
1. דרישות מוקדמות
כדי לבצע את ה-Codelab הזה, צריך לעמוד בכמה תנאים מוקדמים. כל דרישה מסומנת בהתאם אם היא נדרשת ל'בדיקה מקומית' או ל'שירות צבירה'.
1.1. הורדת הכלי לבדיקה מקומית (בדיקה מקומית)
כדי לבצע בדיקה מקומית, צריך להוריד את הכלי לבדיקה מקומית. הכלי ייצור דוחות סיכום מדוחות הניפוי באגים הלא מוצפנים.
אפשר להוריד את הכלי לבדיקה מקומית מארכיוני ה-JAR של Lambda ב-Github. היא צריכה להיקרא LocalTestingTool_{version}.jar.
1.2. אימות ההתקנה של JAVA JRE (שירות בדיקות מקומי ושירות צבירה)
פותחים את Terminal ומשתמשים ב-java --version כדי לבדוק אם Java או openJDK מותקנים במחשב.
 בודקים את הגרסה של Java JRE באמצעות `java --version`.
בודקים את הגרסה של Java JRE באמצעות `java --version`.
אם היא לא מותקנת, אפשר להוריד ולהתקין אותה מאתר Java או מאתר openJDK.
1.3. הורדת כלי להמרת דוחות שניתנים לצבירה (בדיקות מקומיות ו-Aggregation Service)
אפשר להוריד עותק של כלי ההמרה של דוחות עם נתונים מצטברים ממאגר ההדגמות של ארגז החול לפרטיות ב-GitHub.
1.4. הפעלת ממשקי Ad Privacy API (בדיקה מקומית ושירות צבירה)
בדפדפן, עוברים אל chrome://settings/adPrivacy ומפעילים את כל ממשקי ה-API של פרטיות המודעות.
מוודאים שקובצי Cookie של צד שלישי מופעלים.
בדפדפן, עוברים אל chrome://settings/cookies ובוחרים באפשרות חסימת קובצי Cookie של צד שלישי במצב פרטי.
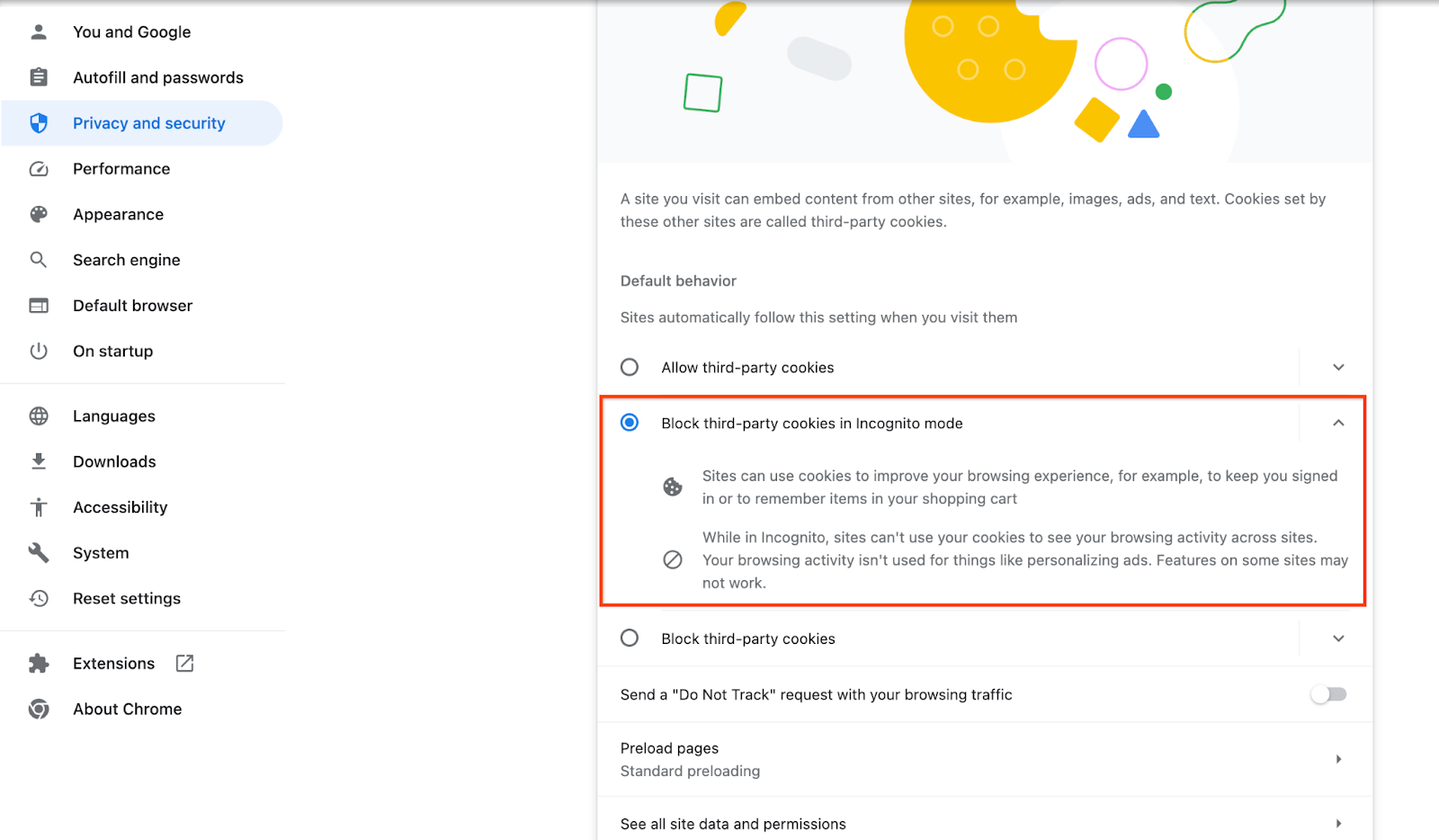 הגדרת קובצי Cookie של צד שלישי ב-Chrome.
הגדרת קובצי Cookie של צד שלישי ב-Chrome.
1.5. הרשמה לאתרים ולאפליקציות ל-Android (Aggregation Service)
כדי להשתמש בממשקי Privacy Sandbox API בסביבת ייצור, חשוב לוודא שסיימתם את תהליך ההרשמה והאימות גם ב-Chrome וגם ב-Android.
לצורך בדיקות מקומיות, אפשר להשבית את ההרשמה באמצעות דגל Chrome ומתג CLI.
כדי להשתמש בתכונה הניסיונית של Chrome להדגמה שלנו, צריך לעבור אל chrome://flags/#privacy-sandbox-enrollment-overrides ולעדכן את ההחלפה באתר שלכם. אם תשתמשו באתר ההדגמה שלנו, לא נדרש עדכון.
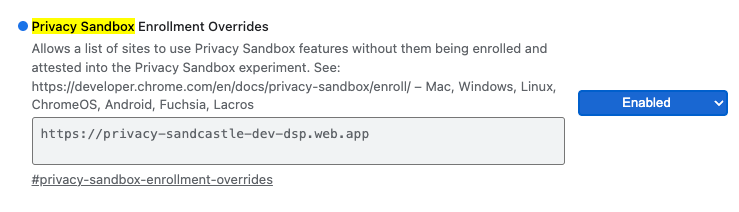 דגל Chrome לביטול ההצטרפות לארגז החול לפרטיות.
דגל Chrome לביטול ההצטרפות לארגז החול לפרטיות.
1.6. הצטרפות ל-Aggregation Service
כדי להשתמש ב-Aggregation Service, צריך להצטרף לתיאום. ממלאים את טופס ההצטרפות לשירות האגרגציה ומזינים את כתובת האתר של הדוחות, את מזהה חשבון AWS ופרטים נוספים.
