
1. ज़रूरी शर्तें
इस कोडलैब को पूरा करने के लिए, कुछ ज़रूरी शर्तें पूरी करनी होंगी. हर ज़रूरी शर्त को इस हिसाब से मार्क किया जाता है कि वह "लोकल टेस्टिंग" या "एग्रीगेशन सेवा" के लिए ज़रूरी है या नहीं.
1.1. लोकल टेस्टिंग टूल (लोकल टेस्टिंग) डाउनलोड करें
लोकल टेस्टिंग के लिए, लोकल टेस्टिंग टूल डाउनलोड करना होगा. यह टूल, डिक्रिप्ट नहीं की गई डीबग रिपोर्ट से खास जानकारी वाली रिपोर्ट जनरेट करेगा.
लोकल टेस्टिंग टूल को GitHub में Lambda JAR आर्काइव से डाउनलोड किया जा सकता है. इसका नाम LocalTestingTool_{version}.jar होना चाहिए.
1.2. पुष्टि करें कि JAVA JRE इंस्टॉल है (लोकल टेस्टिंग और एग्रीगेशन सेवा)
"टर्मिनल" खोलें और java --version का इस्तेमाल करके देखें कि आपकी मशीन पर Java या openJDK इंस्टॉल है या नहीं.
 `java --version` का इस्तेमाल करके, Java JRE का वर्शन देखना.
`java --version` का इस्तेमाल करके, Java JRE का वर्शन देखना.
अगर यह इंस्टॉल नहीं है, तो इसे Java की साइट या openJDK की साइट से डाउनलोड और इंस्टॉल किया जा सकता है.
1.3. एग्रीगेट की जा सकने वाली रिपोर्ट कन्वर्टर (लोकल टेस्टिंग और एग्रीगेशन सेवा) डाउनलोड करें
Privacy Sandbox Demos की Github रिपॉज़िटरी से, एग्रीगेट की जा सकने वाली रिपोर्ट कन्वर्टर की कॉपी डाउनलोड की जा सकती है.
1.4. विज्ञापन देखने वाले की निजता बनाए रखने से जुड़े एपीआई (लोकल टेस्टिंग और एग्रीगेशन सेवा) चालू करना
अपने ब्राउज़र पर, chrome://settings/adPrivacy पर जाएं और विज्ञापन की निजता से जुड़े सभी एपीआई चालू करें.
पुष्टि करें कि तीसरे पक्ष की कुकी चालू हैं.
अपने ब्राउज़र पर, chrome://settings/cookies पर जाएं. इसके बाद, "गुप्त मोड में, तीसरे पक्ष की कुकी ब्लॉक करें" को चुनें.
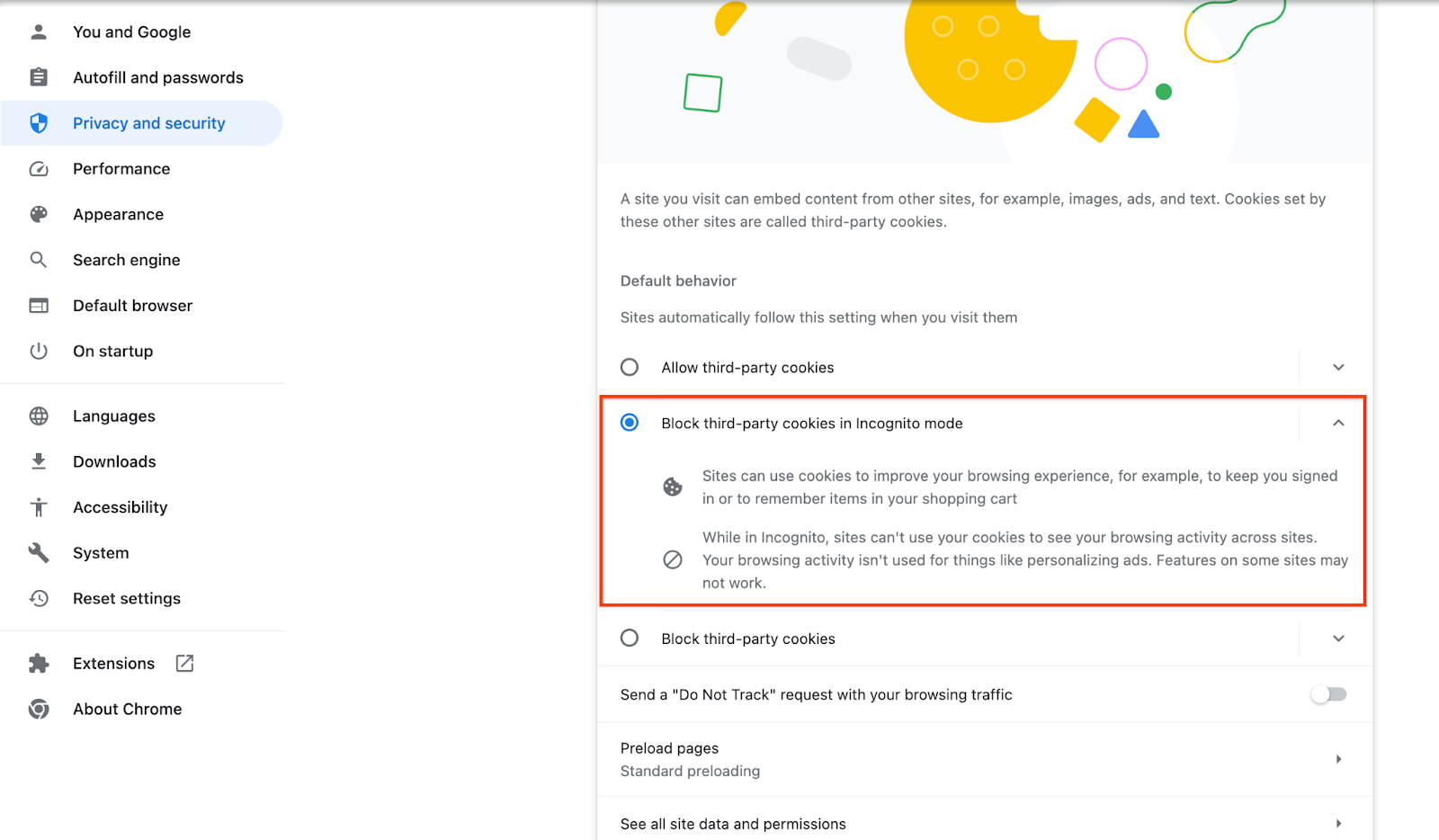 Chrome में तीसरे पक्ष की कुकी की सेटिंग.
Chrome में तीसरे पक्ष की कुकी की सेटिंग.
1.5. वेब और Android पर ऑप्ट-इन करना (एग्रीगेशन सेवा)
प्रोडक्शन एनवायरमेंट में Privacy Sandbox API का इस्तेमाल करने के लिए, पक्का करें कि आपने Chrome और Android, दोनों के लिए रजिस्ट्रेशन और पुष्टि कर ली हो.
लोकल टेस्टिंग के लिए, Chrome फ़्लैग और सीएलआई स्विच का इस्तेमाल करके, रजिस्ट्रेशन की सुविधा बंद की जा सकती है.
हमारे डेमो के लिए Chrome फ़्लैग का इस्तेमाल करने के लिए, chrome://flags/#privacy-sandbox-enrollment-overrides पर जाएं और अपनी साइट के साथ ओवरराइड को अपडेट करें. अगर हमारी डेमो साइट का इस्तेमाल किया जा रहा है, तो अपडेट करने की ज़रूरत नहीं है.
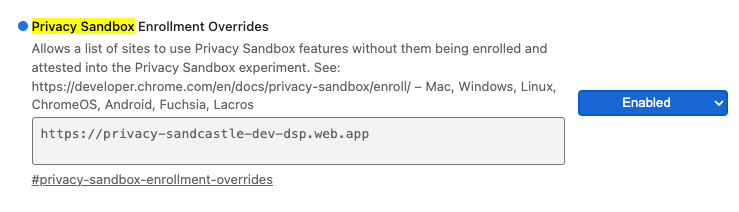 Privacy Sandbox में ऑप्ट-इन करने की सुविधा को बंद करने वाला Chrome फ़्लैग.
