
1. 前提条件
この Codelab を実行するには、いくつかの前提条件を満たす必要があります。各要件には、「ローカル テスト」または「集計サービス」のどちらに必要なのかがマークされています。
1.1. ローカルテスト ツール(ローカルテスト)をダウンロードする
ローカル テストでは、ローカル テストツールのダウンロードが必要になります。ツールは、暗号化されていないデバッグ レポートから概要レポートを生成します。
ローカル テストツールは、Github の Lambda JAR アーカイブからダウンロードできます。LocalTestingTool_{version}.jar という名前になります。
1.2. JAVA JRE がインストールされていることを確認する(ローカル テストと集計サービス)
[ターミナル] を開き、java --version を使用して、マシンに Java または openJDK がインストールされているかどうかを確認します。
 `java --version` を使用して Java JRE のバージョンを確認します。
`java --version` を使用して Java JRE のバージョンを確認します。
インストールされていない場合は、Java サイトまたは openJDK サイトからダウンロードしてインストールできます。
1.3. 集計可能レポート コンバータをダウンロードする(ローカルテストと集計サービス)
集計可能レポート コンバータのコピーは、プライバシー サンドボックス デモの GitHub リポジトリからダウンロードできます。
1.4. 広告プライバシー API(ローカル テストとアグリゲーション サービス)を有効にする
ブラウザで chrome://settings/adPrivacy にアクセスし、すべての広告プライバシー API を有効にします。
サードパーティの Cookie が有効になっていることを確認します。
ブラウザで chrome://settings/cookies に移動し、[シークレット モードでサードパーティ Cookie をブロックする] を選択します。
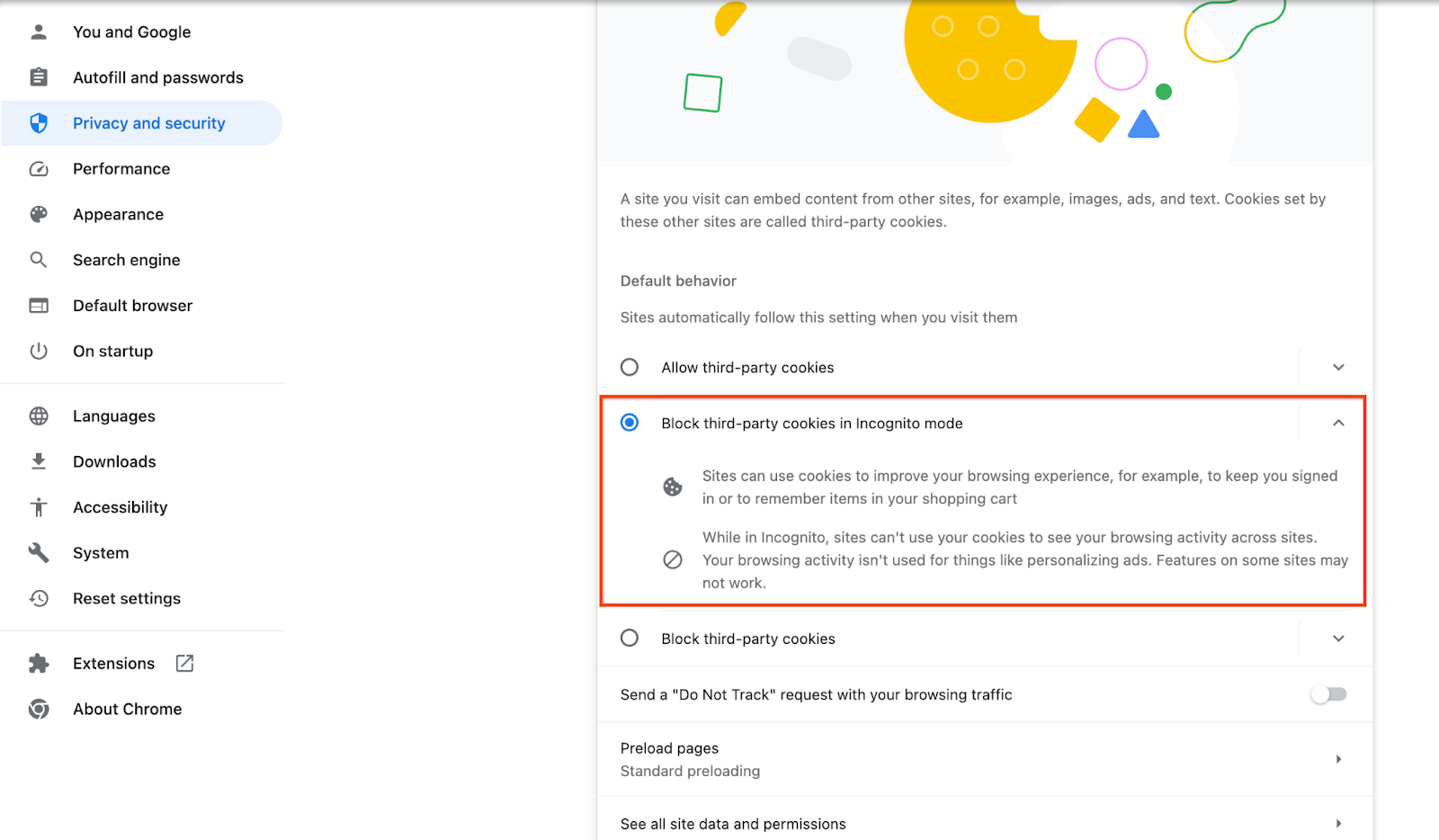 Chrome のサードパーティ Cookie の設定。
Chrome のサードパーティ Cookie の設定。
1.5. ウェブと Android の登録(集計サービス)
本番環境でプライバシー サンドボックス API を使用するには、Chrome と Android の両方で登録と証明書取得を完了していることを確認してください。
ローカルテストでは、Chrome フラグと CLI スイッチを使用して登録を無効にできます。
デモで Chrome フラグを使用するには、chrome://flags/#privacy-sandbox-enrollment-overrides に移動して、サイトでオーバーライドを更新します。デモサイトを使用する場合は、更新は不要です。
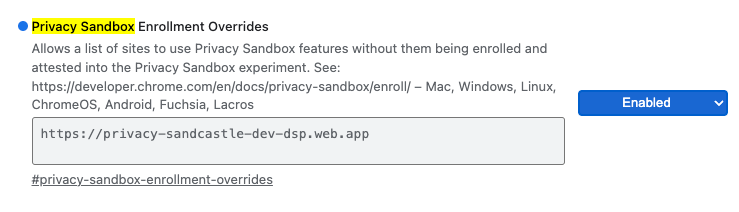 プライバシー サンドボックス登録オーバーライド Chrome フラグ。
プライバシー サンドボックス登録オーバーライド Chrome フラグ。
1.6. Aggregation Service のオンボーディング(Aggregation Service)
集計サービスを使用するには、コーディネーターにオンボーディングする必要があります。レポートサイトのアドレス、AWS アカウント ID などの情報を入力して、集計サービスのオンボーディング フォームに記入します。
1.7. クラウド プロバイダ(アグリゲーション サービス)