1.7. ספק שירותי ענן (Aggregation Service)
כדי להשתמש ב-Aggregation Service, צריך להשתמש בסביבת מחשוב אמינה (TEE) שמשתמשת בסביבת ענן. שירות הצבירה נתמך ב-Amazon Web Services (AWS) וב-Google Cloud (GCP). ב-Codelab הזה נסביר רק על שילוב עם AWS.
AWS מספקת סביבת מחשוב אמינה שנקראת Nitro Enclaves. מוודאים שיש לכם חשבון AWS ופועלים לפי ההוראות להתקנה ולעדכון של AWS CLI כדי להגדיר את סביבת AWS CLI.
אם אתם משתמשים ב-AWS CLI חדש, תוכלו להגדיר אותו באמצעות ההוראות להגדרת ה-CLI.
1.7.1. יצירת קטגוריית AWS S3
יוצרים קטגוריית AWS S3 לאחסון מצב Terraform, ועוד קטגוריית S3 לאחסון הדוחות והדוחות המסכמים. אפשר להשתמש בפקודת ה-CLI שמופיעה כאן. מחליפים את השדה <> במשתנים המתאימים.
aws s3api create-bucket --bucket <tf_bucket_name> --region us-east-1
aws s3api create-bucket --bucket <report_bucket_name> --region us-east-1
1.7.2. יצירת מפתח גישה למשתמש
יוצרים מפתחות לגישת משתמש באמצעות המדריך של AWS. הוא ישמש לקריאה לנקודות הקצה של ה-API createJob ו-getJob שנוצרו ב-AWS.
1.7.3. הרשאות משתמשים וקבוצות ב-AWS
כדי לפרוס את Aggregation Service ב-AWS, צריך לתת הרשאות מסוימות למשתמש שמשמש לפריסת השירות. ב-Codelab הזה, צריך לוודא שלמשתמש יש גישת אדמין כדי להיות בטוחים שיש לו הרשאות מלאות לפריסה.
1.8. Terraform (Aggregation Service)
ב-Codelab הזה משתמשים ב-Terraform כדי לפרוס את Aggregation Service. מוודאים שקובץ ה-Terraform הבינארי מותקן בסביבה המקומית.
מורידים את קובץ ההפעלה של Terraform לסביבה המקומית.
אחרי שמורידים את קובץ ה-Terraform הבינארי, מחלצים את הקובץ ומעבירים את קובץ ה-Terraform הבינארי אל /usr/local/bin.
cp <directory>/terraform /usr/local/bin
מוודאים ש-Terraform זמין בנתיב המחלקה.
terraform -v
1.9. Postman (ל-Aggregation Service AWS)
ב-Codelab הזה, משתמשים ב-Postman לניהול בקשות.
כדי ליצור סביבת עבודה, עוברים אל סביבות עבודה בתפריט הניווט העליון ובוחרים באפשרות יצירה של סביבת עבודה.
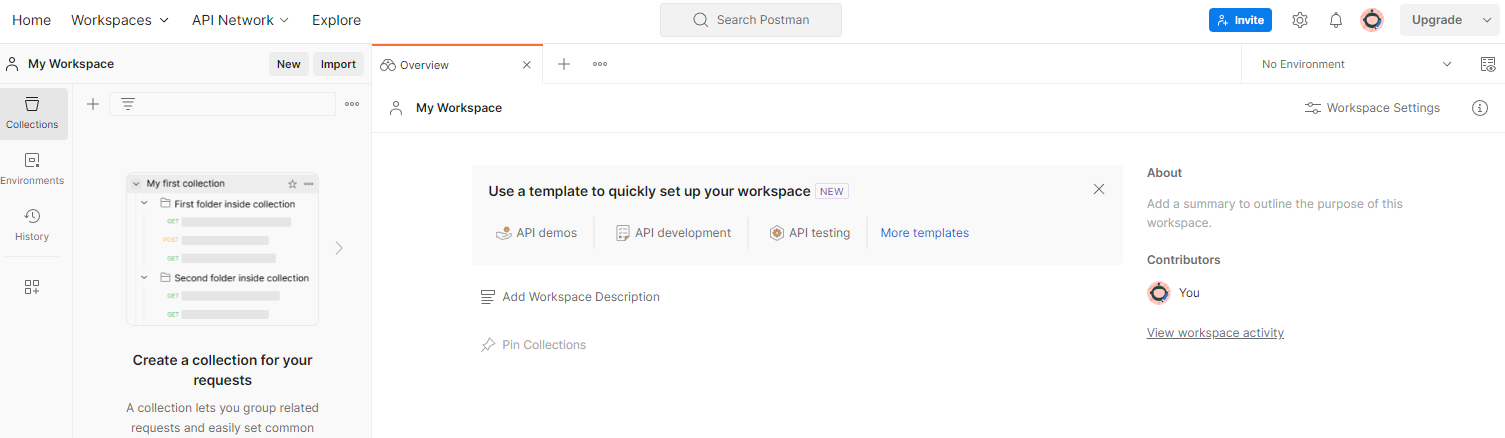 סביבת עבודה ב-Postman
סביבת עבודה ב-Postman
בוחרים באפשרות סביבת עבודה ריקה, לוחצים על 'הבא' ונותנים לה את השם ארגז החול לפרטיות. בוחרים באפשרות אישי ולוחצים על יצירה.
מורידים את קובצי הגדרות ה-JSON והסביבה הגלובלית של סביבת העבודה שהוגדרה מראש.
מייבאים את קובצי ה-JSON אל My Workspace באמצעות הלחצן Import (ייבוא).
 ייבוא קובצי JSON של Postman.
ייבוא קובצי JSON של Postman.
הפעולה הזו תיצור בשבילכם את אוסף ארגז החול לפרטיות יחד עם בקשות ה-HTTP createJob ו-getJob.
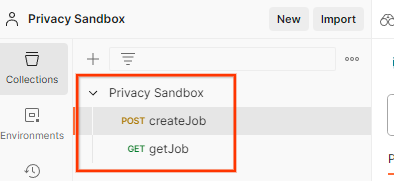 אוסף שייובא מ-Postman.
אוסף שייובא מ-Postman.
מעדכנים את מפתח הגישה ואת המפתח הסודי של AWS דרך סקירה מהירה של הסביבה.
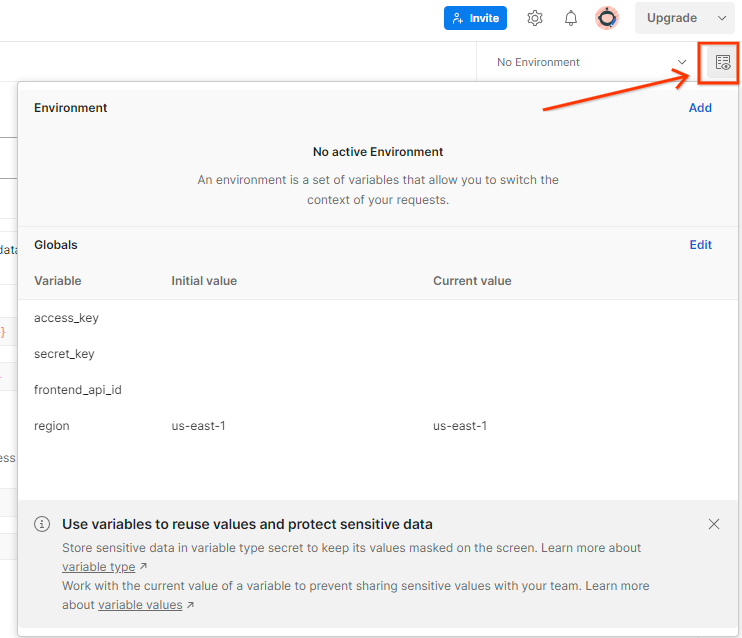 מבט מהיר על סביבת Postman.
