาง
นำเข้าไฟล์ JSON ทั้ง 2 ไฟล์ไปยัง "พื้นที่ทํางานของฉัน" โดยใช้ปุ่ม "นําเข้า"
 ปุ่มนำเข้า
ปุ่มนำเข้า
การดำเนินการนี้จะสร้างคอลเล็กชัน "GCP Privacy Sandbox" พร้อมกับคำขอ HTTP createJob และ getJob
1.8.2. ตั้งค่าการให้สิทธิ์
คลิกคอลเล็กชัน "GCP Privacy Sandbox" แล้วไปที่แท็บ "การให้สิทธิ์"
 ปุ่มการให้สิทธิ์
ปุ่มการให้สิทธิ์
คุณจะใช้วิธี "โทเค็น Bearer" จากสภาพแวดล้อมเทอร์มินัล ให้เรียกใช้คำสั่งนี้และคัดลอกเอาต์พุต
gcloud auth print-identity-token
จากนั้นวางค่าโทเค็นนี้ในช่อง "โทเค็น" ของแท็บการให้สิทธิ์ Postman
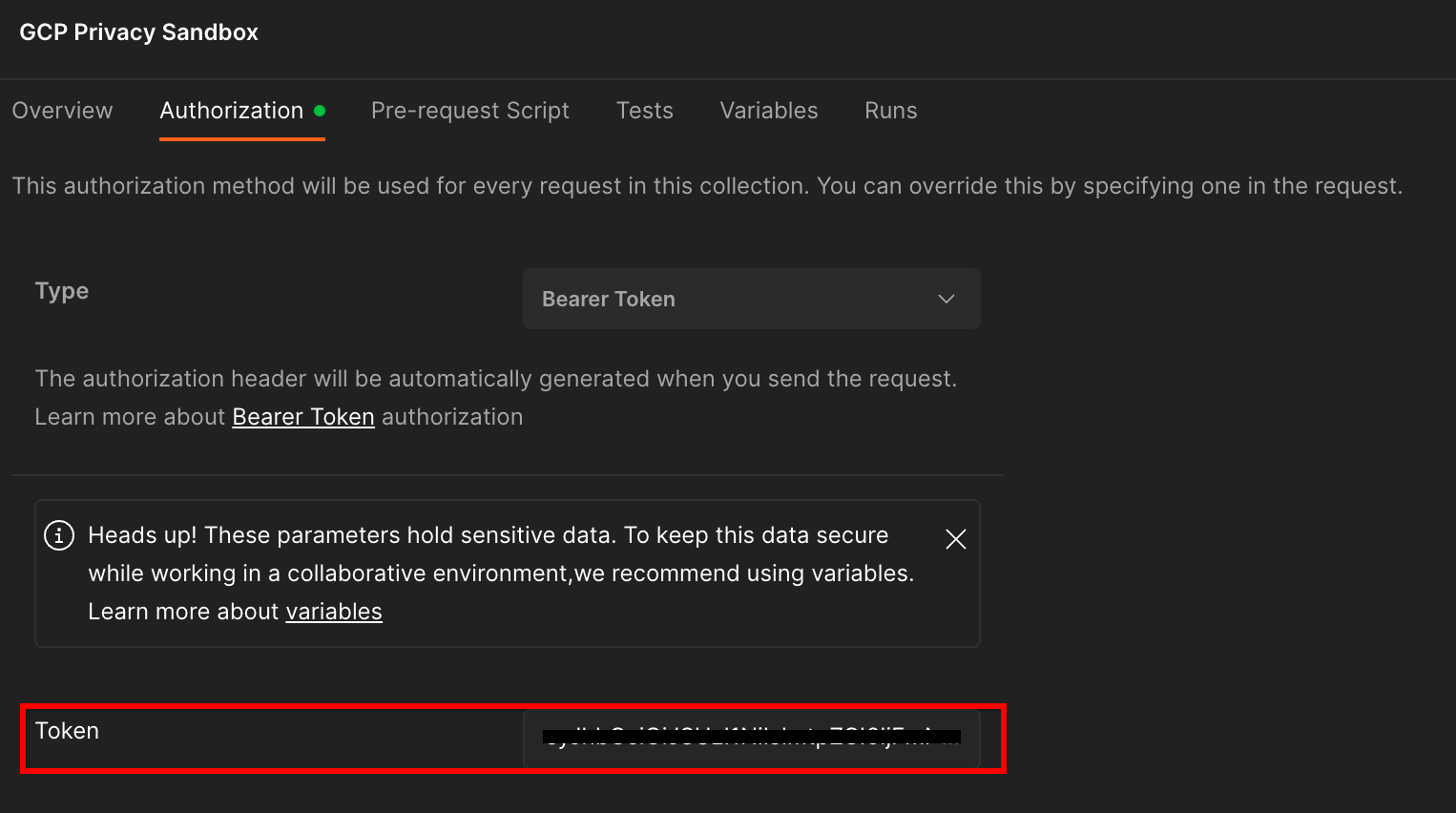 ฟิลด์ "โทเค็น"
ฟิลด์ "โทเค็น"
1.8.3. ตั้งค่าสภาพแวดล้อม
ไปที่ "ภาพรวมสภาพแวดล้อม" ที่มุมขวาบน
 ปุ่มดูข้อมูลสภาพแวดล้อมอย่างรวดเร็ว
ปุ่มดูข้อมูลสภาพแวดล้อมอย่างรวดเร็ว
คลิก "แก้ไข" แล้วอัปเดต "ค่าปัจจุบัน" ของ "environment", "region" และ "cloud-function-id" ดังนี้
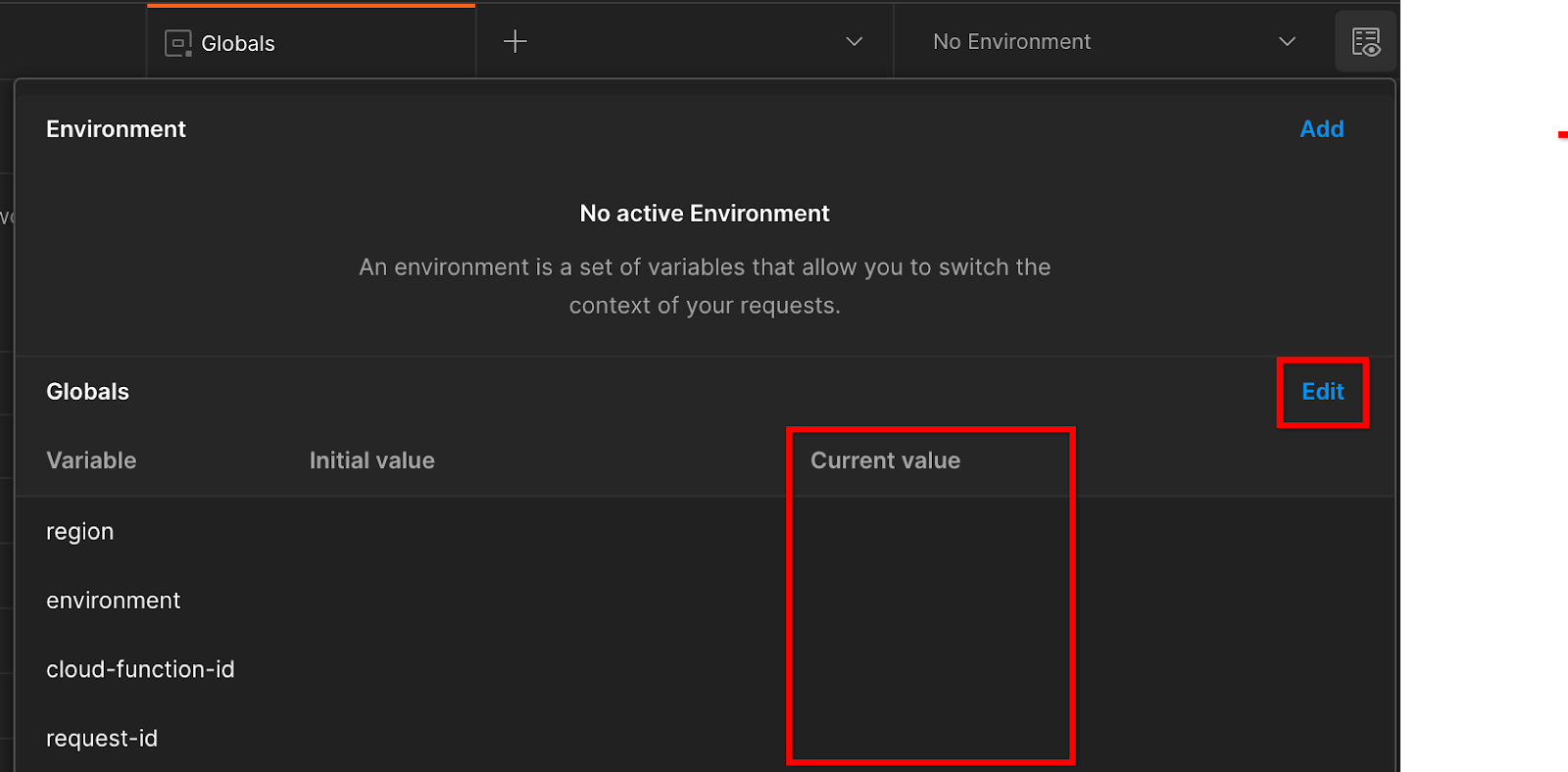 ตั้งค่าปัจจุบัน
ตั้งค่าปัจจุบัน
คุณเว้น "request-id" ว่างไว้ก่อนได้ เนื่องจากเราจะกรอกข้อมูลในภายหลัง สำหรับฟิลด์อื่นๆ ให้ใช้ค่าจาก frontend_service_cloudfunction_url ซึ่งได้จากการติดตั้งใช้งาน Terraform ที่สำเร็จในข้อกำหนดเบื้องต้น 1.6 URL จะมีรูปแบบดังนี้ https://
2. 2. Codelab การทดสอบในเครื่อง
เวลาที่ใช้โดยประมาณ: น้อยกว่า 1 ชั่วโมง
คุณสามารถใช้เครื่องมือทดสอบในเครื่องเพื่อทำการรวบรวมและสร้างรายงานสรุปโดยใช้รายงานการแก้ไขข้อบกพร่องที่ไม่ได้เข้ารหัส ก่อนที่จะเริ่มต้น ให้ตรวจสอบว่าคุณได้ทำตามข้อกำหนดเบื้องต้นทั้งหมดที่มีป้ายกำกับว่า "การทดสอบในพื้นที่" แล้ว
ขั้นตอน Codelab
ขั้นตอนที่ 2.1 รายงานทริกเกอร์: ทริกเกอร์การรายงาน Private Aggregation เพื่อให้รวบรวมรายงานได้
ขั้นตอนที่ 2.2 สร้างรายงาน AVRO สำหรับการแก้ไขข้อบกพร่อง: แปลงรายงาน JSON ที่รวบรวมแล้วเป็นรายงานในรูปแบบ AVRO ขั้นตอนนี้จะคล้ายกับเมื่อเทคโนโลยีโฆษณารวบรวมรายงานจากปลายทางการรายงาน API และแปลงรายงาน JSON เป็นรายงานรูปแบบ AVRO
ขั้นตอนที่ 2.3 ดึงข้อมูลคีย์ของที่เก็บข้อมูล: เทคโนโลยีโฆษณาออกแบบคีย์ของที่เก็บข้อมูล ใน Codelab นี้ เนื่องจากมีการกำหนด Bucket ไว้ล่วงหน้าแล้ว ให้ดึงคีย์ Bucket ตามที่ระบุ
ขั้นตอนที่ 2.4 สร้าง AVRO ของโดเมนเอาต์พุต: เมื่อดึงคีย์ของที่เก็บข้อมูลแล้ว ให้สร้างไฟล์ AVRO ของโดเมนเอาต์พุต
