
W propozycji raportowania atrybucji wprowadzono wiele zmian, aby uwzględnić opinie społeczności, od zmian w mechanizmie interfejsu API po nowe funkcje.
Historia zmian
- 7 lutego 2022 r.: dodano sekcję o przekierowaniu reguły uruchamiającej w nagłówku.
- 27 stycznia 2022 r.: pierwszy raz opublikowano artykuł.
Dla kogo jest przeznaczony ten post?
Ten post jest dla Ciebie:
- Jeśli znasz już interfejs API, np. obserwujesz lub uczestniczysz w dyskusjach w repozytorium WICG i chcesz poznać zmiany wprowadzone w propozycji w styczniu 2022 r.
- Jeśli używasz interfejsu Attribution Reporting API w wersji demonstracyjnej lub w ramach eksperymentu w produkcji.
Jeśli dopiero zaczynasz korzystać z tego interfejsu API lub nie masz jeszcze z nim do czynienia, przejdź bezpośrednio do wprowadzenia do interfejsu API.
Migracja
Gdy wprowadzimy te zmiany w Chrome: jeśli korzystasz z raportów na poziomie zdarzenia z interfejsu Attribution Reporting API w wersji demonstracyjnej lub w ramach eksperymentu w produkcji (testowanie origin), musisz zmodyfikować kod interfejsu API, aby nadal działał. Możesz też skorzystać z nowych funkcji.
Z tego artykułu dowiesz się też, jakie zmiany dotyczą raportów podlegających agregacji. Jednak te zmiany, jeśli zostaną zaimplementowane, nie będą wymagać żadnych działań ani migracji, ponieważ w momencie pisania tego tekstu nie ma jeszcze w przeglądarce możliwości tworzenia raportów zbiorczych.
Zmiany nazw
Raporty podsumowujące i raporty umożliwiające agregację
Dane określane jako raporty zbiorcze będą teraz nazywane raportami podsumowaniami.
Raporty podsumowania to końcowy wynik agregacji wielu raportów podlegających agregacji, które wcześniej nazywano udziałami lub udziałami w histogramie.
Zmiany mechanizmu interfejsu API
Rejestrowanie źródła na podstawie nagłówka (raporty na poziomie zdarzenia)
Co się zmienia i dlaczego?
Gdy użytkownik obejrzy reklamę lub kliknie ją, przeglądarka na urządzeniu użytkownika rejestruje to zdarzenie wraz z parametrami specyficznymi dla raportowania atrybucji (np. attributionsourceeventid, attributiondestination, attributionexpiry i inne parametry). Wartości tych parametrów są ustawiane przez technologię reklamową.
Zmienia się sposób ustawiania tych parametrów.
W poprzedniej propozycji parametry musiały być uwzględnione po stronie klienta: w tagach kotwicy jako atrybuty HTML lub jako argumenty wywołania opartego na JS. Parametry musiały być znane w momencie kliknięcia lub wyświetlenia.
W nowej propozycji wartość tych parametrów jest zamiast tego definiowana na serwerze adtech.
