
1. Wymagania wstępne
Aby wykonać to ćwiczenie, musisz spełnić kilka warunków wstępnych. Każde wymaganie jest odpowiednio oznaczone, aby wskazać, czy jest wymagane w przypadku „Testowania lokalnego” czy „Usługi agregacji”.
1.1. Pobieranie narzędzia do testowania lokalnego (testowanie lokalne)
Testy lokalne wymagają pobrania narzędzia do testów lokalnych. Narzędzie wygeneruje raporty podsumowujące na podstawie niezaszyfrowanych raportów debugowania.
Narzędzie do testowania lokalnego można pobrać z archiwów JAR Lambda w GitHub. Powinien nazywać się LocalTestingTool_{version}.jar.
1.2. Sprawdź, czy jest zainstalowane środowisko JAVA JRE (usługa testowania lokalnego i usługa agregacji)
Otwórz „Terminal” i użyj polecenia java --version, aby sprawdzić, czy na komputerze jest zainstalowana Java lub openJDK.
 Sprawdzanie wersji środowiska Java JRE za pomocą polecenia `java --version`.
Sprawdzanie wersji środowiska Java JRE za pomocą polecenia `java --version`.
Jeśli nie jest zainstalowana, możesz ją pobrać i zainstalować ze strony Javy lub strony openJDK.
1.3. Pobieranie konwertera raportów z możliwością agregacji (testowanie lokalne i usługa agregacji)
Kopię konwertera raportów z możliwością agregacji możesz pobrać z repozytorium GitHub z wersjami demonstracyjnymi Piaskownicy prywatności.
1.4. Włączanie interfejsów Ad Privacy API (testowanie lokalne i usługa agregacji)
W przeglądarce otwórz chrome://settings/adPrivacy i włącz wszystkie interfejsy Ad Privacy API.
Sprawdź, czy włączona jest obsługa plików cookie innych firm.
W przeglądarce kliknij chrome://settings/cookies i wybierz „Blokuj pliki cookie innych firm w trybie incognito”.
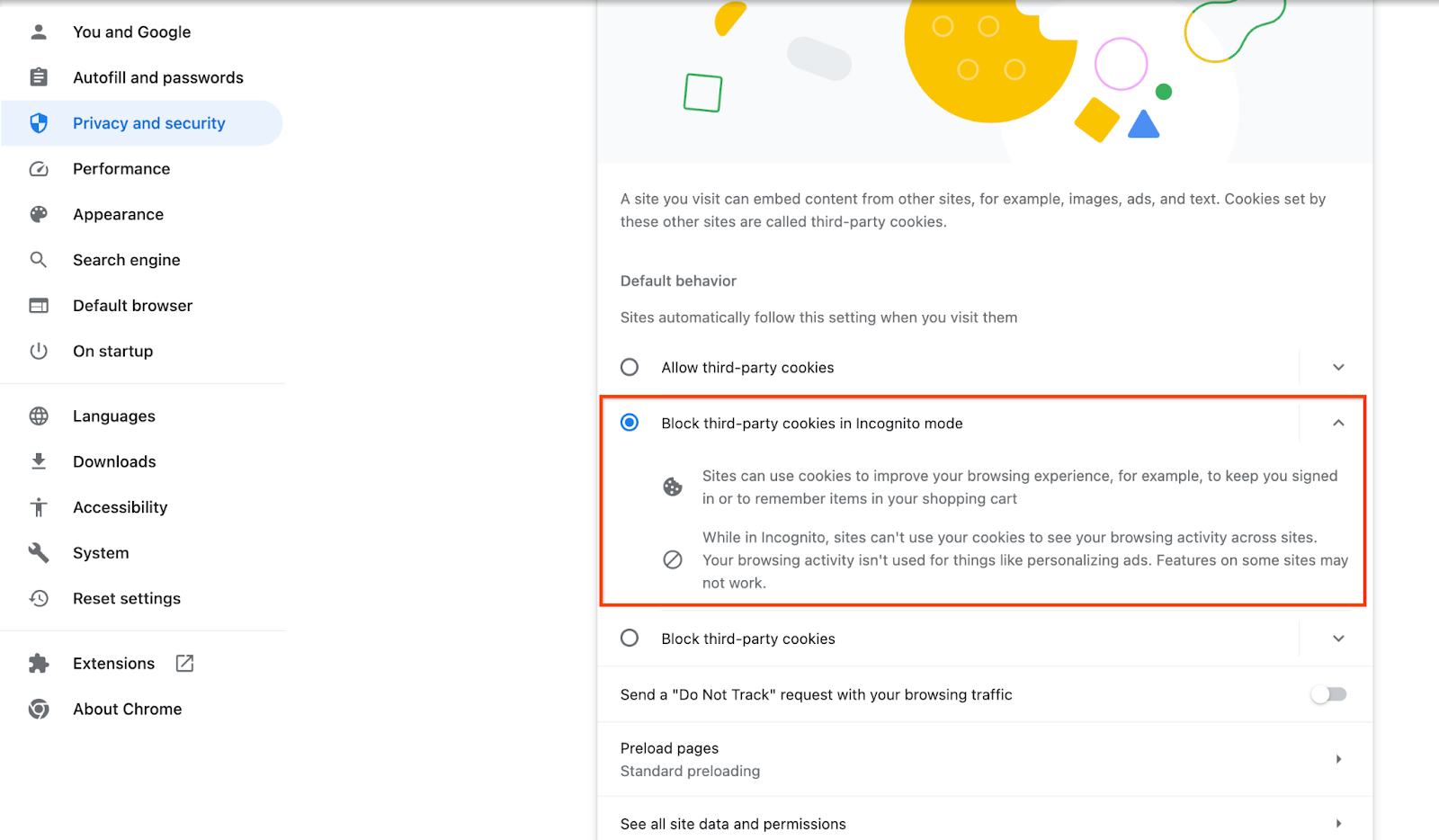 Ustawienie plików cookie innych firm w Chrome.
Ustawienie plików cookie innych firm w Chrome.
1.5. Rejestracja w internecie i na Androidzie (usługa do agregacji)
Aby korzystać z interfejsów API Piaskownicy prywatności w środowisku produkcyjnym, musisz przejść rejestrację i atest zarówno w Chrome, jak i na Androidzie.
W przypadku testów lokalnych rejestrację można wyłączyć za pomocą flagi Chrome i przełącznika interfejsu wiersza poleceń.
Aby użyć flagi Chrome w naszej wersji demonstracyjnej, otwórz chrome://flags/#privacy-sandbox-enrollment-overrides i zastąp ją swoją witryną. Jeśli będziesz korzystać z naszej witryny demonstracyjnej, nie musisz niczego zmieniać.
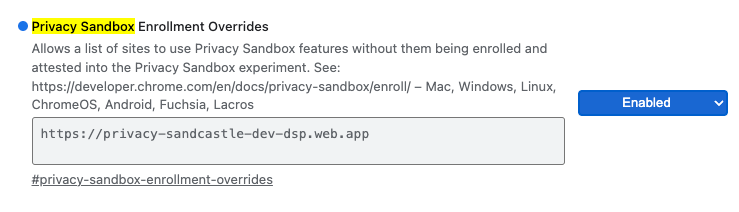 Flaga Chrome zastępująca rejestrację w Piaskownicy prywatności.
Flaga Chrome zastępująca rejestrację w Piaskownicy prywatności.