集計サービスでは、クラウド環境を使用する高信頼実行環境を使用する必要があります。集約サービスは、Amazon Web Services(AWS)と Google Cloud(GCP)でサポートされています。この Codelab では、AWS 統合のみについて説明します。
AWS は、Nitro Enclaves という高信頼実行環境を提供しています。AWS アカウントがあることを確認し、AWS CLI のインストールと更新の手順に沿って AWS CLI 環境を設定します。
AWS CLI が新しい場合は、CLI 構成の手順に沿って AWS CLI を構成できます。
1.7.1. AWS S3 バケットを作成する
Terraform の状態を保存する AWS S3 バケットと、レポートと概要レポートを保存する別の S3 バケットを作成します。提供されている CLI コマンドを使用できます。<> のフィールドを適切な変数に置き換えます。
aws s3api create-bucket --bucket <tf_bucket_name> --region us-east-1
aws s3api create-bucket --bucket <report_bucket_name> --region us-east-1
1.7.2. ユーザー アクセスキーを作成する
AWS ガイドを使用してユーザー アクセスキーを作成します。これは、AWS で作成された createJob と getJob の API エンドポイントを呼び出すために使用されます。
1.7.3. AWS のユーザーとグループの権限
AWS に Aggregation Service をデプロイするには、サービスのデプロイに使用するユーザーに特定の権限を付与する必要があります。この Codelab では、ユーザーに管理者権限があることを確認して、デプロイの完全な権限を確保します。
1.8. Terraform(集計サービス)
この Codelab では、Terraform を使用して集計サービスをデプロイします。Terraform バイナリがローカル環境にインストールされていることを確認します。
Terraform バイナリをローカル環境にダウンロードします。
Terraform バイナリがダウンロードされたら、ファイルを解凍して、Terraform バイナリを /usr/local/bin に移動します。
cp <directory>/terraform /usr/local/bin
Terraform がクラスパスで使用可能であることを確認します。
terraform -v
1.9. Postman(集計サービス AWS 用)
この Codelab では、リクエスト管理に Postman を使用します。
ワークスペースを作成するには、上部のナビゲーション アイテムの [ワークスペース] に移動し、[ワークスペースを作成] を選択します。
 Postman ワークスペース
Postman ワークスペース
[空白のワークスペース] を選択し、[次へ] をクリックして、[プライバシー サンドボックス] という名前を付けます。[個人] を選択し、[作成] をクリックします。
事前構成済みのワークスペースの JSON 構成ファイルとグローバル環境ファイルをダウンロードします。
[インポート] ボタンを使用して、[マイ ワークスペース] に JSON ファイルをインポートします。
 Postman JSON ファイルをインポートします。
Postman JSON ファイルをインポートします。
これにより、createJob と getJob の HTTP リクエストとともに、プライバシー サンドボックス コレクションが作成されます。