Privacy Sandbox में ऑप्ट-इन करने की सुविधा को बंद करने वाला Chrome फ़्लैग.
1.6. एग्रीगेशन सेवा में शामिल होना (एग्रीगेशन सेवा)
एग्रीगेशन सेवा का इस्तेमाल करने के लिए, कोऑर्डिनेटर को ऑनबोर्ड करना ज़रूरी है. एग्रीगेशन सेवा में शामिल होने का फ़ॉर्म भरें. इसमें अपनी रिपोर्टिंग साइट का पता, AWS खाता आईडी, और अन्य जानकारी दें.
1.7. क्लाउड की सेवा देने वाली कंपनी (एग्रीगेशन सेवा)
एग्रीगेशन की सेवा के लिए, ट्रस्टेड एक्ज़ीक्यूशन एनवायरमेंट का इस्तेमाल करना ज़रूरी है. यह क्लाउड एनवायरमेंट का इस्तेमाल करता है. Amazon Web Services (AWS) और Google Cloud (GCP) पर एग्रीगेशन सेवा काम करती है. इस कोडलैब में, सिर्फ़ AWS इंटिग्रेशन के बारे में बताया जाएगा.
AWS, Nitro Enclaves नाम का ट्रस्टेड एक्ज़ीक्यूशन एनवायरमेंट उपलब्ध कराता है. पुष्टि करें कि आपके पास AWS खाता है. साथ ही, AWS CLI एनवायरमेंट सेट अप करने के लिए, AWS CLI को इंस्टॉल करने और अपडेट करने से जुड़े निर्देशों का पालन करें.
अगर आपका AWS CLI नया है, तो सीएलआई कॉन्फ़िगरेशन के निर्देशों का इस्तेमाल करके, AWS CLI को कॉन्फ़िगर किया जा सकता है.
1.7.1. AWS S3 बकेट बनाना
Terraform की स्थिति को सेव करने के लिए, AWS S3 बकेट बनाएं. साथ ही, अपनी रिपोर्ट और खास जानकारी वाली रिपोर्ट सेव करने के लिए, एक और S3 बकेट बनाएं. इसके लिए, दी गई सीएलआई कमांड का इस्तेमाल करें. <> में मौजूद फ़ील्ड को सही वैरिएबल से बदलें.
aws s3api create-bucket --bucket <tf_bucket_name> --region us-east-1
aws s3api create-bucket --bucket <report_bucket_name> --region us-east-1
1.7.2. उपयोगकर्ता के लिए ऐक्सेस कुंजी बनाना
AWS गाइड का इस्तेमाल करके, उपयोगकर्ता के ऐक्सेस की कुंजियां बनाएं. इसका इस्तेमाल, AWS पर बनाए गए createJob और getJob एपीआई एंडपॉइंट को कॉल करने के लिए किया जाएगा.
1.7.3. AWS उपयोगकर्ता और ग्रुप की अनुमतियां
AWS पर Aggregation Service को डिप्लॉय करने के लिए, आपको उस उपयोगकर्ता को कुछ अनुमतियां देनी होंगी जिसका इस्तेमाल सेवा को डिप्लॉय करने के लिए किया जाता है. इस कोडलैब के लिए, पुष्टि करें कि उपयोगकर्ता के पास एडमिन का ऐक्सेस हो, ताकि यह पक्का किया जा सके कि डिप्लॉयमेंट के लिए उसके पास सभी अनुमतियां हैं.
1.8. Terraform (एग्रीगेशन सेवा)
इस कोडलैब में, एग्रीगेशन सेवा को डिप्लॉय करने के लिए Terraform का इस्तेमाल किया जाता है. पुष्टि करें कि Terraform बाइनरी आपके लोकल एनवायरमेंट में इंस्टॉल हो.
अपने लोकल एनवायरमेंट में Terraform बाइनरी डाउनलोड करें.
Terraform बाइनरी डाउनलोड हो जाने के बाद, फ़ाइल को एक्सट्रैक्ट करें और Terraform बाइनरी को /usr/local/bin में ले जाएं.
cp <directory>/terraform /usr/local/bin
देखें कि क्लासपाथ पर Terraform उपलब्ध है या नहीं.
terraform -v
1.9. Postman (For Aggregation Service AWS)
इस कोडलैब के लिए, अनुरोधों को मैनेज करने के लिए Postman का इस्तेमाल करें.
फ़ाइल फ़ोल्डर बनाने के लिए, सबसे ऊपर मौजूद नेविगेशन आइटम "फ़ाइल फ़ोल्डर" पर जाएं. इसके बाद, "फ़ाइल फ़ोल्डर बनाएं" को चुनें.
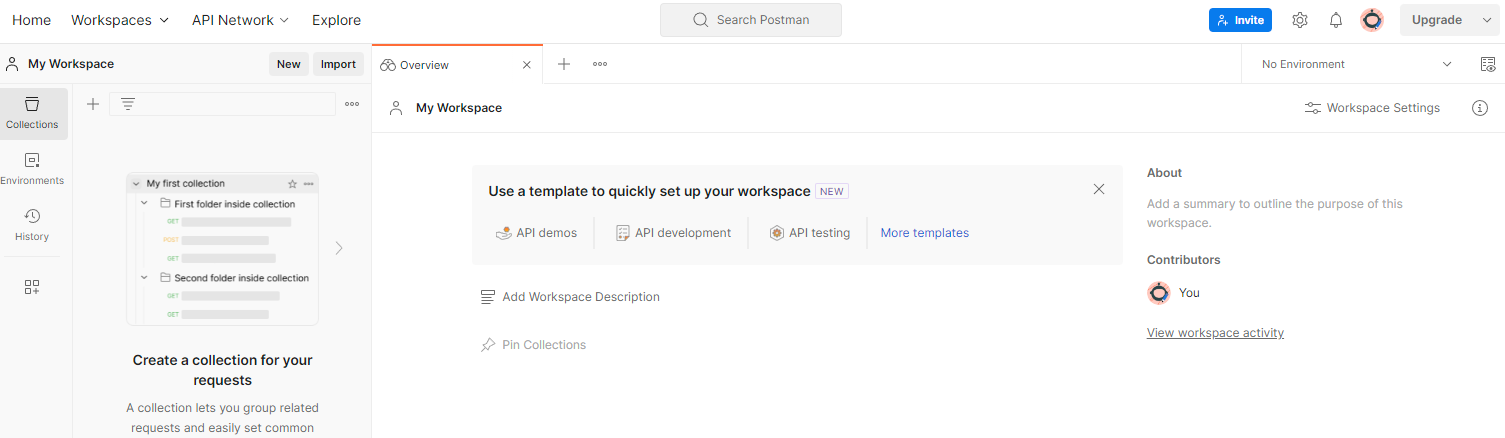 Postman workspace
Postman workspace
"खाली फ़ाइल फ़ोल्डर" चुनें. इसके बाद, आगे बढ़ें पर क्लिक करें और इसे "Privacy Sandbox" नाम दें. "निजी" को चुनें और "बनाएं" पर क्लिक करें.
पहले से कॉन्फ़िगर किए गए वर्कस्पेस की JSON कॉन्फ़िगरेशन और ग्लोबल एनवायरमेंट फ़ाइलें डाउनलोड करें.
"इंपोर्ट करें" बटन का इस्तेमाल करके, JSON फ़ाइलों को "मेरा वर्कस्पेस" में इंपोर्ट करें.
 Postman की JSON फ़ाइलें इंपोर्ट करें.
Postman की JSON फ़ाइलें इंपोर्ट करें.
इससे आपके लिए Privacy Sandbox कलेक्शन के साथ-साथ createJob और getJob एचटीटीपी अनुरोध भी बन जाएंगे.
