
1. 前提条件
若要完成此 Codelab,您需要满足一些前提条件。每个要求都会相应地标记为“本地测试”或“汇总服务”所需的要求。
1.1. 下载本地测试工具(本地测试)
本地测试需要下载本地测试工具。该工具将根据未加密的调试报告生成摘要报告。
您可以在 GitHub 中的 Lambda JAR 归档中下载本地测试工具。应命名为 LocalTestingTool_{version}.jar。
1.2. 验证是否已安装 JAVA JRE(本地测试和汇总服务)
打开“终端”,然后使用 java --version 检查您的机器是否已安装 Java 或 openJDK。
 使用“java --version”检查 Java JRE 版本。
使用“java --version”检查 Java JRE 版本。
如果未安装,您可以从 Java 网站或 openJDK 网站下载并安装。
1.3. 下载可汇总报告转换器(本地测试和汇总服务)
您可以从 Privacy Sandbox 演示 GitHub 代码库下载可汇总报告转换器的副本。
1.4. 启用广告隐私权 API(本地测试和汇总服务)
在浏览器中,前往 chrome://settings/adPrivacy 并启用所有广告隐私权 API。
验证是否已启用第三方 Cookie。
在浏览器中,前往 chrome://settings/cookies,然后选择在无痕模式下阻止第三方 Cookie。
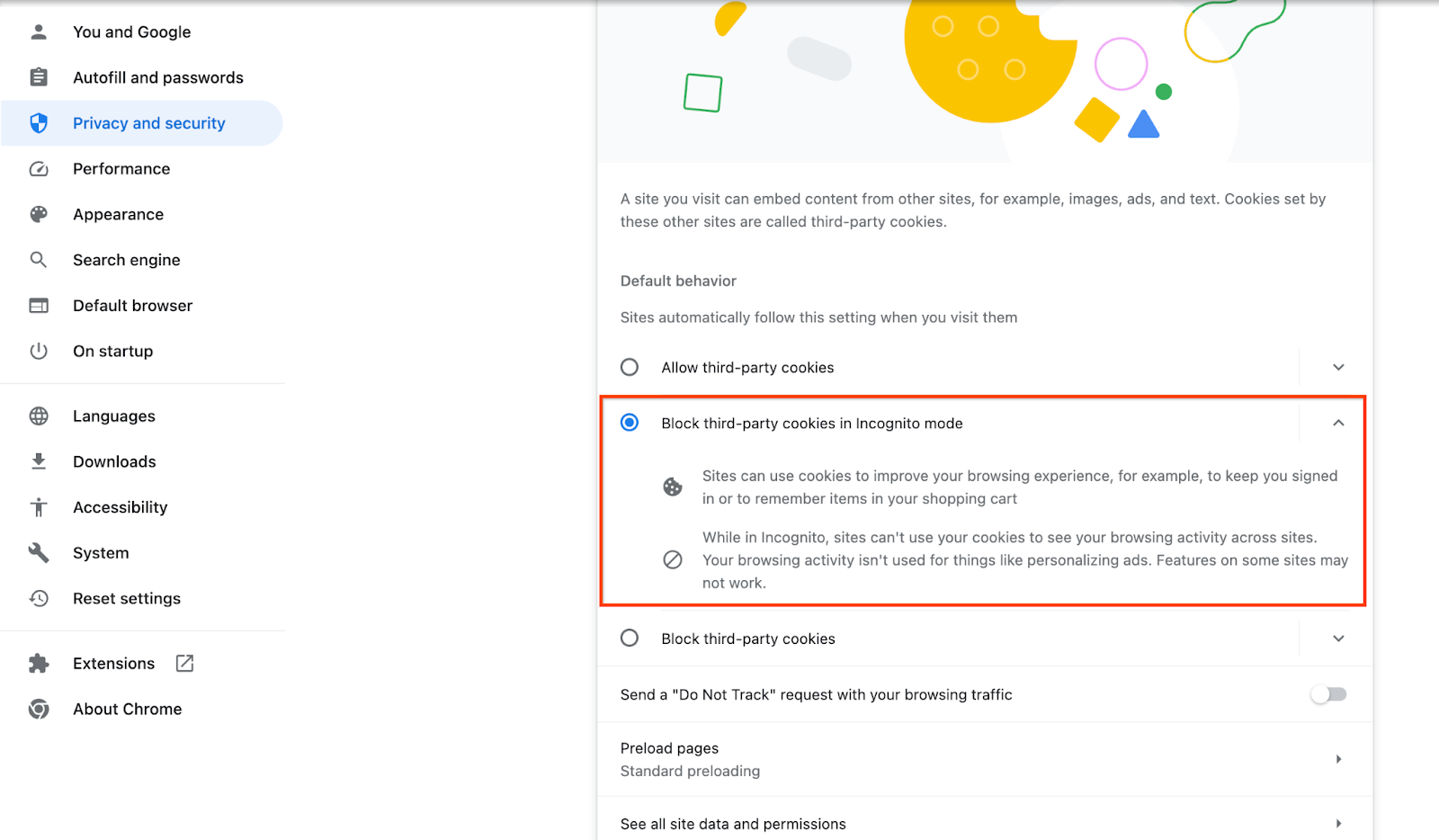 第三方 Cookie Chrome 设置。
第三方 Cookie Chrome 设置。
1.5. 网页版和 Android 版注册(汇总服务)
如需在生产环境中使用 Privacy Sandbox API,请务必完成 Chrome 和 Android 的注册和证明。
对于本地测试,可以使用 Chrome 标志和 CLI 开关停用注册。
如需使用 Chrome 标志进行演示,请前往 chrome://flags/#privacy-sandbox-enrollment-overrides 并使用您的网站更新替换项;如果您将使用我们的演示网站,则无需更新。
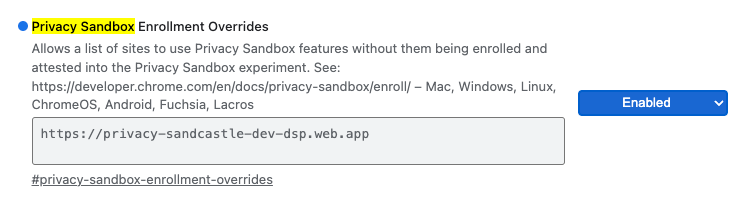 Privacy Sandbox 注册覆盖 Chrome 标志。
Privacy Sandbox 注册覆盖 Chrome 标志。
1.6. Aggregation Service 初始配置(Aggregation Service)
汇总服务需要加入协调器才能使用。填写汇总服务初始配置表单,提供您的报告网址、AWS 账号 ID 和其他信息。
1.7. 云提供商(汇总服务)
汇总服务需要使用可信执行环境,而该环境使用云环境。汇总服务在 Amazon Web Services (AWS) 和 Google Cloud (GCP) 上受支持。此 Codelab 仅介绍 AWS 集成。
AWS 提供了一种名为 Nitro Enclaves 的可信执行环境。验证您是否拥有 AWS 账号,并按照 AWS CLI 安装和更新说明设置 AWS CLI 环境。
如果您的 AWS CLI 是新安装的,您可以按照 CLI 配置说明配置 AWS CLI。
1.7.1. 创建 AWS S3 存储分区