ขั้นตอนที่ 2.5 สร้างรายงานสรุป: ใช้เครื่องมือทดสอบในเครื่องเพื่อสร้างรายงานสรุปในสภาพแวดล้อมในเครื่อง
ขั้นตอนที่ 2.6 ตรวจสอบรายงานสรุป: ตรวจสอบรายงานสรุปที่สร้างโดยเครื่องมือทดสอบในพื้นที่
2.1 รายงานทริกเกอร์
หากต้องการเรียกใช้รายงานการรวบรวมข้อมูลแบบส่วนตัว คุณสามารถใช้เว็บไซต์เดโมของ Privacy Sandbox (https://privacy-sandbox-demos-news.dev/?env=gcp) หรือเว็บไซต์ของคุณเอง (เช่น https://adtechexample.com) หากใช้เว็บไซต์ของตนเองและยังไม่ได้ลงทะเบียนและยืนยัน รวมถึงเริ่มต้นใช้งานบริการรวบรวมข้อมูล คุณจะต้องใช้ Chrome Flag และสวิตช์ CLI
สําหรับการสาธิตนี้ เราจะใช้เว็บไซต์สาธิตของ Privacy Sandbox ไปที่เว็บไซต์โดยคลิกลิงก์ จากนั้นดูรายงานได้ที่ chrome://private-aggregation-internals
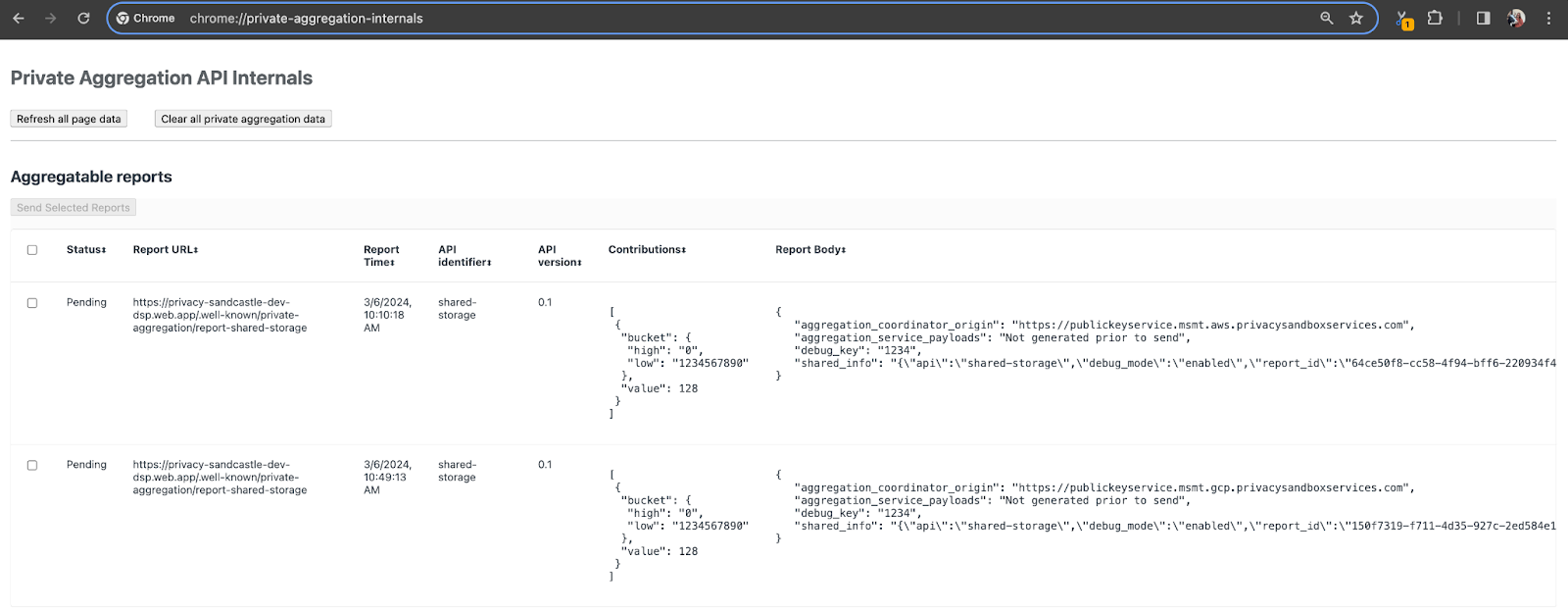 หน้าภายในของ Chrome
หน้าภายในของ Chrome
รายงานที่ส่งไปยัง{reporting-origin}/.well-known/private-aggregation/debug/report-shared-storageปลายทางจะอยู่ใน "เนื้อหารายงาน" ของรายงานที่แสดงในหน้า chrome://internals ด้วย
คุณอาจเห็นรายงานจํานวนมากที่นี่ แต่สําหรับโค้ดแล็บนี้ ให้ใช้รายงานแบบรวมที่เฉพาะเจาะจงสําหรับ Google Cloud และสร้างขึ้นโดยปลายทางการแก้ไขข้อบกพร่อง "URL ของรายงาน" จะมี "/debug/" และ aggregation_coordinator_origin field ของ "เนื้อหาของรายงาน" จะมี URL นี้ https://publickeyservice.msmt.gcp.privacysandboxservices.com
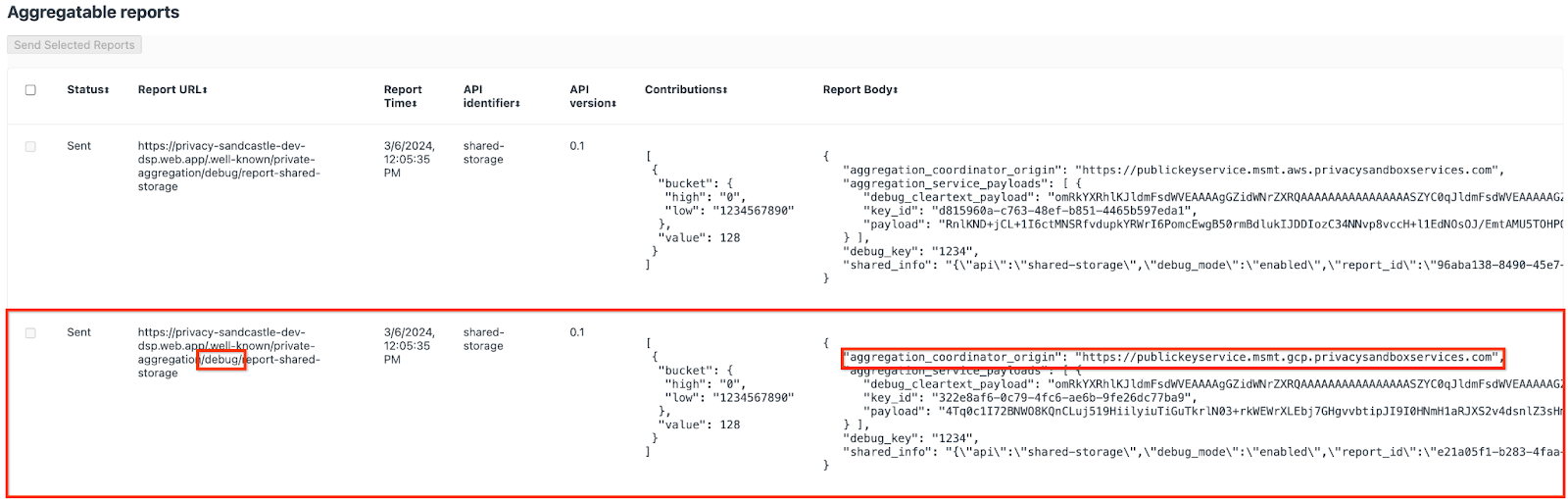 รายงานการแก้ไขข้อบกพร่องของ Google Cloud
รายงานการแก้ไขข้อบกพร่องของ Google Cloud
2.2 สร้างรายงานที่รวบรวมได้สำหรับการแก้ไขข้อบกพร่อง
คัดลอกรายงานที่อยู่ใน "เนื้อหารายงาน" ของ chrome://private-aggregation-internals แล้วสร้างไฟล์ JSON ในโฟลเดอร์ privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar (ภายในที่เก็บที่ดาวน์โหลดในข้อกำหนดเบื้องต้น 1.5)
ในตัวอย่างนี้ เราใช้ vim เนื่องจากเราใช้ Linux แต่คุณจะใช้โปรแกรมแก้ไขข้อความใดก็ได้
vim report.json
วางรายงานลงใน report.json แล้วบันทึกไฟล์
 โค้ด JSON ของรายงาน
โค้ด JSON ของรายงาน
เมื่อมีข้อมูลดังกล่าวแล้ว ให้ใช้ aggregatable_report_converter.jar เพื่อช่วยสร้างรายงานที่รวบรวมได้สำหรับการแก้ไขข้อบกพร่อง ซึ่งจะสร้างรายงานที่รวบรวมได้ชื่อ report.avro ในไดเรกทอรีปัจจุบัน