1.6. Wprowadzenie do usługi do agregacji (usługa do agregacji)
Aby korzystać z usługi agregacji, musisz przejść proces wprowadzania koordynatorów. Wypełnij formularz rejestracji w usłudze agregacji, podając adres witryny raportowania, identyfikator konta AWS i inne informacje.
1.7. Dostawca chmury (usługa do agregacji)
Usługa agregacji wymaga użycia zaufanego środowiska wykonawczego, które korzysta ze środowiska chmurowego. Usługa agregacji jest obsługiwana w Amazon Web Services (AWS) i Google Cloud (GCP). Te ćwiczenia obejmują tylko integrację z AWS.
AWS udostępnia zaufane środowisko wykonawcze o nazwie Nitro Enclaves. Sprawdź, czy masz konto AWS, i postępuj zgodnie z instrukcjami instalacji i aktualizacji interfejsu AWS CLI, aby skonfigurować środowisko interfejsu AWS CLI.
Jeśli Twój interfejs AWS CLI jest nowy, możesz go skonfigurować, korzystając z instrukcji konfiguracji interfejsu wiersza poleceń.
1.7.1. Tworzenie zasobnika AWS S3
Utwórz zasobnik AWS S3 do przechowywania stanu Terraform oraz kolejny zasobnik S3 do przechowywania raportów i raportów podsumowujących. Możesz użyć podanego polecenia interfejsu wiersza poleceń. Zastąp pole w <> odpowiednimi zmiennymi.
aws s3api create-bucket --bucket <tf_bucket_name> --region us-east-1
aws s3api create-bucket --bucket <report_bucket_name> --region us-east-1
1.7.2. Tworzenie klucza dostępu użytkownika
Utwórz klucze dostępu użytkownika, korzystając z przewodnika AWS. Będzie on używany do wywoływania punktów końcowych interfejsu API createJob i getJob utworzonych w AWS.
1.7.3. Uprawnienia użytkowników i grup AWS
Aby wdrożyć usługę agregacji w AWS, musisz przyznać określone uprawnienia użytkownikowi, który będzie wdrażać usługę. W tym laboratorium sprawdź, czy użytkownik ma dostęp administracyjny, aby mieć pewność, że ma pełne uprawnienia do wdrożenia.
1.8. Terraform (usługa do agregacji)
W tym module Codelab używamy Terraform do wdrożenia usługi agregacji. Sprawdź, czy w środowisku lokalnym jest zainstalowany plik binarny Terraform.
Pobierz plik binarny Terraform do środowiska lokalnego.
Po pobraniu pliku binarnego Terraform wyodrębnij go i przenieś do folderu /usr/local/bin.
cp <directory>/terraform /usr/local/bin
Sprawdź, czy Terraform jest dostępny w ścieżce klasy.
terraform -v
1.9. Postman (w przypadku usługi agregacji AWS)
W tym laboratorium kodu do zarządzania żądaniami użyj Postmana.
Aby utworzyć obszar roboczy, kliknij „Obszary robocze” w menu u góry, a potem wybierz „Utwórz obszar roboczy”.
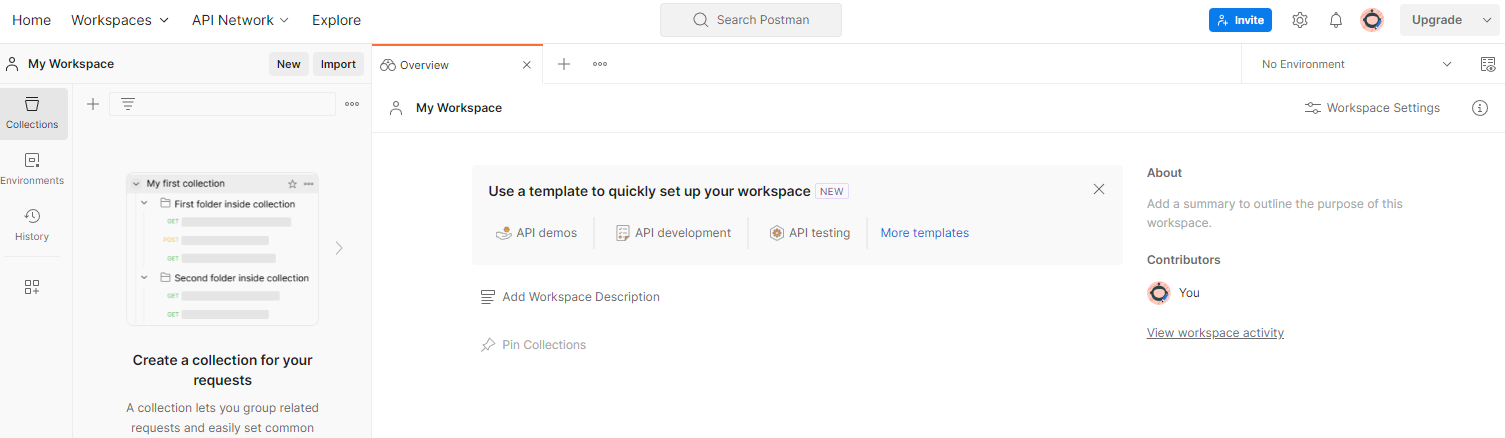 Obszar roboczy Postman
Obszar roboczy Postman
Wybierz „Pusty obszar roboczy”, kliknij Dalej i nadaj mu nazwę „Piaskownica prywatności”. Wybierz „Osobiste” i kliknij „Utwórz”.
Pobierz wstępnie skonfigurowane pliki obszaru roboczego konfiguracji JSON i środowiska globalnego.
Zaimportuj pliki JSON do sekcji „Mój obszar roboczy”, klikając przycisk „Importuj”.
 Importuj pliki JSON Postman.
Importuj pliki JSON Postman.
Spowoduje to utworzenie kolekcji Piaskownicy prywatności wraz z żądaniami HTTP createJob i getJob.
 Zaimportowana kolekcja Postman.
Zaimportowana kolekcja Postman.
Zaktualizuj „Klucz dostępu” i „Klucz tajny” AWS w sekcji „Szybki przegląd środowiska”.
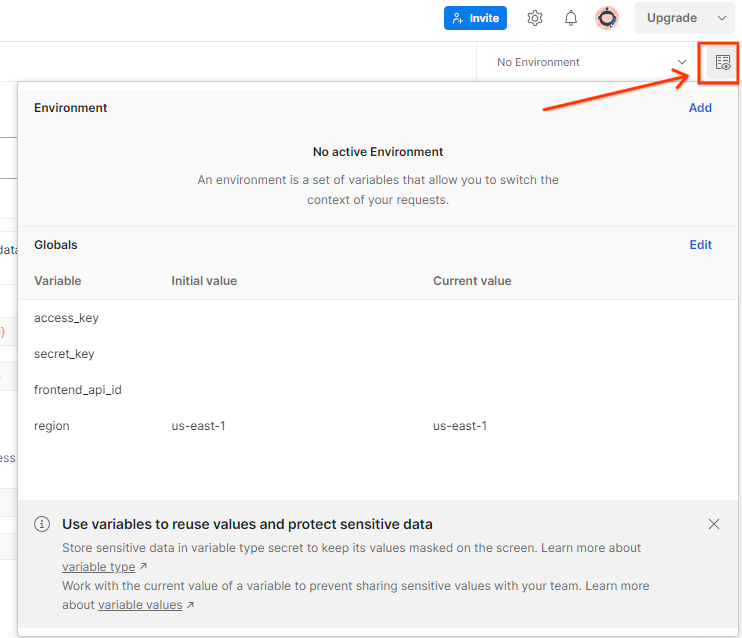 Szybki podgląd środowiska Postman.
