
1. Pré-requisitos
Para realizar este codelab, alguns pré-requisitos são necessários. Cada requisito é marcado de acordo com a necessidade para "Teste local" ou "Serviço de agregação".
1.1. Baixar a ferramenta de teste local (teste local)
Para fazer testes locais, é necessário baixar a ferramenta de teste local. A ferramenta vai gerar relatórios resumidos com base nos relatórios de depuração não criptografados.
A ferramenta de teste local está disponível para download em Arquivos JAR do Lambda no GitHub. Ele precisa ser nomeado como LocalTestingTool_{version}.jar.
1.2. Verificar se o JRE do Java está instalado (teste local e serviço de agregação)
Abra o Terminal e use java --version para verificar se a máquina tem o Java ou o openJDK instalado.
 Checking java jre version using `java --version`.
Checking java jre version using `java --version`.
Se ele não estiver instalado, faça o download e instale no site do Java ou no site do openJDK.
1.3. Baixar o conversor de relatórios agregáveis (teste local e serviço de agregação)
Faça o download de uma cópia do conversor de relatórios agregáveis no repositório do GitHub de demonstrações do Sandbox de privacidade.
1.4. Ativar as APIs de privacidade de anúncios (teste local e serviço de agregação)
No navegador, acesse chrome://settings/adPrivacy e ative todas as APIs de privacidade de anúncios.
Verifique se os cookies de terceiros estão ativados.
No navegador, acesse chrome://settings/cookies e selecione Bloquear cookies de terceiros no modo de navegação anônima.
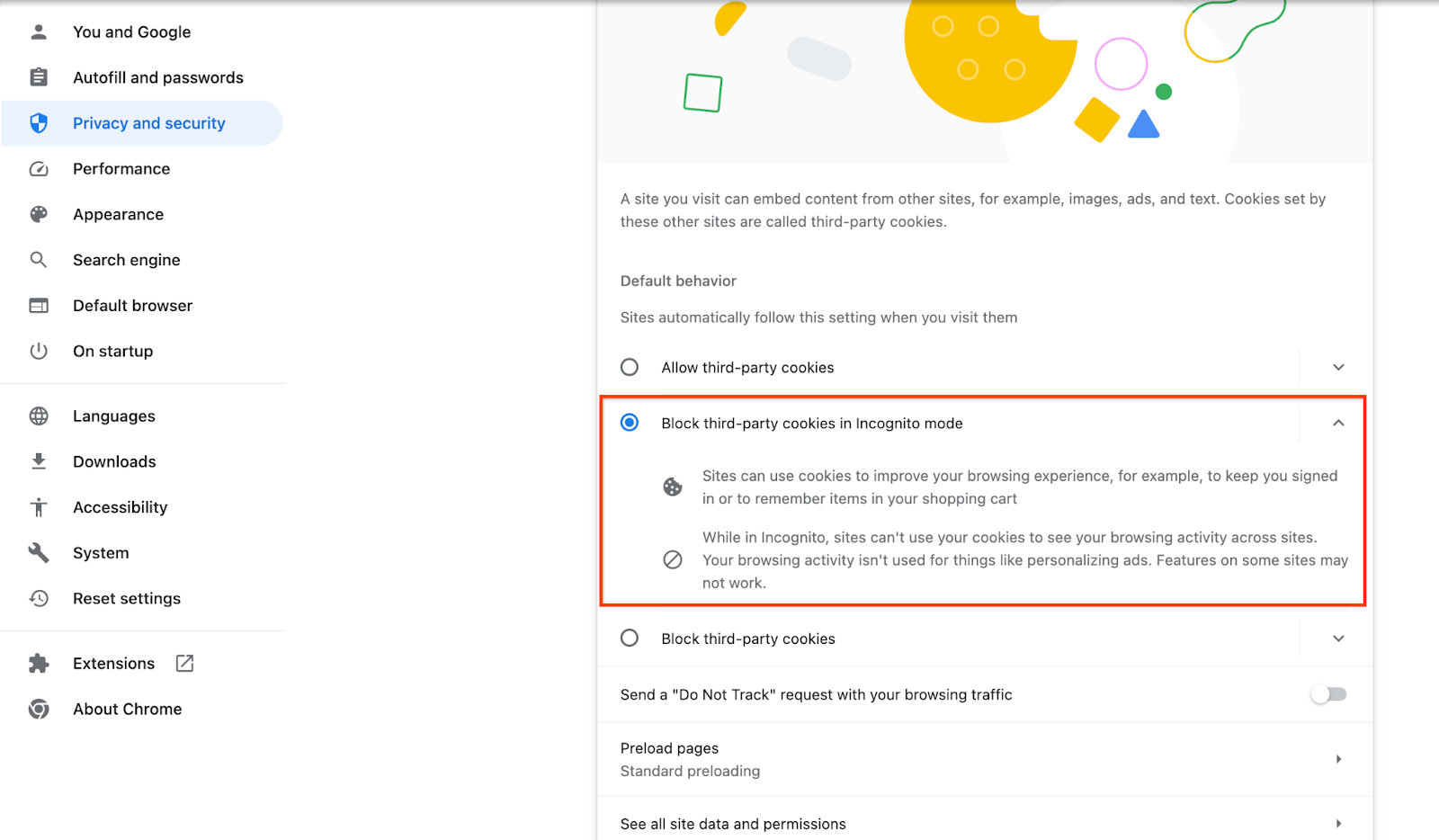 Configuração de cookies de terceiros no Chrome.
Configuração de cookies de terceiros no Chrome.
1.5. Inscrição na Web e no Android (serviço de agregação)
Para usar as APIs do Sandbox de privacidade em um ambiente de produção, conclua a inscrição e a atestação para o Chrome e o Android.
Para testes locais, o registro pode ser desativado usando uma flag do Chrome e uma opção de linha de comando.
Para usar a flag do Chrome na nossa demonstração, acesse chrome://flags/#privacy-sandbox-enrollment-overrides e atualize a substituição com seu site. Se você usar nosso site de demonstração, não será necessário fazer nenhuma atualização.
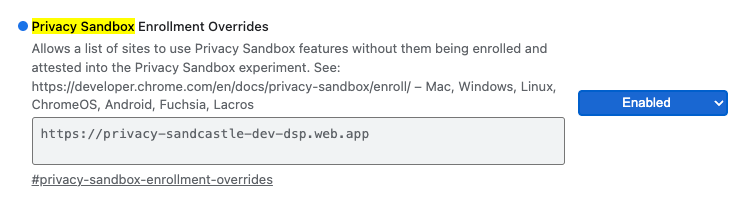 Substituição da inscrição no Sandbox de privacidade, flag do Chrome.
