
1. Предварительные требования
Для выполнения этого практического задания требуется выполнить несколько предварительных условий. Каждое требование отмечено в зависимости от того, требуется ли оно для «локального тестирования» или для «агрегационного сервиса».
1.1. Загрузите инструмент локального тестирования (Local Testing)
Для локального тестирования потребуется загрузить инструмент локального тестирования. Этот инструмент будет генерировать сводные отчеты на основе незашифрованных отладочных отчетов.
Инструмент локального тестирования доступен для загрузки в архиве JAR-файлов Lambda на Github . Его следует назвать LocalTestingTool_{version}.jar .
1.2. Убедитесь, что Java JRE установлена (служба локального тестирования и агрегации).
Откройте « Терминал » и используйте java --version , чтобы проверить, установлены ли на вашем компьютере Java или OpenJDK.
 Проверка версии Java JRE с помощью команды `java --version`.
Проверка версии Java JRE с помощью команды `java --version`.
Если он не установлен, вы можете загрузить и установить его с сайта Java или сайта openJDK .
1.3. Скачать конвертер агрегируемых отчетов (сервис локального тестирования и агрегирования)
Вы можете скачать копию конвертера агрегируемых отчетов из репозитория Privacy Sandbox Demos на Github .
1.4. Включите API для обеспечения конфиденциальности рекламы (сервис локального тестирования и агрегации).
В браузере перейдите по адресу chrome://settings/adPrivacy и включите все API для защиты конфиденциальности рекламы.
Убедитесь, что сторонние файлы cookie включены.
В браузере перейдите по адресу chrome://settings/cookies и выберите « Блокировать сторонние файлы cookie в режиме инкогнито ».
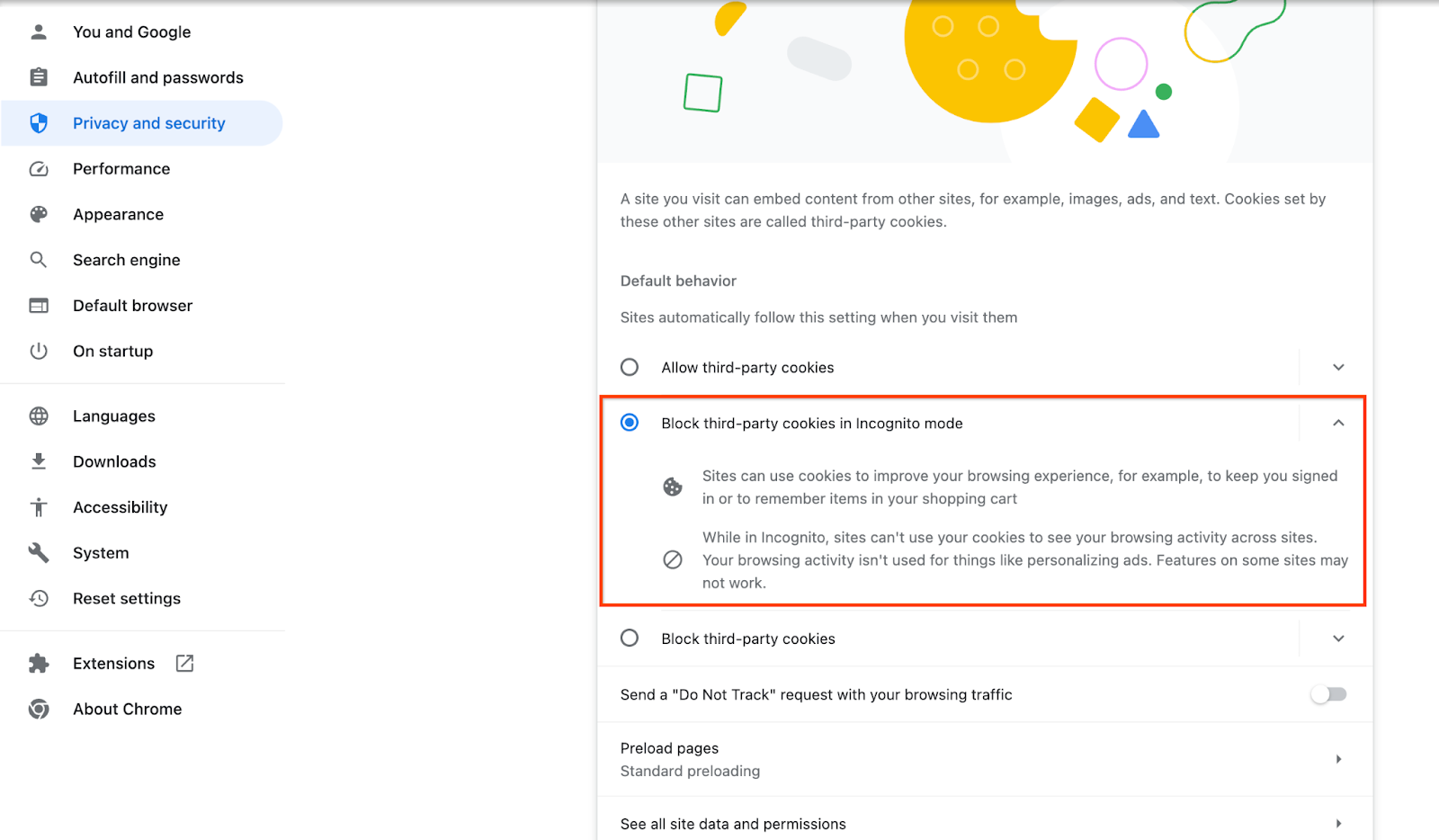 Настройки Chrome для сторонних файлов cookie.
Настройки Chrome для сторонних файлов cookie.
1.5. Регистрация через веб-браузер и Android (сервис агрегации)
Для использования API Privacy Sandbox в рабочей среде убедитесь, что вы завершили регистрацию и аттестацию как для Chrome, так и для Android.
Для локального тестирования регистрацию можно отключить с помощью флага Chrome и параметра командной строки .
Чтобы использовать флаг Chrome для нашей демонстрации, перейдите по chrome://flags/#privacy-sandbox-enrollment-overrides и обновите значение параметра override, указав адрес вашего сайта. Если же вы будете использовать наш демонстрационный сайт, обновление не требуется.
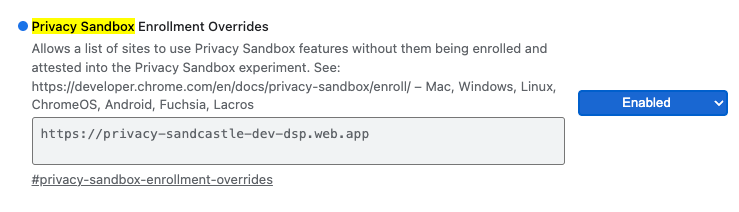 Переопределение флага Chrome для регистрации в песочнице конфиденциальности.