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3 ดึงข้อมูลคีย์ Bucket จากรายงาน
หากต้องการสร้างไฟล์ output_domain.avro คุณต้องมีคีย์ของ Bucket ที่ดึงข้อมูลจากรายงานได้
คีย์กลุ่มได้รับการออกแบบโดยเทคโนโลยีโฆษณา แต่ในกรณีนี้ เว็บไซต์ Privacy Sandbox Demo จะสร้างคีย์กลุ่ม เนื่องจาก Private Aggregation สำหรับเว็บไซต์นี้อยู่ในโหมดแก้ไขข้อบกพร่อง เราจึงใช้ debug_cleartext_payload จาก "เนื้อหารายงาน" เพื่อรับคีย์กลุ่มได้
คัดลอก debug_cleartext_payload จากเนื้อหารายงาน
 แก้ไขข้อบกพร่องของเพย์โหลดข้อความที่โอนหรือจัดเก็บได้โดยไม่ต้องเข้ารหัส
แก้ไขข้อบกพร่องของเพย์โหลดข้อความที่โอนหรือจัดเก็บได้โดยไม่ต้องเข้ารหัส
เปิด goo.gle/ags-payload-decoder แล้ววาง debug_cleartext_payload ในช่อง "INPUT" แล้วคลิก "Decode"
 ปุ่มถอดรหัส
ปุ่มถอดรหัส
หน้าเว็บจะแสดงผลค่าทศนิยมของคีย์ที่จัดเก็บข้อมูล ต่อไปนี้คือคีย์ของที่เก็บข้อมูลตัวอย่าง
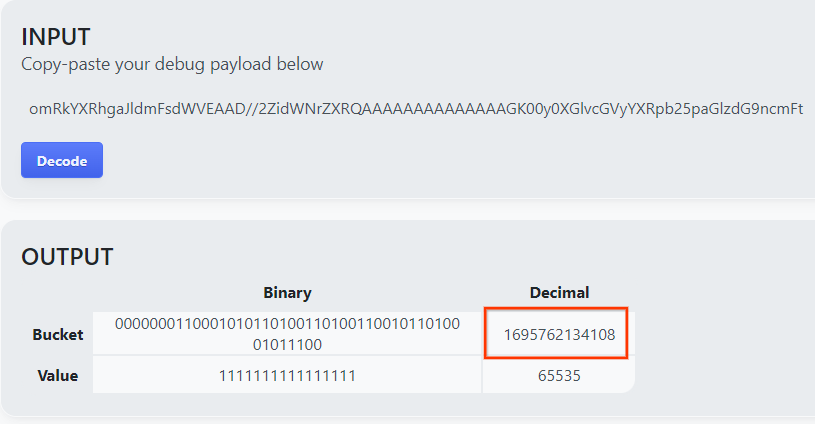 คีย์ของ Bucket ตัวอย่าง
คีย์ของ Bucket ตัวอย่าง
2.4 สร้าง AVRO ของโดเมนเอาต์พุต
ตอนนี้เรามีคีย์ที่เก็บข้อมูลแล้ว มาสร้าง output_domain.avro ในโฟลเดอร์เดียวกันกับที่เราใช้ทำงานกัน ตรวจสอบว่าคุณได้แทนที่คีย์ระดับบัคเก็ตด้วยคีย์ระดับบัคเก็ตที่ดึงมา
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
สคริปต์จะสร้างไฟล์ output_domain.avro ในโฟลเดอร์ปัจจุบัน
2.5 สร้างรายงานสรุปโดยใช้เครื่องมือทดสอบในเครื่อง
เราจะใช้ LocalTestingTool_{version}.jar ที่ดาวน์โหลดในข้อกำหนดเบื้องต้น 1.3 เพื่อสร้างรายงานสรุปโดยใช้คำสั่งต่อไปนี้ แทนที่ {version} ด้วยเวอร์ชันที่คุณดาวน์โหลด อย่าลืมย้าย LocalTestingTool_{version}.jar ไปยังไดเรกทอรีปัจจุบัน หรือเพิ่มเส้นทางแบบสัมพัทธ์เพื่ออ้างอิงตำแหน่งปัจจุบัน
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
คุณควรเห็นข้อความคล้ายกับข้อความต่อไปนี้เมื่อเรียกใช้คำสั่ง ระบบจะสร้างรายงานoutput.avroเมื่อการดำเนินการนี้เสร็จสมบูรณ์
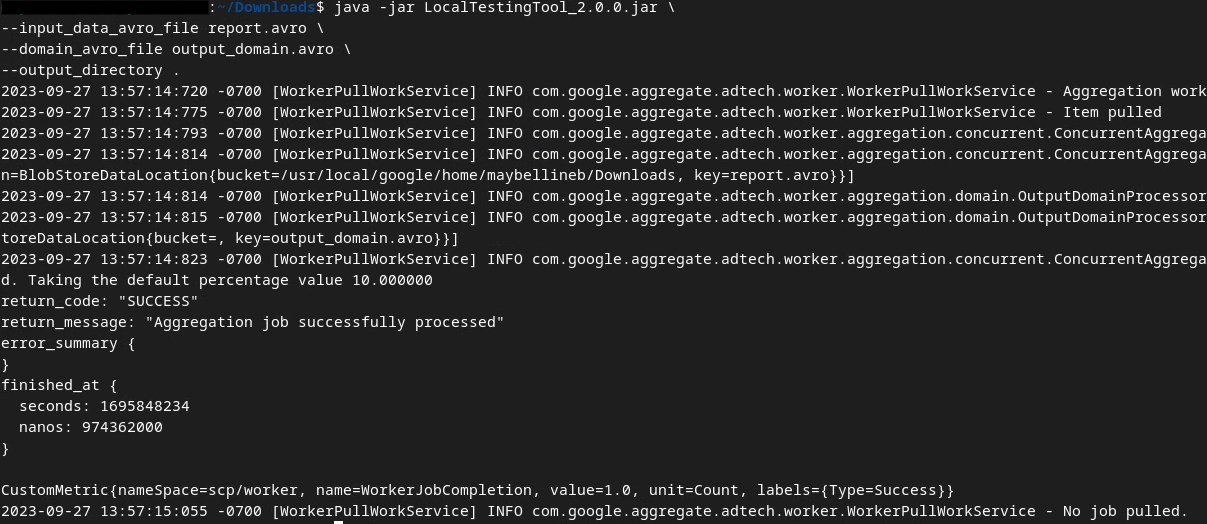 เอาต์พุต AVRO
เอาต์พุต AVRO
2.6 ตรวจสอบรายงานสรุป