Substituição da inscrição no Sandbox de privacidade, flag do Chrome.
1.6. Integração do serviço de agregação (Aggregation Service)
O serviço de agregação exige integração com coordenadores para ser usado. Preencha o formulário de integração do serviço de agregação com o endereço do seu site de relatórios, o ID da conta da AWS e outras informações.
1.7. Provedor de nuvem (serviço de agregação)
O serviço de agregação exige o uso de um ambiente de execução confiável que usa um ambiente de nuvem. O serviço de agregação é compatível com a Amazon Web Services (AWS) e o Google Cloud (GCP). Este codelab vai abordar apenas a integração com a AWS.
A AWS oferece um ambiente de execução confiável chamado Nitro Enclaves. Verifique se você tem uma conta da AWS e siga as instruções de instalação e atualização da CLI da AWS para configurar seu ambiente da CLI da AWS.
Se a CLI da AWS for nova, configure-a usando as instruções de configuração da CLI.
1.7.1. Criar bucket do AWS S3
Crie um bucket do AWS S3 para armazenar o estado do Terraform e outro para armazenar seus relatórios e relatórios de resumo. Você pode usar o comando da CLI fornecido. Substitua o campo em <> pelas variáveis adequadas.
aws s3api create-bucket --bucket <tf_bucket_name> --region us-east-1
aws s3api create-bucket --bucket <report_bucket_name> --region us-east-1
1.7.2. Criar chave de acesso do usuário
Crie chaves de acesso do usuário usando o guia da AWS. Isso será usado para chamar os endpoints de API createJob e getJob criados na AWS.
1.7.3. Permissões de usuários e grupos da AWS
Para implantar o serviço de agregação na AWS, você precisa conceder determinadas permissões ao usuário usado para implantar o serviço. Para este codelab, verifique se o usuário tem acesso de administrador para garantir permissões completas na implantação.
1.8. Terraform (serviço de agregação)
Este codelab usa o Terraform para implantar o serviço de agregação. Verifique se o binário do Terraform está instalado no seu ambiente local.
Faça o download do binário do Terraform no seu ambiente local.
Depois que o binário do Terraform for baixado, extraia o arquivo e mova o binário para /usr/local/bin.
cp <directory>/terraform /usr/local/bin
Verifique se o Terraform está disponível no classpath.
terraform -v
1.9. Postman (para o serviço de agregação da AWS)
Neste codelab, use o Postman para gerenciar solicitações.
Para criar um espaço de trabalho, acesse o item de navegação superior Espaços de trabalho e selecione Criar espaço de trabalho.
 Espaço de trabalho do Postman
Espaço de trabalho do Postman
Selecione Espaço de trabalho em branco, clique em "Próxima" e dê o nome Sandbox de privacidade. Selecione Pessoal e clique em Criar.
Faça o download dos arquivos configuração JSON e ambiente global do espaço de trabalho pré-configurado.
Importe os arquivos JSON para Meu espaço de trabalho usando o botão Importar.
 Importe arquivos JSON do Postman.
Importe arquivos JSON do Postman.
Isso vai criar a coleção do Sandbox de privacidade para você junto com as solicitações HTTP createJob e getJob.
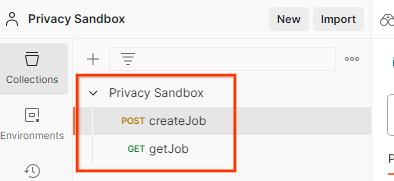 Coleção importada do Postman.
Coleção importada do Postman.
Atualize a "Chave de acesso" e a "Chave secreta" da AWS em Visão geral rápida do ambiente.
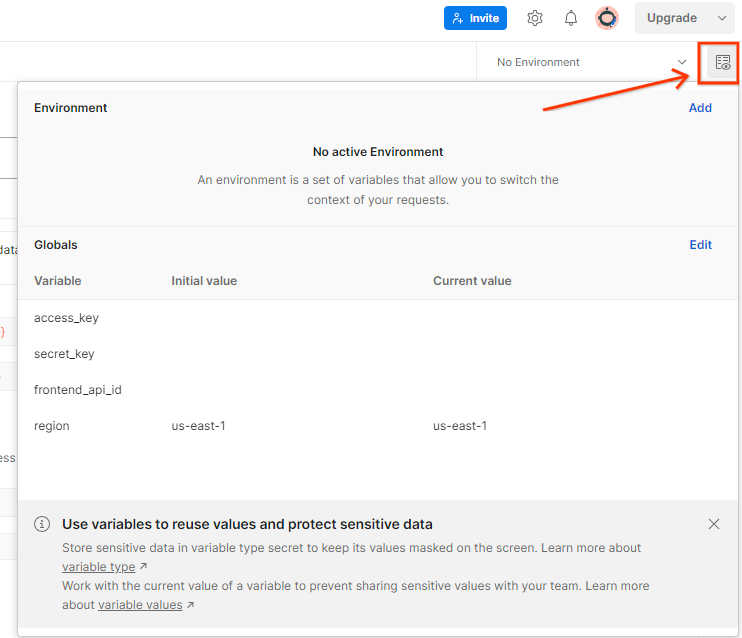 Visão geral rápida do ambiente do Postman.
Visão geral rápida do ambiente do Postman.
Clique em Editar e atualize o "Valor atual" de access_key e secret_key. O frontend_api_id será fornecido na seção 3.1.4 deste documento. Recomendamos usar a região us-east-1. No entanto, se você quiser fazer a implantação em uma região diferente, verifique se copiou a AMI lançada para sua conta ou faça uma autocompilação usando os scripts fornecidos.
 Variáveis globais do Postman.
Variáveis globais do Postman. 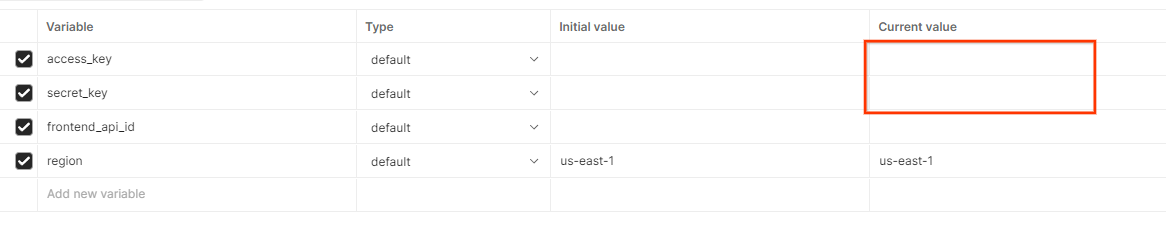 Editar variáveis globais do Postman.