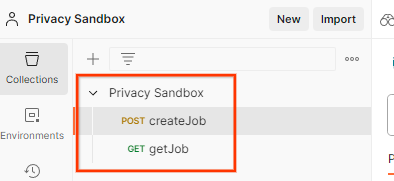 Postman でコレクションをインポートしました。
Postman でコレクションをインポートしました。
[環境の概要] で AWS の [アクセスキー] と [シークレット キー] を更新します。
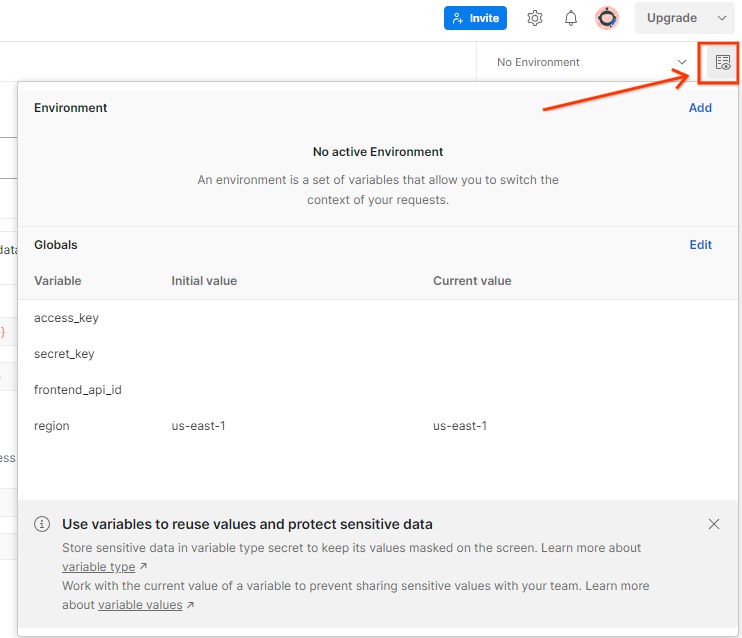 Postman 環境の概要。
Postman 環境の概要。
[編集] をクリックし、[access_key] と [secret_key] の両方の [現在の値] を更新します。frontend_api_id については、このドキュメントのセクション 3.1.4 で説明します。また、us-east-1 リージョンを使用することをおすすめします。ただし、別のリージョンにデプロイする場合は、リリースされた AMI をアカウントにコピーするか、提供されたスクリプトを使用してセルフビルドを行うことを確認してください。
 Postman のグローバル変数。
Postman のグローバル変数。 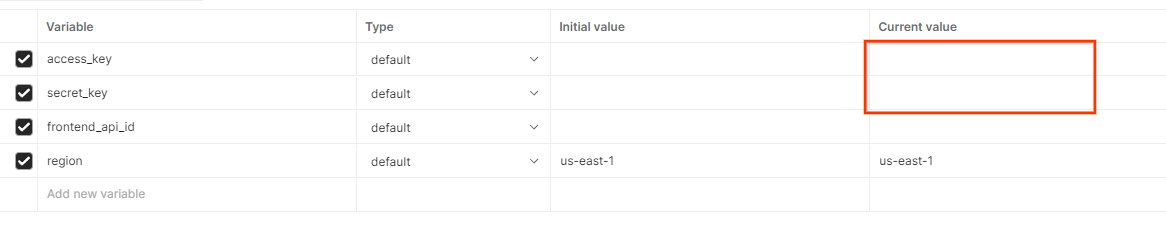 Postman でグローバル変数を編集します。
Postman でグローバル変数を編集します。
2. ローカルテスト コードラボ
マシン上のローカル テストツールを使用して、暗号化されていないデバッグ レポートを使用して集計を行い、概要レポートを生成できます。
Codelab の手順
ステップ 2.1. トリガー レポート: レポートを収集できるように、Private Aggregation レポートをトリガーします。
ステップ 2.2. デバッグ可能な集計レポートを作成する: 収集した JSON レポートを AVRO 形式のレポートに変換します。
このステップは、広告テクノロジーが API レポート エンドポイントからレポートを収集し、JSON レポートを AVRO 形式のレポートに変換する場合と似ています。
ステップ 2.3. デバッグ レポートからバケットキーを解析する: バケットキーは広告テクノロジーによって設計されます。この Codelab では、バケットが事前定義されているため、提供されたバケットキーを取得します。
ステップ 2.4. 出力ドメイン AVRO を作成する: バケットキーを取得したら、出力ドメイン AVRO ファイルを作成します。
ステップ 2.5. ローカルテスト ツールを使用して概要レポートを作成する: ローカルテスト ツールを使用して、ローカル環境で概要レポートを作成できます。
ステップ 2.6. 概要レポートを確認する: ローカル テストツールによって作成された概要レポートを確認します。
2.1. トリガー レポート
プライバシー サンドボックスのデモサイトにアクセスします。これにより、プライベート集計レポートがトリガーされます。レポートは chrome://private-aggregation-internals で確認できます。
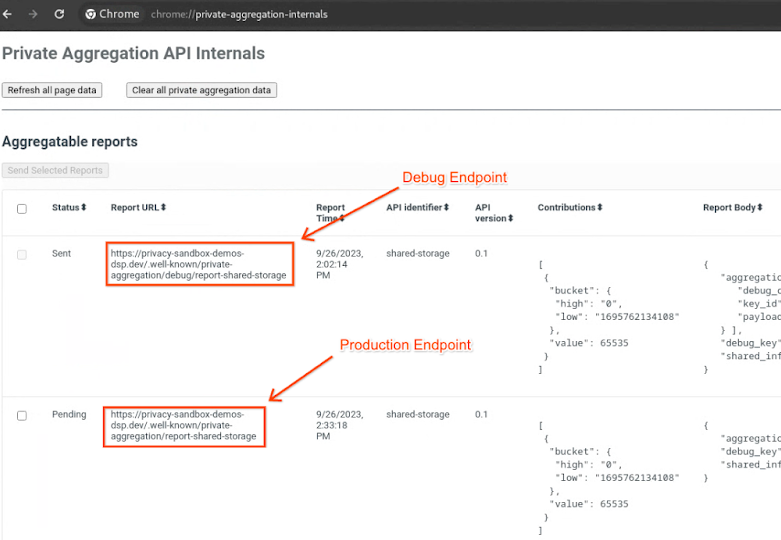 Chrome のプライベート アグリゲーションの内部。
Chrome のプライベート アグリゲーションの内部。
レポートのステータスが [保留中] の場合は、レポートを選択して [選択したレポートを送信] をクリックします。
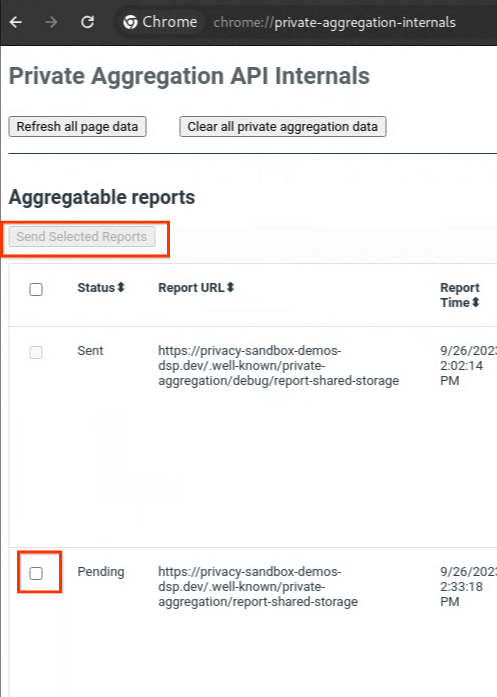 プライベート集計レポートを送信します。
プライベート集計レポートを送信します。
2.2. デバッグ可能な集約可能レポートを作成する