מבט מהיר על סביבת Postman.
לוחצים על עריכה ומעדכנים את הערך הנוכחי של access_key ושל secret_key. שימו לב שfrontend_api_id יסופק בקטע 3.1.4 במסמך הזה. מומלץ להשתמש באזור us-east-1. עם זאת, אם רוצים לבצע פריסה באזור אחר, צריך לוודא שהעתקתם את ה-AMI שפורסם לחשבון שלכם או לבצע בנייה עצמית באמצעות סקריפטים שסופקו.
 משתנים גלובליים של Postman.
משתנים גלובליים של Postman. 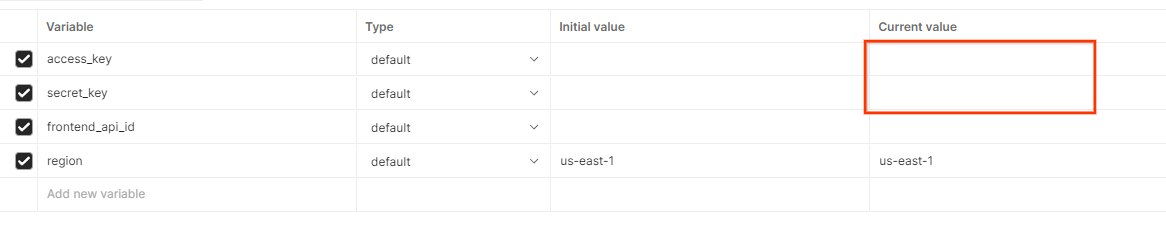 עריכת משתנים גלובליים ב-Postman.
עריכת משתנים גלובליים ב-Postman.
2. Codelab בנושא בדיקות מקומיות
אתם יכולים להשתמש בכלי לבדיקה מקומית במחשב שלכם כדי לבצע צבירה וליצור דוחות סיכום באמצעות דוחות ניפוי הבאגים הלא מוצפנים.
שלבים ב-Codelab
שלב 2.1. הפעלת דוח: הפעלת דיווח של Private Aggregation כדי לאסוף את הדוח.
שלב 2.2. יצירת דוח מצטבר לניפוי באגים: המרת דוח JSON שנאסף לדוח בפורמט AVRO.
השלב הזה דומה למצב שבו טכנולוגיות פרסום אוספות את הדוחות מנקודות הקצה של ה-API לדיווח וממירות את הדוחות בפורמט JSON לדוחות בפורמט AVRO.
שלב 2.3. ניתוח מפתח המאגר מדוח הניפוי באגים: מפתחות המאגר מתוכננים על ידי טכנולוגיות פרסום. ב-codelab הזה, מאחר שהקטגוריות מוגדרות מראש, צריך לאחזר את מפתחות הקטגוריות כמו שהם.
שלב 2.4. יצירת קובץ AVRO של דומיין הפלט: אחרי אחזור מפתחות ה-Bucket, יוצרים את קובץ ה-AVRO של דומיין הפלט.
שלב 2.5. יצירת דוחות סיכום באמצעות הכלי לבדיקות מקומיות: אפשר להשתמש בכלי לבדיקות מקומיות כדי ליצור דוחות סיכום בסביבה המקומית.
שלב 2.6. עיון בדוח הסיכום: עיון בדוח הסיכום שנוצר על ידי הכלי לבדיקה מקומית.
2.1. דוח טריגרים
עוברים לאתר הדגמה של ארגז החול לפרטיות. הפעולה הזו מפעילה דוח צבירה פרטי. אפשר לראות את הדוח בכתובת chrome://private-aggregation-internals.
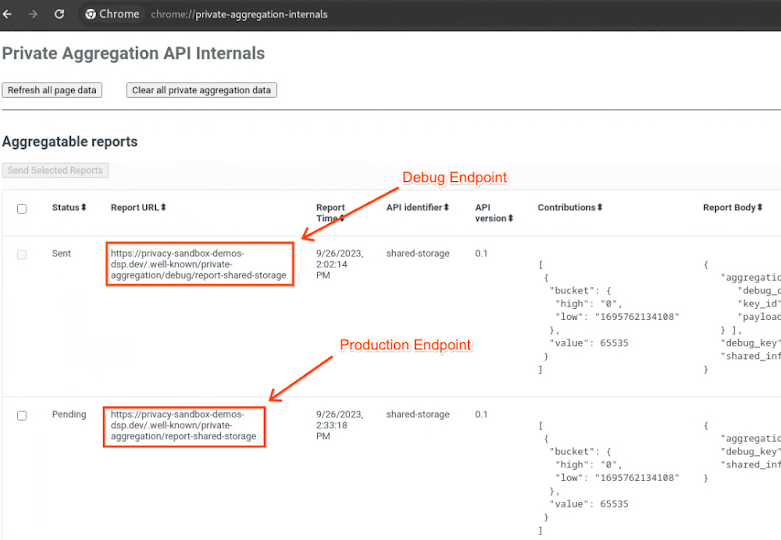 פרטים פנימיים על צבירה פרטית ב-Chrome.
פרטים פנימיים על צבירה פרטית ב-Chrome.
אם הדוח שלכם במצב בהמתנה, אתם יכולים לבחור את הדוח וללחוץ על שליחת הדוחות שנבחרו.
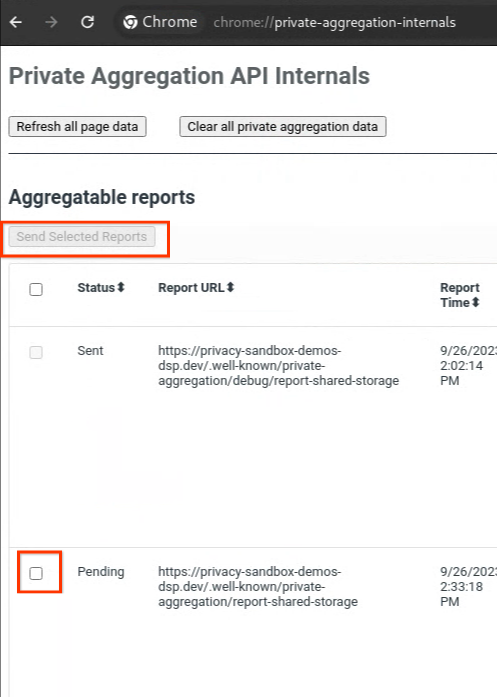 שליחת דוח צבירה פרטית.
שליחת דוח צבירה פרטית.
2.2. יצירת דוח ניתן לצבירה לניפוי באגים
ב-chrome://private-aggregation-internals, מעתיקים את גוף הדוח שהתקבל בנקודת הקצה [reporting-origin]/.well-known/private-aggregation/report-shared-storage.
מוודאים שב-Report Body (גוף הדוח), aggregation_coordinator_origin מכיל https://publickeyservice.msmt.aws.privacysandboxservices.com, כלומר הדוח הוא דוח ניתן לצבירה ב-AWS.