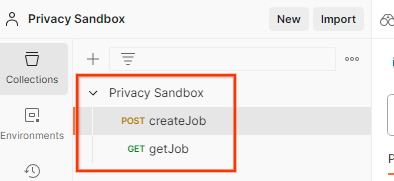 Postman से कलेक्शन इंपोर्ट किया गया.
Postman से कलेक्शन इंपोर्ट किया गया.
"एनवायरमेंट की खास जानकारी" का इस्तेमाल करके, AWS की "ऐक्सेस कुंजी" और "सीक्रेट कुंजी" अपडेट करें.
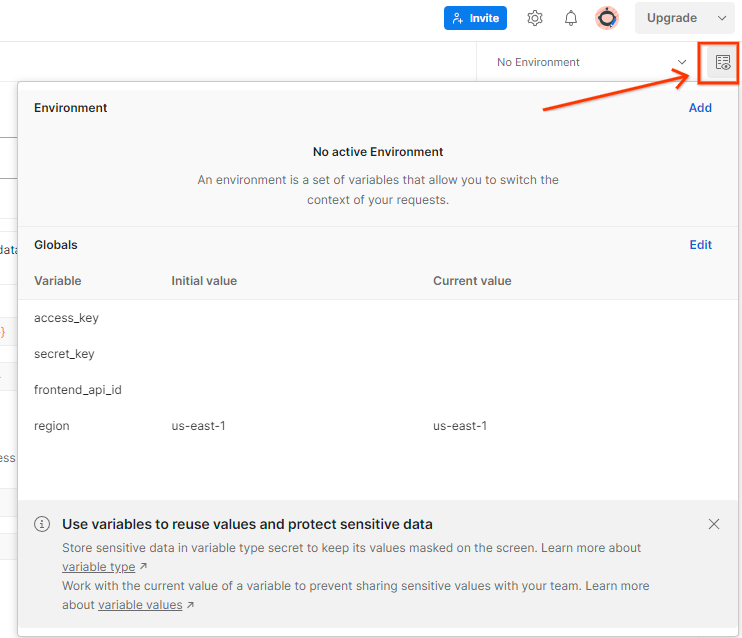 Postman एनवायरमेंट की खास जानकारी.
Postman एनवायरमेंट की खास जानकारी.
"बदलाव करें" पर क्लिक करें. इसके बाद, "access_key" और "secret_key" की "मौजूदा वैल्यू" को अपडेट करें. ध्यान दें कि frontend_api_id की जानकारी, इस दस्तावेज़ के सेक्शन 3.1.4 में दी जाएगी. हमारा सुझाव है कि आप us-east-1 क्षेत्र का इस्तेमाल करें. हालांकि, अगर आपको किसी दूसरे क्षेत्र में डिप्लॉय करना है, तो पुष्टि करें कि आपने रिलीज़ की गई एएमआई को अपने खाते में कॉपी कर लिया है. इसके अलावा, दी गई स्क्रिप्ट का इस्तेमाल करके, खुद से भी एएमआई बनाई जा सकती है.
 Postman के ग्लोबल वैरिएबल.
Postman के ग्लोबल वैरिएबल.  Postman में ग्लोबल वैरिएबल में बदलाव करें.
Postman में ग्लोबल वैरिएबल में बदलाव करें.
2. लोकल टेस्टिंग कोडलैब
अपनी मशीन पर लोकल टेस्टिंग टूल का इस्तेमाल करके, एग्रीगेशन किया जा सकता है. साथ ही, बिना एन्क्रिप्ट (सुरक्षित) की गई डीबग रिपोर्ट का इस्तेमाल करके खास जानकारी वाली रिपोर्ट जनरेट की जा सकती हैं.
कोडलैब के चरण
चरण 2.1. ट्रिगर रिपोर्ट: रिपोर्ट इकट्ठा करने के लिए, Private Aggregation रिपोर्टिंग को ट्रिगर करें.
चरण 2.2. डबग करने लायक एग्रीगेट की जा सकने वाली रिपोर्ट बनाएं: इकट्ठा की गई JSON रिपोर्ट को AVRO फ़ॉर्मैट वाली रिपोर्ट में बदलें.
यह चरण, उस चरण के जैसा होगा जब विज्ञापन टेक्नोलॉजी कंपनियां, एपीआई रिपोर्टिंग एंडपॉइंट से रिपोर्ट इकट्ठा करती हैं और JSON रिपोर्ट को AVRO फ़ॉर्मैट वाली रिपोर्ट में बदलती हैं.
दूसरा चरण.3. डीबग रिपोर्ट से बकेट की को पार्स करें: बकेट की, विज्ञापन टेक्नोलॉजी कंपनियां डिज़ाइन करती हैं. इस कोडलैब में, बकेट पहले से तय हैं. इसलिए, बकेट की कुंजियां उसी तरह से पाएं जिस तरह से दी गई हैं.
चरण 2.4. आउटपुट डोमेन AVRO बनाएं: बकेट की कुंजियां वापस पाने के बाद, आउटपुट डोमेन AVRO फ़ाइल बनाएं.
दूसरा चरण.5. Local Testing Tool का इस्तेमाल करके खास जानकारी वाली रिपोर्ट बनाना: लोकल एनवायरमेंट में खास जानकारी वाली रिपोर्ट बनाने के लिए, Local Testing Tool का इस्तेमाल करें.
चरण 2.6. खास जानकारी वाली रिपोर्ट की समीक्षा करें: Local Testing Tool से बनाई गई खास जानकारी वाली रिपोर्ट की समीक्षा करें.
2.1. ट्रिगर रिपोर्ट
Privacy Sandbox के डेमो की साइट पर जाएं. इससे निजता बनाए रखने वाली एग्रीगेशन रिपोर्ट ट्रिगर होती है. रिपोर्ट को chrome://private-aggregation-internals पर देखा जा सकता है.
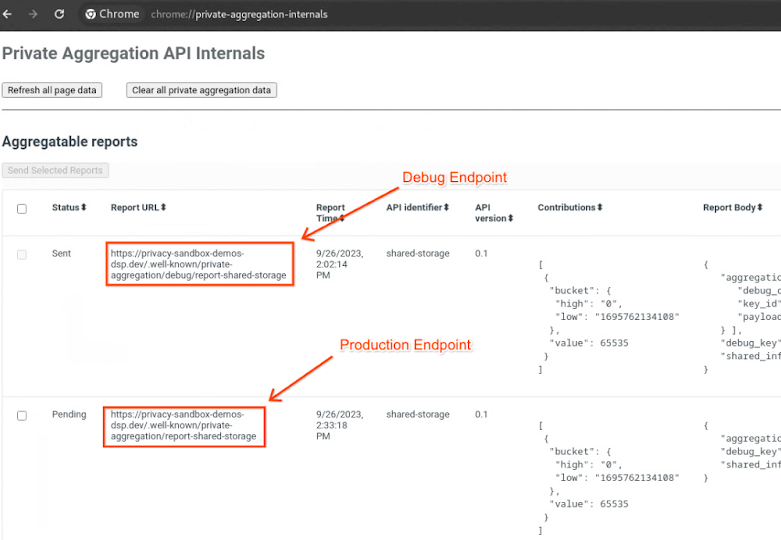 Chrome में निजता बनाए रखते हुए डेटा इकट्ठा करने की सुविधा के बारे में जानकारी.
Chrome में निजता बनाए रखते हुए डेटा इकट्ठा करने की सुविधा के बारे में जानकारी.
अगर आपकी रिपोर्ट "लंबित है" स्थिति में है, तो रिपोर्ट को चुनें और "चुनी गई रिपोर्ट भेजें" पर क्लिक करें.