รายงานสรุปที่สร้างขึ้นจะอยู่ในรูปแบบ AVRO หากต้องการอ่านข้อมูลนี้ คุณต้องแปลงจาก AVRO เป็นรูปแบบ JSON ในอุดมคติแล้ว เทคโนโลยีโฆษณาควรเขียนโค้ดเพื่อแปลงรายงาน AVRO กลับเป็น JSON
เราจะใช้ aggregatable_report_converter.jar เพื่อแปลงรายงาน AVRO กลับเป็น JSON
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
ซึ่งจะแสดงรายงานที่คล้ายกับรายงานต่อไปนี้ พร้อมกับรายงาน output.json ที่สร้างในไดเรกทอรีเดียวกัน
 เอาต์พุต JSON
เอาต์พุต JSON
Codelab เสร็จสมบูรณ์แล้ว
สรุป: คุณได้รวบรวมรายงานการแก้ไขข้อบกพร่อง สร้างไฟล์โดเมนเอาต์พุต และสร้างรายงานสรุปโดยใช้เครื่องมือทดสอบในเครื่องซึ่งจำลองลักษณะการทำงานของการรวมข้อมูลของบริการรวมข้อมูล
ขั้นตอนถัดไป: ตอนนี้คุณได้ทดสอบเครื่องมือทดสอบในเครื่องแล้ว คุณสามารถลองใช้การทดสอบเดียวกันกับการติดตั้งใช้งานบริการรวมข้อมูลแบบเรียลไทม์ในสภาพแวดล้อมของคุณเอง กลับไปดูข้อกำหนดเบื้องต้นเพื่อให้แน่ใจว่าคุณได้ตั้งค่าทุกอย่างสำหรับโหมด "บริการรวบรวมข้อมูล" แล้ว จากนั้นไปที่ขั้นตอนที่ 3
3. 3. Codelab บริการรวมข้อมูล
เวลาที่ใช้โดยประมาณ: 1 ชั่วโมง
ก่อนที่จะเริ่มต้น ให้ตรวจสอบว่าคุณได้ทำตามข้อกำหนดเบื้องต้นทั้งหมดที่มีป้ายกำกับ "บริการการรวม" แล้ว
ขั้นตอน Codelab
ขั้นตอนที่ 3.1 การสร้างอินพุตของบริการรวมข้อมูล: สร้างรายงานบริการรวมข้อมูลที่จัดกลุ่มสำหรับบริการรวมข้อมูล
- ขั้นตอนที่ 3.1.1 รายงานทริกเกอร์
- ขั้นตอนที่ 3.1.2 รวบรวมรายงานที่รวบรวมได้
- ขั้นตอนที่ 3.1.3 แปลงรายงานเป็น AVRO
- ขั้นตอนที่ 3.1.4 สร้าง AVRO ของ output_domain
- ขั้นตอนที่ 3.1.5 ย้ายรายงานไปยังที่เก็บข้อมูล Cloud Storage
ขั้นตอนที่ 3.2 การใช้งานบริการรวมข้อมูล: ใช้ Aggregation Service API เพื่อสร้างรายงานสรุปและตรวจสอบรายงานสรุป
- ขั้นตอนที่ 3.2.1 การใช้
createJobปลายทางเพื่อประมวลผลเป็นกลุ่ม - ขั้นตอนที่ 3.2.2 การใช้ปลายทาง
getJobเพื่อดึงสถานะกลุ่ม - ขั้นตอนที่ 3.2.3 การตรวจสอบรายงานสรุป
3.1 การสร้างอินพุตของบริการรวมข้อมูล
ดำเนินการสร้างรายงาน AVRO สำหรับการจัดกลุ่มไปยังบริการรวมข้อมูล คุณสามารถเรียกใช้คำสั่งเชลล์ในขั้นตอนเหล่านี้ได้ภายใน Cloud Shell ของ Google Cloud (ตราบใดที่ได้โคลนการอ้างอิงจากข้อกำหนดเบื้องต้นลงในสภาพแวดล้อม Cloud Shell) หรือในสภาพแวดล้อมการดำเนินการในเครื่อง
3.1.1. รายงานทริกเกอร์
ไปที่เว็บไซต์โดยคลิกลิงก์ จากนั้นดูรายงานได้ที่ chrome://private-aggregation-internals