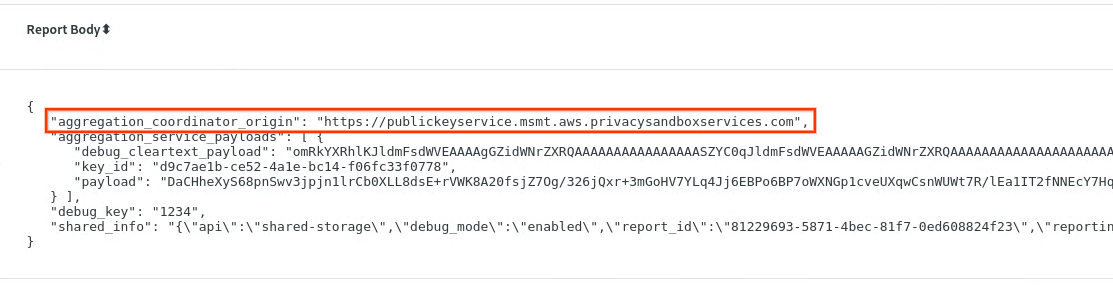 דוח של צבירת נתונים פרטית.
דוח של צבירת נתונים פרטית.
ממקמים את ה-JSON Report Body בקובץ JSON. בדוגמה הזו, אפשר להשתמש ב-vim. אבל אתם יכולים להשתמש בכל עורך טקסט שתרצו.
vim report.json
מדביקים את הדוח ב-report.json ושומרים את הקובץ.
 קובץ JSON של הדוח.
קובץ JSON של הדוח.
אחרי שיש לכם את זה, עוברים לתיקיית הדוחות ומשתמשים ב-aggregatable_report_converter.jar כדי ליצור את הדוח המצטבר לניפוי באגים. הפעולה הזו יוצרת דוח שניתן לצבירה בשם report.avro בספרייה הנוכחית.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. ניתוח מפתח הדלי מדוח ניפוי הבאגים
כשמשתמשים ב-Aggregation Service כדי ליצור חבילות, צריך שני קבצים. הדוח שניתן לצבירה וקובץ פלט הדומיין. קובץ הפלט של הדומיין מכיל את המפתחות שרוצים לאחזר מהדוחות הניתנים לצבירה. כדי ליצור את הקובץ output_domain.avro, צריך את מפתחות ה-bucket שאפשר לאחזר מהדוחות.
מפתחות של מאגרי מידע נוצרים על ידי מי שקורא ל-API, ובהדמו יש דוגמאות מוכנות של מפתחות של מאגרי מידע. בגלל שמצב ניפוי הבאגים של צבירה פרטית מופעל בהדגמה, אפשר לנתח את מטען הנתונים של הטקסט הגלוי לניפוי באגים מהקטע גוף הדוח כדי לאחזר את מפתח הדלי. עם זאת, במקרה הזה, האתר privacy sandbox demo יוצר את מפתחות הדלי. מכיוון ש-Private Aggregation באתר הזה נמצא במצב ניפוי באגים, אפשר להשתמש ב-debug_cleartext_payload מתוך גוף הדוח כדי לקבל את מפתח הדלי.
מעתיקים את debug_cleartext_payload מגוף הדוח.
 ניפוי באגים של מטען ייעודי (payload) בטקסט גלוי מגוף הדוח.
ניפוי באגים של מטען ייעודי (payload) בטקסט גלוי מגוף הדוח.
פותחים את הכלי Debug payload decoder for Private Aggregation (מפענח מטען ייעודי למאגרי מידע פרטיים) ומדביקים את debug_cleartext_payloadבתיבה INPUT (קלט) ואז לוחצים על Decode (פענוח).
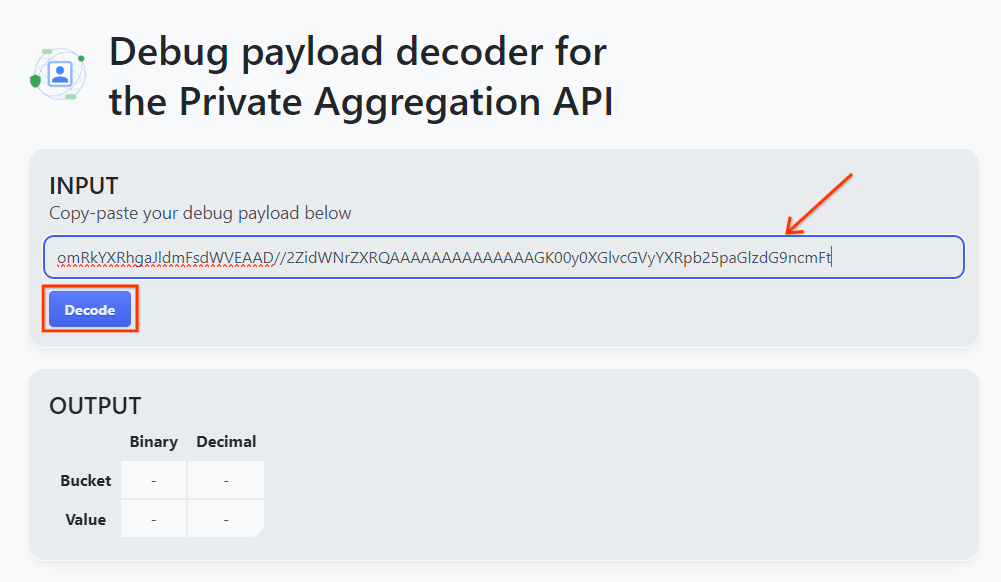 מפענח מטען ייעודי (payload).
מפענח מטען ייעודי (payload).
הדף מחזיר את הערך העשרוני של מפתח הדלי. זוהי דוגמה למפתח קטגוריה.
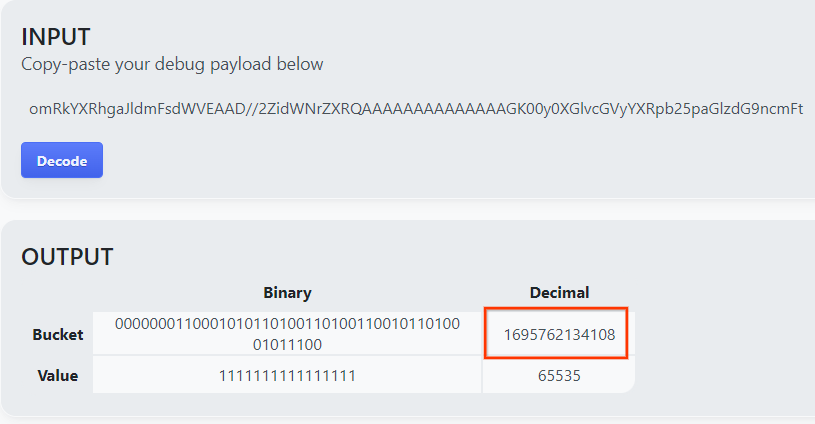 תוצאה של פענוח מטען ייעודי (payload).
תוצאה של פענוח מטען ייעודי (payload).
2.4. יצירת קובץ AVRO של דומיין הפלט
אחרי שמוצאים את מפתח הדלי, מעתיקים את הערך העשרוני שלו. ממשיכים ליצור את output_domain.avro באמצעות מפתח קטגוריית האחסון. מוודאים שהחלפתם את
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
הסקריפט יוצר את הקובץ output_domain.avro בתיקייה הנוכחית.
2.5. יצירת דוחות סיכום באמצעות הכלי לבדיקות מקומיות
נשתמש ב-LocalTestingTool_{version}.jar שהורד בקטע 1.1 כדי ליצור את דוחות הסיכום. משתמשים בפקודה הבאה. צריך להחליף את LocalTestingTool_{version}.jar בגרסה שהורדתם עבור LocalTestingTool.
מריצים את הפקודה הבאה כדי ליצור דוח סיכום בסביבת הפיתוח המקומית:
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
אחרי שמריצים את הפקודה, אמור להופיע פלט שדומה לזה שמוצג בתמונה הבאה. דוח output.avro נוצר בסיום התהליך.