创建一个 AWS S3 存储分区来存储 Terraform 状态,并创建另一个 S3 存储分区来存储报告和摘要报告。您可以使用提供的 CLI 命令。将 <> 中的字段替换为适当的变量。
aws s3api create-bucket --bucket <tf_bucket_name> --region us-east-1
aws s3api create-bucket --bucket <report_bucket_name> --region us-east-1
1.7.2. 创建用户访问密钥
使用 AWS 指南创建用户访问密钥。此变量将用于调用在 AWS 上创建的 createJob 和 getJob API 端点。
1.7.3. AWS 用户和群组权限
如需在 AWS 上部署汇总服务,您需要向用于部署服务的用户提供特定权限。在此 Codelab 中,请验证用户是否拥有管理员访问权限,以确保在部署中拥有完整权限。
1.8. Terraform(汇总服务)
此 Codelab 使用 Terraform 部署汇总服务。验证 Terraform 二进制文件是否已安装到本地环境中。
将 Terraform 二进制文件下载到本地环境。
下载 Terraform 二进制文件后,提取该文件并将 Terraform 二进制文件移到 /usr/local/bin 中。
cp <directory>/terraform /usr/local/bin
检查以确保 Terraform 在 classpath 上可用。
terraform -v
1.9. Postman(适用于汇总服务 AWS)
在此 Codelab 中,您将使用 Postman 来管理请求。
如需创建工作区,请前往顶部导航项“工作区”,然后选择“创建工作区”。
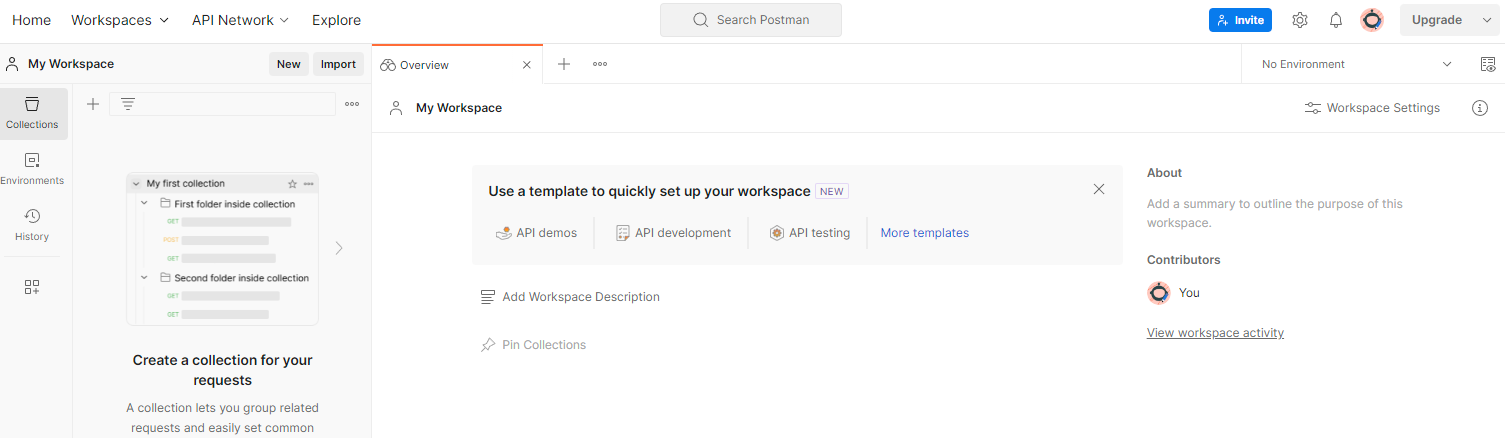 Postman 工作区
Postman 工作区
选择“空白工作区”,点击“下一步”,然后将其命名为“Privacy Sandbox”。选择“个人”,然后点击“创建”。
使用“导入”按钮将 JSON 文件导入到“我的工作区”。
 导入 Postman JSON 文件。
导入 Postman JSON 文件。
这会为您创建 Privacy Sandbox 集合以及 createJob 和 getJob HTTP 请求。
 Postman 导入的集合。
Postman 导入的集合。
通过“环境概览”更新 AWS“访问密钥”和“密钥”。
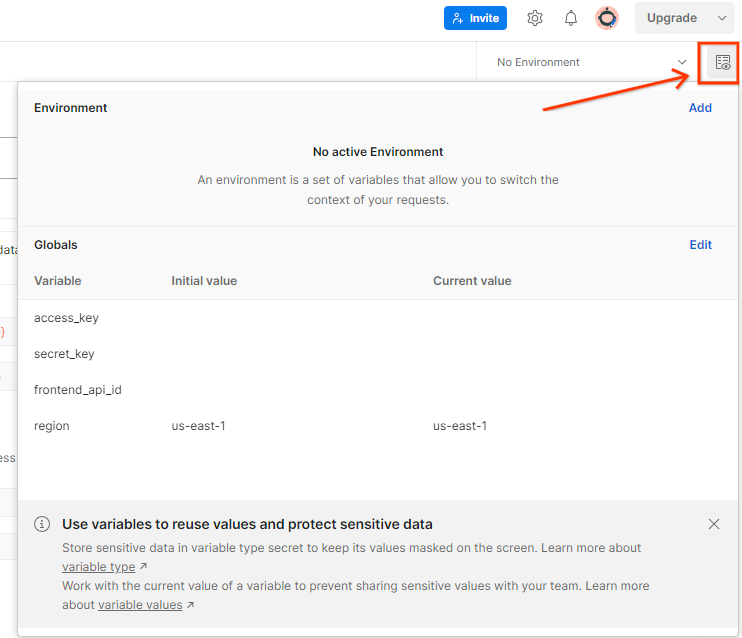 Postman 环境快速浏览。
Postman 环境快速浏览。
点击“修改”,然后更新“access_key”和“secret_key”的“当前值”。请注意,frontend_api_id 将在本文档的第 3.1.4 节中提供。我们建议您使用 us-east-1 区域。不过,如果您想在其他区域中部署,请验证您是否已将发布的 AMI 复制到您的账号中,或者使用提供的脚本执行了自建操作。
 Postman 全局变量。
Postman 全局变量。  Postman 编辑全局变量。
Postman 编辑全局变量。
2. 本地测试 Codelab
您可以使用本地测试工具在自己的机器上执行汇总,并使用未加密的调试报告生成摘要报告。
Codelab 步骤
第 2.1 步。触发报告:触发 Private Aggregation 报告,以便能够收集报告。
第 2.2 步:创建调试可汇总报告:将收集的 JSON 报告转换为 AVRO 格式的报告。