Editar variáveis globais do Postman.
2. Codelab de testes locais
Você pode usar a ferramenta de teste local na sua máquina para fazer a agregação e gerar relatórios resumidos usando os relatórios de depuração não criptografados.
Etapas do codelab
Etapa 2.1. Acionar relatório: acione a geração de relatórios da API Private Aggregation para coletar o relatório.
Etapa 2.2. Criar relatório agregável de depuração: converta o relatório JSON coletado em um relatório formatado em AVRO.
Esta etapa é semelhante a quando as adtechs coletam os relatórios dos endpoints de relatórios da API e convertem os relatórios JSON para o formato AVRO.
Etapa 2.3. Analise a chave do bucket no relatório de depuração: as chaves do bucket são projetadas por adtechs. Neste codelab, como os buckets são predefinidos, recupere as chaves conforme fornecidas.
Etapa 2.4. Crie o AVRO de domínio de saída: depois que as chaves de bucket forem recuperadas, crie o arquivo AVRO de domínio de saída.
Etapa 2.5. Crie relatórios de resumo usando a Ferramenta de teste local: use a Ferramenta de teste local para criar relatórios de resumo no ambiente local.
Etapa 2.6. Analise o relatório de resumo: confira o relatório de resumo criado pela ferramenta de teste local.
2.1. Relatório de acionador
Acesse o site da demonstração do Sandbox de privacidade. Isso aciona um relatório de agregação particular. Confira o relatório em chrome://private-aggregation-internals.
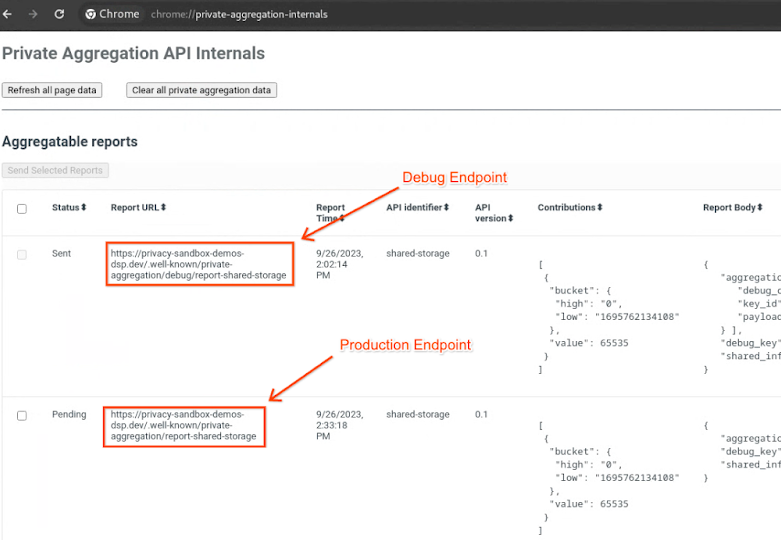 Internos da agregação particular do Chrome.
Internos da agregação particular do Chrome.
Se o relatório estiver com o status Pendente, selecione-o e clique em Enviar relatórios selecionados.
 Enviar relatório de agregação privada.
Enviar relatório de agregação privada.
2.2. Criar relatório agregável de depuração
Em chrome://private-aggregation-internals, copie o corpo do relatório recebido no endpoint [reporting-origin]/.well-known/private-aggregation/report-shared-storage.
Verifique se, no corpo do relatório, o aggregation_coordinator_origin contém https://publickeyservice.msmt.aws.privacysandboxservices.com, o que significa que o relatório é agregável da AWS.
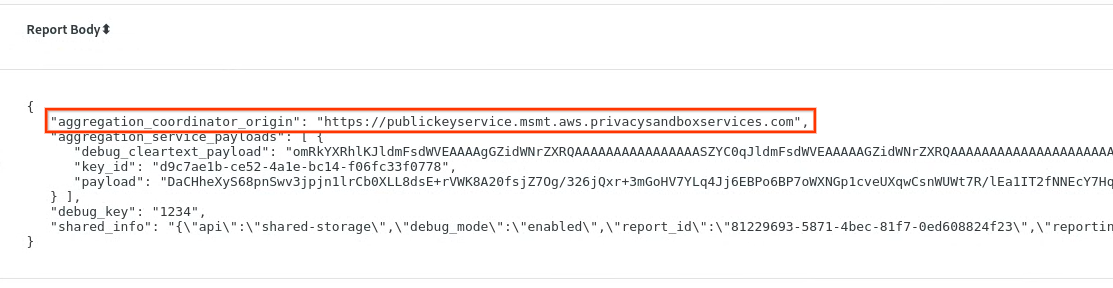 Relatório de agregação privada.
Relatório de agregação privada.
Coloque o corpo do relatório JSON em um arquivo JSON. Neste exemplo, você pode usar o vim. Mas você pode usar qualquer editor de texto.
vim report.json
Cole o relatório em report.json e salve o arquivo.
 Arquivo JSON do relatório.
Arquivo JSON do relatório.
Depois disso, navegue até a pasta de relatórios e use aggregatable_report_converter.jar para criar o relatório agregável de depuração. Isso cria um relatório agregável chamado report.avro no diretório atual.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Analisar a chave do bucket no relatório de depuração
O serviço de agregação exige dois arquivos ao fazer o agrupamento em lote. O relatório agregável e o arquivo de domínio de saída. O arquivo de domínio de saída contém as chaves que você quer recuperar dos relatórios agregáveis. Para criar o arquivo output_domain.avro, você precisa das chaves do bucket que podem ser recuperadas dos relatórios.
As chaves de bucket são projetadas pelo caller da API, e a demonstração contém exemplos pré-criados de chaves de bucket. Como a demonstração ativou o modo de depuração para agregação privada, é possível analisar o payload de texto não criptografado de depuração do corpo do relatório para recuperar a chave do bucket. No entanto, nesse caso, o site Demonstração do Sandbox de privacidade cria as chaves de agrupamento. Como a agregação particular para este site está no modo de depuração, você pode usar o debug_cleartext_payload do corpo do relatório para receber a chave do bucket.