Переопределение флага Chrome для регистрации в песочнице конфиденциальности.
1.6. Подключение к сервису агрегации (Сервис агрегации)
Для использования сервиса агрегации координаторам необходимо пройти процедуру регистрации. Заполните форму регистрации в сервисе агрегации , указав адрес вашего сайта для формирования отчетов, идентификатор учетной записи AWS и другую информацию.
1.7. Поставщик облачных услуг (агрегационная услуга)
Для работы сервиса агрегации требуется доверенная среда выполнения, использующая облачную среду. Сервис агрегации поддерживается в Amazon Web Services (AWS) и Google Cloud (GCP). В данном практическом занятии будет рассмотрена только интеграция с AWS.
AWS предоставляет доверенную среду выполнения под названием Nitro Enclaves. Убедитесь, что у вас есть учетная запись AWS, и следуйте инструкциям по установке и обновлению AWS CLI для настройки среды AWS CLI.
Если вы новичок в AWS CLI, вы можете настроить его, используя инструкции по настройке CLI .
1.7.1. Создание корзины AWS S3
Создайте корзину AWS S3 для хранения состояния Terraform и еще одну корзину S3 для хранения отчетов и сводных отчетов. Вы можете использовать предоставленную команду CLI. Замените поле в <> на соответствующие переменные.
aws s3api create-bucket --bucket <tf_bucket_name> --region us-east-1
aws s3api create-bucket --bucket <report_bucket_name> --region us-east-1
1.7.2. Создание ключа доступа пользователя
Создайте ключи доступа пользователей, используя руководство AWS . Они будут использоваться для вызова API-интерфейсов createJob и getJob , созданных в AWS.
1.7.3. Права доступа пользователей и групп AWS
Для развертывания сервиса агрегации на AWS вам потребуется предоставить пользователю, используемому для развертывания сервиса, определенные права доступа. В этом примере убедитесь, что у пользователя есть права администратора, чтобы гарантировать полные права доступа при развертывании.
1.8. Terraform (сервис агрегации)
В этом практическом занятии используется Terraform для развертывания сервиса агрегации. Убедитесь, что исполняемый файл Terraform установлен в вашей локальной среде.
Загрузите исполняемый файл Terraform в свою локальную среду.
После загрузки исполняемого файла Terraform распакуйте его и переместите в каталог /usr/local/bin .
cp <directory>/terraform /usr/local/bin
Убедитесь, что Terraform доступен в classpath.
terraform -v
1.9. Postman (для сервиса агрегации AWS)
Для выполнения этого практического задания используйте Postman для управления запросами.
Чтобы создать рабочее пространство, перейдите в раздел « Рабочие пространства » в верхней панели навигации и выберите « Создать рабочее пространство ».
 рабочее место почтальона
рабочее место почтальона
Выберите « Пустое рабочее пространство », нажмите «Далее» и назовите его « Песочница конфиденциальности ». Выберите « Личное » и нажмите « Создать ».
Загрузите предварительно настроенные файлы конфигурации рабочего пространства в формате JSON и файлы глобальной среды .
Импортируйте JSON-файлы в раздел « Моя рабочая область » с помощью кнопки « Импорт ».
 Импортируйте JSON-файлы в Postman.
Импортируйте JSON-файлы в Postman.
Это создаст для вас коллекцию Privacy Sandbox, а также HTTP-запросы createJob и getJob .
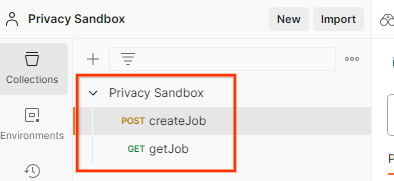 Коллекция, привезенная почтальоном.
Коллекция, привезенная почтальоном.
Обновите ключ доступа AWS и секретный ключ через функцию « Быстрый просмотр среды ».
 Краткий обзор среды Postman.
Краткий обзор среды Postman.
Нажмите « Редактировать » и обновите «Текущее значение» для параметров « access_key » и « secret_key ». Обратите внимание, что frontend_api_id будет указан в разделе 3.1.4 этого документа. Мы рекомендуем использовать регион us-east-1. Однако, если вы хотите развернуть приложение в другом регионе, убедитесь, что вы скопировали выпущенный AMI в свою учетную запись, или выполните самостоятельную сборку, используя предоставленные скрипты .
 Глобальные переменные Postman.
Глобальные переменные Postman. 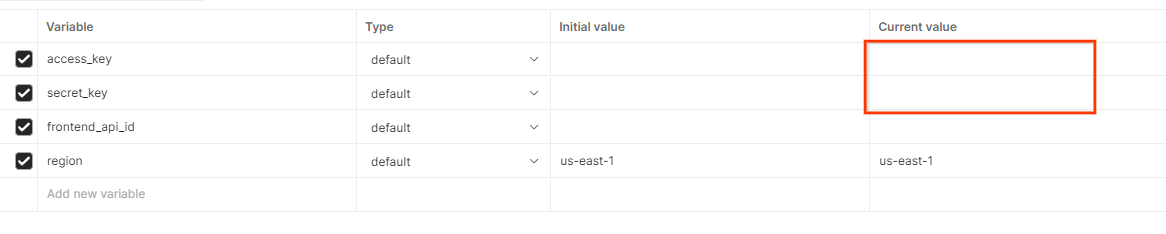 Редактирование глобальных переменных в Postman.
Редактирование глобальных переменных в Postman.
2. Лаборатория локального тестирования
Вы можете использовать локальный инструмент тестирования на своем компьютере для выполнения агрегирования данных и создания сводных отчетов на основе незашифрованных отладочных отчетов.
Этапы Codelab
Шаг 2.1. Запуск отчета : Запустите формирование отчета на основе частной агрегации данных, чтобы иметь возможность собрать отчет.
Шаг 2.2. Создание сводного отладочного отчета : преобразуйте собранный JSON-отчет в отчет в формате AVRO.
Этот шаг будет аналогичен тому, как специалисты по рекламным технологиям собирают отчеты из API-интерфейсов и преобразуют отчеты в формате JSON в отчеты в формате AVRO.
Шаг 2.3. Извлечение ключа корзины из отладочного отчета : Ключи корзин разрабатываются специалистами по рекламным технологиям. В этом практическом задании, поскольку корзины предопределены, извлеките ключи корзин в том виде, в котором они предоставлены.