此步骤类似于广告技术平台从 API 报告端点收集报告并将 JSON 报告转换为 AVRO 格式的报告。
第 2.3 步。从调试报告中解析出分桶键:分桶键由广告技术平台设计。在此 Codelab 中,由于存储分区是预定义的,因此请按提供的形式检索存储分区键。
第 2.4 步。创建输出网域 AVRO:检索到存储分区密钥后,创建输出网域 AVRO 文件。
第 2.5 步。使用本地测试工具创建摘要报告:使用本地测试工具可在本地环境中创建摘要报告。
第 2.6 步。查看摘要报告:查看本地测试工具创建的摘要报告。
2.1. 触发报告
前往 Privacy Sandbox 演示网站。这会触发私密汇总报告。您可以在 chrome://private-aggregation-internals 中查看报告。
 Chrome 不公开汇总内部信息。
Chrome 不公开汇总内部信息。
如果您的报告处于“待处理”状态,您可以选择该报告,然后点击“发送所选报告”。
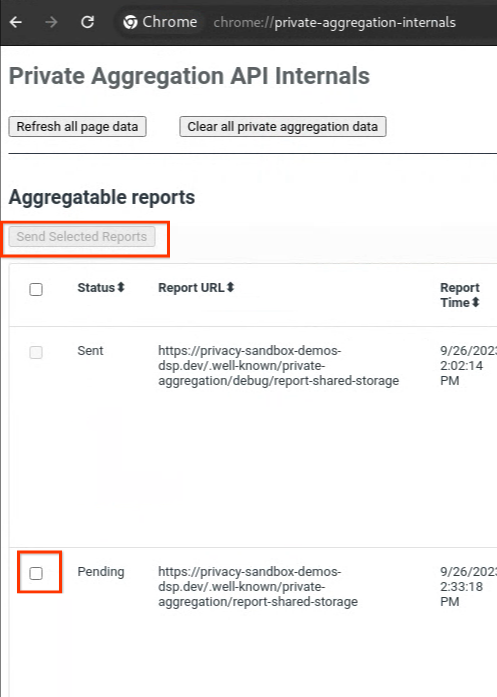 发送私密汇总报告。
发送私密汇总报告。
2.2. 创建调试可汇总报告
在 chrome://private-aggregation-internals 中,复制在 [reporting-origin]/.well-known/private-aggregation/report-shared-storage 端点收到的“报告正文”。
确保在“报告正文”中,aggregation_coordinator_origin 包含 https://publickeyservice.msmt.aws.privacysandboxservices.com,这意味着该报告是 AWS 可汇总报告。
 私密汇总报告。
私密汇总报告。
将 JSON“报告正文”放在 JSON 文件中。在此示例中,您可以使用 vim。不过,您可以使用任何所需的文本编辑器。
vim report.json
将报告粘贴到 report.json 中,然后保存文件。
 报告 JSON 文件。
报告 JSON 文件。
获得该数据后,前往报告文件夹,然后使用 aggregatable_report_converter.jar 帮助创建调试可汇总报告。此命令会在当前目录中创建一个名为 report.avro 的可汇总报告。
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. 从调试报告中解析出分桶键
在批处理时,汇总服务需要两个文件。可汇总报告和输出网域文件。输出网域文件包含您希望从可汇总报告中检索的键。如需创建 output_domain.avro 文件,您需要可从报告中检索到的存储分区键。
存储分区密钥由 API 的调用方设计,而 demo 包含预先构建的存储分区密钥示例。由于演示已为私密聚合启用调试模式,因此您可以从“报告正文”中解析调试明文载荷,以检索分桶键。不过,在这种情况下,网站 Privacy Sandbox 演示会创建分桶密钥。由于此网站的 Private Aggregation 处于调试模式,因此您可以使用“报告正文”中的 debug_cleartext_payload 获取分桶键。
从报告正文中复制 debug_cleartext_payload。
 调试来自报告正文的明文载荷。
调试来自报告正文的明文载荷。