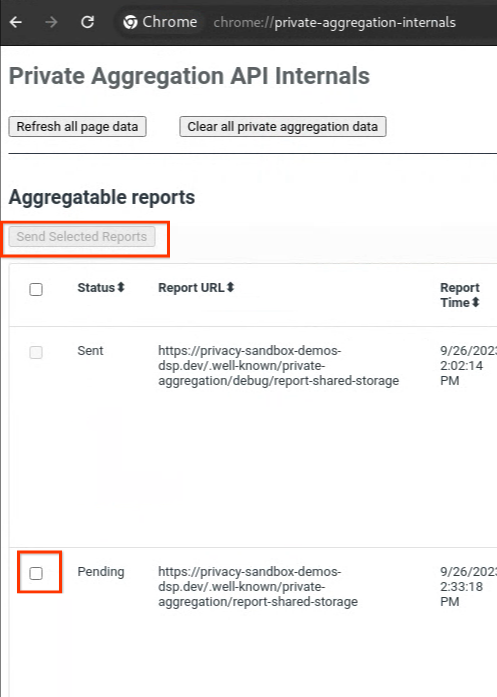 निजी एग्रीगेशन रिपोर्ट भेजें.
निजी एग्रीगेशन रिपोर्ट भेजें.
2.2. डबग करने लायक एग्रीगेट की गई रिपोर्ट बनाना
chrome://private-aggregation-internals में, [reporting-origin]/.well-known/private-aggregation/report-shared-storage एंडपॉइंट से मिला "Report Body" कॉपी करें.
पक्का करें कि "रिपोर्ट बॉडी" में, aggregation_coordinator_origin में https://publickeyservice.msmt.aws.privacysandboxservices.com शामिल हो. इसका मतलब है कि रिपोर्ट, AWS की एग्रीगेट की जा सकने वाली रिपोर्ट है.
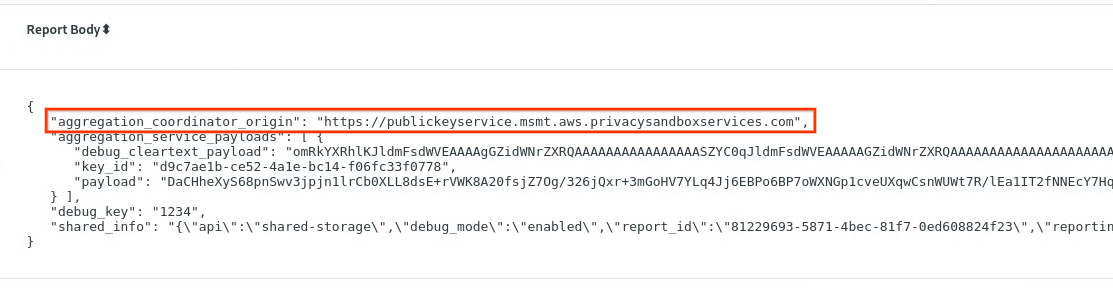 Private Aggregation रिपोर्ट.
Private Aggregation रिपोर्ट.
JSON फ़ाइल में JSON "Report Body" को रखें. इस उदाहरण में, vim का इस्तेमाल किया जा सकता है. हालांकि, अपनी पसंद के किसी भी टेक्स्ट एडिटर का इस्तेमाल किया जा सकता है.
vim report.json
रिपोर्ट को report.json में चिपकाएं और अपनी फ़ाइल सेव करें.
 रिपोर्ट की JSON फ़ाइल.
रिपोर्ट की JSON फ़ाइल.
इसके बाद, अपनी रिपोर्ट फ़ोल्डर पर जाएं और aggregatable_report_converter.jar का इस्तेमाल करके, डीबग करने लायक एग्रीगेट की गई रिपोर्ट बनाएं. इससे आपकी मौजूदा डायरेक्ट्री में, एग्रीगेट की जा सकने वाली एक रिपोर्ट बन जाती है. इसे report.avro कहा जाता है.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. डीबग रिपोर्ट से बकेट कुंजी पार्स करना
बैचिंग के दौरान, एग्रीगेशन सेवा को दो फ़ाइलों की ज़रूरत होती है. एग्रीगेट की जा सकने वाली रिपोर्ट और आउटपुट डोमेन फ़ाइल. आउटपुट डोमेन फ़ाइल में वे कुंजियां होती हैं जिन्हें आपको एग्रीगेट की जा सकने वाली रिपोर्ट से वापस पाना है. output_domain.avro फ़ाइल बनाने के लिए, आपको बकेट कुंजियों की ज़रूरत होती है. इन्हें रिपोर्ट से वापस पाया जा सकता है.
बकेट की, एपीआई को कॉल करने वाला व्यक्ति बनाता है. डेमो में, पहले से बनाई गई बकेट की के उदाहरण दिए गए हैं. डेमो में, Private Aggregation के लिए डीबग मोड चालू किया गया है. इसलिए, बकेट की वापस पाने के लिए, "Report Body" से डीबग क्लियरटेक्स्ट पेलोड को पार्स किया जा सकता है.. हालांकि, इस मामले में Privacy Sandbox Demo साइट, बकेट कुंजियां बनाती है. इस साइट के लिए, Private Aggregation API डीबग मोड में है. इसलिए, बकेट की पाने के लिए "Report Body" से debug_cleartext_payload का इस्तेमाल किया जा सकता है.
रिपोर्ट के मुख्य हिस्से से debug_cleartext_payload कॉपी करें.
 रिपोर्ट के मुख्य हिस्से से क्लियरटेक्स्ट पेलोड डीबग करें.
रिपोर्ट के मुख्य हिस्से से क्लियरटेक्स्ट पेलोड डीबग करें.
निजी एग्रीगेशन के लिए डीबग पेलोड डिकोडर टूल खोलें. इसके बाद, "INPUT" बॉक्स में अपना debug_cleartext_payload चिपकाएं और "Decode" पर क्लिक करें.
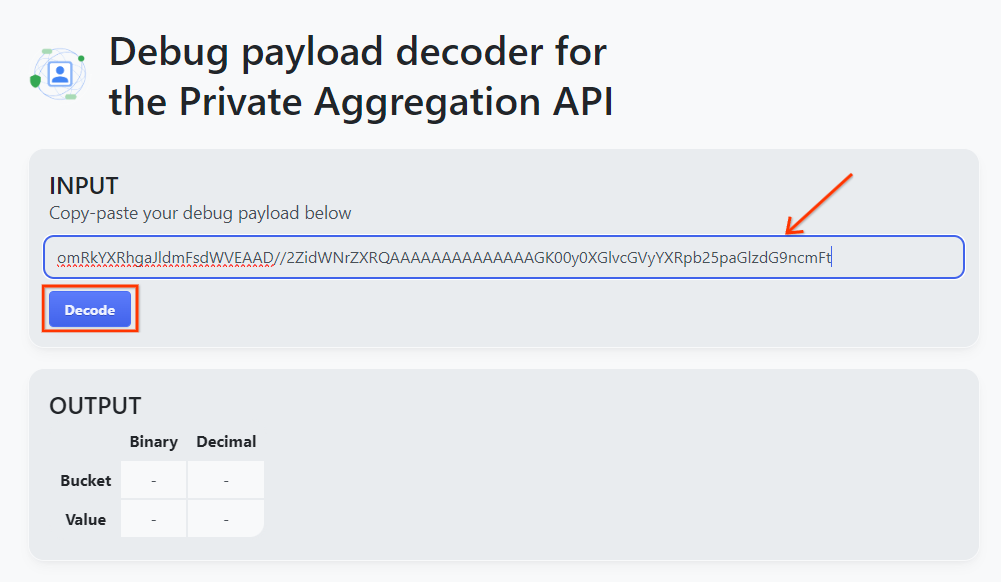 पेलोड डिकोडर.
पेलोड डिकोडर.
यह पेज, बकेट कुंजी की दशमलव वैल्यू दिखाता है. यहां बकेट की का एक सैंपल दिया गया है.
 Payload decoder result.
Payload decoder result.
2.4. आउटपुट डोमेन AVRO बनाएं
अब हमारे पास बकेट की कुंजी है. इसलिए, बकेट की कुंजी की दशमलव वैल्यू को कॉपी करें. बकेट कुंजी का इस्तेमाल करके, output_domain.avro बनाएं. पुष्टि करें कि आपने
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
यह स्क्रिप्ट, आपके मौजूदा फ़ोल्डर में output_domain.avro फ़ाइल बनाती है.