chrome://private-aggregation-internals で、[reporting-origin]/.well-known/private-aggregation/report-shared-storage エンドポイントで受信した「Report Body」をコピーします。
[レポート本文] で、aggregation_coordinator_origin に https://publickeyservice.msmt.aws.privacysandboxservices.com が含まれていることを確認します。これは、レポートが AWS 集計可能レポートであることを意味します。
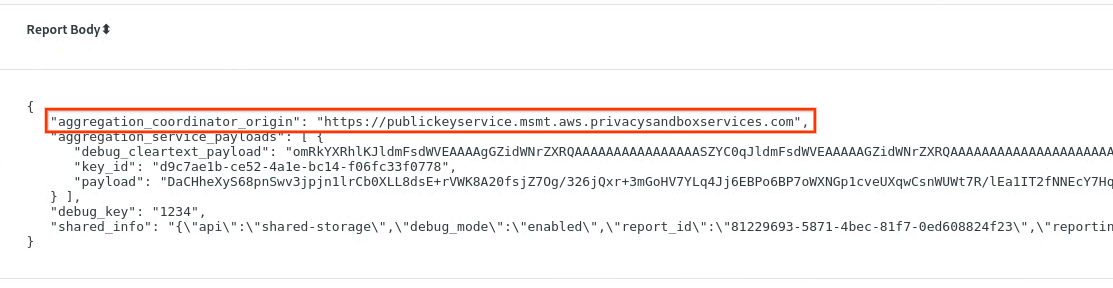 プライベート集計レポート。
プライベート集計レポート。
JSON の「レポート本文」を JSON ファイルに配置します。この例では、vim を使用できます。ただし、任意のテキスト エディタを使用できます。
vim report.json
レポートを report.json に貼り付けて、ファイルを保存します。
 レポートの JSON ファイル。
レポートの JSON ファイル。
取得したら、レポート フォルダに移動し、aggregatable_report_converter.jar を使用してデバッグ可能な集計レポートを作成します。これにより、現在のディレクトリに report.avro という集計可能なレポートが作成されます。
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. デバッグ レポートからバケットキーを解析する
集計サービスでは、バッチ処理時に 2 つのファイルが必要です。集計可能なレポートと出力ドメイン ファイル。出力ドメイン ファイルには、集計可能レポートから取得するキーが含まれます。output_domain.avro ファイルを作成するには、レポートから取得できるバケットキーが必要です。
バケットキーは API の呼び出し元が設計します。デモには、事前に構築されたバケットキーの例が含まれています。デモではプライベート アグリゲーションのデバッグモードが有効になっているため、「レポート本文」からデバッグのクリアテキスト ペイロードを解析して、バケットキーを取得できます。ただし、この場合は、サイトのプライバシー サンドボックスのデモがバケットキーを作成します。このサイトのプライベート アグリゲーションはデバッグモードであるため、「レポート本文」の debug_cleartext_payload を使用してバケットキーを取得できます。
レポートの本文から debug_cleartext_payload をコピーします。
 レポート本文からクリアテキスト ペイロードをデバッグします。
レポート本文からクリアテキスト ペイロードをデバッグします。
プライベート アグリゲーションのデバッグ ペイロード デコーダ ツールを開き、[INPUT] ボックスに debug_cleartext_payload を貼り付けて、[Decode] をクリックします。
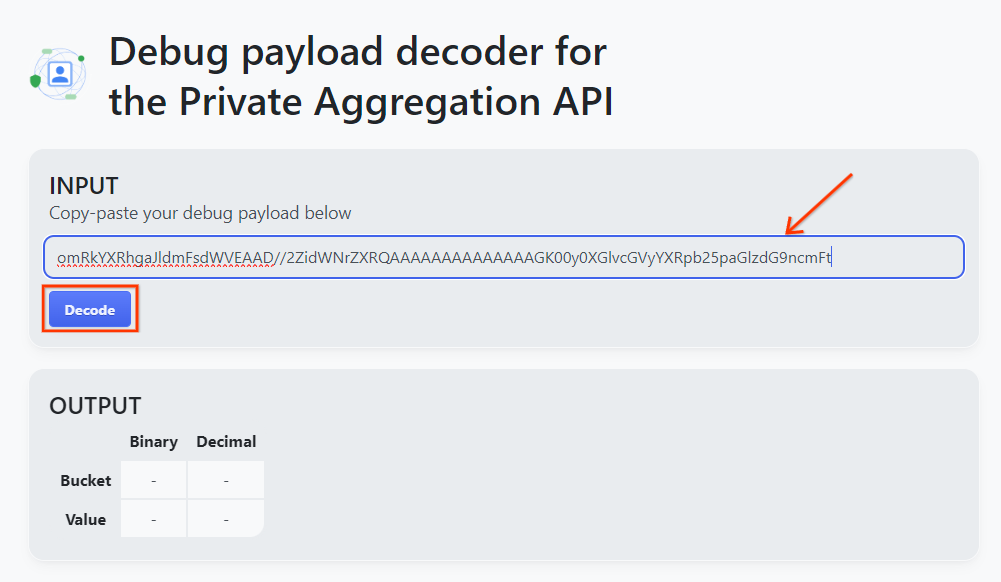 ペイロード デコーダ。
ペイロード デコーダ。
このページは、バケットキーの 10 進数値を返します。バケットキーのサンプルを次に示します。
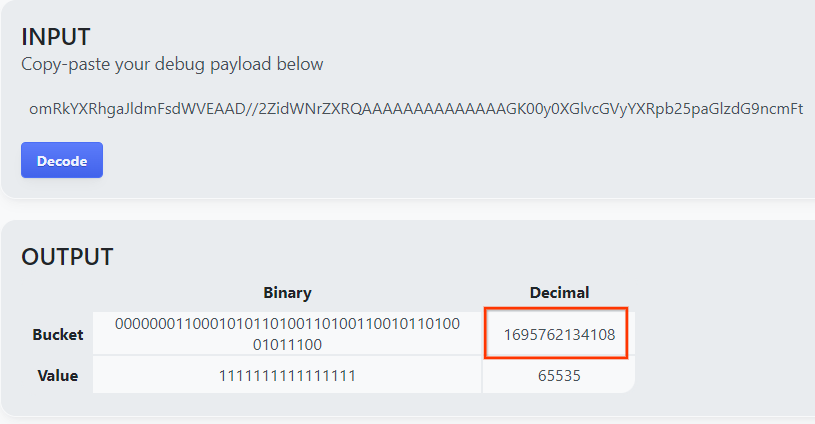 ペイロード デコーダの結果。
ペイロード デコーダの結果。
2.4. 出力ドメイン AVRO を作成する
バケットキーを取得したので、バケットキーの 10 進数値をコピーします。バケットキーを使用して output_domain.avro を作成します。