Copie o debug_cleartext_payload do corpo do relatório.
 Depure o payload de texto simples do corpo do relatório.
Depure o payload de texto simples do corpo do relatório.
Abra a ferramenta Decodificador de payload de depuração para agregação privada, cole seu debug_cleartext_payload na caixa INPUT e clique em Decode.
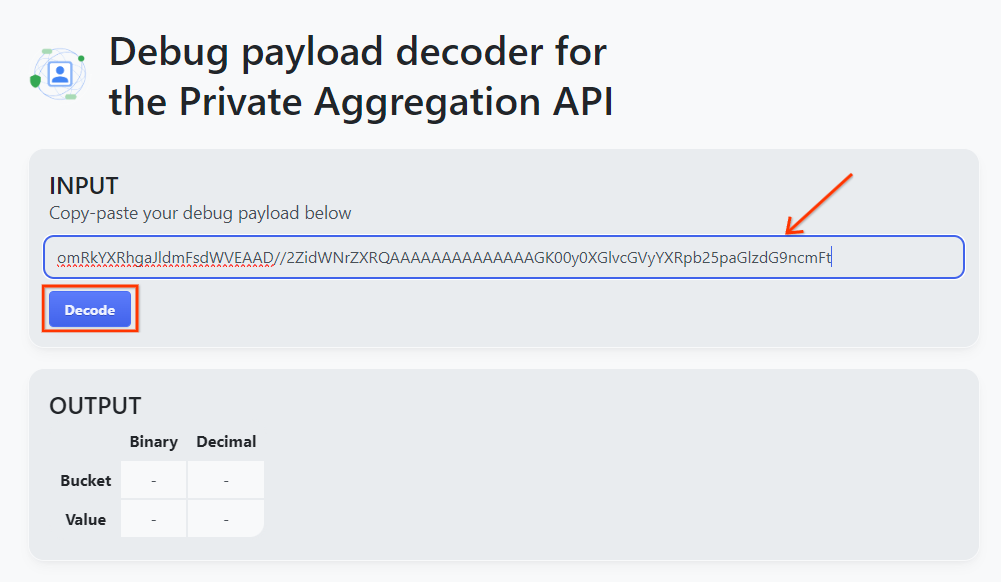 Decodificador de payload.
Decodificador de payload.
A página retorna o valor decimal da chave do bucket. Confira a seguir um exemplo de chave de bucket.
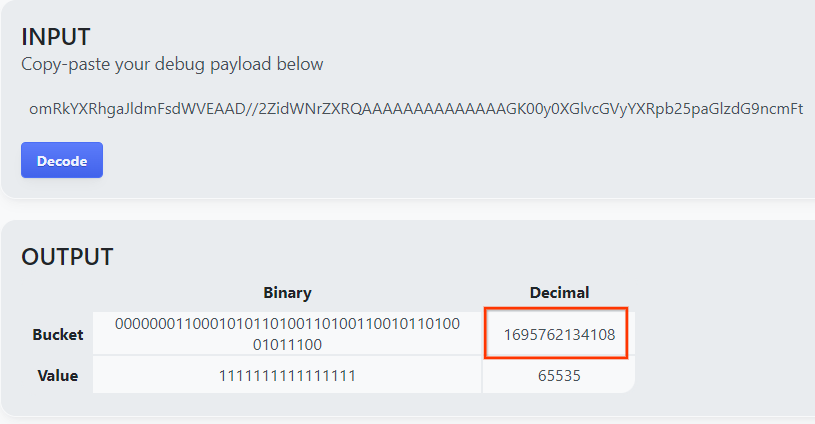 Resultado do decodificador de payload.
Resultado do decodificador de payload.
2.4. Criar o AVRO do domínio de saída
Agora que temos a chave do bucket, copie o valor decimal dela. Crie o output_domain.avro usando a chave do bucket. Verifique se você substituiu
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
O script cria o arquivo output_domain.avro na pasta atual.
2.5. Criar relatórios de resumo usando a Ferramenta de teste local
Vamos usar o LocalTestingTool_{version}.jar baixado na seção 1.1 para criar os relatórios de resumo. Use o seguinte comando. Substitua LocalTestingTool_{version}.jar pela versão baixada para a LocalTestingTool.
Execute o comando a seguir para gerar um relatório de resumo no seu ambiente de desenvolvimento local:
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
Você vai ver algo parecido com a imagem a seguir depois que o comando for executado. Um relatório output.avro é criado quando isso é concluído.
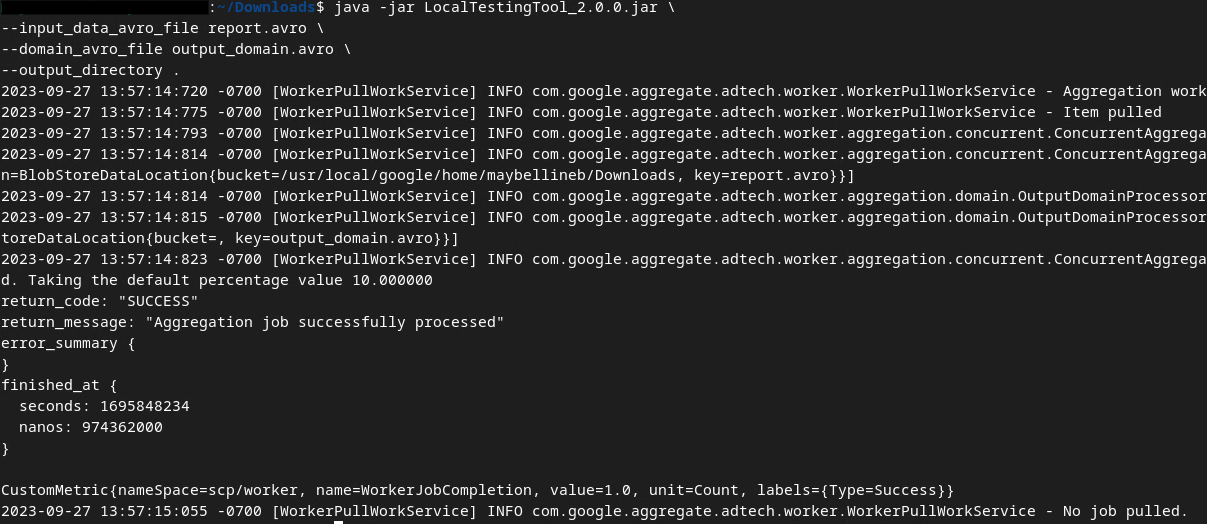 Arquivo Avro do relatório de resumo do teste local.