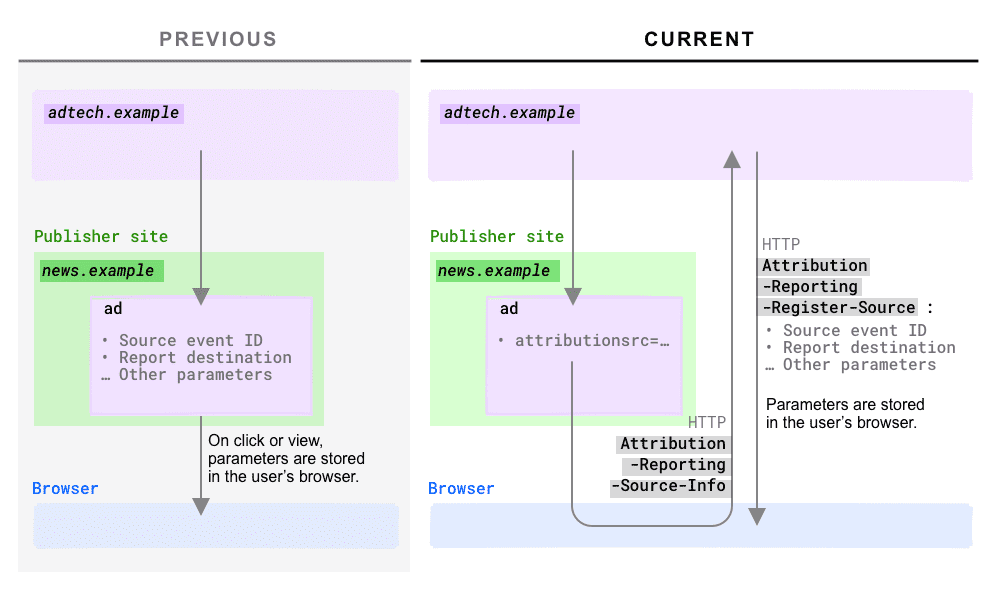
Ma to wiele zalet, zwłaszcza w zakresie bezpieczeństwa: mechanizm nagłówka daje źródłu raportowania (zwykle firmie zajmującej się technologiami reklamowymi) bezpośrednią kontrolę nad tym, czy źródło atrybucji jest zarejestrowane w jego zakresie. Zmiana ta częściowo ogranicza ryzyko oszustwa, ponieważ prawdziwa przeglądarka nigdy nie zarejestruje źródła bez zgody źródła raportującego.
Jak działa rejestracja źródła?
- W przypadku danej reklamy firma adtech musi teraz zdefiniować określony atrybut po stronie klienta.
attributionsrcWartość tego atrybutu to adres URL, do którego przeglądarka wyśle żądanie. Żądanie to będzie zawierać nowy nagłówek HTTPAttribution-Reporting-Source-Info, którego wartośćnavigationlubevent,określa, czy źródłem było kliknięcie, czy wyświetlenie. - Po otrzymaniu tego żądania serwer śledzenia kliknięć/wyświetleń powinien odpowiedzieć nagłówkiem HTTP
Attribution-Reporting-Register-Sourcezawierającym odpowiednie parametry atrybucji. Punkt początkowy, który zwraca ten nagłówek, jest teraz punktem początkowym raportowania (wcześniej zdefiniowanym jako
attributionreportto).Nagłówek odpowiedzi HTTP
Attribution-Reporting-Register-Source:{ "source_event_id": "267630968326743374", "destination": "https://toasters.example", "expiry": "604800000" }
Więcej informacji znajdziesz w opisie technicznym
Rejestrowanie źródeł atrybucji
Dołącz do publicznej dyskusji
Aktywator atrybucji na podstawie nagłówka (raporty na poziomie zdarzenia)
Co się zmienia i dlaczego?
Podobnie jak w przypadku rejestracji kliknięć lub wyświetleń nowa propozycja zmienia wyzwalacz atrybucji (czyli moment, w którym technologia reklamowa instruuje przeglądarkę, aby zarejestrowała konwersję) na metodę opartą na nagłówku.
Ten mechanizm jest zgodny z rejestracją źródła na podstawie nagłówka i jest bardziej konwencjonalny niż używany wcześniej mechanizm przekierowania.
W nowej propozycji na stronie konwersji wymagany jest atrybut attributionsrc.
Uzasadnienie: w poprzedniej propozycji witryna strony uruchamiającej (zazwyczaj witryna reklamodawcy) miała ogólną kontrolę nad funkcją za pomocą nagłówka Permissions-Policy, ale nie miała szczegółowej kontroli na poziomie elementu dotyczącej tego, czy element może wysłać żądanie do strony, która ostatecznie uruchamia atrybucję. attributionsrc zmienia to: ten obowiązkowy znacznik daje reklamodawcy możliwość monitorowania i tym samym kontrolowania, które elementy mogą wywołać atrybucję.