Szybki podgląd środowiska Postman.
Kliknij „Edytuj” i zaktualizuj „Bieżącą wartość” zarówno w przypadku „access_key”, jak i „secret_key”. Pamiętaj, że frontend_api_id znajdziesz w sekcji 3.1.4 tego dokumentu. Zalecamy używanie regionu us-east-1. Jeśli jednak chcesz wdrożyć usługę w innym regionie, sprawdź, czy skopiujesz wydaną AMI na swoje konto, lub samodzielnie utwórz obraz, korzystając z udostępnionych skryptów.
 Zmienne globalne Postmana.
Zmienne globalne Postmana. 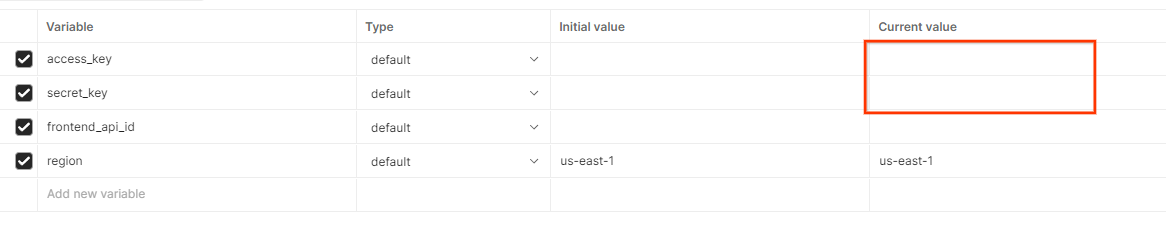 Edytowanie zmiennych globalnych w Postmanie.
Edytowanie zmiennych globalnych w Postmanie.
2. Ćwiczenie z programowania dotyczące testowania lokalnego
Możesz użyć narzędzia do testowania lokalnego na swoim urządzeniu, aby przeprowadzić agregację i wygenerować raporty podsumowujące na podstawie niezaszyfrowanych raportów debugowania.
Kroki ćwiczenia
Krok 2.1. Raport wyzwalający: wyzwala raportowanie Private Aggregation, aby umożliwić zbieranie raportu.
Krok 2.2. Utwórz raport z możliwością agregacji do debugowania: przekonwertuj zebrany raport JSON na raport w formacie AVRO.
Ten krok będzie podobny do sytuacji, w której dostawcy technologii reklamowych pobierają raporty z punktów końcowych raportowania interfejsu API i konwertują raporty w formacie JSON na raporty w formacie AVRO.
Krok 2.3. Wyodrębnij klucz zasobnika z raportu debugowania: klucze zasobników są projektowane przez dostawców technologii reklamowych. W tym laboratorium, ponieważ zasobniki są wstępnie zdefiniowane, pobierz klucze zasobników zgodnie z podanymi informacjami.
Krok 2.4. Utwórz wyjściowy plik AVRO domeny: po pobraniu kluczy zasobnika utwórz wyjściowy plik AVRO domeny.
Krok 2.5. Tworzenie raportów podsumowujących za pomocą narzędzia do testowania lokalnego: użyj narzędzia do testowania lokalnego, aby tworzyć raporty podsumowujące w środowisku lokalnym.
Krok 2.6. Sprawdź raport podsumowujący: zapoznaj się z raportem podsumowującym utworzonym przez narzędzie do testowania lokalnego.
2.1. Raport aktywatora
Otwórz witrynę demonstracyjną Piaskownicy prywatności. Spowoduje to wygenerowanie raportu agregacji prywatnej. Raport możesz wyświetlić na stronie chrome://private-aggregation-internals.
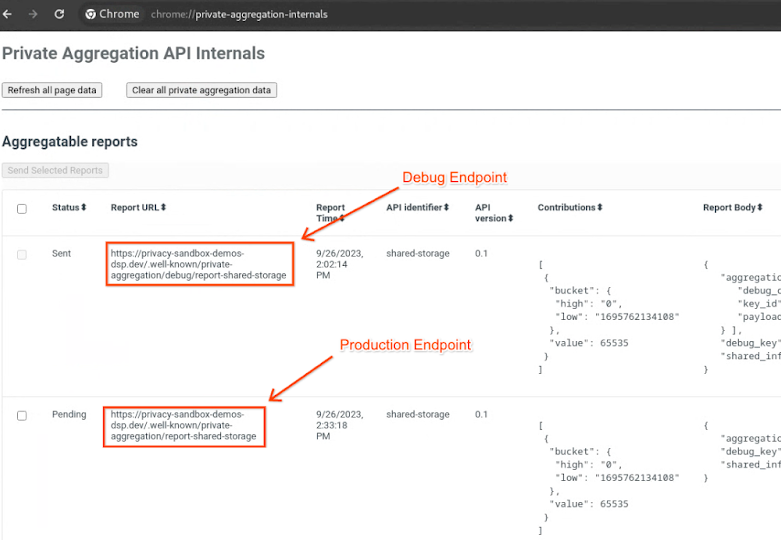 Wewnętrzne działanie prywatnej agregacji w Chrome.
Wewnętrzne działanie prywatnej agregacji w Chrome.
Jeśli raport ma stan „Oczekuje”, możesz go wybrać i kliknąć „Wyślij wybrane raporty”.
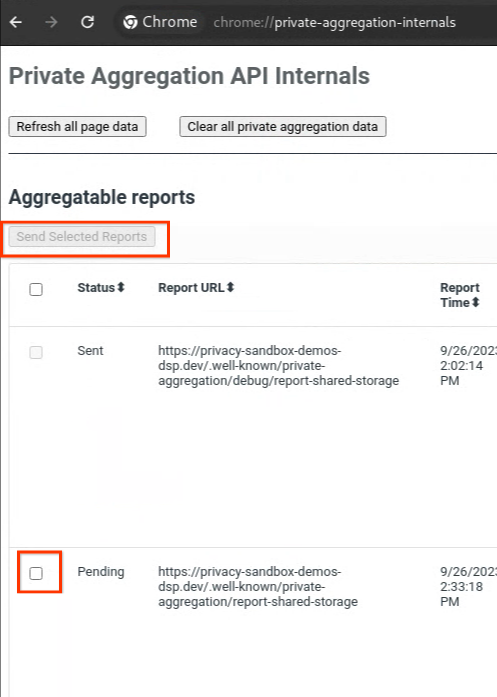 Wysyłanie raportu o agregacji prywatnej.
Wysyłanie raportu o agregacji prywatnej.
2.2. Tworzenie raportu debugowania z możliwością agregacji
W chrome://private-aggregation-internals skopiuj element „Report Body” otrzymany w punkcie końcowym [reporting-origin]/.well-known/private-aggregation/report-shared-storage.
Sprawdź, czy w sekcji „Treść raportu” w polu aggregation_coordinator_origin znajduje się https://publickeyservice.msmt.aws.privacysandboxservices.com, co oznacza, że raport jest raportem AWS, który można agregować.