Arquivo Avro do relatório de resumo do teste local.
2.6. Analisar o relatório resumido
O relatório de resumo criado está no formato AVRO. Para ler isso, é necessário converter de AVRO para um formato JSON. O ideal é que a tecnologia de publicidade codifique para converter relatórios AVRO de volta para JSON.
Para este codelab, vamos usar a ferramenta aggregatable_report_converter.jar fornecida para converter o relatório AVRO de volta para JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Isso retorna um relatório semelhante à imagem a seguir. Junto com um relatório output.json criado no mesmo diretório.
 Arquivo avro de resumo convertido para json.
Arquivo avro de resumo convertido para json.
Abra o arquivo JSON em um editor de sua escolha para analisar o relatório de resumo.
3. Implantação do serviço de agregação
Para implantar o serviço de agregação, siga estas etapas:
Etapa 3. Implantação do serviço de agregação: implante o serviço de agregação na AWS
Etapa 3.1 Clone o repositório do serviço de agregação
Etapa 3.2 Baixar dependências pré-criadas
Etapa 3.3 Criar um ambiente de desenvolvimento
Etapa 3.4 Implantar o serviço de agregação
3.1. Clonar o repositório do serviço de agregação
No seu ambiente local, clone o repositório do GitHub do serviço de agregação.
git clone https://github.com/privacysandbox/aggregation-service.git
3.2. Baixar dependências pré-criadas
Depois de clonar o repositório do serviço de agregação, acesse a pasta do Terraform e a pasta da nuvem correspondente. Se o cloud_provider for a AWS, siga para
cd <repository_root>/terraform/aws
Em download_prebuilt_dependencies.sh.
bash download_prebuilt_dependencies.sh
3.3. Criar um ambiente de desenvolvimento
Crie um ambiente de desenvolvimento em dev.
mkdir dev
Copie o conteúdo da pasta demo para a pasta dev.
cp -R demo/* dev
Acesse a pasta dev.
cd dev
Atualize o arquivo main.tf e pressione i para input editar o arquivo.
vim main.tf
Remova a marca de comentário do código na caixa vermelha, excluindo o # e atualizando os nomes do bucket e da chave.
Para o main.tf da AWS:
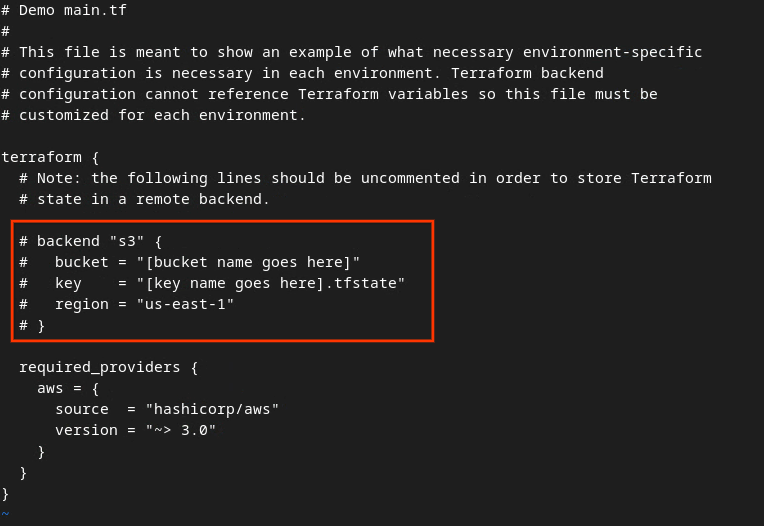 Arquivo tf principal da AWS.
Arquivo tf principal da AWS.
O código sem comentários vai ficar assim.
backend "s3" {
bucket = "<tf_state_bucket_name>"
key = "<environment_name>.tfstate"
region = "us-east-1"
}
Quando as atualizações estiverem concluídas, salve-as e saia do editor pressionando esc -> :wq!. Isso salva as atualizações em main.tf.
Em seguida, renomeie example.auto.tfvars como dev.auto.tfvars.
mv example.auto.tfvars dev.auto.tfvars
Atualize dev.auto.tfvars e pressione i para input editar o arquivo.
vim dev.auto.tfvars
Atualize os campos na caixa vermelha seguindo a imagem com os parâmetros corretos de ARN da AWS fornecidos durante a integração do serviço de agregação, o ambiente e o e-mail de notificação.
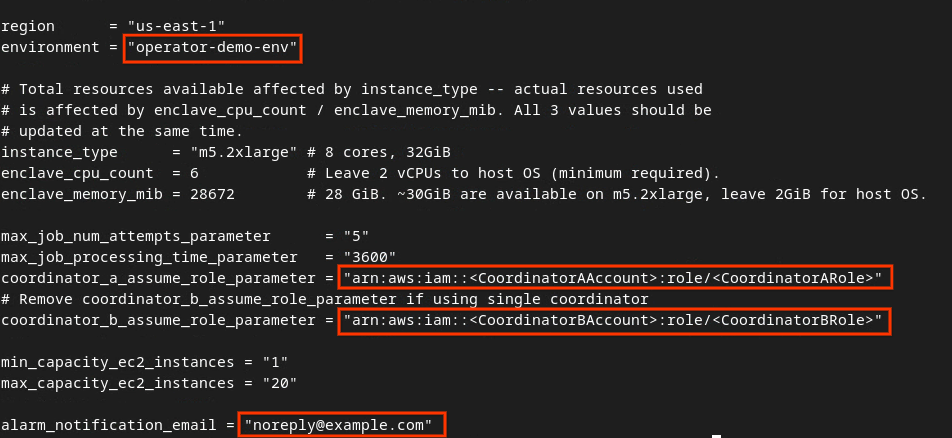 Edite o arquivo tfvars de desenvolvimento automático.
Edite o arquivo tfvars de desenvolvimento automático.
Quando as atualizações forem concluídas, pressione esc -> :wq!. Isso salva o arquivo dev.auto.tfvars, que deve ficar parecido com a imagem a seguir.