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
スクリプトにより、現在のフォルダに output_domain.avro ファイルが作成されます。
2.5. ローカル テストツールを使用して概要レポートを作成する
セクション 1.1 でダウンロードした LocalTestingTool_{version}.jar を使用して、概要レポートを作成します。次のコマンドを使用します。LocalTestingTool_{version}.jar は、LocalTestingTool 用にダウンロードしたバージョンに置き換える必要があります。
次のコマンドを実行して、ローカル開発環境で概要レポートを生成します。
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
コマンドを実行すると、次の画像のような画面が表示されます。この処理が完了すると、レポート output.avro が作成されます。
 ローカル テストの概要レポートの Avro ファイル。
ローカル テストの概要レポートの Avro ファイル。
2.6. 概要レポートを確認する
作成される概要レポートは AVRO 形式です。これを読み取るには、AVRO から JSON 形式に変換する必要があります。理想的には、広告テクノロジーは AVRO レポートを JSON に変換するコードを作成する必要があります。
この Codelab では、提供されている aggregatable_report_converter.jar ツールを使用して、AVRO レポートを JSON に変換します。
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
次のようなレポートが返されます。同じディレクトリに作成されたレポート output.json も含まれます。
 概要 avro ファイルが json に変換されました。
概要 avro ファイルが json に変換されました。
任意のテキスト エディタで JSON ファイルを開き、概要レポートを確認します。
3. 集計サービスのデプロイ
集計サービスをデプロイする手順は次のとおりです。
ステップ 3. 集計サービスのデプロイ: AWS に集計サービスをデプロイします。
ステップ 3.1. 集計サービス リポジトリのクローンを作成する
ステップ 3.2. ビルド済みの依存関係をダウンロードする
ステップ 3.3. 開発環境を作成する
ステップ 3.4. 集計サービスをデプロイする
3.1. 集計サービス リポジトリのクローンを作成する
ローカル環境で、集計サービス GitHub リポジトリのクローンを作成します。
git clone https://github.com/privacysandbox/aggregation-service.git
3.2. 事前構築済みの依存関係をダウンロードする
集計サービス リポジトリをクローンしたら、リポジトリの Terraform フォルダと対応するクラウド フォルダに移動します。cloud_provider が AWS の場合は、
cd <repository_root>/terraform/aws
download_prebuilt_dependencies.sh を実行します。
bash download_prebuilt_dependencies.sh
3.3. 開発環境を作成する
dev という名前のフォルダを作成します。
mkdir dev
demo フォルダの内容を dev フォルダにコピーします。