2.5. लोकल टेस्टिंग टूल का इस्तेमाल करके खास जानकारी वाली रिपोर्ट बनाना
हम समरी रिपोर्ट बनाने के लिए, सेक्शन 1.1 में डाउनलोड किए गए LocalTestingTool_{version}.jar का इस्तेमाल करेंगे. इस कमांड का इस्तेमाल करें. आपको LocalTestingTool_{version}.jar को LocalTestingTool के लिए डाउनलोड किए गए वर्शन से बदलना चाहिए.
अपने लोकल डेवलपमेंट एनवायरमेंट में खास जानकारी वाली रिपोर्ट जनरेट करने के लिए, यह निर्देश चलाएं:
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
कमांड चलाने के बाद, आपको इस इमेज जैसा कुछ दिखेगा. यह प्रोसेस पूरी होने के बाद, एक रिपोर्ट output.avro जनरेट हो जाती है.
 स्थानीय जांच की खास जानकारी वाली रिपोर्ट की avro फ़ाइल.
स्थानीय जांच की खास जानकारी वाली रिपोर्ट की avro फ़ाइल.
2.6. खास जानकारी वाली रिपोर्ट की समीक्षा करना
खास जानकारी वाली रिपोर्ट, AVRO फ़ॉर्मैट में बनाई जाती है. इसे पढ़ने के लिए, आपको इसे AVRO से JSON फ़ॉर्मैट में बदलना होगा. आदर्श रूप से, विज्ञापन टेक्नोलॉजी को AVRO रिपोर्ट को वापस JSON में बदलने के लिए कोड करना चाहिए.
इस कोडलैब के लिए, हम दिए गए aggregatable_report_converter.jar टूल का इस्तेमाल करके, AVRO रिपोर्ट को वापस JSON में बदलेंगे.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
इससे आपको इस इमेज जैसी रिपोर्ट मिलेगी. साथ ही, उसी डायरेक्ट्री में बनाई गई रिपोर्ट output.json भी शामिल है.
 Avro फ़ाइल की खास जानकारी को json फ़ाइल में बदल दिया गया है.
Avro फ़ाइल की खास जानकारी को json फ़ाइल में बदल दिया गया है.
खास जानकारी वाली रिपोर्ट की समीक्षा करने के लिए, JSON फ़ाइल को अपनी पसंद के एडिटर में खोलें.
3. एग्रीगेशन सेवा को डिप्लॉय करना
एग्रीगेशन सेवा को डिप्लॉय करने के लिए, यह तरीका अपनाएं:
तीसरा चरण. एग्रीगेशन सेवा को डिप्लॉय करना: AWS पर एग्रीगेशन सेवा को डिप्लॉय करना
तीसरा चरण.1. एग्रीगेशन सेवा की रिपॉज़िटरी को क्लोन करना
चरण 3.2. पहले से बनी डिपेंडेंसी डाउनलोड करना
तीसरा चरण.3. डेवलपमेंट एनवायरमेंट बनाना
तीसरा चरण.4. एग्रीगेशन सेवा को डिप्लॉय करना
3.1. एग्रीगेशन सेवा की रिपॉज़िटरी क्लोन करना
अपने लोकल एनवायरमेंट में, Aggregation Service की GitHub रिपॉज़िटरी को क्लोन करें.
git clone https://github.com/privacysandbox/aggregation-service.git
3.2. पहले से बनी डिपेंडेंसी डाउनलोड करना
Aggregation Service की रिपॉज़िटरी को क्लोन करने के बाद, रिपॉज़िटरी के Terraform फ़ोल्डर और उससे जुड़े क्लाउड फ़ोल्डर पर जाएं. अगर आपका cloud_provider AWS है, तो
cd <repository_root>/terraform/aws
download_prebuilt_dependencies.sh को लागू करें.
bash download_prebuilt_dependencies.sh
3.3. डेवलपमेंट एनवायरमेंट बनाना
dev नाम का फ़ोल्डर बनाओ.
mkdir dev
demo फ़ोल्डर के कॉन्टेंट को dev फ़ोल्डर में कॉपी करें.
cp -R demo/* dev
उसे अपने dev फ़ोल्डर में ले जाएं.
cd dev
अपनी main.tf फ़ाइल अपडेट करें. इसके बाद, फ़ाइल में बदलाव करने के लिए input के लिए i दबाएं.
vim main.tf
# हटाकर, लाल बॉक्स में मौजूद कोड से टिप्पणी हटाएं. साथ ही, बकेट और कुंजी के नाम अपडेट करें.
AWS main.tf के लिए:
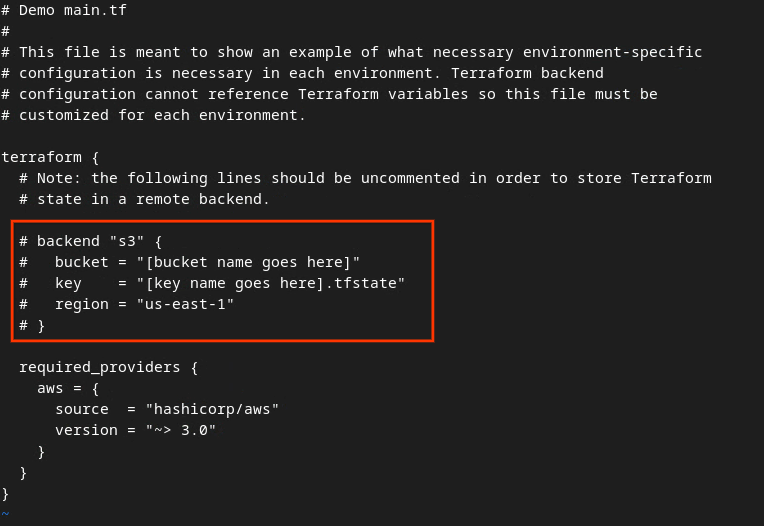 AWS की मुख्य tf फ़ाइल.
AWS की मुख्य tf फ़ाइल.
अनकमेंट किया गया कोड ऐसा दिखना चाहिए.
backend "s3" {
bucket = "<tf_state_bucket_name>"
key = "<environment_name>.tfstate"
region = "us-east-1"
}
अपडेट पूरा होने के बाद, अपडेट सेव करें और esc -> :wq! दबाकर एडिटर से बाहर निकलें. इससे main.tf पर अपडेट सेव हो जाते हैं.
इसके बाद, example.auto.tfvars का नाम बदलकर dev.auto.tfvars करें.
mv example.auto.tfvars dev.auto.tfvars
फ़ाइल में बदलाव करने के लिए, dev.auto.tfvars को अपडेट करें और input के लिए i दबाएं.
vim dev.auto.tfvars
नीचे दी गई इमेज में, लाल बॉक्स में दिए गए फ़ील्ड को अपडेट करें. इसके लिए, एग्रीगेशन सेवा में शामिल होने के दौरान दिए गए सही AWS ARN पैरामीटर, एनवायरमेंट, और सूचना वाले ईमेल का इस्तेमाल करें.
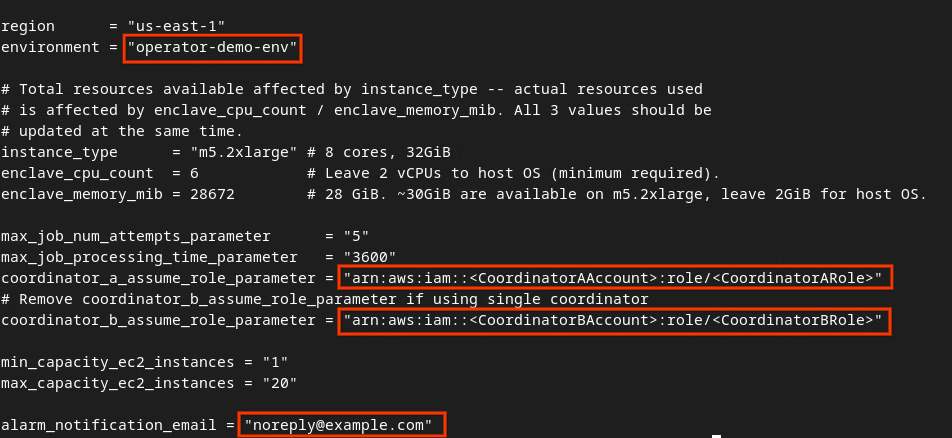 डेवलपमेंट एनवायरमेंट के लिए, अपने-आप जनरेट होने वाली tfvars फ़ाइल में बदलाव करें.