หน้า Chrome Internals
รายงานที่ส่งไปยัง{reporting-origin}/.well-known/private-aggregation/debug/report-shared-storageปลายทางจะอยู่ใน "เนื้อหารายงาน" ของรายงานที่แสดงในหน้า chrome://internals ด้วย
คุณอาจเห็นรายงานจํานวนมากที่นี่ แต่สําหรับโค้ดแล็บนี้ ให้ใช้รายงานแบบรวมที่เฉพาะเจาะจงสําหรับ Google Cloud และสร้างขึ้นโดยปลายทางการแก้ไขข้อบกพร่อง "URL ของรายงาน" จะมี "/debug/" และ aggregation_coordinator_origin field ของ "เนื้อหาของรายงาน" จะมี URL นี้ https://publickeyservice.msmt.gcp.privacysandboxservices.com
รายงานการแก้ไขข้อบกพร่องของ Google Cloud
3.1.2. รวบรวมรายงานที่รวบรวมได้
รวบรวมรายงานที่รวบรวมได้จากปลายทางที่รู้จักกันดีของ API ที่เกี่ยวข้อง
- การรวบรวมข้อมูลแบบส่วนตัว:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - Attribution Reporting - รายงานสรุป:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
สำหรับโค้ดแล็บนี้ เราจะรวบรวมรายงานด้วยตนเอง ในขั้นตอนการผลิต เทคโนโลยีโฆษณาจะต้องรวบรวมและแปลงรายงานแบบเป็นโปรแกรม
มาคัดลอกรายงาน JSON ใน "เนื้อหารายงาน" จาก chrome://private-aggregation-internals กันเลย
ในตัวอย่างนี้ เราใช้ vim เนื่องจากเราใช้ Linux แต่คุณจะใช้โปรแกรมแก้ไขข้อความใดก็ได้
vim report.json
วางรายงานลงใน report.json แล้วบันทึกไฟล์
รายงาน JSON
3.1.3. แปลงรายงานเป็น AVRO
รายงานที่ได้รับจากปลายทาง .well-known จะอยู่ในรูปแบบ JSON และต้องแปลงเป็นรูปแบบรายงาน AVRO เมื่อมีรายงาน JSON แล้ว ให้ไปที่ตำแหน่งที่จัดเก็บ report.json และใช้ aggregatable_report_converter.jar เพื่อช่วยสร้างรายงานที่รวบรวมได้สำหรับการแก้ไขข้อบกพร่อง ซึ่งจะสร้างรายงานที่รวบรวมได้ชื่อ report.avro ในไดเรกทอรีปัจจุบัน
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. สร้าง AVRO ของ output_domain
หากต้องการสร้างไฟล์ output_domain.avro คุณต้องมีคีย์ของ Bucket ที่ดึงข้อมูลจากรายงานได้
คีย์กลุ่มได้รับการออกแบบโดยเทคโนโลยีโฆษณา แต่ในกรณีนี้ เว็บไซต์ Privacy Sandbox Demo จะสร้างคีย์กลุ่ม เนื่องจาก Private Aggregation สำหรับเว็บไซต์นี้อยู่ในโหมดแก้ไขข้อบกพร่อง เราจึงใช้ debug_cleartext_payload จาก "เนื้อหารายงาน" เพื่อรับคีย์กลุ่มได้