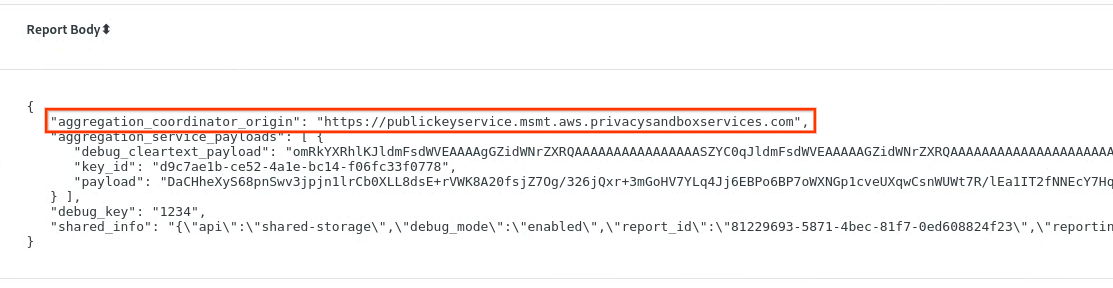 Raport agregacji prywatnej.
Raport agregacji prywatnej.
Umieść element JSON „Treść raportu” w pliku JSON. W tym przykładzie możesz użyć edytora vim. Możesz jednak użyć dowolnego edytora tekstu.
vim report.json
Wklej raport do report.json i zapisz plik.
 Plik JSON raportu.
Plik JSON raportu.
Następnie przejdź do folderu raportu i użyj ikony aggregatable_report_converter.jar, aby utworzyć raport z możliwością agregacji do debugowania. Spowoduje to utworzenie w bieżącym katalogu raportu z możliwością agregacji o nazwie report.avro.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Analizowanie klucza zasobnika z raportu debugowania
Usługa do agregacji wymaga 2 plików w przypadku przetwarzania wsadowego. Raport z możliwością agregacji i plik domeny wyjściowej. Plik domeny wyjściowej zawiera klucze, które chcesz pobrać z raportów zbiorczych. Aby utworzyć plik output_domain.avro, potrzebujesz kluczy zasobnika, które można pobrać z raportów.
Klucze zasobnika są projektowane przez osobę wywołującą interfejs API, a wersja demonstracyjna zawiera wstępnie utworzone przykładowe klucze zasobnika. W wersji demonstracyjnej włączony jest tryb debugowania na potrzeby prywatnej agregacji, więc możesz przeanalizować niezaszyfrowany ładunek debugowania z sekcji „Treść raportu”, aby pobrać klucz segmentu. W tym przypadku klucze segmentów tworzy jednak witryna privacy sandbox demo. Prywatna agregacja w przypadku tej witryny jest w trybie debugowania, więc możesz użyć debug_cleartext_payload z sekcji „Treść raportu”, aby uzyskać klucz segmentu.
Skopiuj debug_cleartext_payload z treści raportu.
 Debug cleartext payload from report body.
Debug cleartext payload from report body.
Otwórz narzędzie Debug payload decoder for Private Aggregation (Dekoder ładunku debugowania na potrzeby agregacji prywatnej) i wklej debug_cleartext_payloadw polu „INPUT” (WEJŚCIE), a następnie kliknij „Decode” (Dekoduj).
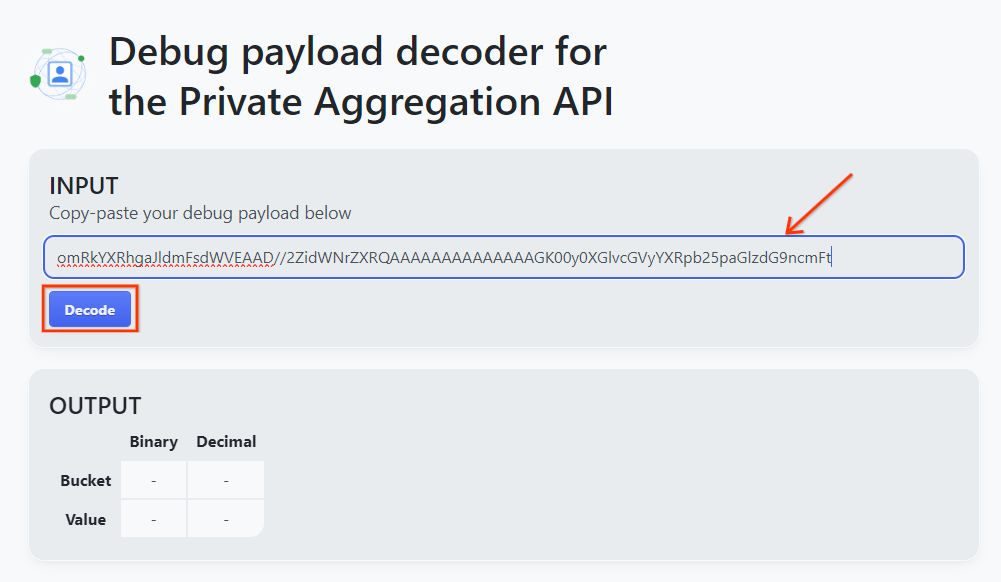 Dekoder ładunku.
Dekoder ładunku.
Strona zwraca wartość dziesiętną klucza segmentu. Oto przykładowy klucz do kosza.
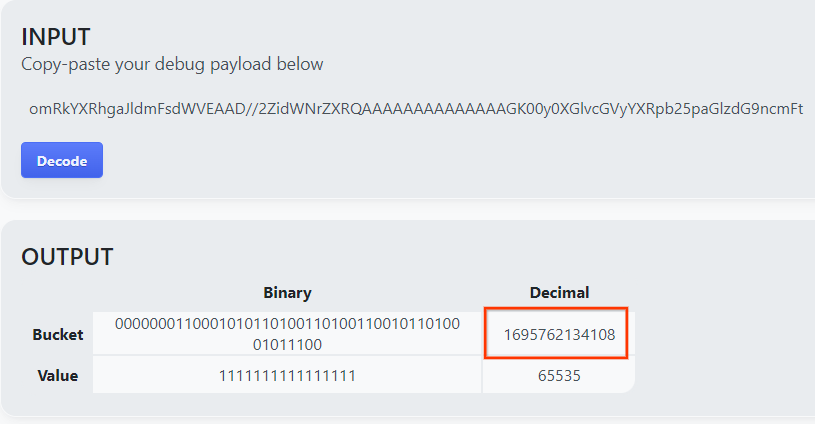 Wynik dekodowania ładunku.
Wynik dekodowania ładunku.
2.4. Tworzenie wyjściowego pliku AVRO domeny
Gdy mamy już klucz zasobnika, skopiuj jego wartość dziesiętną. Utwórz output_domain.avro za pomocą klucza zasobnika. Upewnij się, że zastępujesz
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Skrypt utworzy plik output_domain.avro w bieżącym folderze.
2.5. Tworzenie raportów podsumowujących za pomocą narzędzia do testowania lokalnego
Do utworzenia raportów podsumowujących użyjemy pliku LocalTestingTool_{version}.jar pobranego w sekcji 1.1. Użyj tego polecenia. Zamiast LocalTestingTool_{version}.jar wpisz wersję pobraną na potrzeby narzędzia LocalTestingTool.
Aby wygenerować raport podsumowujący w lokalnym środowisku programistycznym, uruchom to polecenie:
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
Po uruchomieniu polecenia zobaczysz coś podobnego do tego: Po zakończeniu tego procesu zostanie utworzony raportoutput.avro.