Pamiętaj, że po stronie źródła (zazwyczaj witryny wydawcy) dostępne są ustawienia obejmujące całą stronę (Permissions-Policy) oraz ustawienia obejmujące cały element (attributionsrc).
Jak działa reguła atrybucji?
Po otrzymaniu żądania pliku pzxelowego i podjęciu decyzji, że należy je zaklasyfikować jako konwersję, usługa adtech powinna odpowiedzieć nowym nagłówkiem HTTPAttribution-Reporting-Register-Event-Trigger.
Wartość tego nagłówka określa, jak traktować zdarzenie uruchamiające jako obiekt JSON. To są te same informacje, które zostały zdefiniowane jako parametry zapytania w poprzedniej propozycji.
Nagłówek odpowiedzi HTTP Attribution-Reporting-Register-Event-Trigger:
[{
trigger_data: (unsigned 3-bit integer),
trigger_priority: (signed 64-bit integer),
deduplication_key: (signed 64-bit integer)
}]
Przekierowanie (opcjonalne)
Opcjonalnie serwer adtech może utworzyć odpowiedź, która zawiera Attribution-Reporting-Register-Event-Trigger jako odpowiedź przekierowania.
Umożliwia to usługom zewnętrznym obserwowanie zdarzenia konwersji i instruowanie przeglądarki, aby je przypisać.
Przekierowanie jest opcjonalne. Nie jest potrzebne, gdy na stronie są piksele adtech i firmy zewnętrznej.
Więcej informacji znajdziesz w sekcji Raportowanie zewnętrzne.
Więcej informacji znajdziesz w opisie technicznym
Dołącz do publicznej dyskusji
Brak workletu (raporty podlegające agregacji)
Co się zmienia i dlaczego?
W poprzedniej propozycji dotyczącej raportów możliwych do zsumowania wymagany był dostęp do kodu JavaScript, aby wywołać element worklet (mechanizm oparty na JavaScript), który generowałby te raporty.
W nowej propozycji nie jest wymagany żaden element pracy. Zamiast tego dostawca technologii reklamowych mógłby deklaratywnie definiować w nagłówkach HTTP reguły, których przeglądarka powinna używać do generowania raportów możliwych do agregacji.
Nowa propozycja zapewnia kilka korzyści:
- Wdrażanie w przeglądarce: nowa architektura jest znacznie prostsza niż architektura workletu, ponieważ nie wymaga tworzenia nowego środowiska wykonywania w przeglądarce.
- Wsparcie dla programistów: nowy interfejs opiera się na nagłówkach, które są powszechnie używane i powszechnie znane programistom, w przeciwieństwie do workletów. Jest też ściśle powiązany z interfejsem API do rejestracji źródła, co ułatwia naukę i używanie interfejsu API.
- Adoption: nowa wersja umożliwia korzystanie z raportów agregowanych przez więcej dotychczasowych systemów pomiarowych. Wiele rozwiązań analitycznych działa tylko w przypadku HTTP: korzystają one z żądań obrazów (żądań pikseli), które nie wymagają dostępu do JavaScript. Jednak podejście oparte na worklecie wymagało dostępu do JavaScriptu, co mogło utrudnić migrację z niektórych dotychczasowych systemów pomiarowych.
- Wytrzymałość: nowy projekt pomaga ograniczać utratę danych, ponieważ ułatwia integrację z semantyką
keepalive, np. gdy kliknięcie lub wyświetlenie jest rejestrowane, gdy użytkownik opuszcza stronę.
Jak działa mechanizm bez workletów?
Ten deklaratywny mechanizm opiera się na nagłówkach HTTP, podobnie jak rejestracja źródła na poziomie zdarzenia i nagłówek reguły atrybucji. Więcej informacji znajdziesz w następnych sekcjach.