cp -R demo/* dev
dev フォルダに移動します。
cd dev
main.tf ファイルを更新し、input の i を押してファイルを編集します。
vim main.tf
# を削除してバケット名とキー名を更新し、赤いボックス内のコードのコメントを解除します。
AWS の main.tf の場合:
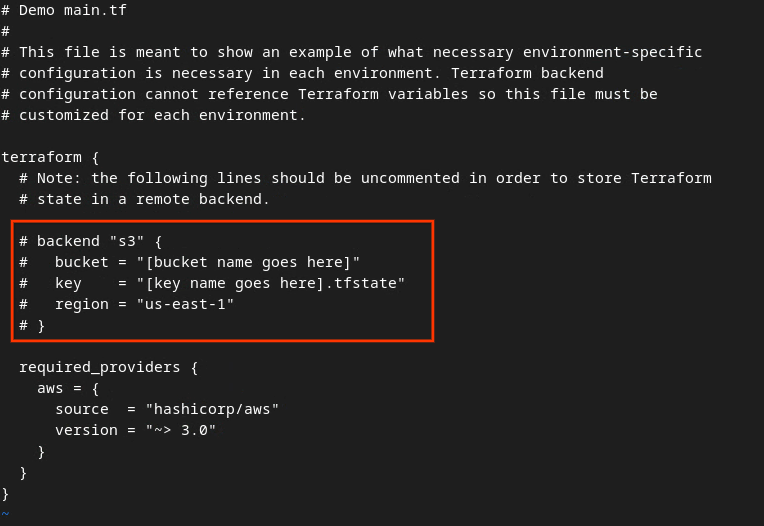 AWS の main.tf ファイル。
AWS の main.tf ファイル。
コメント化を解除したコードは次のようになります。
backend "s3" {
bucket = "<tf_state_bucket_name>"
key = "<environment_name>.tfstate"
region = "us-east-1"
}
更新が完了したら、esc -> :wq! を押して更新を保存し、エディタを終了します。これにより、main.tf の更新が保存されます。
次に、example.auto.tfvars の名前を dev.auto.tfvars に変更します。
mv example.auto.tfvars dev.auto.tfvars
dev.auto.tfvars を更新し、input の i を押してファイルを編集します。
vim dev.auto.tfvars
次の画像の赤いボックス内のフィールドを、アグリゲーション サービスのオンボーディング、環境、通知メールで提供される正しい AWS ARN パラメータで更新します。
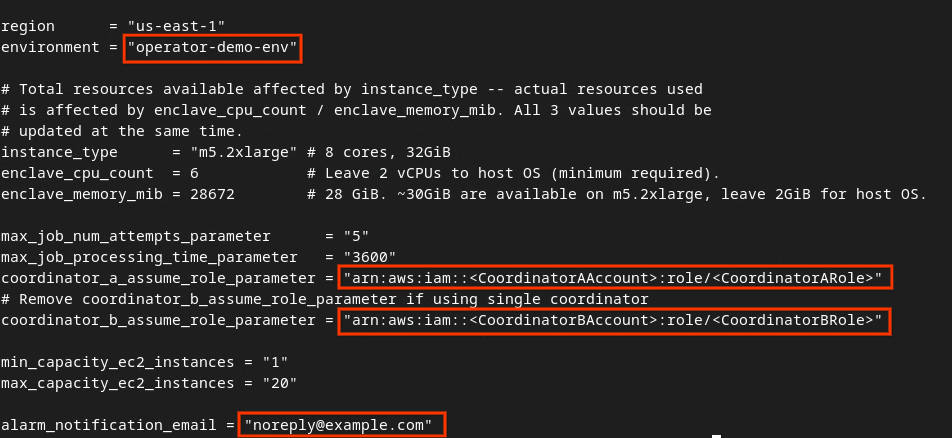 開発自動 tfvars ファイルを編集します。
開発自動 tfvars ファイルを編集します。
アップデートが完了したら、esc -> :wq! を押します。これで dev.auto.tfvars ファイルが保存されます。次の図のようになります。
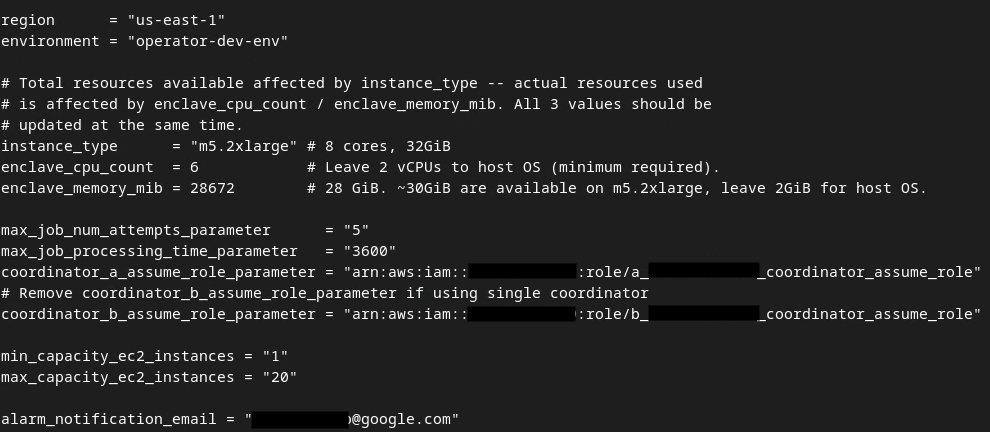 更新された開発自動 tfvars ファイル。
更新された開発自動 tfvars ファイル。
3.4. 集計サービスをデプロイする
Aggregation Service をデプロイするには、同じフォルダ
terraform init
次のような結果が返されます。
 Terraform init。
Terraform init。
Terraform を初期化したら、Terraform 実行プランを作成します。追加するリソースの数と、次の画像のようなその他の追加情報が返されます。
terraform plan
以下に「プラン」の概要を示します。新しいデプロイの場合、追加されるリソースの数が表示され、変更と破棄は 0 になります。
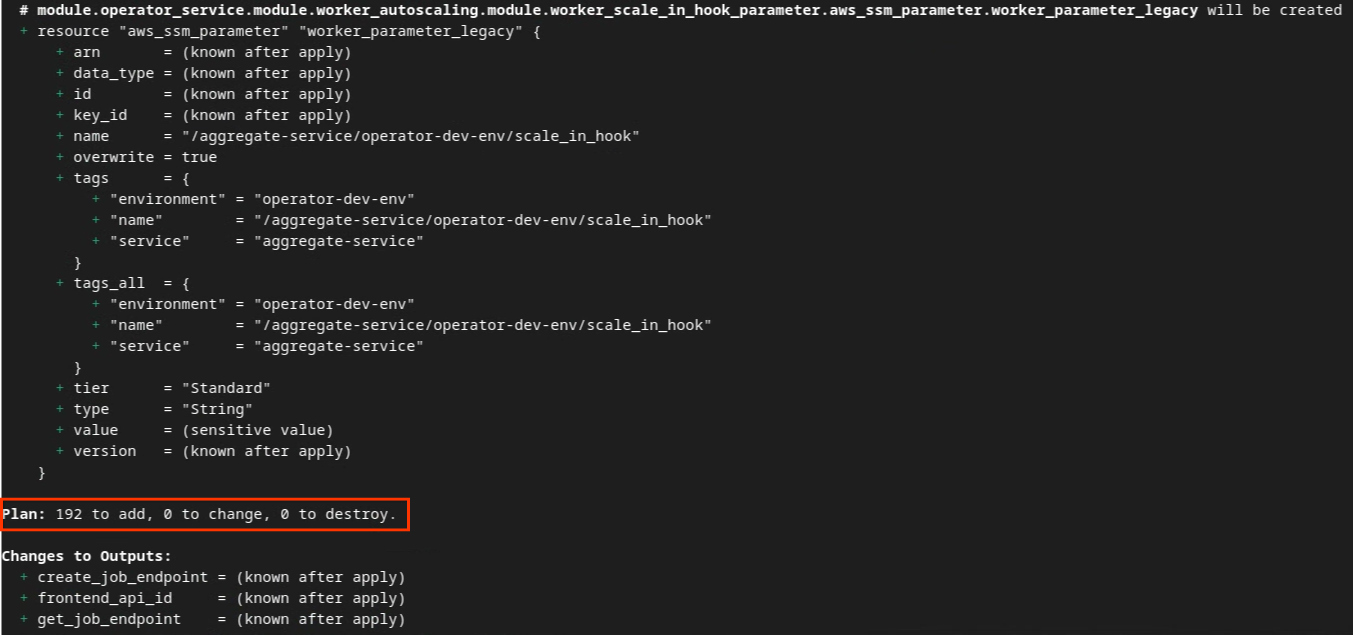 Terraform プラン。
Terraform プラン。
この手順を完了したら、Terraform の適用に進むことができます。
terraform apply
Terraform によってアクションの実行を確認するよう求められたら、値に「yes」と入力します。
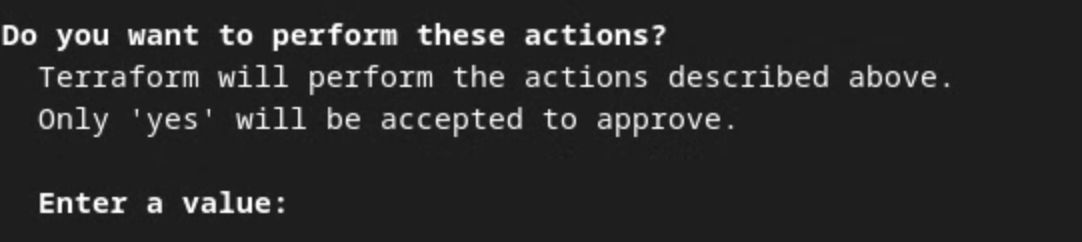 Terraform apply プロンプト。
Terraform apply プロンプト。
terraform apply が完了すると、createJob と getJob の次のエンドポイントが返されます。セクション 1.9 で Postman で更新する必要がある frontend_api_id も返されます。
 Terraform apply complete.