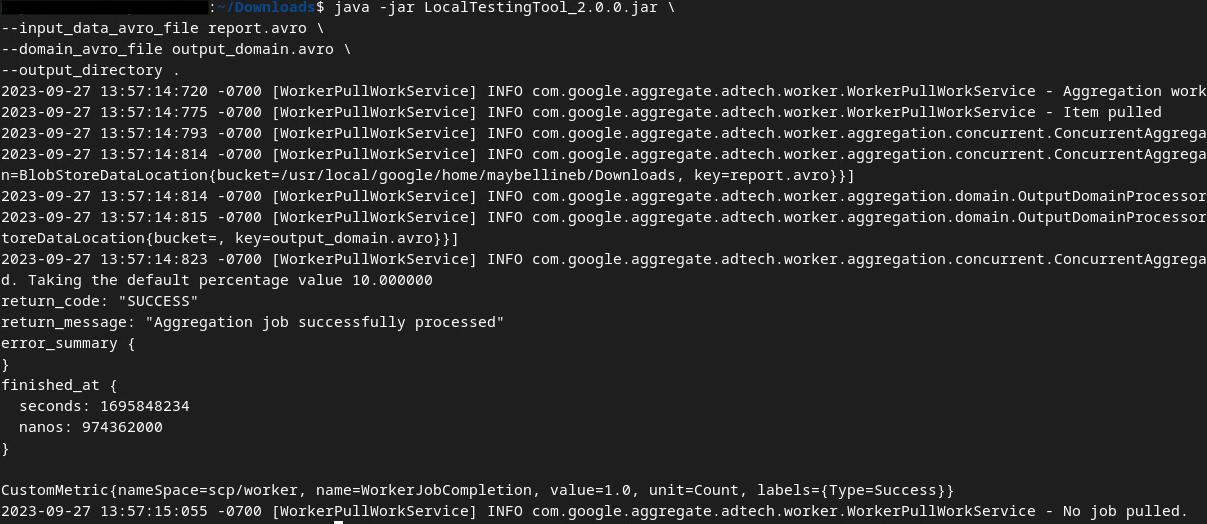 Plik Avro z raportem podsumowującym testowanie lokalne.
Plik Avro z raportem podsumowującym testowanie lokalne.
2.6. Sprawdzanie raportu podsumowującego
Utworzony raport podsumowujący jest w formacie AVRO. Aby to zrobić, musisz przekonwertować plik z formatu AVRO na format JSON. Najlepiej, aby technologia reklamowa miała kod umożliwiający przekształcanie raportów AVRO z powrotem na format JSON.
W naszym laboratorium kodu użyjemy podanego narzędzia aggregatable_report_converter.jar, aby przekonwertować raport AVRO z powrotem na format JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Spowoduje to wygenerowanie raportu podobnego do tego na ilustracji poniżej. wraz z raportem output.json utworzonym w tym samym katalogu.
 Plik avro z podsumowaniem przekonwertowany na format JSON.
Plik avro z podsumowaniem przekonwertowany na format JSON.
Otwórz plik JSON w wybranym edytorze, aby przejrzeć raport podsumowujący.
3. Wdrożenie usługi do agregacji
Aby wdrożyć usługę agregacji, wykonaj te czynności:
Krok 3. Wdrażanie usługi agregacji: wdrażanie usługi agregacji w AWS
Krok 3.1. Sklonuj repozytorium usługi do agregacji
Krok 3.2. Pobierz gotowe zależności
Krok 3.3. Tworzenie środowiska programistycznego
Etap 3.4. Wdrażanie usługi agregacji
3.1. Klonowanie repozytorium usługi do agregacji
W środowisku lokalnym sklonuj repozytorium GitHub usługi agregacji.
git clone https://github.com/privacysandbox/aggregation-service.git
3.2. Pobieranie wstępnie utworzonych zależności
Po sklonowaniu repozytorium usługi agregacji przejdź do folderu Terraform w repozytorium i do odpowiedniego folderu chmury. Jeśli cloud_provider to AWS, możesz przejść do
cd <repository_root>/terraform/aws
W języku download_prebuilt_dependencies.sh.
bash download_prebuilt_dependencies.sh
3.3 Tworzenie środowiska programistycznego
Utwórz środowisko deweloperskie w dev.
mkdir dev
Skopiuj zawartość folderu demo do folderu dev.
cp -R demo/* dev
Przenieś go do folderu dev.
cd dev
Zaktualizuj plik main.tf i naciśnij i, aby input edytować plik.
vim main.tf
Usuń znacznik komentarza z kodu w czerwonym polu, usuwając znak # i aktualizując nazwy zasobnika i klucza.
W przypadku pliku AWS main.tf:
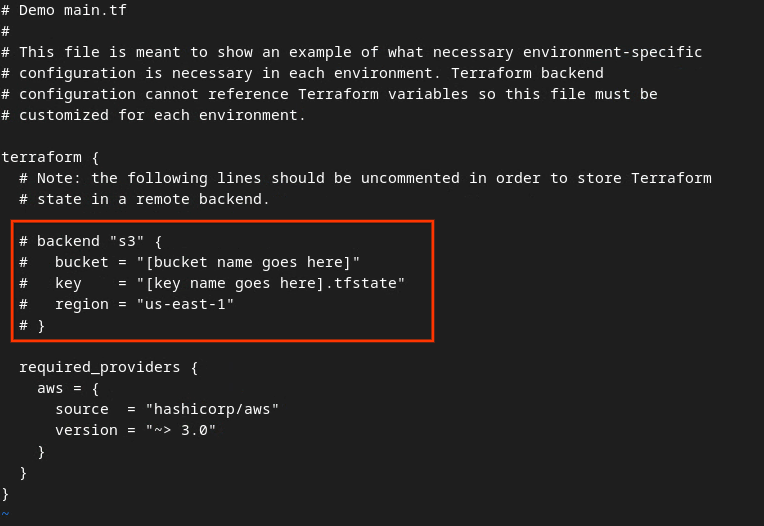 Główny plik tf AWS.
Główny plik tf AWS.
Odkomentowany kod powinien wyglądać tak:
backend "s3" {
bucket = "<tf_state_bucket_name>"
key = "<environment_name>.tfstate"
region = "us-east-1"
}
Po zakończeniu aktualizacji zapisz zmiany i zamknij edytor, naciskając esc -> :wq!. Spowoduje to zapisanie zmian w usłudze main.tf.
Następnie zmień nazwę example.auto.tfvars na dev.auto.tfvars.
mv example.auto.tfvars dev.auto.tfvars
Zaktualizuj dev.auto.tfvars i naciśnij i, aby input edytować plik.
vim dev.auto.tfvars
Zaktualizuj pola w czerwonej ramce na poniższym obrazie, podając prawidłowe parametry AWS ARN, które są udostępniane podczas wprowadzania usługi agregacji, w środowisku i w e-mailu z powiadomieniem.
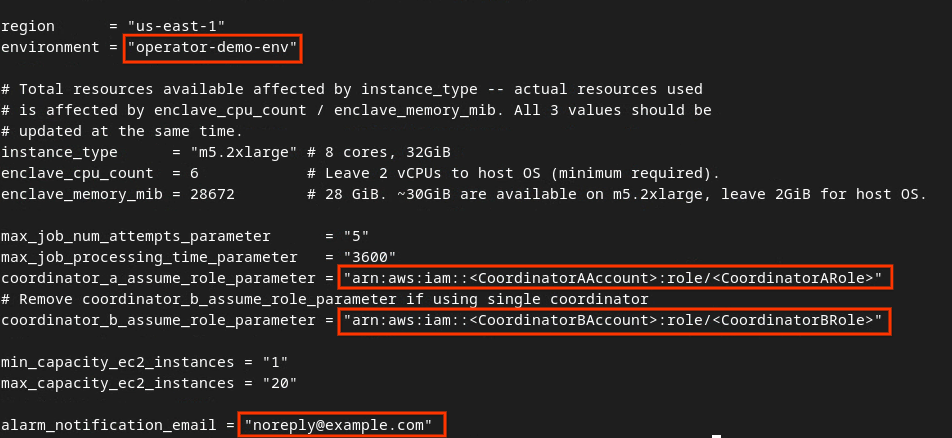 Edytuj plik dev auto tfvars.