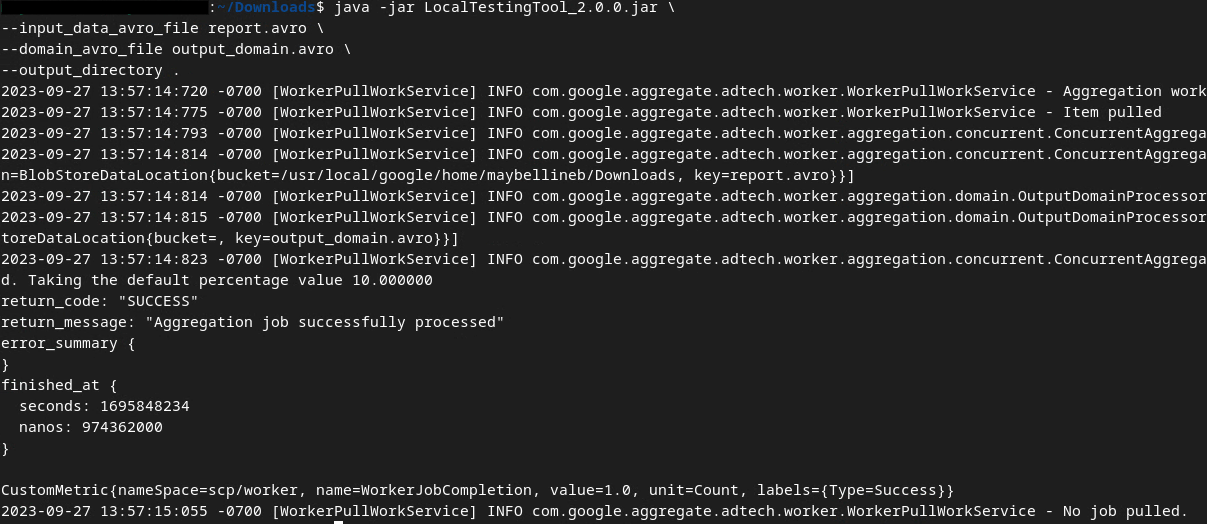 קובץ avro של דוח סיכום הבדיקה המקומית.
קובץ avro של דוח סיכום הבדיקה המקומית.
2.6. בדיקת דוח הסיכום
דוח הסיכום שנוצר הוא בפורמט AVRO. כדי לקרוא את הנתונים, צריך להמיר אותם מפורמט AVRO לפורמט JSON. מומלץ להשתמש בטכנולוגיות פרסום דיגיטלי שכוללות קוד להמרה של דוחות AVRO בחזרה ל-JSON.
ב-Codelab הזה נשתמש בכלי aggregatable_report_converter.jar שסיפקנו כדי להמיר את דוח ה-AVRO בחזרה ל-JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
יוחזר דוח שדומה לתמונה הבאה. יחד עם דוח output.json שנוצר באותה תיקייה.
 קובץ avro של סיכום שהומר ל-json.
קובץ avro של סיכום שהומר ל-json.
פותחים את קובץ ה-JSON בעורך לבחירתכם כדי לעיין בדוח הסיכום.
3. פריסה של Aggregation Service
כדי לפרוס את Aggregation Service, פועלים לפי השלבים הבאים:
שלב 3. פריסת Aggregation Service: פריסת Aggregation Service ב-AWS
שלב 3.1. משכפלים את מאגר Aggregation Service
שלב 3.2. הורדת יחסי תלות מוכנים מראש
שלב 3.3. יצירת סביבת פיתוח
שלב 3.4. פריסת Aggregation Service
3.1. שכפול המאגר של Aggregation Service
בסביבה המקומית, משכפלים את מאגר GitHub של שירות הצבירה.
git clone https://github.com/privacysandbox/aggregation-service.git
3.2. הורדה של פניות קשורות מוכנות מראש
אחרי שמשכפלים את מאגר Aggregation Service, עוברים לתיקיית Terraform של המאגר ולתיקיית הענן המתאימה. אם cloud_provider הוא AWS, אפשר להמשיך אל
cd <repository_root>/terraform/aws
ב-download_prebuilt_dependencies.sh.
bash download_prebuilt_dependencies.sh
3.3. יצירת סביבת פיתוח
יוצרים סביבת פיתוח ב-dev.
mkdir dev
מעתיקים את התוכן של התיקייה demo לתיקייה dev.
cp -R demo/* dev
עוברים לתיקייה dev.
cd dev
מעדכנים את הקובץ main.tf ולוחצים על i כדי לערוך את הקובץ input.
vim main.tf
מבטלים את ההערה של הקוד בתיבה האדומה על ידי הסרת התו # ועדכון השמות של דלי הנתונים והמפתח.
עבור AWS main.tf:
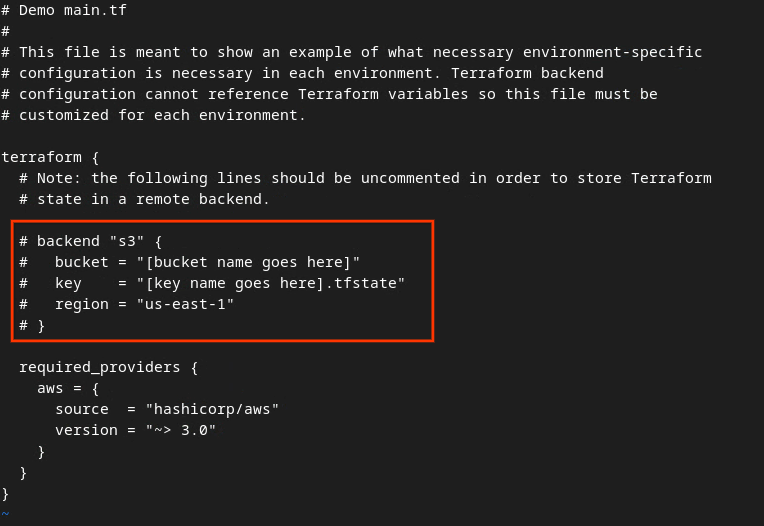 קובץ ה-tf הראשי של AWS.
קובץ ה-tf הראשי של AWS.
הקוד ללא ההערות צריך להיראות כך.
backend "s3" {
bucket = "<tf_state_bucket_name>"
key = "<environment_name>.tfstate"
region = "us-east-1"
}
אחרי שמסיימים את העדכונים, שומרים אותם ויוצאים מהעורך על ידי הקשה על esc -> :wq!. העדכונים יישמרו ב-main.tf.
לאחר מכן, משנים את השם של example.auto.tfvars ל-dev.auto.tfvars.
mv example.auto.tfvars dev.auto.tfvars
מעדכנים את dev.auto.tfvars ומקישים על i למשך input כדי לערוך את הקובץ.
vim dev.auto.tfvars
מעדכנים את השדות בתיבה האדומה בתמונה הבאה עם הפרמטרים הנכונים של AWS ARN שמופיעים בתהליך ההצטרפות ל-Aggregation Service, בסביבה ובאימייל של ההתראות.