Шаг 2.4. Создание выходного домена AVRO : После получения ключей сегментов создайте файл выходного домена AVRO.
Шаг 2.5. Создание сводных отчетов с помощью инструмента локального тестирования : Используйте инструмент локального тестирования, чтобы иметь возможность создавать сводные отчеты в локальной среде.
Шаг 2.6. Просмотрите сводный отчет : Просмотрите сводный отчет, созданный инструментом локального тестирования.
2.1. Отчет о триггере
Перейдите на демонстрационный сайт песочницы конфиденциальности . Это запустит отчет о приватной агрегации. Вы можете просмотреть отчет по адресу chrome://private-aggregation-internals .
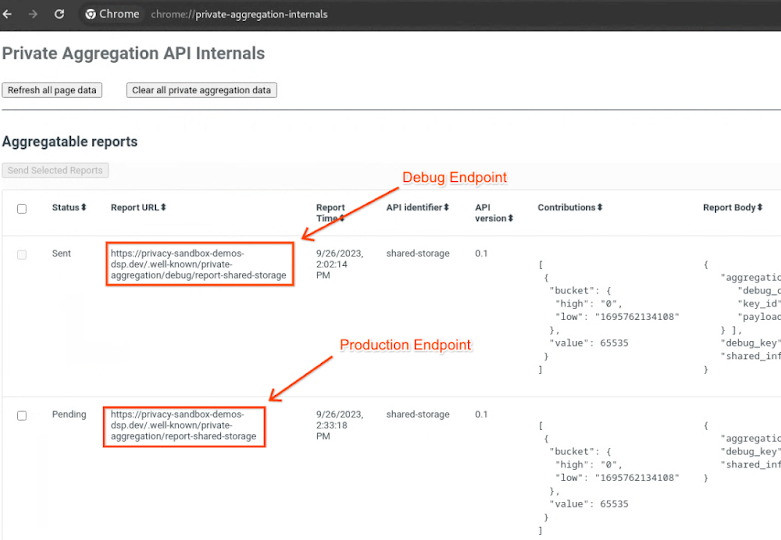 Внутренние механизмы частной агрегации Chrome.
Внутренние механизмы частной агрегации Chrome.
Если ваш отчет находится в статусе « В ожидании », вы можете выбрать отчет и нажать « Отправить выбранные отчеты ».
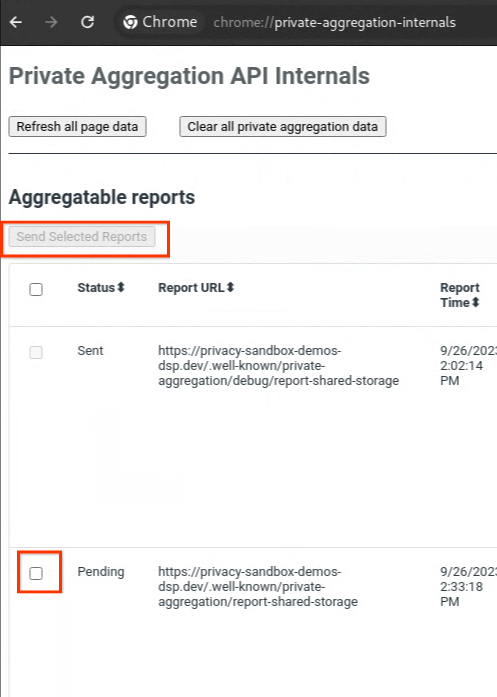 Отправить частный сводный отчет.
Отправить частный сводный отчет.
2.2. Создание сводного отладочного отчета.
В chrome://private-aggregation-internals скопируйте " Тело отчета ", полученное в конечной точке [reporting-origin]/.well-known/private-aggregation/report-shared-storage .
Убедитесь, что в поле " Тело отчета " параметр aggregation_coordinator_origin содержит https://publickeyservice.msmt.aws.privacysandboxservices.com , что означает, что отчет является агрегируемым отчетом AWS.
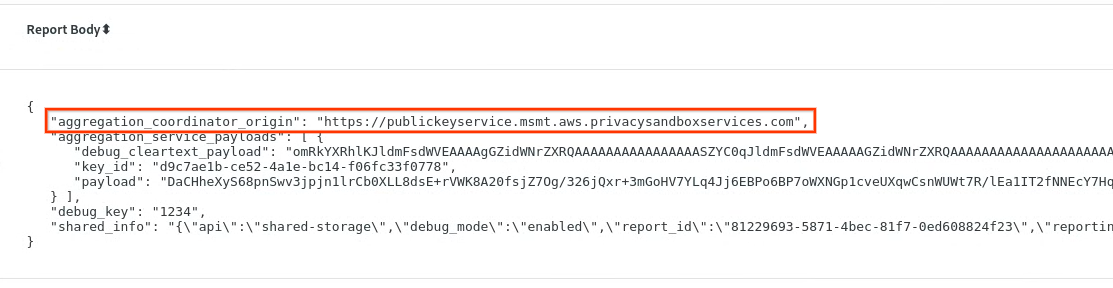 Отчет о частном агрегировании.
Отчет о частном агрегировании.
Поместите JSON-текст " Report Body " в JSON-файл. В этом примере можно использовать vim, но вы можете использовать любой текстовый редактор по своему усмотрению.
vim report.json
Вставьте отчет в файл report.json и сохраните его.
 Отчет в формате JSON.
Отчет в формате JSON.
После этого перейдите в папку с отчетами и используйте aggregatable_report_converter.jar для создания отладочного агрегируемого отчета. Это создаст агрегируемый отчет с именем report.avro в текущем каталоге.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Анализ ключа корзины из отладочного отчета.
Для пакетной обработки данных сервису агрегации требуются два файла: файл агрегируемого отчета и файл выходного домена. Файл выходного домена содержит ключи, которые необходимо получить из агрегируемых отчетов. Для создания файла output_domain.avro необходимы ключи сегментов, которые можно получить из отчетов.
Ключи сегментов создаются вызывающей стороной API, и демонстрационная версия содержит предварительно созданные примеры ключей сегментов. Поскольку в демонстрационной версии включен режим отладки для частной агрегации, вы можете проанализировать отладочную полезную нагрузку в открытом виде из « Тела отчета », чтобы получить ключ сегмента. Однако в данном случае ключи сегментов создаются в демонстрационной версии песочницы конфиденциальности сайта. Поскольку частная агрегация для этого сайта находится в режиме отладки, вы можете использовать debug_cleartext_payload из « Тела отчета », чтобы получить ключ сегмента.