Edytuj plik dev auto tfvars.
Po zakończeniu aktualizacji naciśnij esc → :wq!. Spowoduje to zapisanie pliku dev.auto.tfvars, który powinien wyglądać podobnie jak na tym obrazie.
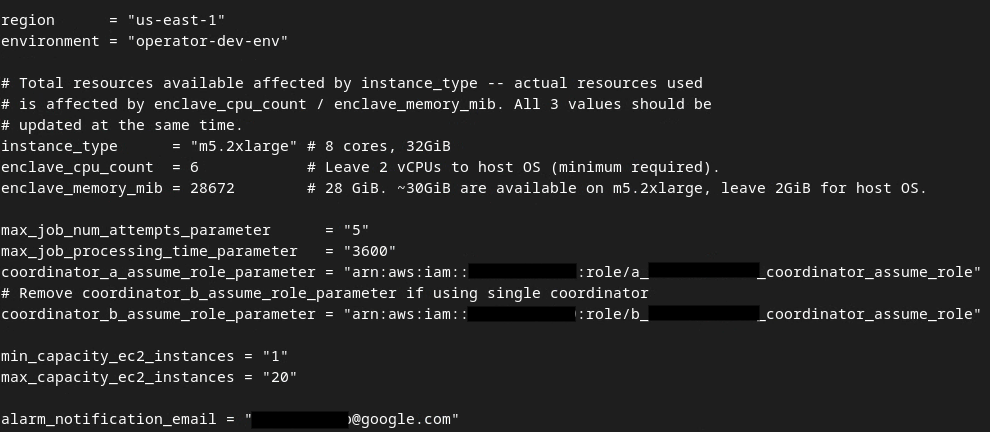 Zaktualizowany plik tfvars automatyzacji środowiska deweloperskiego.
Zaktualizowany plik tfvars automatyzacji środowiska deweloperskiego.
3.4. Wdrażanie usługi agregacji
Aby wdrożyć usługę Aggregation Service, w tym samym folderze
terraform init
Powinno to zwrócić wynik podobny do tego na ilustracji:
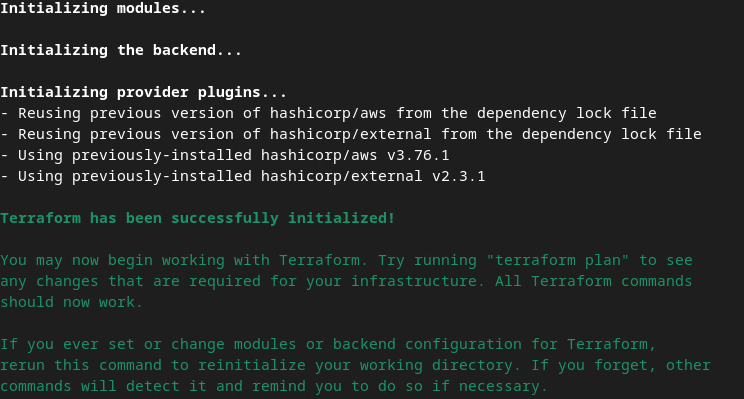 Terraform init.
Terraform init.
Po zainicjowaniu Terraform utwórz plan wykonania Terraform. Zwraca on liczbę zasobów do dodania i inne dodatkowe informacje podobne do tych na poniższym obrazie.
terraform plan
Poniżej znajdziesz podsumowanie „Plan”. Jeśli jest to nowe wdrożenie, powinna pojawić się liczba zasobów, które zostaną dodane, oraz 0 zasobów do zmiany i 0 do usunięcia.
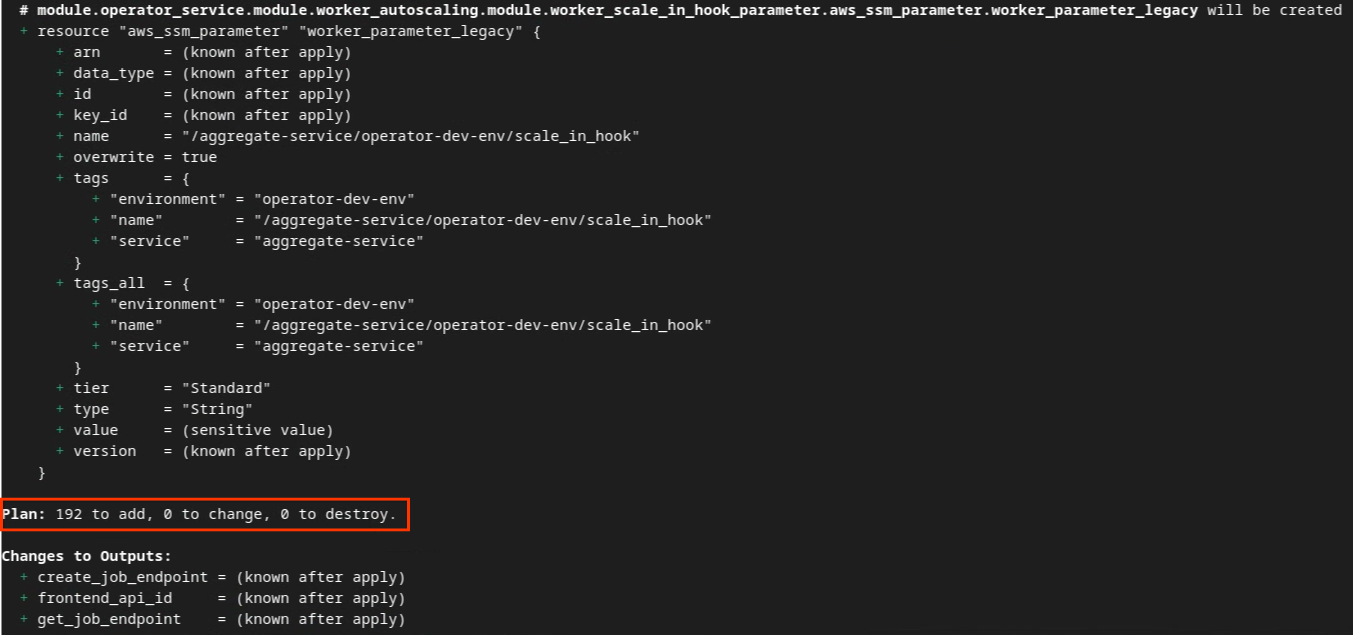 Plan Terraform.
Plan Terraform.
Gdy to zrobisz, możesz zastosować Terraform.
terraform apply
Gdy Terraform poprosi o potwierdzenie wykonania działań, wpisz w wartości znak yes.