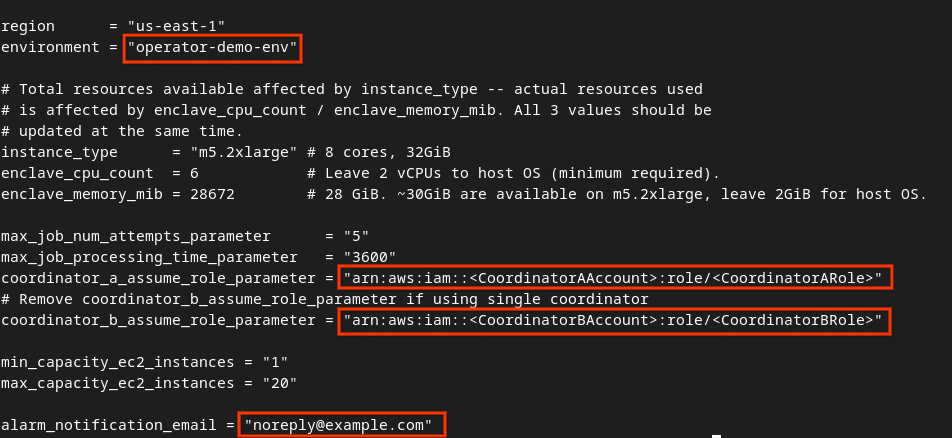 עורכים את קובץ ה-tfvars האוטומטי של הסביבה לפיתוח.
עורכים את קובץ ה-tfvars האוטומטי של הסביבה לפיתוח.
אחרי שהעדכונים מסתיימים, לוחצים על esc -> :wq!. הקובץ dev.auto.tfvars יישמר ויראה בערך כמו בתמונה הבאה.
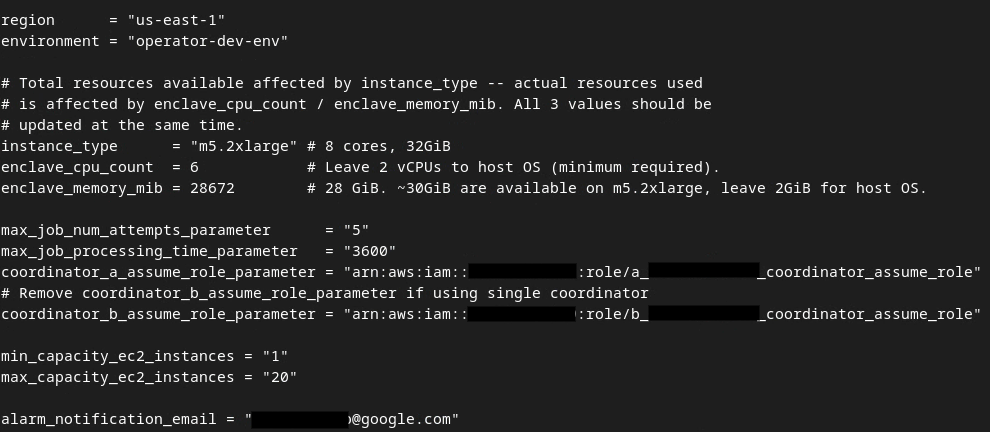 קובץ tfvars מעודכן של dev auto.
קובץ tfvars מעודכן של dev auto.
3.4. פריסת Aggregation Service
כדי לפרוס את Aggregation Service, מאתחלים את Terraform באותה תיקייה
terraform init
אמורה להתקבל תגובה שדומה לתמונה הבאה:
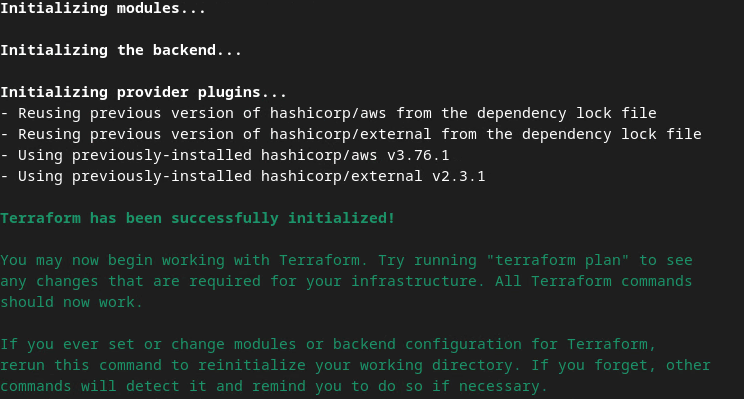 Terraform init.
Terraform init.
אחרי שמפעילים את Terraform, יוצרים את תוכנית הביצוע של Terraform. הפלט יכלול את מספר המשאבים שצריך להוסיף ומידע נוסף, כמו בדוגמה הבאה.
terraform plan
בקטע הבא מוצג סיכום של התוכנית. אם זה פריסה חדשה, אמור להופיע מספר המשאבים שיתווספו עם 0 לשינוי ו-0 להשמדה.
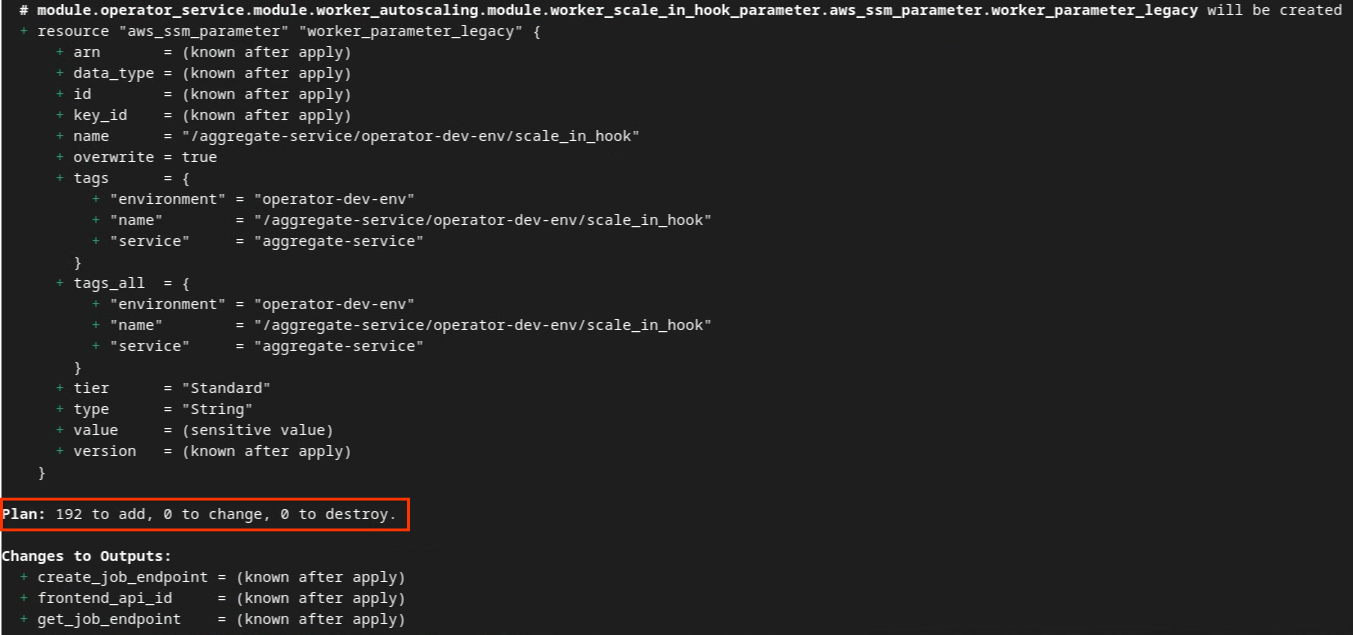 Terraform plan.
Terraform plan.
אחרי שתסיימו את השלב הזה, תוכלו להמשיך להפעלת Terraform.
terraform apply
כשמופיעה הנחיה לאשר את ביצוע הפעולות על ידי Terraform, מזינים yes בערך.