Скопируйте значение debug_cleartext_payload из тела отчета.
 Отладка содержимого в открытом виде из тела отчета.
Отладка содержимого в открытом виде из тела отчета.
Откройте инструмент Debug payload decoder for Private Aggregation , вставьте ваш debug_cleartext_payload в поле " INPUT " и нажмите " Decode ".
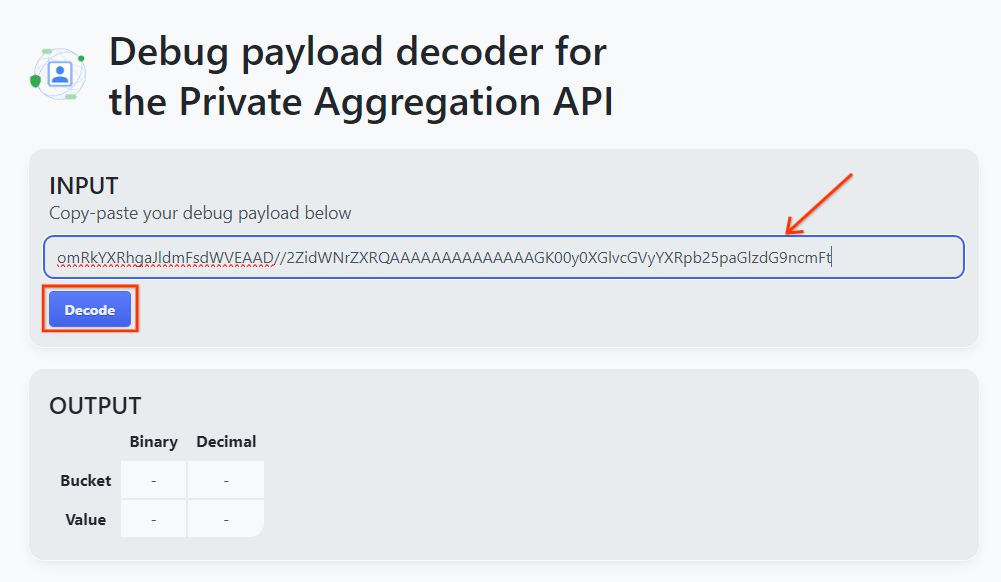 Декодер полезной нагрузки.
Декодер полезной нагрузки.
Страница возвращает десятичное значение ключа корзины. Ниже приведен пример ключа корзины.
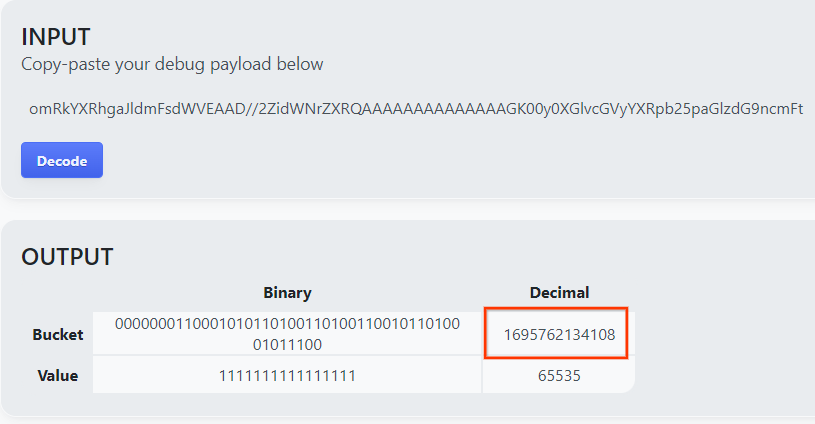 Результат декодирования полезной нагрузки.
Результат декодирования полезной нагрузки.
2.4. Создайте выходной домен AVRO.
Теперь, когда у нас есть ключ корзины, скопируйте его десятичное значение. Затем создайте файл output_domain.avro , используя этот ключ корзины. Убедитесь, что вы произвели замену.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Скрипт создаёт файл output_domain.avro в текущей папке.
2.5. Создавайте сводные отчеты с помощью инструмента локального тестирования.
Для создания сводных отчетов мы будем использовать LocalTestingTool_{version}.jar , загруженный в разделе 1.1. Используйте следующую команду. Вам следует заменить LocalTestingTool_{version}.jar на версию LocalTestingTool, загруженную из этого раздела.
Выполните следующую команду, чтобы сгенерировать сводный отчет в вашей локальной среде разработки:
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
После выполнения команды вы должны увидеть что-то похожее на изображение ниже. После завершения процесса будет создан файл отчета output.avro .
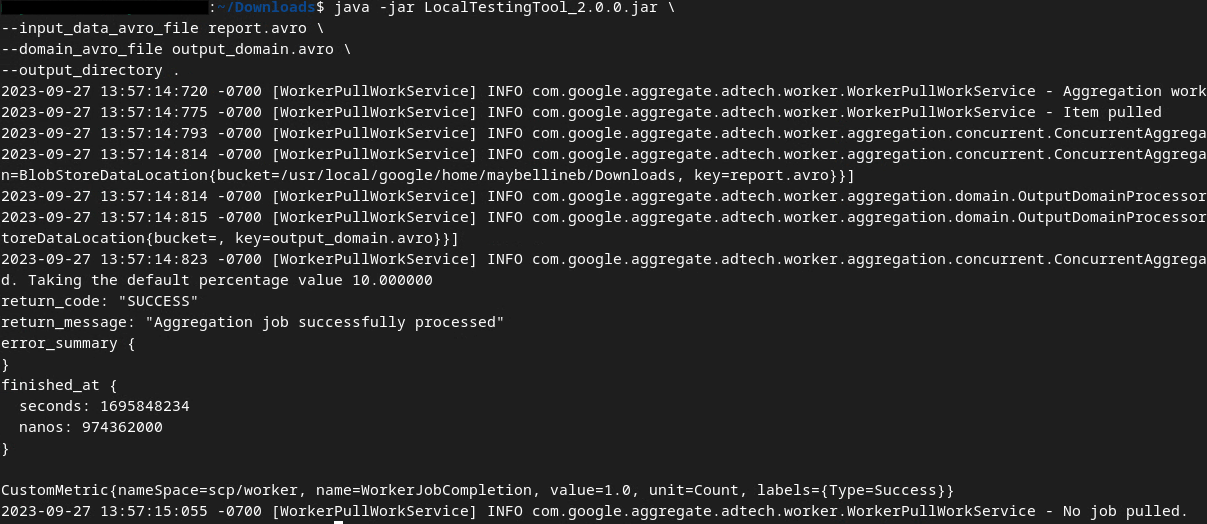 Сводный отчет о локальном тестировании в формате Avro.