डेवलपमेंट एनवायरमेंट के लिए, अपने-आप जनरेट होने वाली tfvars फ़ाइल में बदलाव करें.
अपडेट करने के बाद, esc -> :wq! दबाएं. इससे dev.auto.tfvars फ़ाइल सेव हो जाती है. यह कुछ इस तरह दिखनी चाहिए.
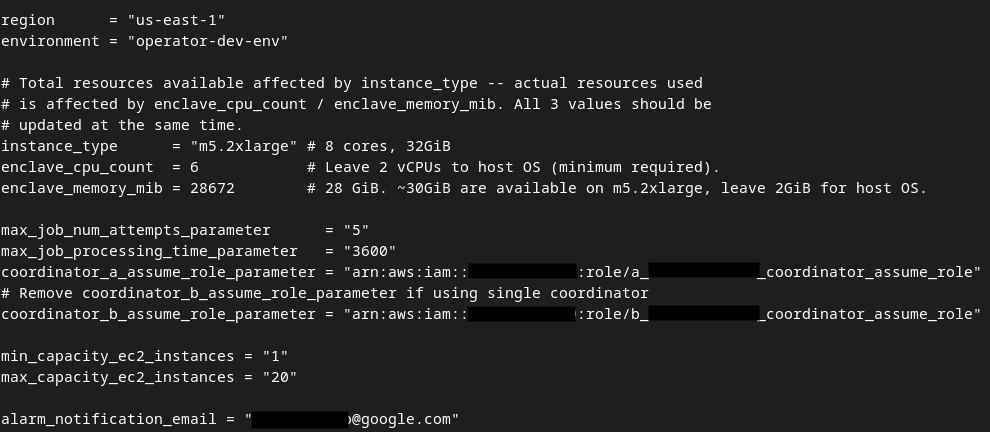 डेवलपमेंट एनवायरमेंट के लिए, अपने-आप जनरेट होने वाली tfvars फ़ाइल अपडेट की गई.
डेवलपमेंट एनवायरमेंट के लिए, अपने-आप जनरेट होने वाली tfvars फ़ाइल अपडेट की गई.
3.4. एग्रीगेशन सेवा को डिप्लॉय करना
एग्रीगेशन सेवा को डिप्लॉय करने के लिए, उसी फ़ोल्डर
terraform init
इससे आपको इस इमेज जैसा कुछ दिखेगा:
 Terraform init.
Terraform init.
Terraform शुरू होने के बाद, Terraform का एक्ज़ीक्यूशन प्लान बनाएं. यहां, जोड़े जाने वाले संसाधनों की संख्या और अन्य अतिरिक्त जानकारी मिलती है. यह जानकारी, इस इमेज में दी गई जानकारी से मिलती-जुलती होती है.
terraform plan
यहां "प्लान" की खास जानकारी दी गई है. अगर यह नया डिप्लॉयमेंट है, तो आपको उन संसाधनों की संख्या दिखेगी जिन्हें जोड़ा जाएगा. साथ ही, आपको यह भी दिखेगा कि कितने संसाधनों में बदलाव किया जाएगा और कितने संसाधनों को हटाया जाएगा.
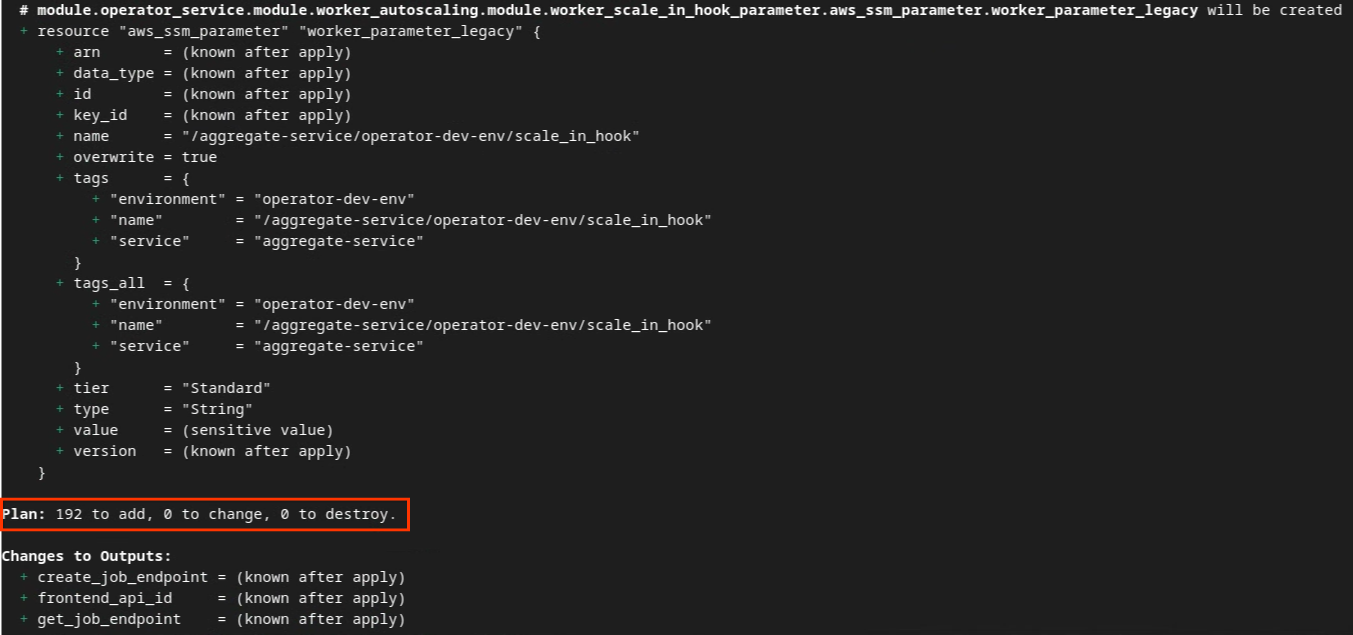 Terraform प्लान.
Terraform प्लान.
यह प्रोसेस पूरी करने के बाद, Terraform लागू किया जा सकता है.
terraform apply
जब Terraform की कार्रवाइयों की पुष्टि करने के लिए कहा जाए, तब वैल्यू में yes डालें.
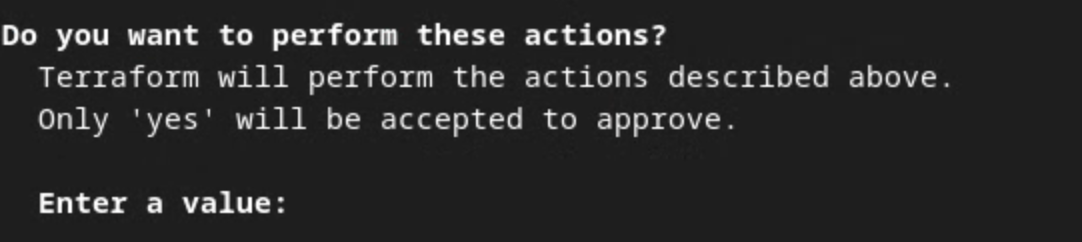 Terraform apply प्रॉम्प्ट.
Terraform apply प्रॉम्प्ट.
terraform apply पूरा होने के बाद, createJob और getJob के लिए ये एंडपॉइंट दिखाए जाते हैं. आपको Postman में सेक्शन 1.9 में मौजूद frontend_api_id को भी अपडेट करना होगा.