Dołącz do publicznej dyskusji
Rejestrowanie źródeł opartych na nagłówku (raporty podlegające agregacji)
Proponujemy nowy mechanizm rejestrowania źródła na potrzeby raportu z możliwością agregacji. Jest on taki sam jak rejestrowanie źródła na poziomie zdarzenia.
Różni się tylko nazwa nagłówka: Attribution-Reporting-Register-Aggregatable-Source.
Więcej informacji znajdziesz w opisie technicznym
Atrybucja na podstawie nagłówka (raporty agregowane)
Proponujemy nowy mechanizm rejestrowania źródła raportu zbiorczego. Jest on taki sam jak reguła atrybucji na poziomie zdarzenia.
Różni się tylko nazwa nagłówka: Attribution-Reporting-Register-Aggregatable-Trigger-Data.
Więcej informacji znajdziesz w opisie technicznym
Nowe funkcje
Raporty zewnętrzne (raporty na poziomie zdarzenia i raporty agregowane)
Co się zmienia i dlaczego?
Nowa propozycja zawiera 2 elementy, które ułatwiają obsługę raportowania zewnętrznego:
- Opcjonalnie dostawcy technologii reklamowych mogą przekierowywać żądania sieci do innych serwerów dostawców technologii reklamowych, co pozwala tym dostawcom rejestrować własne źródła i wyzwalacze. Jest to obecnie powszechny sposób konfigurowania aplikacji innych firm. Dzięki temu interfejs API łatwiej się wdraża, m.in. w dotychczasowych systemach raportowania innych firm.
- Źródła raportowania (zwykle firmy technologiczne związane z reklamą) nie udostępniają już większości limitów prywatności. Umożliwia to obsługę przypadków, w których wiele firm technologicznych współpracuje z tymi samymi wydawcami lub reklamodawcami.
Jak działa raportowanie przez osoby trzecie?
W nowej propozycji rejestracja źródła i jej wyzwalacz oparte na odpowiedzi korzystają z nagłówków HTTP. Technologia reklamowa może wykorzystywać przekierowania HTTP do tych żądań.
Jeśli żądanie kliknięcia lub wyświetlenia w witrynie wydawcy (rejestracja źródła) zostanie następnie przekierowane do wielu stron, każda z nich może zarejestrować to wyświetlenie lub kliknięcie (zdarzenie źródła).
Podobnie technologia reklamowa może przekierowywać określone żądanie atrybucji wysłane z witryny reklamodawcy, umożliwiając rejestrowanie konwersji przez wiele innych stron (wyzwalacz atrybucji).
Każda ze stron ma dostęp do osobnych raportów i może je konfigurować z użyciem oddzielnych danych.
Rejestrowanie wielu reguł bez przekierowań
Można też zarejestrować wiele reguł atrybucji bez korzystania z przekierowań, dodając po stronie konwersji wiele elementów piksela (po jednym na regułę).
Dołącz do publicznej dyskusji
pomiar konwersji po wyświetleniu (raporty na poziomie zdarzenia i raporty agregowane);
Co się zmienia i dlaczego?
W nowej propozycji pomiar konwersji po obejrzeniu i po kliknięciu działają w ujednolicony sposób:
registerattributionsrc, atrybut dotyczący wyświetlenia, który nakazywał przeglądarce rejestrowanie wyświetleń wraz z kliknięciami, nie jest już uwzględniany w propozycji.- Mechanizmy ochrony prywatności są teraz zjednoczone w przypadku kliknięć i wyświetleń. Więcej informacji na ten temat znajdziesz w artykule O szumie i przejrzystości.
Proponujemy tę zmianę, aby dostosować ją do nowego mechanizmu rejestracji w nagłówku. Ułatwia też pracę deweloperom, którzy chcą obsługiwać pomiar zarówno na podstawie kliknięcia, jak i wyświetlenia.