Сводный отчет о локальном тестировании в формате Avro.
2.6. Ознакомьтесь с итоговым отчетом.
Созданный сводный отчет имеет формат AVRO. Для его чтения необходимо преобразовать его из формата AVRO в формат JSON. В идеале, в сфере рекламных технологий должен быть предусмотрен код для преобразования отчетов AVRO обратно в JSON.
Для нашей практической работы мы воспользуемся предоставленным инструментом aggregatable_report_converter.jar , чтобы преобразовать отчет AVRO обратно в формат JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
В результате выполнения программы будет создан отчет, похожий на изображение ниже. Вместе с ним в той же директории будет создан файл output.json .
 Сводная информация из файла Avro, преобразованного в формат JSON.
Сводная информация из файла Avro, преобразованного в формат JSON.
Откройте JSON-файл в любом удобном для вас редакторе, чтобы просмотреть сводный отчет.
3. Развертывание сервиса агрегации
Для развертывания службы агрегации выполните следующие действия:
Шаг 3. Развертывание сервиса агрегации : Разверните сервис агрегации на AWS.
Шаг 3.1. Клонируйте репозиторий сервиса агрегации.
Шаг 3.2. Загрузите предварительно собранные зависимости.
Шаг 3.3. Создайте среду разработки.
Шаг 3.4. Развертывание службы агрегации
3.1. Клонируйте репозиторий сервиса агрегации.
В локальной среде клонируйте репозиторий Aggregation Service на GitHub .
git clone https://github.com/privacysandbox/aggregation-service.git
3.2. Загрузка предварительно собранных зависимостей
После клонирования репозитория Aggregation Service перейдите в папку Terraform этого репозитория, а затем в соответствующую папку cloud. Если ваш cloud_provider — AWS, вы можете продолжить.
cd <repository_root>/terraform/aws
В download_prebuilt_dependencies.sh .
bash download_prebuilt_dependencies.sh
3.3. Создайте среду разработки.
Создайте среду разработки в dev .
mkdir dev
Скопируйте содержимое папки demo в папку dev .
cp -R demo/* dev
Перейдите в папку dev .
cd dev
Обновите файл main.tf и нажмите клавишу i для input , чтобы отредактировать файл.
vim main.tf
Раскомментируйте код в красной рамке, удалив символ # и обновив имена корзины и ключа.
Для файла main.tf в AWS :
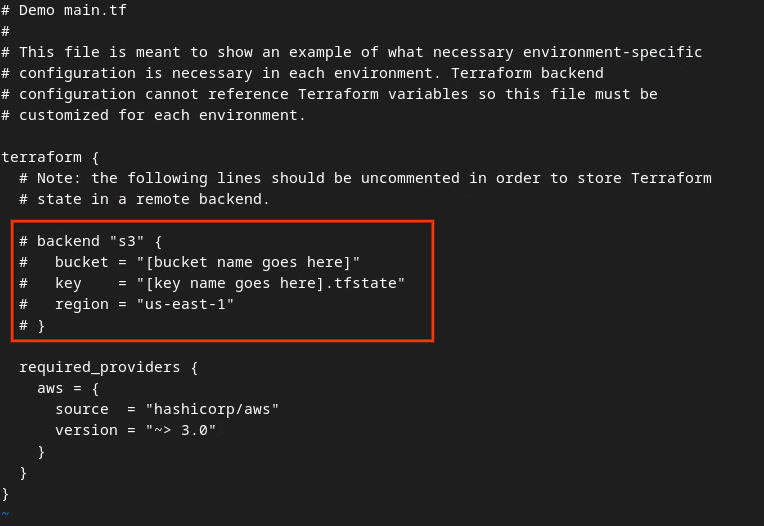 Основной файл tf AWS.
Основной файл tf AWS.
Раскомментированный код должен выглядеть следующим образом.
backend "s3" {
bucket = "<tf_state_bucket_name>"
key = "<environment_name>.tfstate"
region = "us-east-1"
}
После завершения обновлений сохраните их и выйдите из редактора, нажав esc -> :wq! Это сохранит обновления в файле main.tf
Далее переименуйте файл example.auto.tfvars в dev.auto.tfvars .
mv example.auto.tfvars dev.auto.tfvars
Обновите файл dev.auto.tfvars и нажмите клавишу i для input , чтобы отредактировать файл.
vim dev.auto.tfvars
Обновите поля в красной рамке на следующем изображении, указав правильные параметры AWS ARN, предоставленные во время подключения к службе агрегации, настройки среды и получения уведомления по электронной почте.
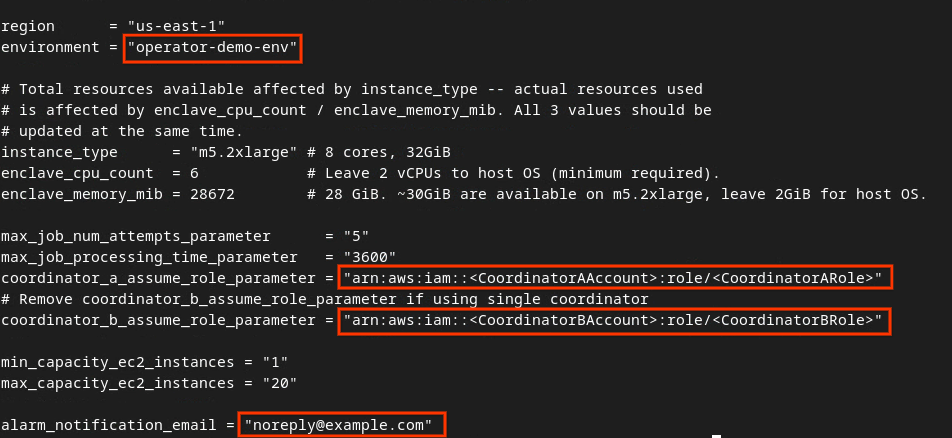 Отредактируйте файл dev auto tfvars.
Отредактируйте файл dev auto tfvars.
После завершения обновлений нажмите esc -> :wq! . Это сохранит файл dev.auto.tfvars , и он должен выглядеть примерно так, как на следующем изображении.