Terraform apply complete.
4. 集計サービスの入力の作成
集計サービスでバッチ処理を行うための AVRO レポートの作成に進みます。
ステップ 4. 集計サービスの入力の作成: 集計サービス用にバッチ処理される集計サービス レポートを作成します。
ステップ 4.1. トリガー レポート
ステップ 4.2. 集約可能レポートを収集する
ステップ 4.3. レポートを AVRO に変換する
ステップ 4.4. 出力ドメイン AVRO を作成する
4.1. トリガー レポート
プライバシー サンドボックスのデモサイトにアクセスします。これにより、プライベート集計レポートがトリガーされます。レポートは chrome://private-aggregation-internals で確認できます。
Chrome のプライベート アグリゲーションの内部。
レポートのステータスが [保留中] の場合は、レポートを選択して [選択したレポートを送信] をクリックします。'
プライベート集計レポートを送信します。
4.2. 集計可能レポートを収集する
対応する API の .well-known エンドポイントから集計可能レポートを収集します。
- Private Aggregation
[reporting-origin] /.well-known/private-aggregation/report-shared-storage - アトリビューション レポート - サマリー レポート
[reporting-origin] /.well-known/attribution-reporting/report-aggregate-attribution
この Codelab では、レポートの収集を手動で行います。本番環境では、広告テクノロジーがレポートをプログラムで収集して変換することが想定されています。
chrome://private-aggregation-internals で、[reporting-origin]/.well-known/private-aggregation/report-shared-storage エンドポイントで受信した「Report Body」をコピーします。
[レポート本文] で、aggregation_coordinator_origin に https://publickeyservice.msmt.aws.privacysandboxservices.com が含まれていることを確認します。これは、レポートが AWS 集計可能レポートであることを意味します。
プライベート集計レポート。
JSON の「レポート本文」を JSON ファイルに配置します。この例では、vim を使用できます。ただし、任意のテキスト エディタを使用できます。
vim report.json
レポートを report.json に貼り付けて、ファイルを保存します。
レポートの JSON ファイル。
4.3. レポートを AVRO に変換する
.well-known エンドポイントから受信したレポートは JSON 形式であるため、AVRO レポート形式に変換する必要があります。JSON レポートを取得したら、レポート フォルダに移動し、aggregatable_report_converter.jar を使用してデバッグ可能な集計レポートを作成します。これにより、現在のディレクトリに report.avro という集計可能なレポートが作成されます。
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
4.4. 出力ドメイン AVRO を作成する
output_domain.avro ファイルを作成するには、レポートから取得できるバケットキーが必要です。
バケットキーは広告テクノロジーによって設計されますが、このケースでは、サイトのプライバシー サンドボックス デモがバケットキーを作成します。このサイトのプライベート アグリゲーションはデバッグモードであるため、「レポート本文」の debug_cleartext_payload を使用してバケットキーを取得できます。
レポートの本文から debug_cleartext_payload をコピーします。
レポート本文からクリアテキスト ペイロードをデバッグします。
goo.gle/ags-payload-decoder を開き、[INPUT] ボックスに debug_cleartext_payload を貼り付けて、[Decode] をクリックします。
ペイロード デコーダ。
このページは、バケットキーの 10 進数値を返します。バケットキーのサンプルを次に示します。
ペイロード デコーダの結果。
バケットキーを取得したので、output_domain.avro を作成します。
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
スクリプトにより、現在のフォルダに output_domain.avro ファイルが作成されます。
4.5. レポートを AWS バケットに移動する
AVRO レポート(セクション 3.2.3)と出力ドメイン(セクション 3.2.4)が作成されたら、レポートと出力ドメインをレポート S3 バケットに移動します。
ローカル環境に AWS CLI が設定されている場合は、次のコマンドを使用して、レポートを対応する S3 バケットとレポート フォルダにコピーします。
aws s3 cp report.avro s3://<report_bucket_name>/<report_folder>/
aws s3 cp output_domain.avro s3://<report_bucket_name>/<output_domain_folder>/
5. 集計サービスの使用状況
terraform apply から、create_job_endpoint、get_job_endpoint、frontend_api_id が返されます。frontend_api_id をコピーし、前提条件セクション 1.9 で設定した Postman グローバル変数 frontend_api_id に配置します。
手順 5. 集計サービスの使用: 集計サービス API を使用して、概要レポートを作成し、概要レポートを確認します。