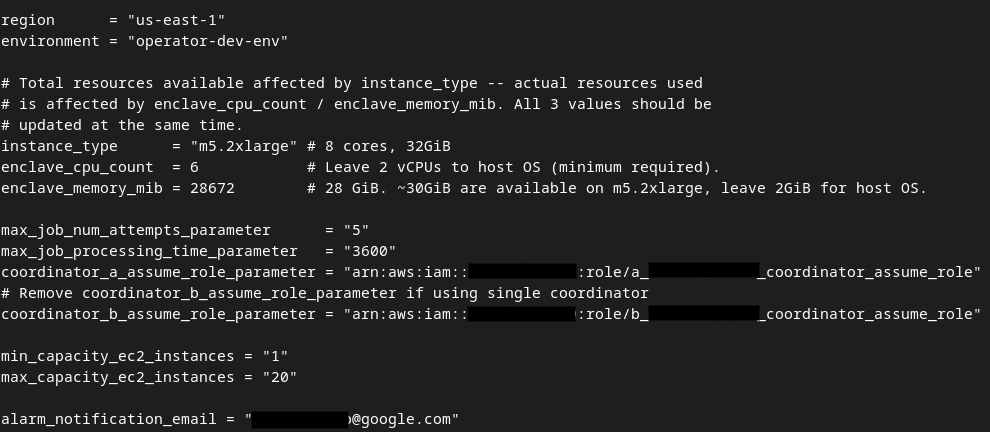 Arquivo tfvars de desenvolvimento automático atualizado.
Arquivo tfvars de desenvolvimento automático atualizado.
3.4. Implantar o serviço de agregação
Para implantar o serviço de agregação, na mesma pasta
terraform init
Isso vai retornar algo semelhante à imagem a seguir:
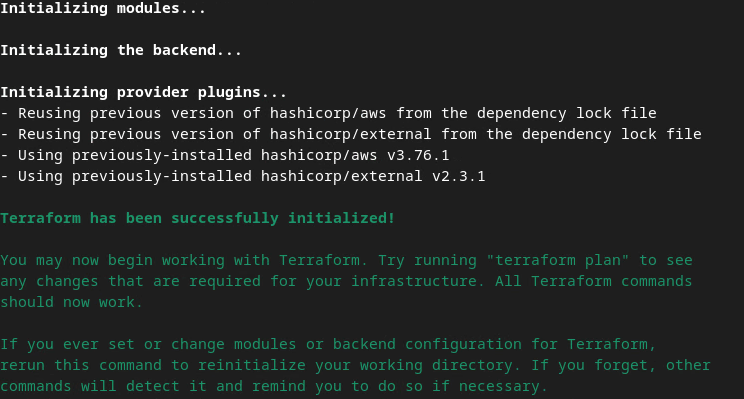 Terraform init.
Terraform init.
Depois que o Terraform for inicializado, crie o plano de execução dele. Ele retorna o número de recursos a serem adicionados e outras informações adicionais semelhantes à imagem a seguir.
terraform plan
Confira abaixo o resumo do Plano. Se for uma implantação nova, você vai ver o número de recursos que serão adicionados com 0 para mudar e 0 para destruir.
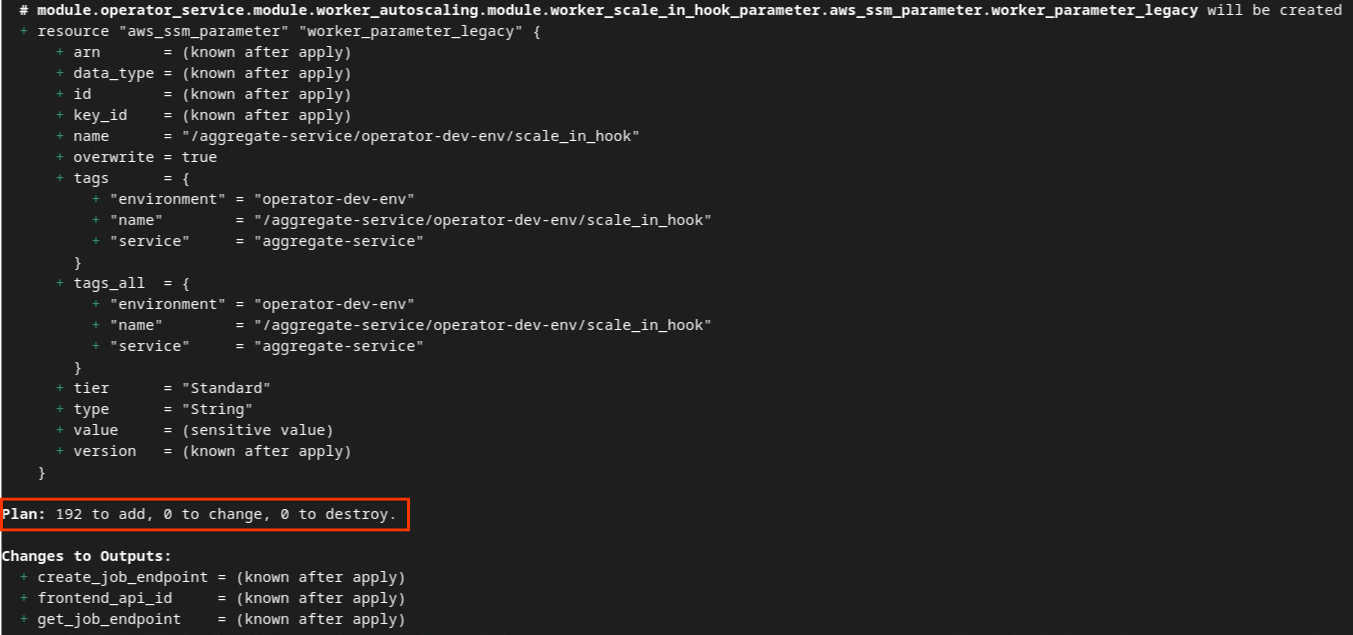 Plano do Terraform.
Plano do Terraform.
Depois de concluir essa etapa, você poderá aplicar o Terraform.
terraform apply
Quando for solicitada a confirmação das ações pelo Terraform, insira um yes no valor.
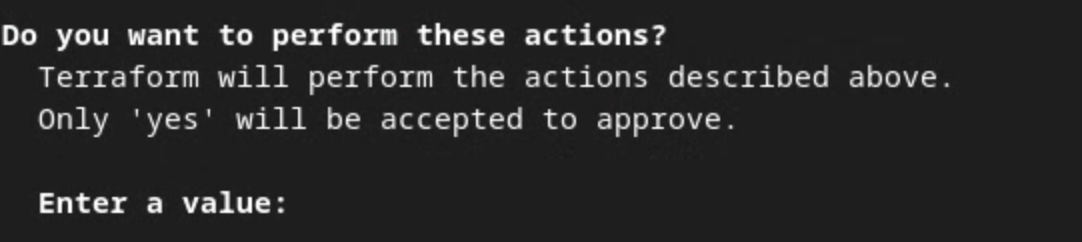 Solicitação de aplicação do Terraform.