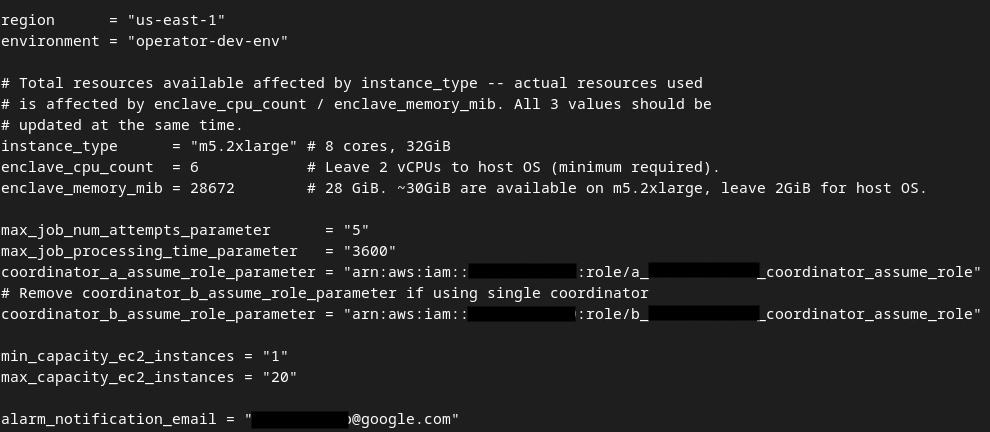 Обновлен файл dev auto tfvars.
Обновлен файл dev auto tfvars.
3.4. Развертывание службы агрегации
Для развертывания службы агрегации, в той же папке.
terraform init
В результате должно получиться что-то похожее на следующее изображение:
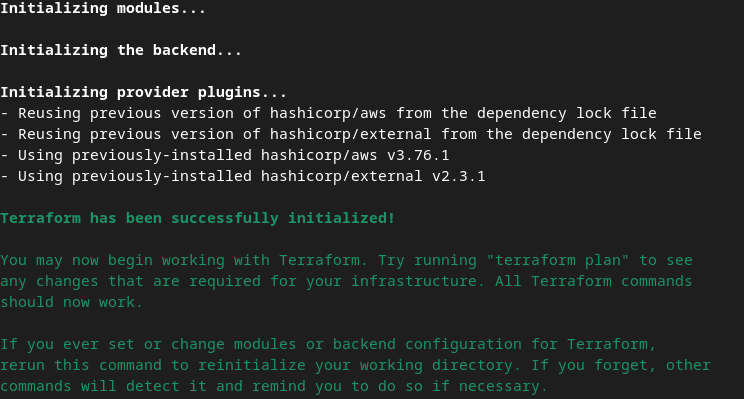 Terraform init.
Terraform init.
После инициализации Terraform создайте план выполнения Terraform. В нем будет указано количество добавляемых ресурсов и другая дополнительная информация, как показано на следующем изображении.
terraform plan
Ниже вы можете увидеть сводку « План ». Если это новое развертывание, вы должны увидеть количество ресурсов, которые будут добавлены, при этом для изменения будет указано 0 ресурсов, а для удаления — 0.
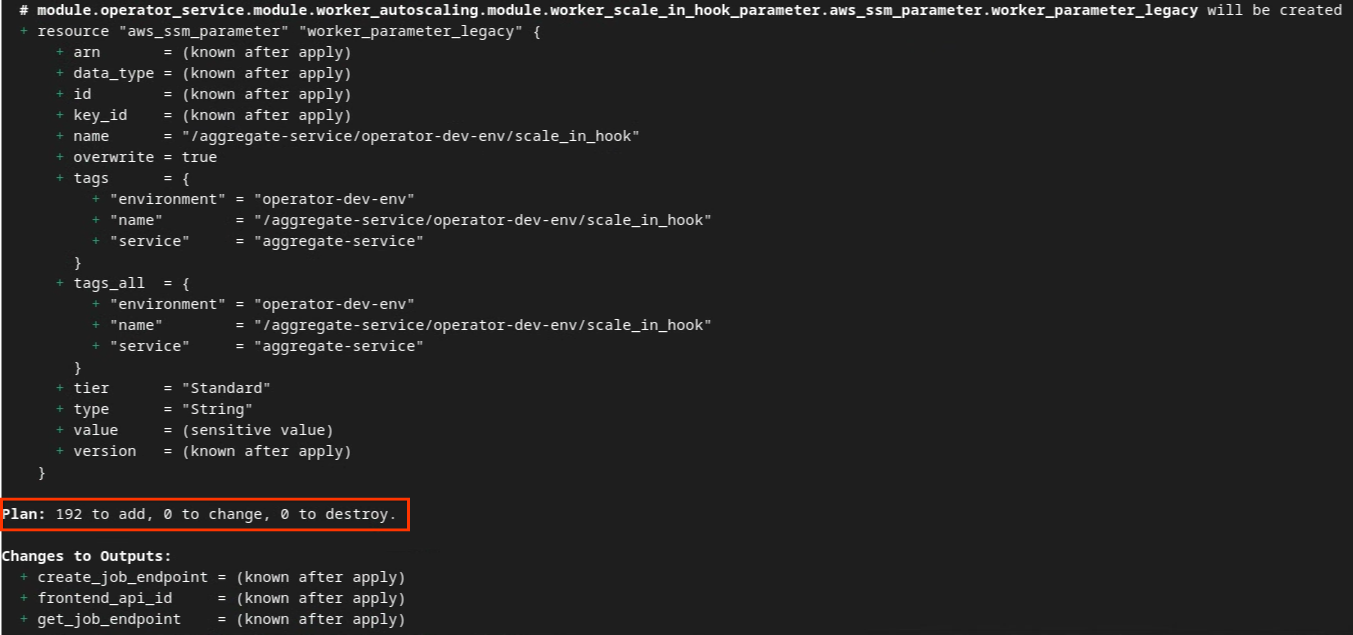 План терраформирования.
План терраформирования.
После завершения этого этапа вы можете приступить к применению Terraform.
terraform apply
Когда Terraform запросит подтверждение выполнения действий, введите « yes в соответствующее значение.
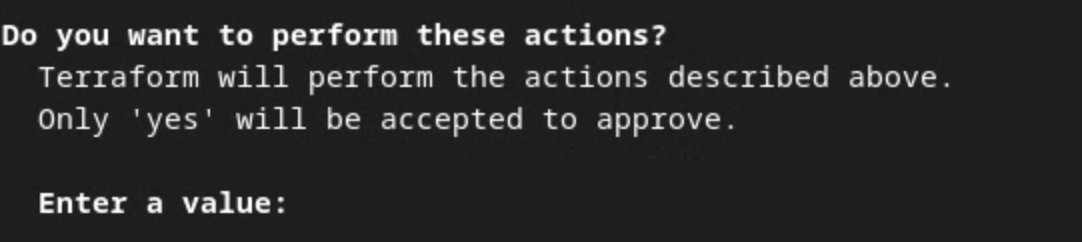 Запрос на применение Terraform.