打开私密汇总的调试载荷解码器工具,将 debug_cleartext_payload 粘贴到“输入”框中,然后点击“解码”。
 载荷解码器。
载荷解码器。
该网页会返回分桶键的十进制值。以下是存储分区密钥示例。
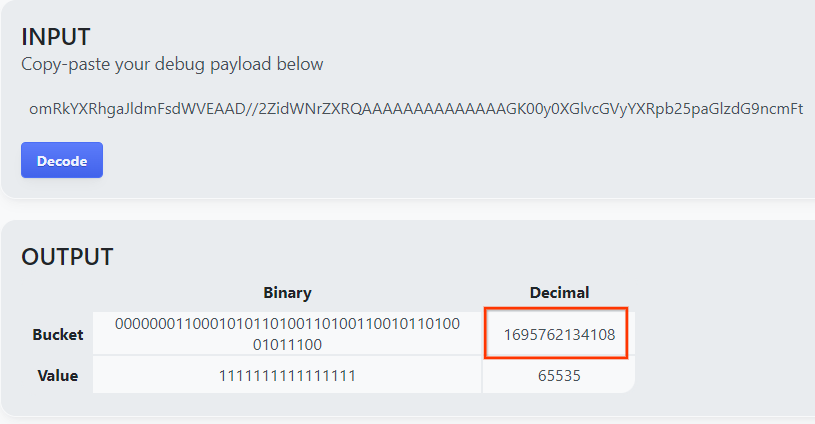 载荷解码器结果。
载荷解码器结果。
2.4. 创建输出网域 AVRO
现在我们已经有了分桶键,接下来复制分桶键的十进制值。继续使用存储分区密钥创建 output_domain.avro。请务必将
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
该脚本会在当前文件夹中创建 output_domain.avro 文件。
2.5. 使用本地测试工具创建摘要报告
我们将使用第 1.1 节中下载的 LocalTestingTool_{version}.jar 来创建摘要报告。使用以下命令。您应将 LocalTestingTool_{version}.jar 替换为为 LocalTestingTool 下载的版本。
运行以下命令,在本地开发环境中生成摘要报告:
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
运行该命令后,您应该会看到类似下图的内容。完成后,系统会生成一份报告 output.avro。
 本地测试摘要报告 avro 文件。
本地测试摘要报告 avro 文件。
2.6. 查看摘要报告
创建的摘要报告采用 AVRO 格式。为了能够读取此文件,您需要将其从 AVRO 格式转换为 JSON 格式。理想情况下,广告技术平台应编写代码将 AVRO 报告转换回 JSON。
在此 Codelab 中,我们将使用提供的 aggregatable_report_converter.jar 工具将 AVRO 报告转换回 JSON。
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
这会返回类似于下图的报告。以及在同一目录中创建的报告 output.json。
 已转换为 JSON 的摘要 avro 文件。
已转换为 JSON 的摘要 avro 文件。
在您选择的编辑器中打开 JSON 文件,以查看摘要报告。
3. Aggregation Service 部署
如需部署汇总服务,请按以下步骤操作:
第 3 步:Aggregation Service 部署:在 AWS 上部署 Aggregation Service
步骤 3.1.克隆 Aggregation Service 代码库
第 3.2 步。下载预构建的依赖项
第 3.3 步。创建开发环境
第 3.4 步。部署 Aggregation Service
3.1. 克隆 Aggregation Service 代码库
在本地环境中,克隆 Aggregation Service Github 代码库。
git clone https://github.com/privacysandbox/aggregation-service.git
3.2. 下载预构建的依赖项
克隆 Aggregation Service 代码库后,前往该代码库的 Terraform 文件夹和相应的云文件夹。如果您的 cloud_provider 是 AWS,您可以继续执行
cd <repository_root>/terraform/aws