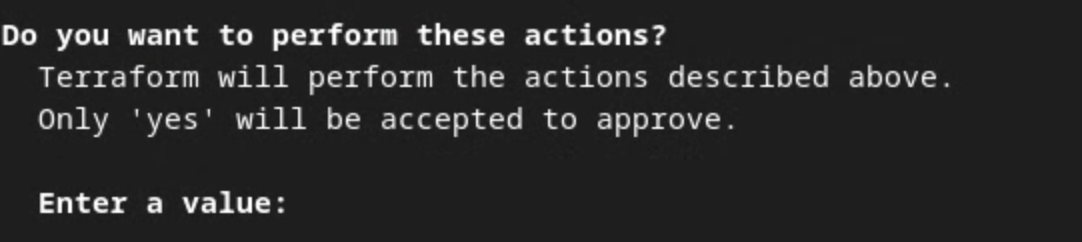 Prompt polecenia Terraform apply.
Prompt polecenia Terraform apply.
Po zakończeniu terraform apply zwracane są te punkty końcowe dla createJob i getJob. Zwracany jest też frontend_api_id, który musisz zaktualizować w Postmanie w sekcji 1.9.
 Zastosowano zmiany w Terraform.
Zastosowano zmiany w Terraform.
4. Tworzenie danych wejściowych usługi agregacji
Przejdź do tworzenia raportów AVRO do przetwarzania wsadowego w usłudze do agregacji.
Krok 4. Tworzenie danych wejściowych usługi do agregacji: tworzenie raportów usługi do agregacji, które są przesyłane do usługi do agregacji w partiach.
Krok 4.1. Raport o aktywatorze
Krok 4.2. Zbieranie raportów zbiorczych
Krok 4.3. Konwertowanie raportów na format AVRO
Krok 4.4. Tworzenie wyjściowego pliku AVRO domeny
4.1. Raport aktywatora
Otwórz stronę demonstracyjną Piaskownicy prywatności. Spowoduje to wygenerowanie raportu agregacji prywatnej. Raport możesz wyświetlić na stronie chrome://private-aggregation-internals.
Wewnętrzne działanie prywatnej agregacji w Chrome.
Jeśli raport ma stan „Oczekuje”, możesz go wybrać i kliknąć „Wyślij wybrane raporty”. '
Wysyłanie raportu o agregacji prywatnej.
4.2. Zbieranie raportów zbiorczych
Zbierz raporty, które można agregować, z punktów końcowych .well-known odpowiedniego interfejsu API.
- Private Aggregation
[reporting-origin] /.well-known/private-aggregation/report-shared-storage - Raporty atrybucji – raport podsumowujący
[reporting-origin] /.well-known/attribution-reporting/report-aggregate-attribution
W tym ćwiczeniu wykonasz zbieranie raportów ręcznie. W środowisku produkcyjnym firmy zajmujące się technologiami reklamowymi będą programowo zbierać i konwertować raporty.
W chrome://private-aggregation-internals skopiuj element „Report Body” otrzymany w punkcie końcowym [reporting-origin]/.well-known/private-aggregation/report-shared-storage.
Sprawdź, czy w sekcji „Treść raportu” w polu aggregation_coordinator_origin znajduje się https://publickeyservice.msmt.aws.privacysandboxservices.com, co oznacza, że raport jest raportem AWS, który można agregować.
Raport agregacji prywatnej.
Umieść element JSON „Treść raportu” w pliku JSON. W tym przykładzie możesz użyć edytora vim. Możesz jednak użyć dowolnego edytora tekstu.
vim report.json
Wklej raport do report.json i zapisz plik.
Plik JSON raportu.
4.3. Konwertowanie raportów do formatu AVRO
Raporty otrzymywane z punktów końcowych .well-known są w formacie JSON i muszą zostać przekonwertowane na format raportu AVRO. Gdy uzyskasz raport JSON, przejdź do folderu raportu i użyj aggregatable_report_converter.jar, aby utworzyć raport z możliwością debugowania. Spowoduje to utworzenie w bieżącym katalogu raportu z możliwością agregacji o nazwie report.avro.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
4.4. Tworzenie wyjściowego pliku AVRO domeny
Aby utworzyć plik output_domain.avro, potrzebujesz kluczy zasobnika, które można pobrać z raportów.
Klucze segmentów są projektowane przez technologię reklamową. W tym przypadku klucze segmentów tworzy jednak witryna Privacy Sandbox demo. Prywatna agregacja w przypadku tej witryny jest w trybie debugowania, więc możesz użyć debug_cleartext_payload z sekcji „Treść raportu”, aby uzyskać klucz segmentu.
Skopiuj debug_cleartext_payload z treści raportu.
Debug cleartext payload from report body.
Otwórz goo.gle/ags-payload-decoder, wklej debug_cleartext_payload do pola „INPUT” i kliknij „Decode” (Dekoduj).
Dekoder ładunku.
Strona zwraca wartość dziesiętną klucza segmentu. Oto przykładowy klucz do kosza.
Wynik dekodowania ładunku.
Gdy mamy już klucz zasobnika, utwórz output_domain.avro. Upewnij się, że zastępujesz
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Skrypt utworzy plik output_domain.avro w bieżącym folderze.
4.5. Przenoszenie raportów do zasobnika AWS
Po utworzeniu raportów AVRO (z sekcji 3.2.3) i domeny wyjściowej (z sekcji 3.2.4) przenieś raporty i domenę wyjściową do zasobników S3 raportowania.
Jeśli masz skonfigurowany interfejs wiersza poleceń AWS w środowisku lokalnym, użyj tych poleceń, aby skopiować raporty do odpowiedniego zasobnika S3 i folderu raportów.
aws s3 cp report.avro s3://<report_bucket_name>/<report_folder>/
aws s3 cp output_domain.avro s3://<report_bucket_name>/<output_domain_folder>/
5. Korzystanie z usługi agregacji
Z terraform apply otrzymasz create_job_endpoint, get_job_endpoint i frontend_api_id. Skopiuj frontend_api_id i wklej go do globalnej zmiennej Postmana frontend_api_id, którą skonfigurowano w sekcji 1.9 wymagań wstępnych.
Krok 5. Wykorzystanie usługi agregacji: użyj interfejsu Aggregation Service API, aby tworzyć i sprawdzać raporty podsumowujące.
Krok 5.1. Używanie punktu końcowego createJob do przetwarzania wsadowego
Krok 5.2. Używanie punktu końcowego getJob do pobierania stanu zadania wsadowego
Krok 5.3. Sprawdzanie raportu podsumowującego
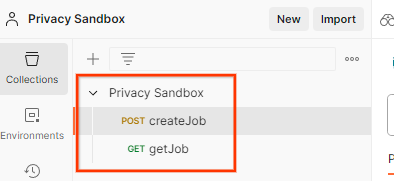
5.1. Używanie punktu końcowego createJob do przetwarzania wsadowego
W Postmanie otwórz kolekcję „Piaskownica prywatności” i wybierz „createJob”.
Wybierz „Body” (Treść) i „raw” (surowa), aby umieścić ładunek żądania.