คัดลอก debug_cleartext_payload จากเนื้อหารายงาน
แก้ไขข้อบกพร่องของเพย์โหลดข้อความที่โอนหรือจัดเก็บได้โดยไม่ต้องเข้ารหัส
เปิด goo.gle/ags-payload-decoder แล้ววาง debug_cleartext_payload ในช่อง "INPUT" แล้วคลิก "Decode"
ปุ่มถอดรหัส
หน้าเว็บจะแสดงผลค่าทศนิยมของคีย์ที่จัดเก็บข้อมูล ต่อไปนี้คือคีย์ของที่เก็บข้อมูลตัวอย่าง
คีย์ของ Bucket ตัวอย่าง
ตอนนี้เรามีคีย์ที่เก็บข้อมูลแล้ว มาสร้าง output_domain.avro ในโฟลเดอร์เดียวกันกับที่เราใช้ทำงานกัน ตรวจสอบว่าคุณได้แทนที่คีย์ระดับบัคเก็ตด้วยคีย์ระดับบัคเก็ตที่ดึงมา
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
สคริปต์จะสร้างไฟล์ output_domain.avro ในโฟลเดอร์ปัจจุบัน
3.1.5. ย้ายรายงานไปยังที่เก็บข้อมูล Cloud Storage
เมื่อสร้างรายงาน AVRO และโดเมนเอาต์พุตแล้ว ให้ย้ายรายงานและโดเมนเอาต์พุตไปยังที่เก็บข้อมูลใน Cloud Storage (ซึ่งคุณจดไว้ในข้อกำหนดเบื้องต้น 1.6)
หากคุณตั้งค่า gcloud CLI ในสภาพแวดล้อมในเครื่อง ให้ใช้คำสั่งต่อไปนี้เพื่อคัดลอกไฟล์ไปยังโฟลเดอร์ที่เกี่ยวข้อง
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
หรืออัปโหลดไฟล์ไปยังที่เก็บข้อมูลด้วยตนเอง สร้างโฟลเดอร์ชื่อ "reports" แล้วอัปโหลดไฟล์ report.avro ไปยังโฟลเดอร์นั้น สร้างโฟลเดอร์ชื่อ "output_domains" แล้วอัปโหลดไฟล์ output_domain.avro ไปยังโฟลเดอร์นั้น
3.2 การใช้งานบริการรวมข้อมูล
โปรดจำไว้ในข้อกำหนดเบื้องต้น 1.8 ว่าคุณเลือก curl หรือ Postman เพื่อส่งคำขอ API ไปยังปลายทางของบริการรวบรวมข้อมูล วิธีการสำหรับทั้ง 2 ตัวเลือกมีดังนี้
หากงานล้มเหลวเนื่องจากข้อผิดพลาด โปรดดูเอกสารการแก้ปัญหาใน GitHub เพื่อดูข้อมูลเพิ่มเติมเกี่ยวกับวิธีดำเนินการต่อ
3.2.1. การใช้ createJob ปลายทางเพื่อประมวลผลเป็นกลุ่ม
ใช้คำสั่ง curl หรือคำสั่ง Postman อย่างใดอย่างหนึ่งต่อไปนี้เพื่อสร้างงาน
curl
ใน "Terminal" ให้สร้างไฟล์เนื้อหาคำขอ (body.json) แล้ววางออบเจ็กต์ JSON ต่อไปนี้ อย่าลืมอัปเดตค่าตัวยึดตำแหน่ง ดูข้อมูลเพิ่มเติมเกี่ยวกับสิ่งที่แต่ละฟิลด์แสดงได้ในเอกสารประกอบเกี่ยวกับ API นี้
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
ดำเนินการคำขอต่อไปนี้ แทนที่ตัวยึดตำแหน่งใน URL ของคำขอ curl ด้วยค่าจาก frontend_service_cloudfunction_url ซึ่งเป็นเอาต์พุตหลังจากที่การติดตั้งใช้งาน Terraform เสร็จสมบูรณ์ในข้อกำหนดเบื้องต้น 1.6