在 download_prebuilt_dependencies.sh。
bash download_prebuilt_dependencies.sh
3.3. 创建开发环境
在 dev 的文件夹。
mkdir dev
将 demo 文件夹的内容复制到 dev 文件夹中。
cp -R demo/* dev
移至 dev 文件夹。
cd dev
更新 main.tf 文件,然后按 i(对于 input)以修改文件。
vim main.tf
取消红色框中代码的注释,方法是移除 # 并更新存储分区和密钥名称。
对于 AWS main.tf:
 AWS main tf 文件。
AWS main tf 文件。
未注释的代码应如下所示。
backend "s3" {
bucket = "<tf_state_bucket_name>"
key = "<environment_name>.tfstate"
region = "us-east-1"
}
更新完成后,按 esc -> :wq! 保存更新并退出编辑器。这样即可在 main.tf 上保存更新。
接下来,将 example.auto.tfvars 重命名为 dev.auto.tfvars。
mv example.auto.tfvars dev.auto.tfvars
更新 dev.auto.tfvars 并按 i(针对 input)以修改文件。
vim dev.auto.tfvars
请使用在汇总服务初始配置、环境和通知电子邮件中提供的正确 AWS ARN 参数更新下图红框中的字段。
 修改开发自动 TFVARS 文件。
修改开发自动 TFVARS 文件。
更新完成后,按 esc -> :wq!。这样便保存了 dev.auto.tfvars 文件,该文件应如下图所示。
 更新了开发自动 TFVARS 文件。
更新了开发自动 TFVARS 文件。
3.4. 部署 Aggregation Service
如需部署 Aggregation Service,请在同一文件夹
terraform init
此操作应该会返回类似于下图的内容:
 Terraform init。
Terraform init。
初始化 Terraform 后,创建 Terraform 执行计划。其中,它会返回要添加的资源数量和其他附加信息,类似于下图。
terraform plan
您可以在下图中看到“方案”摘要。如果这是全新部署,您应该会看到要添加的资源数量,以及要更改和销毁的资源数量(均为 0)。
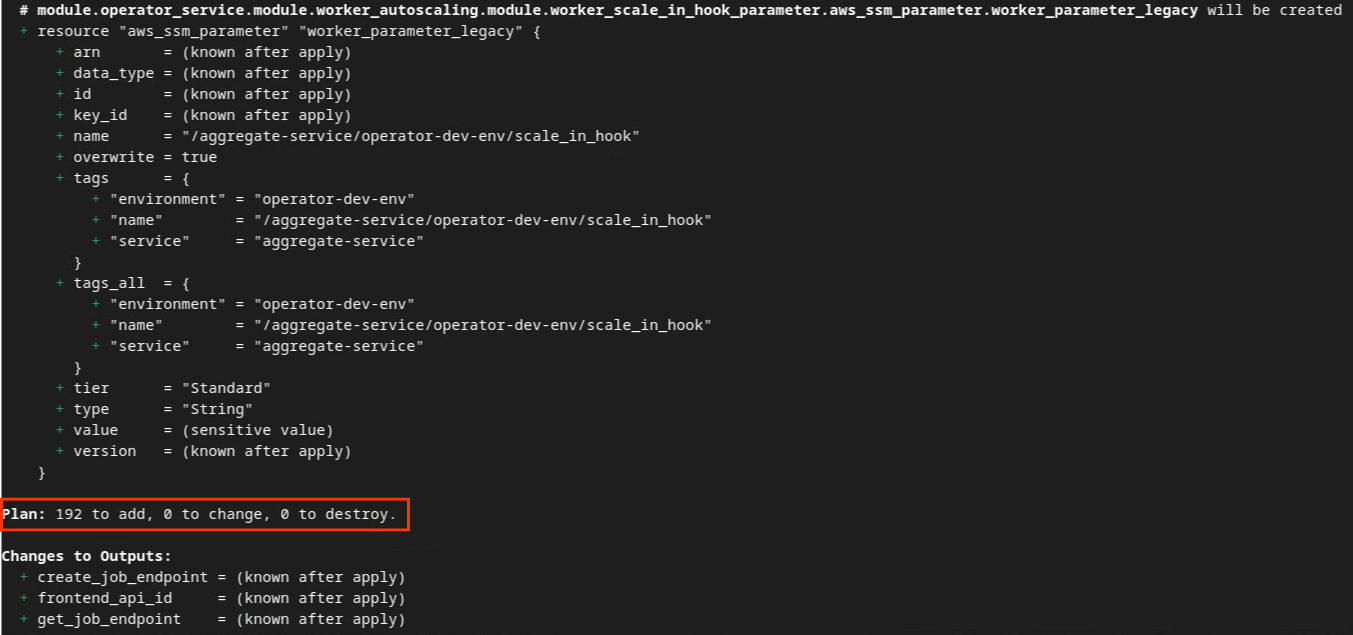 Terraform 方案。
Terraform 方案。
完成此操作后,您就可以继续应用 Terraform 了。
terraform apply
当系统提示您确认是否要通过 Terraform 执行操作时,请输入 yes 作为值。
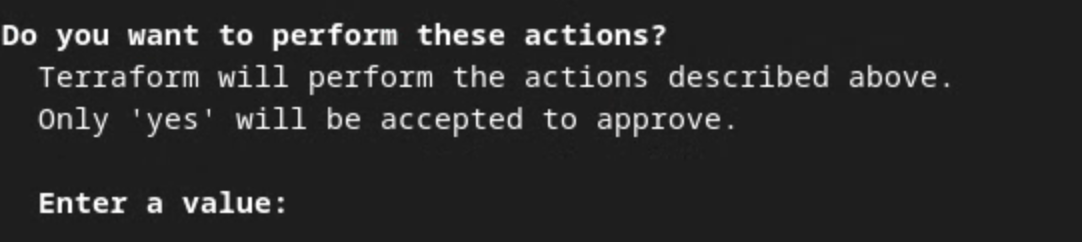 Terraform apply 提示。
Terraform apply 提示。
terraform apply 完成后,系统会返回 createJob 和 getJob 的以下端点。系统还会返回您需要在 Postman 中更新的 1.9 部分中的 frontend_api_id。
 Terraform apply complete.
Terraform apply complete.
4. 创建 Aggregation Service 输入