ステップ 5.1. createJob エンドポイントを使用して
ステップ 5.2. をバッチ処理します。getJob エンドポイントを使用してバッチ ステータスを取得する
ステップ 5.3. 概要レポートを確認する
5.1. createJob エンドポイントを使用してバッチ処理する
Postman で [Privacy Sandbox] コレクションを開き、[createJob] を選択します。
[Body] を選択し、[raw] を選択してリクエスト ペイロードを配置します。
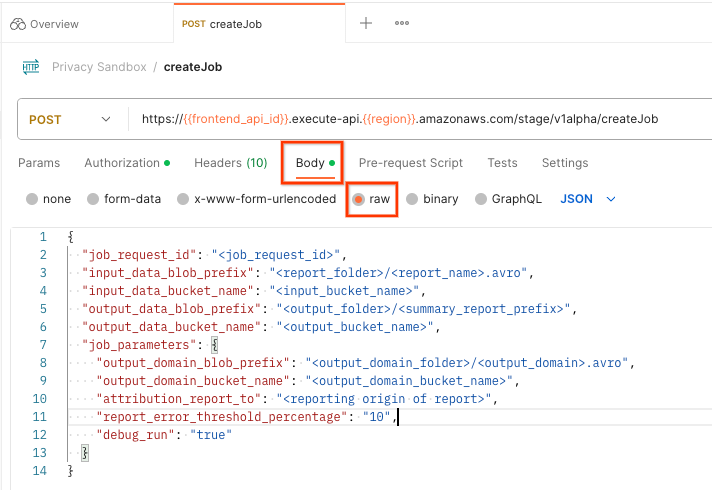 postman createJob リクエストの本文
postman createJob リクエストの本文
createJob ペイロード スキーマは github で入手できます。次のようになります。<> は、適切なフィールドに置き換えます。
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
], // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
[送信] をクリックすると、job_request_id を使用してジョブが作成されます。リクエストがアグリゲーション サービスによって受け入れられると、HTTP 202 レスポンスが返されます。その他の戻りコードについては、HTTP レスポンス コードをご覧ください。
 postman createJob リクエストのステータス
postman createJob リクエストのステータス
5.2. getJob エンドポイントを使用してバッチ ステータスを取得する
ジョブ リクエストのステータスを確認するには、getJob エンドポイントを使用します。[Privacy Sandbox] コレクションで [getJob] を選択します。
[Params] で、job_request_id の値を createJob リクエストで送信された job_request_id に更新します。
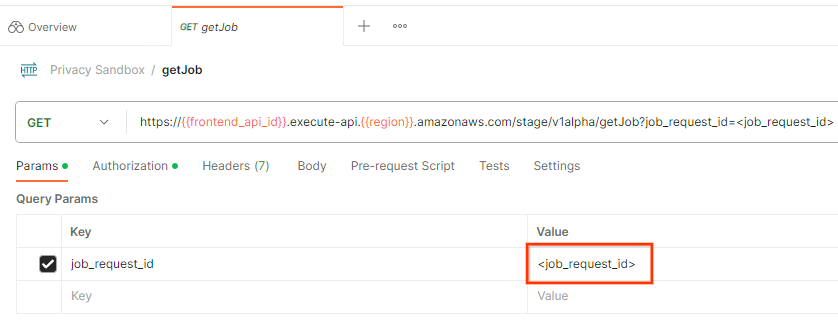 postman getJob リクエスト
postman getJob リクエスト
getJob の結果は、HTTP ステータス 200 でジョブ リクエストのステータスを返す必要があります。リクエストの「本文」には、job_status、return_message、error_messages(ジョブがエラーになった場合)などの必要な情報が含まれています。
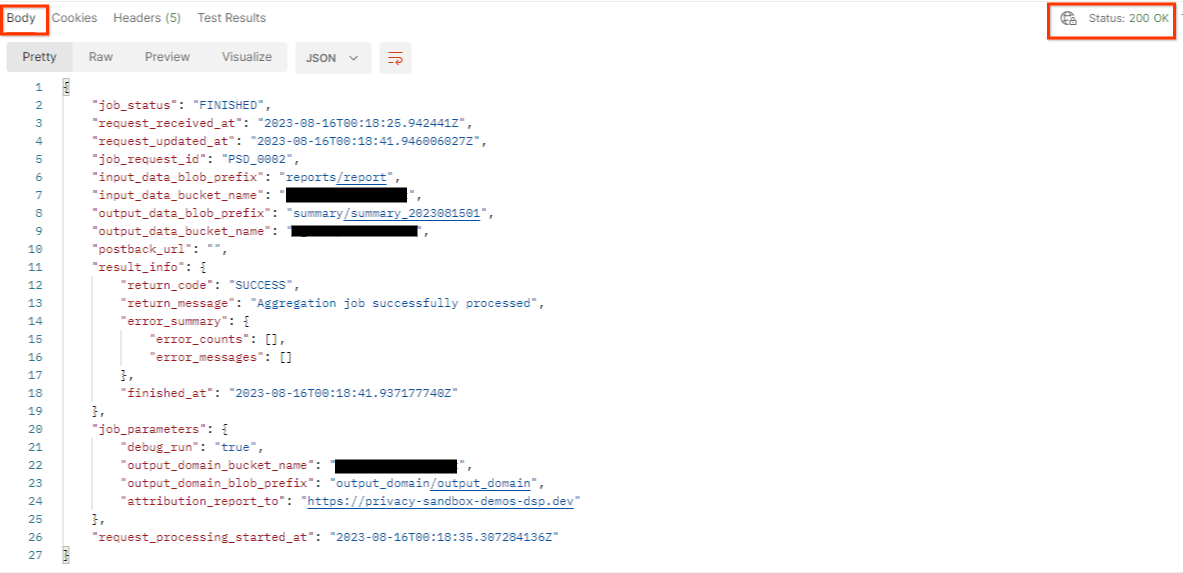 postman getJob リクエストのステータス
postman getJob リクエストのステータス
生成されたデモレポートのレポートサイトは、AWS ID のオンボーディングされたサイトとは異なるため、PRIVACY_BUDGET_AUTHORIZATION_ERROR return_code のレスポンスが返されることがあります。これは、レポートのレポート配信元のサイトが AWS ID にオンボーディングされたレポートサイトと一致しないため、正常な動作です。
{
"job_status": "FINISHED",
"request_received_at": "2023-12-07T22:50:58.830956Z",
"request_updated_at": "2023-12-07T22:51:10.526326456Z",
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"postback_url": "",
"result_info": {
"return_code": "PRIVACY_BUDGET_AUTHORIZATION_ERROR",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-12-07T22:51:10.517730898Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"attribution_report_to": "https://privacy-sandbox-demos-dsp.dev",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
},
"request_processing_started_at": "2023-12-07T22:51:06.034472697Z"
}
5.3. 概要レポートを確認する
出力 S3 バケットで概要レポートを受け取ったら、ローカル環境にダウンロードできます。概要レポートは AVRO 形式で、JSON に変換し直すことができます。aggregatable_report_converter.jar を使用してレポートを読み取るには、次のコマンドを使用します。
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
これにより、次の図のような各バケットキーの集計値の JSON が返されます。
 概要レポート。
概要レポート。
createJob リクエストに debug_run を true として含める場合、output_data_blob_prefix にあるデバッグ フォルダで概要レポートを受け取ることができます。レポートは AVRO 形式で、前のコマンドを使用して JSON に変換できます。
レポートには、バケットキー、ノイズが追加されていない指標、ノイズが追加されていない指標にノイズを追加して概要レポートを作成したものが含まれます。レポートは次の図のようになります。
 デバッグの概要レポート。
デバッグの概要レポート。
アノテーションには in_reports と in_domain も含まれています。これは次のことを意味します。
- in_reports - バケットキーは集計可能レポート内で使用できます。
- in_domain - バケットキーは output_domain AVRO ファイル内で使用できます。