Jak działa pomiar konwersji po wyświetleniu
Pomiar konwersji po wyświetleniu i po kliknięciu korzysta z rejestracji na podstawie nagłówka.
Więcej informacji znajdziesz w opisie technicznym
Raporty na poziomie zdarzenia (dotyczące zarówno kliknięć, jak i wyświetleń)
Dołącz do publicznej dyskusji
Debugowanie i analiza skuteczności (raporty na poziomie zdarzenia i raporty podlegające agregacji)
Co się zmienia i dlaczego?
Do propozycji dodaliśmy mechanizm debugowania, który pomaga deweloperom wykrywać błędy i porównywać skuteczność raportowania atrybucji z dotychczasowymi rozwiązaniami pomiarowymi opartymi na plikach cookie.
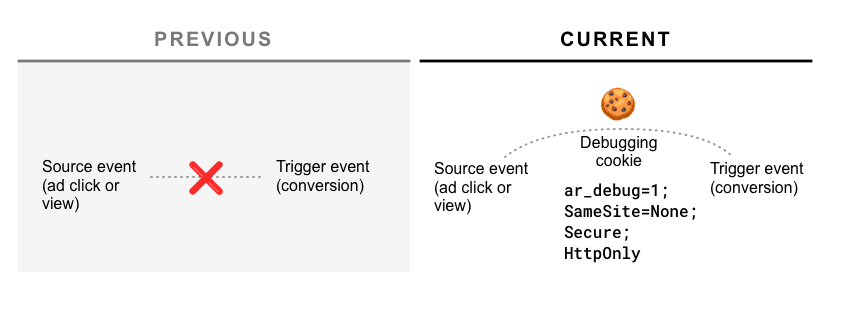
Jak działa debugowanie?
Zarówno rejestracja źródła, jak i reguły będą akceptować nowy parametr debug_key, który jest 64-bitową liczbą całkowitą bez znaku (czyli dużą liczbą).
Jeśli raport jest tworzony za pomocą kluczy debugowania źródła i kluczy debugowania wyzwalacza, a w czasie rejestracji źródła i wyzwalacza w źródle raportowania znajduje się plik cookie Samesite=None ar_debug=1, raport debugowania (w formacie JSON) zostanie wysłany do punktu końcowego .well-known/attribution-reporting/debug:
{
"source_debug_key": 1234567890987,
"trigger_debug_key": 4567654345028
}
Raporty na poziomie zdarzenia i zbiorcze będą zawierać te 2 nowe parametry, dzięki czemu można je powiązać z odpowiednim raportem debugowania.
Więcej informacji znajdziesz w opisie technicznym
Opcjonalnie: rozszerzone raporty z debugowania
Dołącz do publicznej dyskusji
Możliwości filtrowania (raporty na poziomie zdarzenia i raporty podlegające agregacji)
Co się zmienia i dlaczego?
W raportach na poziomie zdarzenia i raportach agregowanych będzie można stosować te zdarzenia, ponieważ obsługują one ważne przypadki użycia w dzisiejszym ekosystemie reklamowym:
- Filtrowanie konwersji: filtrowanie konwersji na podstawie informacji ze źródła. Możesz np. wybrać różne dane wyzwalające (dane o konwersjach) dla kliknięć i wyświetleń reklam.
- Niespójność atrybucji: filtrowanie konwersji, które zostały przypisane do nieprawidłowego źródła; jest to szczególny typ filtrowania konwersji. Możesz na przykład odfiltrowywać konwersje dopasowywane do złego kliknięcia lub wyświetlenia reklamy z powodu zakresu miejsca docelowego etld+1 w interfejsie API.
Jak działają funkcje filtrowania? (dotyczy raportów na poziomie zdarzenia)
Opcjonalne pole source_data w obiekcie JSON po stronie źródła może definiować elementy, które będą następnie używane przez przeglądarkę w momencie konwersji do stosowania logiki filtrowania.