继续创建 AVRO 报告,以便在汇总服务中进行批处理。
第 4 步:创建 Aggregation Service 输入:创建为 Aggregation Service 批处理的 Aggregation Service 报告。
第 4.1 步。触发器报告
第 4.2 步。收集可汇总报告
第 4.3 步。将报告转换为 AVRO
步骤 4.4.创建输出网域 AVRO
4.1. 触发报告
前往 Privacy Sandbox 演示网站。这会触发私密汇总报告。您可以在 chrome://private-aggregation-internals 中查看报告。
Chrome 不公开汇总内部信息。
如果您的报告处于“待处理”状态,您可以选择该报告,然后点击“发送所选报告”。'
发送私密汇总报告。
4.2. 收集可汇总报告
从相应 API 的 .well-known 端点收集可汇总报告。
- Private Aggregation
[reporting-origin] /.well-known/private-aggregation/report-shared-storage - Attribution Reporting - 摘要报告
[reporting-origin] /.well-known/attribution-reporting/report-aggregate-attribution
在此 Codelab 中,您将手动执行报告集合。在生产环境中,广告技术平台应以程序化方式收集和转换报告。
在 chrome://private-aggregation-internals 中,复制在 [reporting-origin]/.well-known/private-aggregation/report-shared-storage 端点收到的“报告正文”。
确保在“报告正文”中,aggregation_coordinator_origin 包含 https://publickeyservice.msmt.aws.privacysandboxservices.com,这意味着该报告是 AWS 可汇总报告。
私密汇总报告。
将 JSON“报告正文”放在 JSON 文件中。在此示例中,您可以使用 vim。不过,您可以使用任何所需的文本编辑器。
vim report.json
将报告粘贴到 report.json 中,然后保存文件。
报告 JSON 文件。
4.3. 将报告转换为 AVRO 格式
从 .well-known 端点收到的报告为 JSON 格式,需要转换为 AVRO 报告格式。获得 JSON 报告后,前往报告文件夹,然后使用 aggregatable_report_converter.jar 帮助创建调试可汇总报告。此命令会在当前目录中创建一个名为 report.avro 的可汇总报告。
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
4.4. 创建输出网域 AVRO
如需创建 output_domain.avro 文件,您需要可从报告中检索到的存储分区键。
分桶键由广告技术平台设计。不过,在本例中,分桶键由网站 Privacy Sandbox 演示创建。由于此网站的 Private Aggregation 处于调试模式,因此您可以使用“报告正文”中的 debug_cleartext_payload 获取分桶键。