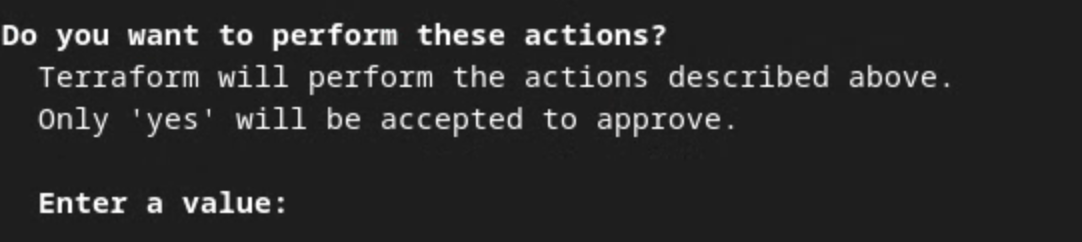 ההנחיה של Terraform apply.
ההנחיה של Terraform apply.
אחרי ש-terraform apply יסיים את הפעולה, יוחזרו נקודות הקצה הבאות עבור createJob ו-getJob. מוחזר גם frontend_api_id שצריך לעדכן ב-Postman בקטע 1.9.
 Terraform apply complete.
Terraform apply complete.
4. יצירת קלט ל-Aggregation Service
ממשיכים ליצירת דוחות AVRO לאיגוד בחבילות ב-Aggregation Service.
שלב 4. יצירת קלט ל-Aggregation Service: יצירת הדוחות של Aggregation Service שנשלחים בחבילות ל-Aggregation Service.
שלב 4.1. דוח על טריגרים
שלב 4.2. איסוף דוחות שניתן לצבור
שלב 4.3. המרת דוחות ל-AVRO
שלב 4.4. יצירת קובץ AVRO של דומיין הפלט
4.1. דוח טריגרים
עוברים לאתר הדמו של ארגז החול לפרטיות. הפעולה הזו מפעילה דוח צבירה פרטי. אפשר לראות את הדוח בכתובת chrome://private-aggregation-internals.
פרטים פנימיים על צבירה פרטית ב-Chrome.
אם הדוח שלכם במצב בהמתנה, אתם יכולים לבחור את הדוח וללחוץ על שליחת הדוחות שנבחרו. '
שליחת דוח צבירה פרטית.
4.2. איסוף דוחות מצטברים
אוספים את הדוחות שניתן לצבור מנקודות הקצה .well-known של ה-API המתאים.
- Private Aggregation
[reporting-origin] /.well-known/private-aggregation/report-shared-storage - דוחות שיוך (Attribution) – דוח סיכום
[reporting-origin] /.well-known/attribution-reporting/report-aggregate-attribution
ב-Codelab הזה תבצעו את איסוף הדוחות באופן ידני. בסביבת הייצור, ספקי טכנולוגיית פרסום צפויים לאסוף ולהמיר את הדוחות באופן פרוגרמטי.
ב-chrome://private-aggregation-internals, מעתיקים את גוף הדוח שהתקבל בנקודת הקצה [reporting-origin]/.well-known/private-aggregation/report-shared-storage.
מוודאים שב-Report Body (גוף הדוח), aggregation_coordinator_origin מכיל https://publickeyservice.msmt.aws.privacysandboxservices.com, כלומר הדוח הוא דוח ניתן לצבירה ב-AWS.
דוח של צבירת נתונים פרטית.
ממקמים את ה-JSON Report Body בקובץ JSON. בדוגמה הזו, אפשר להשתמש ב-vim. אבל אתם יכולים להשתמש בכל עורך טקסט שתרצו.
vim report.json
מדביקים את הדוח ב-report.json ושומרים את הקובץ.
קובץ JSON של הדוח.
4.3. המרת דוחות לפורמט AVRO
דוחות שמתקבלים מנקודות הקצה .well-known הם בפורמט JSON וצריך להמיר אותם לפורמט דוח AVRO. אחרי שיש לכם את דוח ה-JSON, עוברים לתיקיית הדוחות ומשתמשים ב-aggregatable_report_converter.jar כדי ליצור את הדוח המצטבר לניפוי באגים. הפעולה הזו יוצרת דוח שניתן לצבירה בשם report.avro בספרייה הנוכחית.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
4.4. יצירת קובץ AVRO של דומיין הפלט
כדי ליצור את הקובץ output_domain.avro, צריך את מפתחות ה-bucket שאפשר לאחזר מהדוחות.
מפתחות הדלי נוצרים על ידי טכנולוגיית הפרסום. עם זאת, במקרה הזה, מפתחות הדלי נוצרים על ידי הדמו של ארגז החול לפרטיות באתר. מכיוון ש-Private Aggregation באתר הזה נמצא במצב ניפוי באגים, אפשר להשתמש ב-debug_cleartext_payload מתוך גוף הדוח כדי לקבל את מפתח הדלי.
אפשר להעתיק את debug_cleartext_payload מגוף הדוח.
ניפוי באגים של מטען ייעודי (payload) בטקסט גלוי מגוף הדוח.
פותחים את goo.gle/ags-payload-decoder, מדביקים את debug_cleartext_payloadבתיבה INPUT ולוחצים על Decode (פענוח).
מפענח מטען ייעודי (payload).
הדף מחזיר את הערך העשרוני של מפתח הדלי. זוהי דוגמה למפתח קטגוריה.
תוצאה של פענוח מטען ייעודי (payload).
עכשיו, אחרי שיש לנו את מפתח הקטגוריה, אפשר ליצור את output_domain.avro. מוודאים שהחלפתם את
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
הסקריפט יוצר את הקובץ output_domain.avro בתיקייה הנוכחית.
4.5. העברת דוחות לקטגוריית AWS
אחרי שיוצרים את דוחות AVRO (מהקטע 3.2.3) ואת דומיין הפלט (מהקטע 3.2.4), ממשיכים להעברת הדוחות ודומיין הפלט אל דלי ה-S3 של הדוחות.
אם ה-AWS CLI מוגדר בסביבה המקומית שלכם, אתם יכולים להשתמש בפקודות הבאות כדי להעתיק את הדוחות לקטגוריית S3 ולתיקיית הדוחות המתאימות.
aws s3 cp report.avro s3://<report_bucket_name>/<report_folder>/
aws s3 cp output_domain.avro s3://<report_bucket_name>/<output_domain_folder>/
5. שימוש ב-Aggregation Service
מ-terraform apply, מקבלים בחזרה את create_job_endpoint, get_job_endpoint ואת frontend_api_id. מעתיקים את frontend_api_id ומציבים אותו במשתנה הגלובלי frontend_api_id של Postman שהגדרתם בסעיף 1.9 של הדרישות המוקדמות.
שלב 5. שימוש ב-Aggregation Service: משתמשים ב-Aggregation Service API כדי ליצור דוחות סיכום ולעיין בהם.
שלב 5.1. שימוש בנקודת הקצה createJob כדי להפעיל אצווה
שלב 5.2. שימוש בנקודת הקצה getJob לאחזור סטטוס של קבוצת קבצים
שלב 5.3. בדיקת דוח הסיכום
5.1. שימוש בנקודת קצה createJob כדי להוסיף קבוצות
ב-Postman, פותחים את האוסף ארגז החול לפרטיות ובוחרים באפשרות createJob.
בוחרים באפשרות Body (גוף) ואז באפשרות raw (גולמי) כדי למקם את מטען ייעודי (payload) הבקשה.