 Terraform apply complete.
Terraform apply complete.
4. एग्रीगेशन सेवा के लिए इनपुट बनाना
एग्रीगेशन सेवा में बैचिंग के लिए, AVRO रिपोर्ट बनाएं.
चौथा चरण. एग्रीगेशन सेवा के लिए इनपुट बनाना: एग्रीगेशन सेवा के लिए बैच की गई एग्रीगेशन सेवा की रिपोर्ट बनाएं.
चौथा चरण.1. ट्रिगर रिपोर्ट
चरण 4.2. एग्रीगेट की जा सकने वाली रिपोर्ट इकट्ठा करना
चौथा चरण.3. रिपोर्ट को AVRO फ़ॉर्मैट में बदलना
चौथा चरण.4. आउटपुट डोमेन AVRO बनाएं
4.1. ट्रिगर रिपोर्ट
Privacy Sandbox के डेमो की साइट पर जाएं. इससे निजता बनाए रखने वाली एग्रीगेशन रिपोर्ट ट्रिगर होती है. रिपोर्ट को chrome://private-aggregation-internals पर देखा जा सकता है.
Chrome में निजता बनाए रखते हुए डेटा इकट्ठा करने की सुविधा के बारे में जानकारी.
अगर आपकी रिपोर्ट "लंबित है" स्थिति में है, तो रिपोर्ट को चुनें और "चुनी गई रिपोर्ट भेजें" पर क्लिक करें. '
निजी एग्रीगेशन रिपोर्ट भेजें.
4.2. अलग-अलग डेटा को मिलाकर तैयार की जा सकने वाली रिपोर्ट इकट्ठा करना
अपने एपीआई के .well-known एंडपॉइंट से, एग्रीगेट की जा सकने वाली रिपोर्ट इकट्ठा करें.
- Private Aggregation
[reporting-origin] /.well-known/private-aggregation/report-shared-storage - Attribution Reporting - खास जानकारी वाली रिपोर्ट
[reporting-origin] /.well-known/attribution-reporting/report-aggregate-attribution
इस कोडलैब के लिए, आपको रिपोर्ट कलेक्शन मैन्युअल तरीके से करना होगा. प्रोडक्शन में, विज्ञापन से जुड़ी टेक्नोलॉजी कंपनियों से उम्मीद की जाती है कि वे प्रोग्राम के हिसाब से रिपोर्ट इकट्ठा करें और उन्हें बदलें.
chrome://private-aggregation-internals में, [reporting-origin]/.well-known/private-aggregation/report-shared-storage एंडपॉइंट से मिला "Report Body" कॉपी करें.
पक्का करें कि "रिपोर्ट बॉडी" में, aggregation_coordinator_origin में https://publickeyservice.msmt.aws.privacysandboxservices.com शामिल हो. इसका मतलब है कि रिपोर्ट, AWS की एग्रीगेट की जा सकने वाली रिपोर्ट है.
Private Aggregation रिपोर्ट.
JSON फ़ाइल में JSON "Report Body" को रखें. इस उदाहरण में, vim का इस्तेमाल किया जा सकता है. हालांकि, अपनी पसंद के किसी भी टेक्स्ट एडिटर का इस्तेमाल किया जा सकता है.
vim report.json
रिपोर्ट को report.json में चिपकाएं और अपनी फ़ाइल सेव करें.
रिपोर्ट की JSON फ़ाइल.
4.3. रिपोर्ट को AVRO फ़ॉर्मैट में बदलना
.well-known एंडपॉइंट से मिली रिपोर्ट, JSON फ़ॉर्मैट में होती हैं. इन्हें AVRO रिपोर्ट फ़ॉर्मैट में बदलना होता है. JSON रिपोर्ट मिलने के बाद, अपने रिपोर्ट फ़ोल्डर पर जाएं. इसके बाद, aggregatable_report_converter.jar का इस्तेमाल करके, डिबग करने लायक एग्रीगेट की गई रिपोर्ट बनाएं. इससे आपकी मौजूदा डायरेक्ट्री में, एग्रीगेट की जा सकने वाली एक रिपोर्ट बन जाती है. इसे report.avro कहा जाता है.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
4.4. आउटपुट डोमेन AVRO बनाएं
output_domain.avro फ़ाइल बनाने के लिए, आपको बकेट कुंजियों की ज़रूरत होती है. इन्हें रिपोर्ट से वापस पाया जा सकता है.
बकेट की, विज्ञापन टेक्नोलॉजी से जुड़ी कंपनी बनाती है. हालांकि, इस मामले में साइट Privacy Sandbox demo बकेट की बनाती है. इस साइट के लिए, Private Aggregation API डीबग मोड में है. इसलिए, बकेट की पाने के लिए "Report Body" से debug_cleartext_payload का इस्तेमाल किया जा सकता है.
रिपोर्ट के मुख्य हिस्से से debug_cleartext_payload को कॉपी करें.
रिपोर्ट के मुख्य हिस्से से क्लियरटेक्स्ट पेलोड डीबग करें.
goo.gle/ags-payload-decoder खोलें. इसके बाद, "INPUT" बॉक्स में अपना debug_cleartext_payload चिपकाएं और "Decode" पर क्लिक करें.
पेलोड डिकोडर.
यह पेज, बकेट कुंजी की दशमलव वैल्यू दिखाता है. यहां बकेट की का एक सैंपल दिया गया है.
Payload decoder result.
अब हमारे पास बकेट की कुंजी है. इसलिए, output_domain.avro बनाएं. पुष्टि करें कि आपने
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
यह स्क्रिप्ट, आपके मौजूदा फ़ोल्डर में output_domain.avro फ़ाइल बनाती है.
4.5. रिपोर्ट को AWS बकेट में ले जाना
AVRO रिपोर्ट (सेक्शन 3.2.3 में दी गई जानकारी के मुताबिक) और आउटपुट डोमेन (सेक्शन 3.2.4 में दी गई जानकारी के मुताबिक) बनाने के बाद, रिपोर्ट और आउटपुट डोमेन को रिपोर्टिंग S3 बकेट में ले जाएं.
अगर आपके लोकल एनवायरमेंट में AWS CLI सेटअप है, तो रिपोर्ट को उससे जुड़े S3 बकेट और रिपोर्ट फ़ोल्डर में कॉपी करने के लिए, इन कमांड का इस्तेमाल करें.
aws s3 cp report.avro s3://<report_bucket_name>/<report_folder>/
aws s3 cp output_domain.avro s3://<report_bucket_name>/<output_domain_folder>/
5. एग्रीगेशन सेवा के इस्तेमाल से जुड़ी जानकारी
terraform apply से आपको create_job_endpoint, get_job_endpoint, और frontend_api_id वापस मिल जाते हैं. frontend_api_id को कॉपी करें और इसे Postman के ग्लोबल वैरिएबल frontend_api_id में डालें. इसे आपने ज़रूरी शर्तें वाले सेक्शन 1.9 में सेट अप किया था.
पांचवां चरण. Aggregation Service का इस्तेमाल: खास जानकारी वाली रिपोर्ट बनाने और उनकी समीक्षा करने के लिए, Aggregation Service API का इस्तेमाल करें.
पांचवां चरण.1. createJob एंडपॉइंट का इस्तेमाल करके बैच
चरण 5.2. बैच की स्थिति वापस पाने के लिए, getJob एंडपॉइंट का इस्तेमाल करना
पांचवां चरण.3. खास जानकारी वाली रिपोर्ट की समीक्षा करना
5.1. बैच के लिए createJob एंडपॉइंट का इस्तेमाल करना
Postman में, "Privacy Sandbox" कलेक्शन खोलें और "createJob" चुनें.
अनुरोध पेलोड डालने के लिए, "बॉडी" और "रॉ" को चुनें.