Запрос на применение Terraform.
После завершения выполнения terraform apply возвращаются следующие конечные точки для createJob и getJob . Также возвращается ` frontend_api_id , который необходимо обновить в Postman в разделе 1.9 .
 Применение Terraform завершено.
Применение Terraform завершено.
4. Создание входных данных для сервиса агрегации
Перейдите к созданию отчетов AVRO для пакетной обработки в службе агрегации.
Шаг 4. Создание входных данных для службы агрегации : Создайте отчеты службы агрегации, которые будут формироваться пакетами для службы агрегации.
Шаг 4.1. Запуск отчета
Шаг 4.2. Сбор сводных отчетов.
Шаг 4.3. Преобразование отчетов в формат AVRO.
Шаг 4.4. Создайте выходной домен AVRO.
4.1. Отчет о триггере
Перейдите на демонстрационный сайт Privacy Sandbox . Это запустит отчет о приватной агрегации. Вы можете просмотреть отчет по адресу chrome://private-aggregation-internals .
Внутренние механизмы частной агрегации Chrome.
Если ваш отчет находится в статусе « В ожидании », вы можете выбрать отчет и нажать « Отправить выбранные отчеты ».
Отправить частный сводный отчет.
4.2. Сбор сводных отчетов.
Собирайте сводные отчеты из конечных точек .well-known соответствующего API.
- Частная агрегация
[reporting-origin] /.well-known/private-aggregation/report-shared-storage - Отчет по атрибуции — Сводный отчет
[reporting-origin] /.well-known/attribution-reporting/report-aggregate-attribution
В рамках этого практического занятия вам предстоит вручную собирать отчеты. В производственной среде специалисты по рекламным технологиям должны будут программно собирать и конвертировать эти отчеты.
В chrome://private-aggregation-internals скопируйте " Тело отчета ", полученное в конечной точке [reporting-origin]/.well-known/private-aggregation/report-shared-storage .
Убедитесь, что в поле " Тело отчета " параметр aggregation_coordinator_origin содержит https://publickeyservice.msmt.aws.privacysandboxservices.com , что означает, что отчет является агрегируемым отчетом AWS.
Отчет о частном агрегировании.
Поместите JSON-текст " Report Body " в JSON-файл. В этом примере можно использовать vim, но вы можете использовать любой текстовый редактор по своему усмотрению.
vim report.json
Вставьте отчет в файл report.json и сохраните его.
Отчет в формате JSON.
4.3. Преобразование отчетов в формат AVRO
Отчеты, полученные с конечных точек .well-known , имеют формат JSON и должны быть преобразованы в формат отчета AVRO. После получения отчета в формате JSON перейдите в папку с отчетами и используйте aggregatable_report_converter.jar для создания отладочного агрегируемого отчета. Это создаст агрегируемый отчет с именем report.avro в текущем каталоге.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
4.4. Создайте выходной домен AVRO.
Для создания файла output_domain.avro вам понадобятся ключи сегментов, которые можно получить из отчетов.
Ключи сегментов создаются рекламной технологической компанией. Однако в данном случае ключи сегментов создаются демонстрационной версией Privacy Sandbox . Поскольку частная агрегация для этого сайта находится в режиме отладки, вы можете использовать параметр debug_cleartext_payload из " тела отчета ", чтобы получить ключ сегмента.
Скопируйте значение debug_cleartext_payload из тела отчета.
Отладка содержимого в открытом виде из тела отчета.
Откройте goo.gle/ags-payload-decoder , вставьте ваш debug_cleartext_payload в поле " INPUT " и нажмите " Decode ".
Декодер полезной нагрузки.
Страница возвращает десятичное значение ключа корзины. Ниже приведен пример ключа корзины.
Результат декодирования полезной нагрузки.
Теперь, когда у нас есть ключ к корзине, создайте файл output_domain.avro . Убедитесь, что вы произвели замену.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Скрипт создаёт файл output_domain.avro в текущей папке.
4.5. Переместите отчеты в хранилище AWS.
После создания отчетов AVRO (из раздела 3.2.3) и выходного домена (из раздела 3.2.4) переместите отчеты и выходной домен в S3-хранилища для отчетов.
Если у вас настроен AWS CLI в локальной среде, используйте следующие команды для копирования отчетов в соответствующий сегмент S3 и папку с отчетами.
aws s3 cp report.avro s3://<report_bucket_name>/<report_folder>/
aws s3 cp output_domain.avro s3://<report_bucket_name>/<output_domain_folder>/
5. Использование сервиса агрегации
Команда terraform apply возвращает значения create_job_endpoint , get_job_endpoint и ` frontend_api_id . Скопируйте ` frontend_api_id и вставьте его в глобальную переменную Postman ` frontend_api_id которую вы настроили в разделе 1.9 предварительных условий.
Шаг 5. Использование сервиса агрегации : Используйте API сервиса агрегации для создания сводных отчетов и их просмотра.
Шаг 5.1. Использование конечной точки createJob для пакетной обработки.
Шаг 5.2. Использование конечной точки getJob для получения статуса пакета.
Шаг 5.3. Проверка сводного отчета
5.1. Использование конечной точки createJob для пакетной обработки.
В Postman откройте коллекцию " Privacy Sandbox " и выберите " createJob ".
Выберите « Тело запроса » и выберите « сырой », чтобы разместить полезную нагрузку вашего запроса.
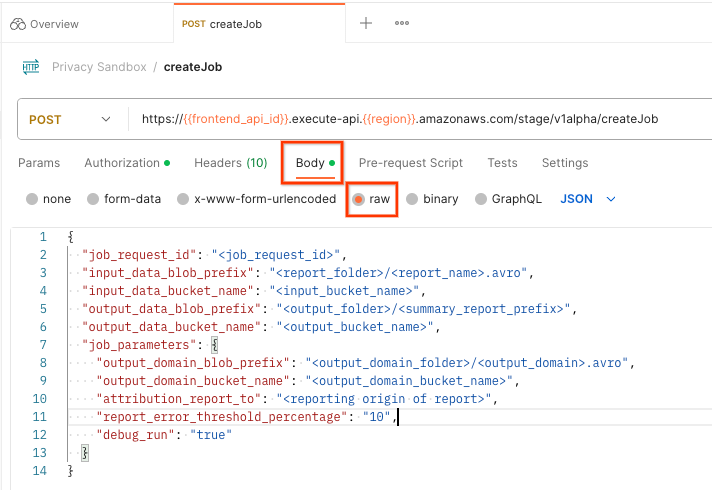 postman createJob request body
postman createJob request body
Схема полезной нагрузки createJob доступна на GitHub и выглядит примерно так. Замените <> соответствующими полями.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
], // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
После нажатия кнопки « Отправить » будет создано задание с идентификатором job_request_id . После принятия запроса службой агрегации вы должны получить HTTP-ответ 202. Другие возможные коды возврата можно найти в кодах HTTP-ответов.
 postman createJob request status
postman createJob request status
5.2. Использование конечной точки getJob для получения статуса пакета.