Solicitação de aplicação do Terraform.
Quando terraform apply terminar, os seguintes endpoints para createJob e getJob serão retornados. O frontend_api_id que você precisa atualizar no Postman na seção 1.9 também é retornado.
 A aplicação do Terraform foi concluída.
A aplicação do Terraform foi concluída.
4. Criação de entrada do serviço de agregação
Crie os relatórios AVRO para agrupamento em lote no Serviço de agregação.
Etapa 4: Criação de entrada do serviço de agregação: crie os relatórios do serviço de agregação que são agrupados em lotes para o serviço de agregação.
Etapa 4.1 Relatório de acionamento
Etapa 4.2 Coletar relatórios agregáveis
Etapa 4.3 Converter relatórios para AVRO
Etapa 4.4 Criar o AVRO do domínio de saída
4.1. Relatório de acionador
Acesse o site da demonstração do Sandbox de privacidade. Isso aciona um relatório de agregação particular. Confira o relatório em chrome://private-aggregation-internals.
Internos da agregação particular do Chrome.
Se o relatório estiver com o status Pendente, selecione-o e clique em Enviar relatórios selecionados. "
Enviar relatório de agregação privada.
4.2. Coletar relatórios agregáveis
Colete seus relatórios agregáveis dos endpoints .well-known da API correspondente.
- Private Aggregation
[reporting-origin] /.well-known/private-aggregation/report-shared-storage - Attribution Reporting: relatório de resumo
[reporting-origin] /.well-known/attribution-reporting/report-aggregate-attribution
Neste codelab, você vai coletar a coleção de relatórios manualmente. Em produção, espera-se que as adtechs coletem e convertam os relatórios de forma programática.
Em chrome://private-aggregation-internals, copie o corpo do relatório recebido no endpoint [reporting-origin]/.well-known/private-aggregation/report-shared-storage.
Verifique se, no corpo do relatório, o aggregation_coordinator_origin contém https://publickeyservice.msmt.aws.privacysandboxservices.com, o que significa que o relatório é agregável da AWS.
Relatório de agregação privada.
Coloque o corpo do relatório JSON em um arquivo JSON. Neste exemplo, você pode usar o vim. Mas você pode usar qualquer editor de texto.
vim report.json
Cole o relatório em report.json e salve o arquivo.
Arquivo JSON do relatório.
4.3. Converter relatórios para AVRO
Os relatórios recebidos dos endpoints .well-known estão no formato JSON e precisam ser convertidos para o formato AVRO. Depois de ter o relatório JSON, navegue até a pasta de relatórios e use aggregatable_report_converter.jar para ajudar a criar o relatório agregável de depuração. Isso cria um relatório agregável chamado report.avro no diretório atual.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
4.4. Criar o AVRO do domínio de saída
Para criar o arquivo output_domain.avro, você precisa das chaves do bucket que podem ser recuperadas dos relatórios.
As chaves de agrupamento são projetadas pela adtech. No entanto, nesse caso, a demonstração do Sandbox de privacidade cria as chaves de agrupamento. Como a agregação particular para este site está no modo de depuração, você pode usar o debug_cleartext_payload do corpo do relatório para receber a chave do bucket.
Copie o debug_cleartext_payload do corpo do relatório.
Depure o payload de texto simples do corpo do relatório.
Abra goo.gle/ags-payload-decoder, cole seu debug_cleartext_payload na caixa INPUT e clique em Decode.
Decodificador de payload.
A página retorna o valor decimal da chave do bucket. Confira a seguir um exemplo de chave de bucket.
Resultado do decodificador de payload.
Agora que temos a chave do bucket, crie o output_domain.avro. Verifique se você substituiu
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
O script cria o arquivo output_domain.avro na pasta atual.
4.5. Mover relatórios para um bucket da AWS
Depois que os relatórios AVRO (da seção 3.2.3) e o domínio de saída (da seção 3.2.4) forem criados, mova os relatórios e o domínio de saída para os buckets do S3 de relatórios.
Se você tiver a CLI da AWS configurada no seu ambiente local, use os comandos a seguir para copiar os relatórios para o bucket do S3 e a pasta de relatórios correspondentes.
aws s3 cp report.avro s3://<report_bucket_name>/<report_folder>/
aws s3 cp output_domain.avro s3://<report_bucket_name>/<output_domain_folder>/
5. Uso da Aggregation Service
Na terraform apply, você recebe o create_job_endpoint, o get_job_endpoint e o frontend_api_id. Copie o frontend_api_id e coloque na variável global do Postman frontend_api_id, que você configurou na seção de pré-requisitos 1.9.
Etapa 5: Uso do Serviço de agregação: use a API do Serviço de agregação para criar e analisar relatórios resumidos.
Etapa 5.1 Usar o endpoint createJob para agrupar
Etapa 5.2 Como usar o endpoint getJob para recuperar o status do lote
Etapa 5.3 Como analisar o relatório de resumo
5.1. Como usar o endpoint createJob para fazer lotes
No Postman, abra a coleção Privacy Sandbox e selecione createJob.
Selecione Corpo e raw para colocar o payload da solicitação.
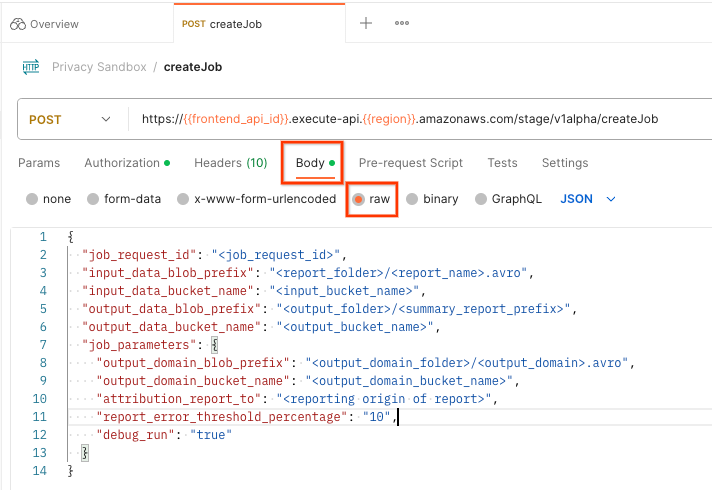 postman createJob request body
postman createJob request body
O esquema de payload createJob está disponível no GitHub e é semelhante ao seguinte. Substitua <> pelos campos adequados.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
], // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Depois de clicar em Enviar, o job será criado com o job_request_id. Você vai receber uma resposta HTTP 202 quando a solicitação for aceita pelo serviço de agregação. Outros códigos de retorno possíveis podem ser encontrados em códigos de resposta HTTP.
 postman createJob request status
postman createJob request status
5.2. Como usar o endpoint getJob para recuperar o status do lote
Para verificar o status da solicitação de job, use o endpoint getJob. Selecione "getJob" na coleção "Sandbox de privacidade".