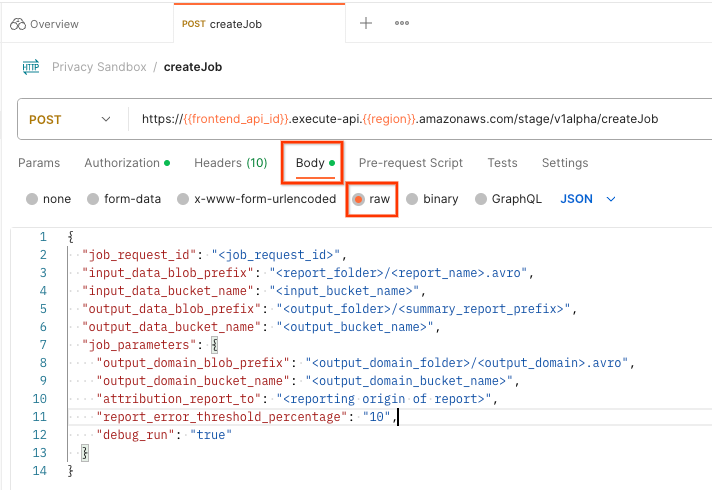 postman createJob request body
postman createJob request body
createJob पेलोड स्कीमा, github में उपलब्ध है. यह कुछ इस तरह दिखता है. <> को सही फ़ील्ड से बदलें.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
], // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
"भेजें" पर क्लिक करने के बाद, job_request_id के साथ नौकरी पोस्ट हो जाएगी. अनुरोध को एग्रीगेशन सेवा से स्वीकार किए जाने के बाद, आपको एचटीटीपी 202 जवाब मिलेगा. अन्य संभावित रिटर्न कोड के बारे में जानने के लिए, एचटीटीपी रिस्पॉन्स कोड पर जाएं
 postman createJob request status
postman createJob request status
5.2. बैच की स्थिति वापस पाने के लिए, getJob एंडपॉइंट का इस्तेमाल करना
नौकरी के अनुरोध की स्थिति देखने के लिए, getJob एंडपॉइंट का इस्तेमाल किया जा सकता है. "Privacy Sandbox" कलेक्शन में जाकर, "getJob" को चुनें.
"पैरामीटर" में, job_request_id की वैल्यू को उस job_request_id पर अपडेट करें जिसे createJob अनुरोध में भेजा गया था.
 postman getJob request
postman getJob request
getJob के नतीजे में, नौकरी के आपके अनुरोध की स्थिति दिखनी चाहिए. साथ ही, एचटीटीपी स्टेटस 200 होना चाहिए. अनुरोध के "मुख्य हिस्से" में ज़रूरी जानकारी शामिल होती है. जैसे, job_status, return_message, और error_messages (अगर नौकरी के विज्ञापन में कोई गड़बड़ी हुई है).
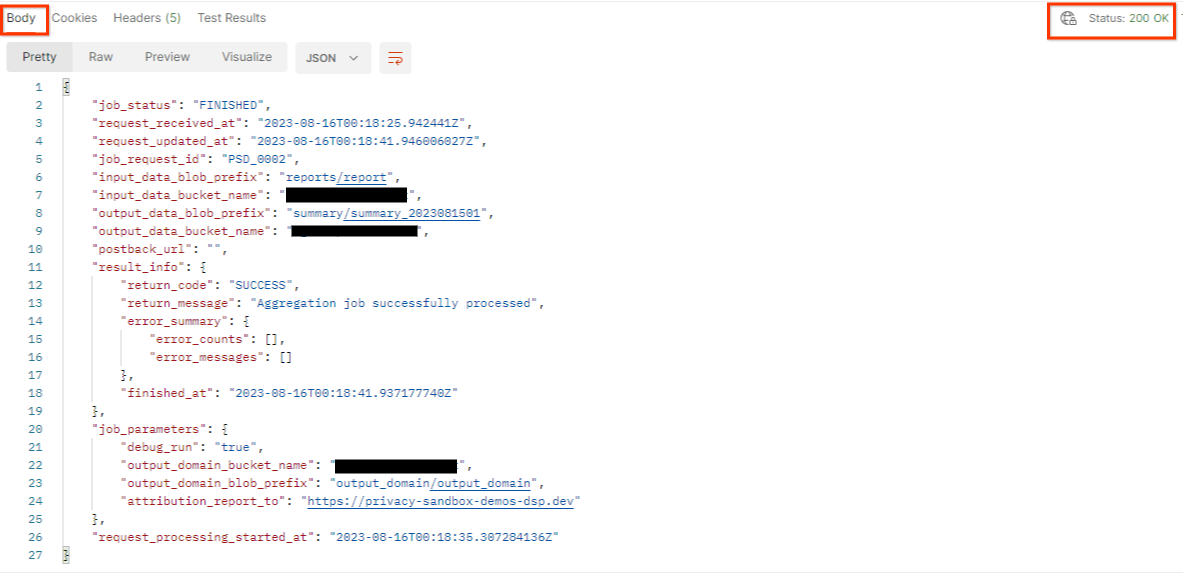 postman getJob request status
postman getJob request status
जनरेट की गई डेमो रिपोर्ट की रिपोर्टिंग साइट, आपके AWS आईडी पर शामिल की गई साइट से अलग है. इसलिए, आपको PRIVACY_BUDGET_AUTHORIZATION_ERROR return_code वाला जवाब मिल सकता है. यह सामान्य है, क्योंकि रिपोर्टिंग ऑरिजिन की साइट, AWS आईडी के लिए शामिल की गई रिपोर्टिंग साइट से मेल नहीं खाती.
{
"job_status": "FINISHED",
"request_received_at": "2023-12-07T22:50:58.830956Z",
"request_updated_at": "2023-12-07T22:51:10.526326456Z",
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"postback_url": "",
"result_info": {
"return_code": "PRIVACY_BUDGET_AUTHORIZATION_ERROR",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-12-07T22:51:10.517730898Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"attribution_report_to": "https://privacy-sandbox-demos-dsp.dev",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
},
"request_processing_started_at": "2023-12-07T22:51:06.034472697Z"
}
5.3. खास जानकारी वाली रिपोर्ट की समीक्षा करना
आउटपुट S3 बकेट में खास जानकारी वाली रिपोर्ट मिलने के बाद, इसे अपने लोकल एनवायरमेंट में डाउनलोड किया जा सकता है. खास जानकारी वाली रिपोर्ट, AVRO फ़ॉर्मैट में होती हैं. इन्हें वापस JSON फ़ॉर्मैट में बदला जा सकता है. aggregatable_report_converter.jar का इस्तेमाल करके, इस निर्देश की मदद से अपनी रिपोर्ट पढ़ी जा सकती है.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
इससे हर बकेट की के लिए, एग्रीगेट की गई वैल्यू का JSON मिलता है. यह JSON, इस इमेज जैसा दिखता है.
 खास जानकारी वाली रिपोर्ट.
खास जानकारी वाली रिपोर्ट.
अगर आपके createJob अनुरोध में debug_run को true के तौर पर शामिल किया गया है, तो आपको अपनी खास जानकारी वाली रिपोर्ट, output_data_blob_prefix में मौजूद डीबग फ़ोल्डर में मिल सकती है. यह रिपोर्ट AVRO फ़ॉर्मैट में है. इसे JSON में बदलने के लिए, पिछली कमांड का इस्तेमाल किया जा सकता है.
रिपोर्ट में बकेट की, बिना नॉइज़ वाली मेट्रिक, और वह नॉइज़ शामिल होती है जिसे बिना नॉइज़ वाली मेट्रिक में जोड़कर खास जानकारी वाली रिपोर्ट बनाई जाती है. रिपोर्ट, इस इमेज की तरह दिखती है.
 डबग की खास जानकारी वाली रिपोर्ट.
डबग की खास जानकारी वाली रिपोर्ट.
एनोटेशन में in_reports और in_domain भी शामिल हैं. इसका मतलब है कि:
- in_reports - बकेट की, एग्रीगेट की जा सकने वाली रिपोर्ट में उपलब्ध है.
- in_domain - बकेट की, output_domain AVRO फ़ाइल में उपलब्ध है.