请继续操作,从报告正文中复制 debug_cleartext_payload。
调试来自报告正文的明文载荷。
打开 goo.gle/ags-payload-decoder,将 debug_cleartext_payload粘贴到“INPUT”框中,然后点击“Decode”。
载荷解码器。
该网页会返回分桶键的十进制值。以下是存储分区密钥示例。
载荷解码器结果。
现在我们有了存储分区密钥,接下来可以创建 output_domain.avro 了。请务必将
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
该脚本会在当前文件夹中创建 output_domain.avro 文件。
4.5. 将报告移至 AWS 存储分区
创建 AVRO 报告(来自第 3.2.3 节)和输出网域(来自第 3.2.4 节)后,继续将报告和输出网域移至报告 S3 存储分区。
如果您已在本地环境中设置 AWS CLI,请使用以下命令将报告复制到相应的 S3 存储分区和报告文件夹。
aws s3 cp report.avro s3://<report_bucket_name>/<report_folder>/
aws s3 cp output_domain.avro s3://<report_bucket_name>/<output_domain_folder>/
5. Aggregation Service 用量
从 terraform apply 中,系统会返回 create_job_endpoint、get_job_endpoint 和 frontend_api_id。复制 frontend_api_id,然后将其放入您在前提条件部分 1.9 中设置的 Postman 全局变量 frontend_api_id 中。
第 5 步:汇总服务使用情况:使用 Aggregation Service API 创建摘要报告并查看摘要报告。
第 5.1 步。使用 createJob 端点批量执行
第 5.2 步。使用 getJob 端点检索批处理状态
步骤 5.3.查看摘要报告
5.1. 使用 createJob 端点进行批量处理
在 Postman 中,打开“Privacy Sandbox”集合,然后选择“createJob”。
选择“正文”,然后选择“原始”以放置请求载荷。
 postman createJob 请求正文
postman createJob 请求正文
createJob 载荷架构可在 GitHub 中找到,类似于以下内容。将 <> 替换为适当的字段。
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
], // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
点击“发送”后,系统会使用 job_request_id 创建作业。当汇总服务接受请求后,您应该会收到 HTTP 202 响应。如需了解其他可能的返回代码,请参阅 HTTP 响应代码
 postman createJob 请求状态
postman createJob 请求状态
5.2. 使用 getJob 端点检索批处理状态
如需检查作业请求的状态,您可以使用 getJob 端点。在“Privacy Sandbox”集合中选择“getJob”。
在“Params”中,将 job_request_id 值更新为 createJob 请求中发送的 job_request_id。