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
คุณควรได้รับการตอบกลับ HTTP 202 เมื่อบริการรวบรวมข้อมูลยอมรับคำขอ โค้ดตอบกลับอื่นๆ ที่เป็นไปได้ระบุไว้ในข้อกำหนด API
Postman
สำหรับcreateJobปลายทาง ต้องมีเนื้อหาคำขอเพื่อให้ระบุตำแหน่งและชื่อไฟล์ของรายงานที่รวบรวมได้ โดเมนเอาต์พุต และรายงานสรุปแก่บริการรวบรวมข้อมูล
ไปที่แท็บ "เนื้อหา" ของคำขอ createJob
 แท็บเนื้อหา
แท็บเนื้อหา
แทนที่ตัวยึดตำแหน่งภายใน JSON ที่ระบุ ดูข้อมูลเพิ่มเติมเกี่ยวกับฟิลด์เหล่านี้และสิ่งที่ฟิลด์แสดงได้ในเอกสารประกอบเกี่ยวกับ API
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
"ส่ง" คำขอ createJob API
 ปุ่มส่ง
ปุ่มส่ง
คุณดูรหัสการตอบกลับได้ที่ครึ่งล่างของหน้าเว็บ
 โค้ดตอบกลับ
โค้ดตอบกลับ
คุณควรได้รับการตอบกลับ HTTP 202 เมื่อบริการรวบรวมข้อมูลยอมรับคำขอ โค้ดตอบกลับอื่นๆ ที่เป็นไปได้ระบุไว้ในข้อกำหนด API
3.2.2. การใช้ปลายทาง getJob เพื่อดึงสถานะกลุ่ม
ใช้คำสั่ง curl หรือ Postman อย่างใดอย่างหนึ่งต่อไปนี้เพื่อรับงาน
curl
เรียกใช้คำขอต่อไปนี้ในเทอร์มินัล แทนที่ตัวยึดตำแหน่งใน URL ด้วยค่าจาก frontend_service_cloudfunction_url ซึ่งเป็น URL เดียวกับที่คุณใช้สำหรับคำขอ createJob สำหรับ "job_request_id" ให้ใช้ค่าจากงานที่คุณสร้างด้วยปลายทาง createJob
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
ผลลัพธ์ควรแสดงสถานะของคำของานที่มีสถานะ HTTP เป็น 200 "เนื้อหา" ของคำขอมีข้อมูลที่จำเป็น เช่น job_status, return_message และ error_messages (หากงานเกิดข้อผิดพลาด)
Postman
หากต้องการตรวจสอบสถานะของคำของาน คุณสามารถใช้ปลายทาง getJob ได้ ในส่วน "Params" ของคำขอ getJob ให้อัปเดตค่า job_request_id เป็น job_request_id ที่ส่งในคำขอ createJob
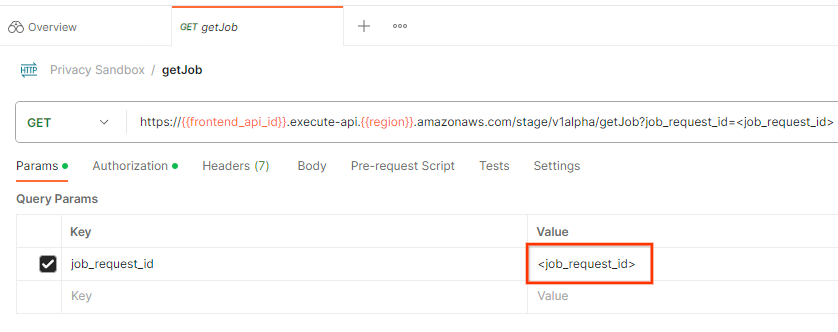 รหัสคำของาน
รหัสคำของาน
"ส่ง" คำขอ getJob
 ปุ่มส่ง
ปุ่มส่ง
ผลลัพธ์ควรแสดงสถานะของคำของานที่มีสถานะ HTTP เป็น 200 "เนื้อหา" ของคำขอมีข้อมูลที่จำเป็น เช่น job_status, return_message และ error_messages (หากงานเกิดข้อผิดพลาด)
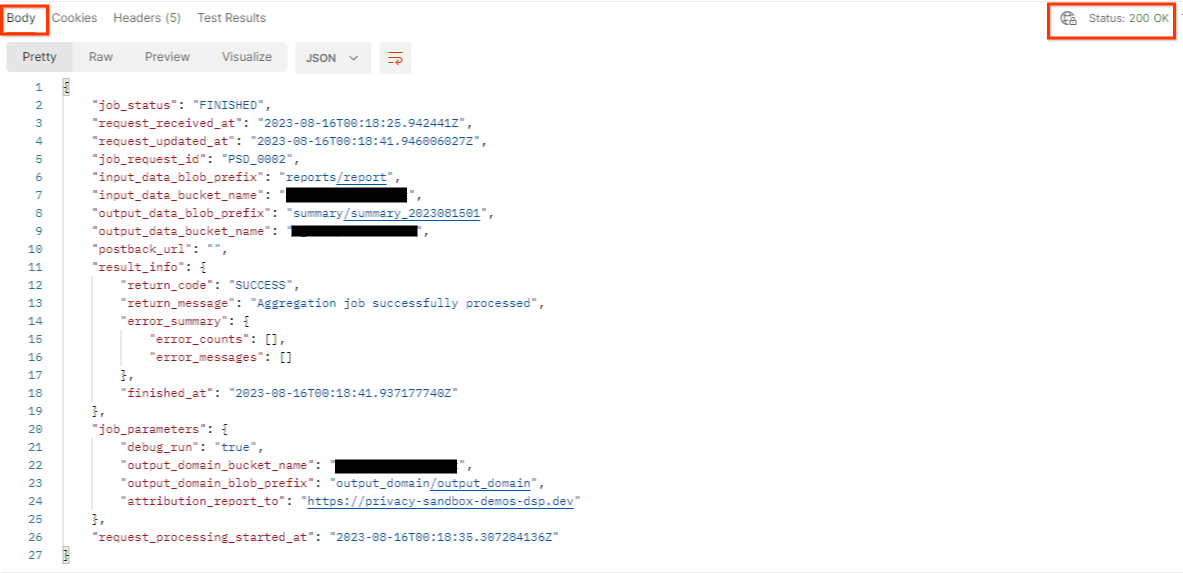 JSON ของการตอบกลับ
JSON ของการตอบกลับ
3.2.3. การตรวจสอบรายงานสรุป