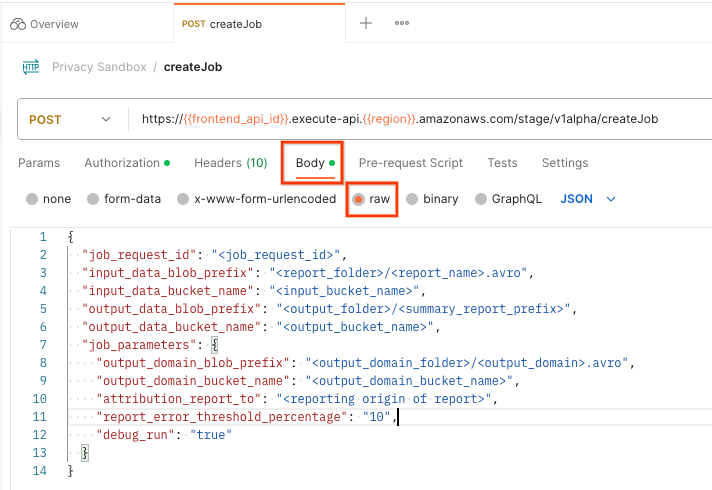 גוף הבקשה של Postman createJob
גוף הבקשה של Postman createJob
סכימת המטען הייעודי (payload) של createJob זמינה ב-github ונראית כך: מחליפים את <> בשדות המתאימים.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
], // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
אחרי שלוחצים על Send (שליחה), נוצרת המשימה עם job_request_id. אחרי ששירות הצבירה יאשר את הבקשה, תקבלו תגובה מסוג HTTP 202. אפשר למצוא קודי החזרה אפשריים אחרים בקודי תגובה של תגובת HTTP
 postman createJob request status
postman createJob request status
5.2. שימוש בנקודת הקצה getJob לאחזור הסטטוס של קבוצת קבצים
כדי לבדוק את הסטטוס של בקשת העבודה, אפשר להשתמש בנקודת הקצה getJob. בוחרים באפשרות getJob באוסף ארגז החול לפרטיות.
בפרמטר Params, מעדכנים את הערך של job_request_id ל-job_request_id שנשלח בבקשה createJob.
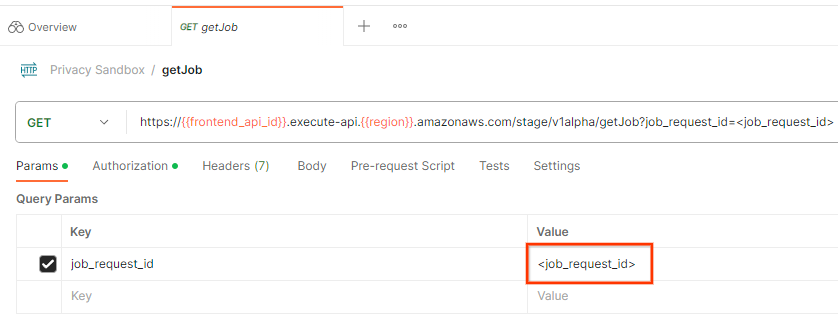 postman getJob request
postman getJob request
התוצאה של getJob צריכה להחזיר את הסטטוס של בקשת העבודה עם סטטוס HTTP של 200. הבקשה Body מכילה את המידע הנדרש כמו job_status, return_message ו-error_messages (אם העבודה נכשלה).
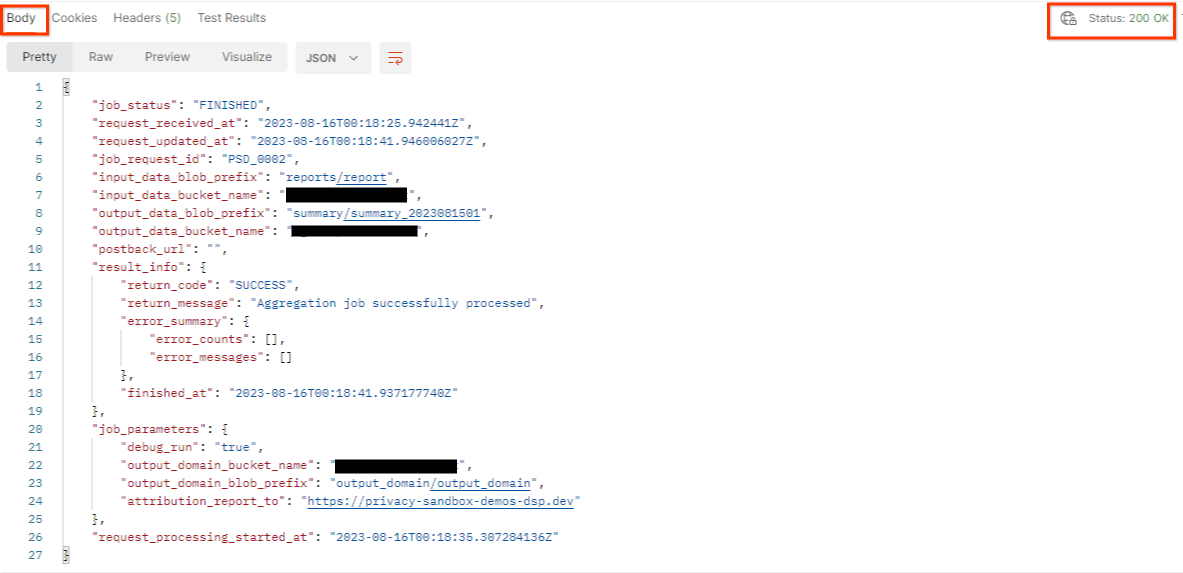 postman getJob request status
postman getJob request status
מאחר שאתר הדיווח של דוח ההדגמה שנוצר שונה מהאתר שנוסף למזהה AWS שלכם, יכול להיות שתקבלו תגובה עם PRIVACY_BUDGET_AUTHORIZATION_ERROR return_code. זה מצב תקין, כי האתר שממנו מגיע הדיווח בדוחות לא זהה לאתר שנוסף ל-AWS ID.
{
"job_status": "FINISHED",
"request_received_at": "2023-12-07T22:50:58.830956Z",
"request_updated_at": "2023-12-07T22:51:10.526326456Z",
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"postback_url": "",
"result_info": {
"return_code": "PRIVACY_BUDGET_AUTHORIZATION_ERROR",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-12-07T22:51:10.517730898Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"attribution_report_to": "https://privacy-sandbox-demos-dsp.dev",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
},
"request_processing_started_at": "2023-12-07T22:51:06.034472697Z"
}
5.3. בדיקת דוח הסיכום
אחרי שתקבלו את הדוח המסכם בקטגוריית S3 של הפלט, תוכלו להוריד אותו לסביבה המקומית. דוחות הסיכום הם בפורמט AVRO ואפשר להמיר אותם בחזרה ל-JSON. אפשר להשתמש בפקודה הבאה כדי לקרוא את הדוח באמצעות aggregatable_report_converter.jar.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
הפעולה הזו מחזירה JSON של ערכים מצטברים של כל מפתח bucket, שדומה לתמונה הבאה.
 דוח סיכום.
דוח סיכום.
אם הבקשה createJob כוללת את debug_run בתור true, תוכלו לקבל את דוח הסיכום בתיקיית ניפוי הבאגים שנמצאת ב-output_data_blob_prefix. הדוח הוא בפורמט AVRO ואפשר להמיר אותו ל-JSON באמצעות הפקודה הקודמת.
הדוח מכיל את מפתח הסיווג, את המדד ללא רעשי רקע ואת הרעש שנוסף למדד ללא רעשי רקע כדי ליצור את דוח הסיכום. הדוח אמור להיראות כך:
 דוח סיכום ניפוי הבאגים.
דוח סיכום ניפוי הבאגים.
ההערות כוללות גם את in_reports וin_domain, שמשמעותם:
- in_reports – מפתח הסיווג לקבוצה זמין בדוחות הניתנים לצבירה.
- in_domain – מפתח הקטגוריה זמין בקובץ הפלט output_domain AVRO.