 postman getJob 请求
postman getJob 请求
getJob 的结果应返回作业请求的状态,并显示 HTTP 状态 200。请求“正文”包含必要的信息,例如 job_status、return_message 和 error_messages(如果作业出错)。
 postman getJob 请求状态
postman getJob 请求状态
由于生成的演示报告的报告网站与您在 AWS ID 中已完成初始配置的网站不同,因此您可能会收到包含 PRIVACY_BUDGET_AUTHORIZATION_ERROR 的响应。这是正常现象,因为报告的报告来源网站与为 AWS ID 启用的报告网站不一致。
{
"job_status": "FINISHED",
"request_received_at": "2023-12-07T22:50:58.830956Z",
"request_updated_at": "2023-12-07T22:51:10.526326456Z",
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"postback_url": "",
"result_info": {
"return_code": "PRIVACY_BUDGET_AUTHORIZATION_ERROR",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-12-07T22:51:10.517730898Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"attribution_report_to": "https://privacy-sandbox-demos-dsp.dev",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
},
"request_processing_started_at": "2023-12-07T22:51:06.034472697Z"
}
5.3. 查看摘要报告
在输出 S3 存储分区中收到摘要报告后,您可以将其下载到本地环境。摘要报告采用 AVRO 格式,可以转换回 JSON 格式。您可以使用 aggregatable_report_converter.jar 通过以下命令读取报告。
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
此函数会返回一个 JSON,其中包含每个分桶键的汇总值,类似于下图。
 摘要报告。
摘要报告。
如果您的 createJob 请求包含 debug_run(作为 true),那么您可以在 output_data_blob_prefix 中的调试文件夹内收到摘要报告。报告采用 AVRO 格式,可以使用之前的命令将其转换为 JSON 格式。
报告包含以下内容:分桶键、未添加噪声的指标,以及为形成汇总报告而添加到未添加噪声的指标中的噪声。报告类似于下图。
 调试摘要报告。
调试摘要报告。
注释还包含 in_reports 和 in_domain,这意味着:
- in_reports - 桶键可在可汇总报告中使用。
- in_domain - 存储分区密钥位于 output_domain AVRO 文件中。