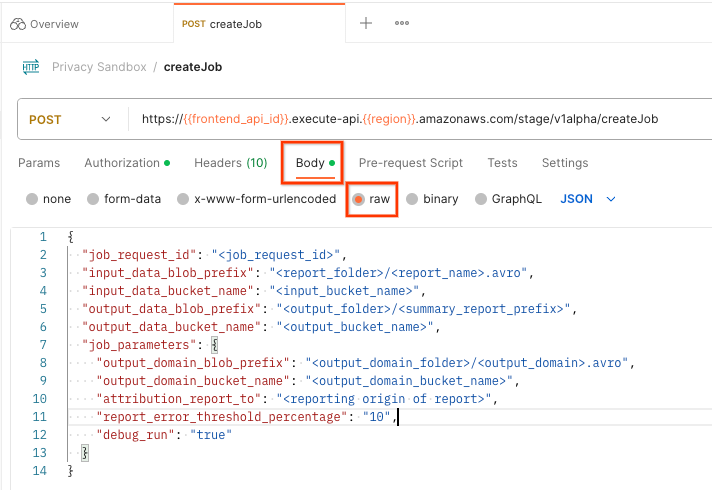 treść żądania postman createJob
treść żądania postman createJob
Schemat ładunku createJob jest dostępny w GitHubie i wygląda podobnie do tego: Zastąp symbol <> odpowiednimi polami.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
], // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Gdy klikniesz Wyślij, utworzysz zadanie z job_request_id. Gdy usługa agregacji zaakceptuje żądanie, powinna zwrócić odpowiedź HTTP 202. Inne możliwe kody zwrotne znajdziesz w sekcji Kody odpowiedzi HTTP.
 postman createJob request status
postman createJob request status
5.2. Używanie punktu końcowego getJob do pobierania stanu pakietu
Aby sprawdzić stan prośby o wykonanie zadania, możesz użyć punktu końcowego getJob. W kolekcji „Piaskownica prywatności” wybierz „getJob”.
W sekcji „Params” zaktualizuj wartość job_request_id na job_request_id, która została wysłana w żądaniu createJob.
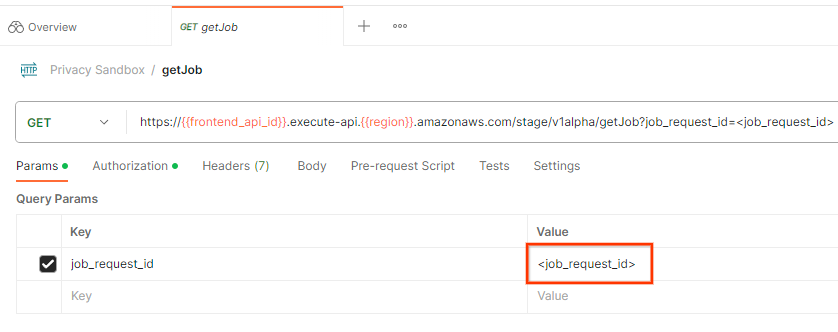 postman getJob request
postman getJob request
Wynik getJob powinien zwrócić stan żądania zadania z kodem stanu HTTP 200. Żądanie „Body” zawiera niezbędne informacje, takie jak job_status, return_message i error_messages (jeśli zadanie zakończyło się błędem).
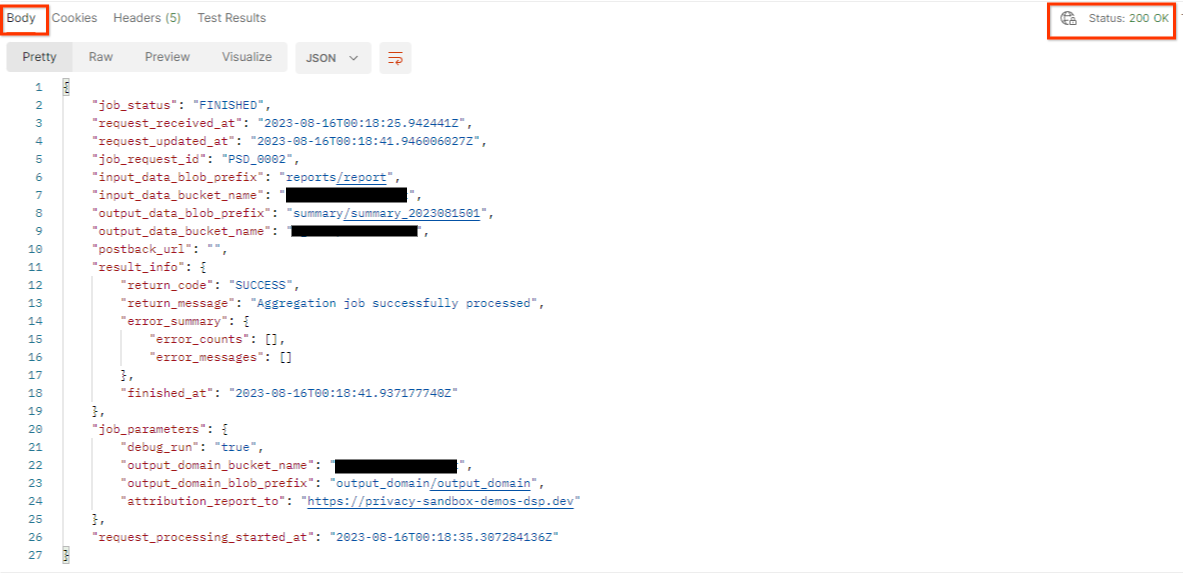 postman getJob request status
postman getJob request status
Ponieważ witryna raportowania wygenerowanego raportu demonstracyjnego różni się od witryny wdrożonej na Twoim identyfikatorze AWS, możesz otrzymać odpowiedź z kodem PRIVACY_BUDGET_AUTHORIZATION_ERROR return_code. To normalne, ponieważ witryna źródła raportowania raportów nie pasuje do witryny raportowania zarejestrowanej w przypadku identyfikatora AWS.
{
"job_status": "FINISHED",
"request_received_at": "2023-12-07T22:50:58.830956Z",
"request_updated_at": "2023-12-07T22:51:10.526326456Z",
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_blob_prefixes": [ // Mutually exclusive to input_data_blob_prefix as of v2.11.0
"<report_folder>/<report_name-1>/",
"<report_folder>/<report_name-2>/",
"<report_folder>/<report_name>.avro"
],
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"postback_url": "",
"result_info": {
"return_code": "PRIVACY_BUDGET_AUTHORIZATION_ERROR",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-12-07T22:51:10.517730898Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"attribution_report_to": "https://privacy-sandbox-demos-dsp.dev",
"reporting_site": "<domain of reporting origin(s) of report>", // Mutually exclusive to attribution_report_to as of v2.7.0
},
"request_processing_started_at": "2023-12-07T22:51:06.034472697Z"
}
5.3. Sprawdzanie raportu podsumowującego
Gdy otrzymasz raport podsumowujący w wyjściowym zasobniku S3, możesz go pobrać do środowiska lokalnego. Raporty podsumowujące są w formacie AVRO i można je przekonwertować z powrotem na format JSON. Aby odczytać raport, możesz użyć aggregatable_report_converter.jar, wpisując to polecenie:
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Zwraca to plik JSON zawierający zagregowane wartości każdego klucza segmentu, który wygląda podobnie do tego na poniższym obrazie.
 Raport zbiorczy.
Raport zbiorczy.
Jeśli Twoje createJob żądanie zawiera debug_run jako true, raport podsumowujący otrzymasz w folderze debugowania znajdującym się w output_data_blob_prefix. Raport jest w formacie AVRO i można go przekonwertować na format JSON za pomocą poprzedniego polecenia.
Raport zawiera klucz segmentu, dane bez szumu i szum dodany do danych bez szumu w celu utworzenia raportu zbiorczego. Raport jest podobny do tego na ilustracji poniżej.
 Raport podsumowujący debugowanie.
Raport podsumowujący debugowanie.
Adnotacje zawierają też symbole in_reports i in_domain, które oznaczają:
- in_reports – klucz segmentu jest dostępny w raportach zbiorczych.
- in_domain – klucz zasobnika jest dostępny w pliku AVRO output_domain.