Чтобы проверить статус запроса на выполнение задания, вы можете использовать конечную точку getJob . Выберите " getJob " в коллекции " Privacy Sandbox ".
В разделе " Параметры " обновите значение job_request_id на тот job_request_id , который был отправлен в запросе createJob .
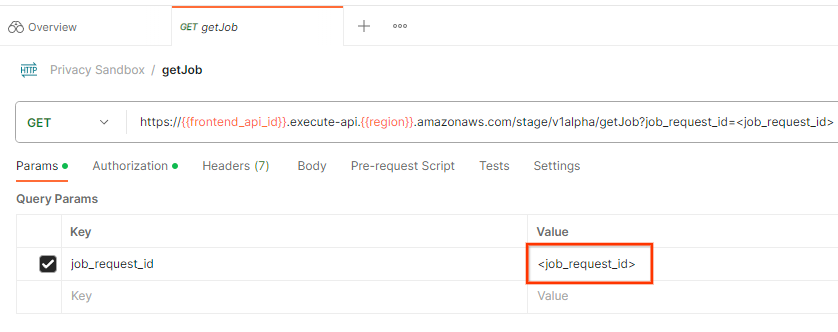 почтальон получить запрос на работу
почтальон получить запрос на работу
Результатом запроса getJob должен быть возвращен статус вашего запроса задания с HTTP-статусом 200. Тело запроса содержит необходимую информацию, такую как job_status , return_message и error_messages (если задание завершилось с ошибкой).
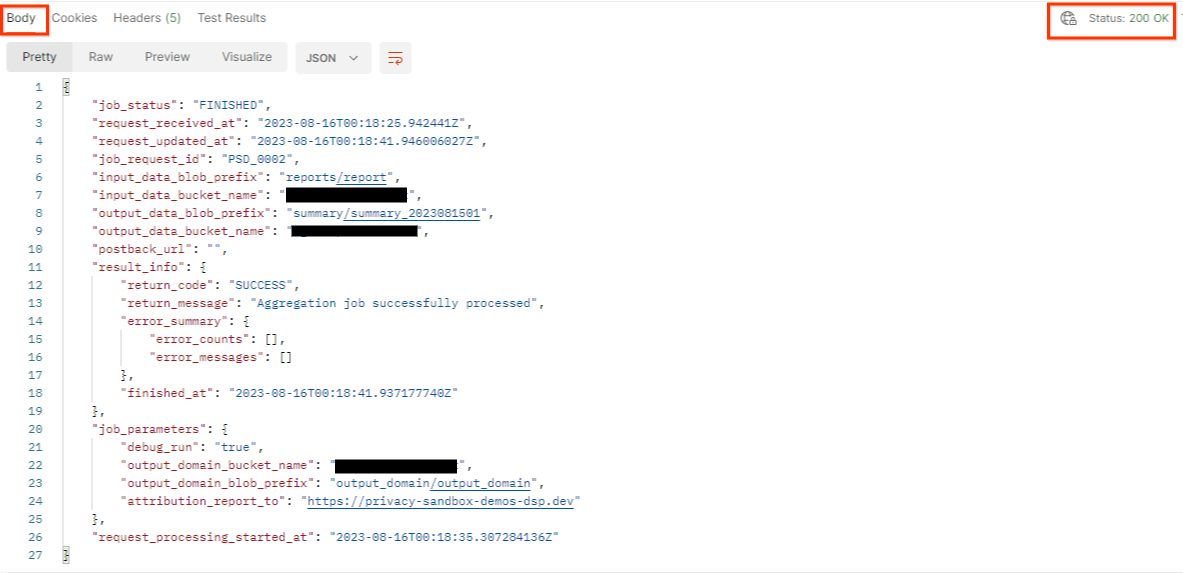 статус запроса на выполнение задания (postman getJob request status)
статус запроса на выполнение задания (postman getJob request status)
Поскольку сайт, на котором создается демонстрационный отчет, отличается от сайта, подключенного к вашему AWS ID, вы можете получить ответ с кодом возврата PRIVACY_BUDGET_AUTHORIZATION_ERROR . Это нормально, так как сайт-источник отчетов не совпадает с сайтом, подключенным к вашему AWS ID.
{
"job_status": "FINISHED",
"request_received_at": "2023-12-07T22:50:58.830956Z",
"request_updated_at": "2023-12-07T22:51:10.526326456Z",
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"postback_url": "",
"result_info": {
"return_code": "PRIVACY_BUDGET_AUTHORIZATION_ERROR",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-12-07T22:51:10.517730898Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"attribution_report_to": "https://privacy-sandbox-demos-dsp.dev",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
},
"request_processing_started_at": "2023-12-07T22:51:06.034472697Z"
}
5.3. Анализ сводного отчета
После получения сводного отчета в выходном S3-хранилище вы можете загрузить его в свою локальную среду. Сводные отчеты имеют формат AVRO и могут быть преобразованы обратно в JSON. Для чтения отчета вы можете использовать aggregatable_report_converter.jar , выполнив следующую команду.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
В результате возвращается JSON-файл с агрегированными значениями каждого ключа сегмента, который выглядит примерно так, как на следующем изображении.
 Сводный отчет.
Сводный отчет.
Если в вашем запросе createJob debug_run установлен в true , то вы получите сводный отчет в папке debug, расположенной в output_data_blob_prefix . Отчет имеет формат AVRO и может быть преобразован в JSON с помощью предыдущей команды.
Отчет содержит ключ к интервалу, незашумленную метрику и шум, который добавляется к незашумленной метрике для формирования сводного отчета. Отчет выглядит примерно так, как показано на следующем изображении.
 Сводный отладочный отчет.
Сводный отладочный отчет.
В аннотациях также содержатся in_reports и in_domain , что означает:
- in_reports - ключ корзины доступен внутри агрегируемых отчетов.
- in_domain - ключ корзины доступен внутри файла AVRO output_domain.