Em Params, atualize o valor de "job_request_id" para o job_request_id enviado na solicitação createJob.
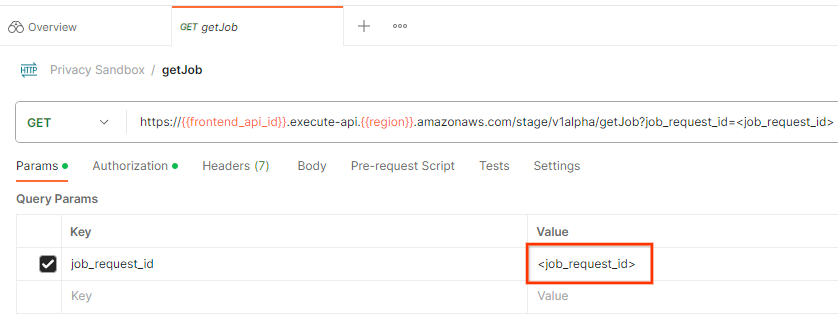 Solicitação getJob do Postman
Solicitação getJob do Postman
O resultado de getJob precisa retornar o status da sua solicitação de job com um status HTTP 200. A solicitação Body contém as informações necessárias, como job_status, return_message e error_messages (se o job tiver apresentado um erro).
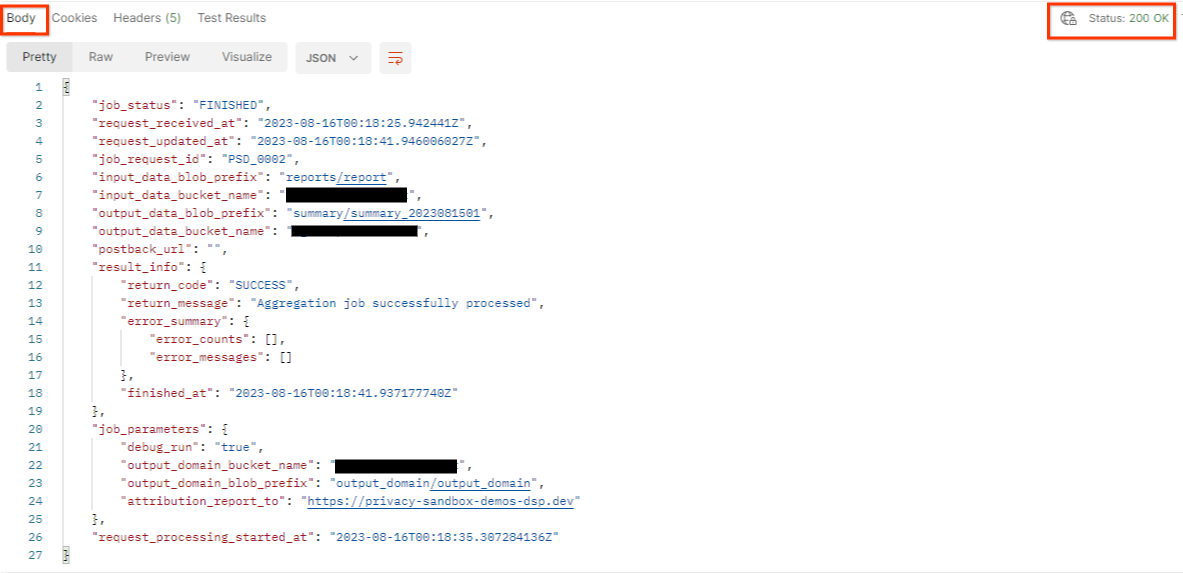 postman getJob request status
postman getJob request status
Como o site de relatórios do relatório de demonstração gerado é diferente do site integrado no seu ID da AWS, você pode receber uma resposta com PRIVACY_BUDGET_AUTHORIZATION_ERROR return_code. Isso é normal, já que o site da origem do relatório não corresponde ao site de geração de relatórios integrado para o ID da AWS.
{
"job_status": "FINISHED",
"request_received_at": "2023-12-07T22:50:58.830956Z",
"request_updated_at": "2023-12-07T22:51:10.526326456Z",
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"postback_url": "",
"result_info": {
"return_code": "PRIVACY_BUDGET_AUTHORIZATION_ERROR",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-12-07T22:51:10.517730898Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"attribution_report_to": "https://privacy-sandbox-demos-dsp.dev",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
},
"request_processing_started_at": "2023-12-07T22:51:06.034472697Z"
}
5.3. Como analisar o relatório de resumo
Depois de receber o relatório de resumo no bucket de saída do S3, faça o download dele para o ambiente local. Os relatórios de resumo estão no formato AVRO e podem ser convertidos de volta para um JSON. É possível usar aggregatable_report_converter.jar para ler o relatório com o comando a seguir.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Isso retorna um JSON de valores agregados de cada chave de agrupamento semelhante à imagem a seguir.
 Relatório de resumo.
Relatório de resumo.
Se a solicitação de createJob incluir debug_run como true, você poderá receber o relatório de resumo na pasta de depuração localizada em output_data_blob_prefix. O relatório está no formato AVRO e pode ser convertido em JSON usando o comando anterior.
O relatório contém a chave do agrupamento, a métrica sem ruído e o ruído adicionado a ela para formar o relatório de resumo. O relatório é semelhante à imagem a seguir.
 Relatório de resumo de depuração.
Relatório de resumo de depuração.
As anotações também contêm in_reports e in_domain, o que significa:
- in_reports: a chave do agrupamento está disponível nos relatórios agregáveis.
- in_domain: a chave do bucket está disponível no arquivo AVRO output_domain.