{
source_event_id: "267630968326743374",
destination: "https://toasters.example",
expiry: "604800000"
source_data: {
conversion_subdomain: ["electronics.megastore"
"electronics2.megastore"],
product: "198764",
// Note that "source_type" will be automatically generated as one of {"navigation", "event"}
}
}
Rejestracja wyzwalacza będzie teraz akceptować opcjonalny nagłówek Attribution-Reporting-Filters.
Nagłówek odpowiedzi HTTP Attribution-Reporting-Filters:
{
"conversion_subdomain": "electronics.megastore",
"directory": "/store/electronics"
}
Możesz też rozszerzyć nagłówek Attribution-Reporting-Register-Event-Trigger o pole filters, aby stosować selektywne filtrowanie i ustawiać wartość pola trigger_data na podstawie pola source_data.
Jeśli klucze w pliku JSON z filtrami pasują do kluczy w pliku source_data, to jeśli przecięcie jest puste, wyzwalacz
jest całkowicie ignorowany.
Więcej informacji znajdziesz w opisie technicznym
Dołącz do publicznej dyskusji
Zmiany w ochronie prywatności
Szum i przejrzystość (raporty na poziomie zdarzenia i raporty agregowane)
Co się zmienia i dlaczego?
W nowej propozycji ulepszono jeden z mechanizmów ochrony prywatności w raportach: raporty są losowo odpowiedziami.
Oznacza to, że niektóre rzeczywiste konwersje będą zgłaszane prawidłowo, a w pewnym odsetku przypadków niektóre z nich zostaną pominięte lub dodane fałszywe konwersje.
Ta nowa technika ma kilka zalet:
- Ujednolica mechanizm ochrony prywatności w przypadku kliknięć i wyświetleń.
- Jest prostszy niż mechanizm, w którym dane o wyzwalaczu (dane o konwersjach) i szum w połączeniu ze źródłem są rozdzielone.
- Ustanowienie ramowów ochrony prywatności, które przy odpowiednich ustawieniach szumu mogą zapewnić, że żadna ze stron nie będzie mogła polegać na interfejsie API, aby z pewnością wiedzieć, czy dany użytkownik dokonał konwersji (lub nie) w przypadku określonej reklamy.
Ten nowy mechanizm zastępuje poprzedni, w którym w 5% przypadków dane wyzwalające (dane o konwersjach) były zastępowane losową wartością.
Dodatkowo do treści raportu (pole randomized_trigger_rate) dodano wartość prawdopodobieństwa losowej odpowiedzi. To pole określa prawdopodobieństwo (0–1), że źródło jest objęte losową odpowiedzią.
Ma to 2 główne zalety:
- Dzięki temu działanie przeglądarki jest przejrzyste dla podmiotów, które otrzymują raporty (zazwyczaj firm technologicznych zajmujących się reklamami).
- Jest to przydatne w przyszłości, gdy interfejs API będzie obsługiwany w różnych przeglądarkach: różne przeglądarki mogą stosować różne poziomy szumów w zależności od swoich celów związanych z prywatnością, a strony, które będą obsługiwać raport, będą potrzebować dostępu do tych informacji.
Jak działa szum?
W ramach nowej propozycji w momencie zarejestrowania źródła (czyli zarejestrowania kliknięcia lub obejrzenia reklamy) przeglądarka losowo decyduje, czy prawidłowo przypisze konwersje i wyśle raporty o tym kliknięciu lub obejrzeniu reklamy, czy też wygeneruje fałszywy wynik.
Fałszywe dane wyjściowe mogą być:
- Brak raportu – niezależnie od tego, czy użytkownik dokonał konwersji.
- 1 lub więcej fałszywych zgłoszeń – niezależnie od tego, czy użytkownik dokonał konwersji.