เมื่อได้รับรายงานสรุปใน Bucket ของ Cloud Storage เอาต์พุตแล้ว คุณจะดาวน์โหลดรายงานนี้ไปยังสภาพแวดล้อมในเครื่องได้ รายงานสรุปอยู่ในรูปแบบ AVRO และสามารถแปลงกลับเป็น JSON ได้ คุณใช้ aggregatable_report_converter.jar เพื่ออ่านรายงานโดยใช้คำสั่งนี้ได้
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
ซึ่งจะแสดงผล JSON ของค่ารวมของคีย์ Bucket แต่ละรายการที่มีลักษณะคล้ายกับตัวอย่างต่อไปนี้
 รายงานสรุป
รายงานสรุป
หากcreateJobคำขอของคุณมี debug_run เป็นจริง คุณจะได้รับรายงานสรุปในโฟลเดอร์การแก้ไขข้อบกพร่องซึ่งอยู่ใน output_data_blob_prefix รายงานอยู่ในรูปแบบ AVRO และสามารถแปลงเป็น JSON ได้โดยใช้คำสั่งก่อนหน้า
รายงานประกอบด้วยคีย์ที่จัดกลุ่ม เมตริกที่ไม่มีการเพิ่มสัญญาณรบกวน และสัญญาณรบกวนที่เพิ่มลงในเมตริกที่ไม่มีการเพิ่มสัญญาณรบกวนเพื่อสร้างรายงานสรุป รายงานจะคล้ายกับรายงานต่อไปนี้
 รายงานที่มีสัญญาณรบกวน
รายงานที่มีสัญญาณรบกวน
คำอธิบายประกอบยังมี "in_reports" หรือ "in_domain" (หรือทั้ง 2 อย่าง) ซึ่งหมายความว่า
- in_reports - คีย์กลุ่มข้อมูลจะอยู่ในรายงานที่รวบรวมได้
- in_domain - คีย์ของ Bucket จะอยู่ในไฟล์ AVRO ของ output_domain
Codelab เสร็จสมบูรณ์แล้ว
สรุป: คุณได้ติดตั้งใช้งานบริการรวมข้อมูลในสภาพแวดล้อมระบบคลาวด์ของคุณเอง รวบรวมรายงานการแก้ไขข้อบกพร่อง สร้างไฟล์โดเมนเอาต์พุต จัดเก็บไฟล์เหล่านี้ใน Bucket ของ Cloud Storage และเรียกใช้งานที่สำเร็จแล้ว
ขั้นตอนถัดไป: ใช้บริการรวบรวมข้อมูลต่อไปในสภาพแวดล้อมของคุณ หรือลบทรัพยากรระบบคลาวด์ที่คุณเพิ่งสร้างตามวิธีการล้างข้อมูลในขั้นตอนที่ 4
4. 4. การจัดระเบียบ
หากต้องการลบทรัพยากรที่สร้างขึ้นสำหรับบริการรวบรวมข้อมูลโดยใช้ Terraform ให้ใช้คำสั่ง destroy ในโฟลเดอร์ adtech_setup และ dev (หรือสภาพแวดล้อมอื่นๆ)
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
วิธีลบที่เก็บข้อมูล Cloud Storage ที่มีรายงานที่รวบรวมได้และรายงานสรุป
$ gcloud storage buckets delete gs://my-bucket
นอกจากนี้ คุณยังเลือกเปลี่ยนการตั้งค่าคุกกี้ของ Chrome จากข้อกำหนดเบื้องต้น 1.2 กลับไปเป็นสถานะก่อนหน้าได้ด้วย
5. 5. ภาคผนวก
ไฟล์ตัวอย่าง adtech_setup.auto.tfvars
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
ไฟล์ตัวอย่าง dev.auto.tfvars
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20