W fałszywych raportach dane wywołujące (dane o konwersjach) są losowe: losowa wartość 3-bitowa dla kliknięć (dowolna liczba od 0 do 7) i losowa wartość 1-bitowa dla wyświetleń (0 lub 1).
Podobnie jak prawdziwe raporty, fałszywe raporty nie są wysyłane natychmiast po konwersji użytkownika. Są one wysyłane na koniec losowego okresu raportowania.
W przypadku kliknięć występują 3 okresy raportowania (2, 7 lub 30 dni po kliknięciu). Każdy fałszywy raport jest losowo przypisywany do jednego z okresów raportowania.
Jak już wspomnieliśmy w poprzedniej propozycji, kolejność raportów w okresie jest losowa.
Więcej informacji znajdziesz w opisie technicznym
Przykłady głośnych fałszywych konwersji
Dołącz do publicznej dyskusji
Ograniczenia raportowania (raporty na poziomie zdarzenia i raporty podlegające agregacji)
Co się zmienia i dlaczego?
Nowa propozycja wyraźnie ogranicza liczbę podmiotów, które mogą mierzyć zdarzenia między 2 witrynami.
- Maksymalna liczba unikalnych źródeł raportowania (zwykle technologii reklamowych), które mogą rejestrować źródła na {publisher, advertiser}, powinna zostać ograniczona do 100 na 30 dni. Ten licznik będzie zwiększany po każdym kliknięciu reklamy lub jej obejrzeniu (źródło zdarzenia), nawet jeśli nie zostanie przypisany.
- Maksymalna liczba unikalnych źródeł raportów (zazwyczaj dostawców technologii reklamowych), które mogą wysyłać raporty do {publisher, advertiser}, powinna zostać ograniczona do 10 na 30 dni. Ten licznik będzie zwiększany o każdą przypisaną konwersję.
Te limity są na tyle wysokie, aby nie ograniczać możliwości pomiaru konwersji, ale jednocześnie na tyle niskie, aby ograniczać niektóre formy nadużywania interfejsu API.
Wyciszanie / ograniczenia dotyczące częstotliwości raportowania
Co się zmienia i dlaczego?
Okres oczekiwania na raportowanie to mechanizm ochrony prywatności, który ogranicza łączną liczbę informacji wysyłanych przez ten interfejs API w danym okresie czasu dla danego użytkownika.
W nowej propozycji można zaplanować 100 raportów na {source site, destination, reporting origin} (zwykle {publisher, advertiser, adtech}) na przestrzeni 30 dni.
Po przekroczeniu tego limitu przeglądarka przestanie planować raporty, które pasują do tych wartości: {witryna źródłowa, miejsce docelowe, źródło raportu} (zwykle {publisher, advertiser, adtech}), dopóki liczba raportów za ostatnie 30 dni nie spadnie poniżej 100 dla tych wartości.
Więcej informacji znajdziesz w opisie technicznym
Czas oczekiwania na raportowanie / limity szybkości
Ograniczenie liczby miejsc docelowych (tylko w raportach na poziomie zdarzenia)
Co się zmienia i dlaczego?
Limitowanie miejsc docelowych zostało zmienione, aby obejmowało źródło raportowania (zazwyczaj firmę zajmującą się technologiami reklamowymi) w zakresie: 100 unikalnych oczekujących miejsc docelowych (zazwyczaj witryn reklamodawców lub witryn, w których mają miejsce konwersje) na {publisher, adtech}.
Jest to ochrona prywatności, która ogranicza odtwarzanie historii przeglądania.
Więcej informacji znajdziesz w opisie technicznym
Ograniczanie liczby unikalnych miejsc docelowych objętych oczekującymi źródłami
Wszystkie zasoby
- Zobacz raportowanie atrybucji.
- Przeczytaj artykuł Więcej informacji o interfejsie API.
Obraz nagłówka pochodzi od Diana Polekhina z Unsplash.